Java8 Stream:两万字博文教你玩转集合的筛选、归约、分组、聚合
目录
-
- 一.Stream概述
- 二.Stream 的创建
- 三.Stream 的中间操作
-
- 3.1.筛选(filter/distinct)
- 3.2.切片(limit/skip)
- 3.3.映射(map/mapToDouble/flatMap)
- 3.4.排序(sorted)
- 3.5.合并流(concat)
- 四.Stream 的终止操作
-
- 4.1.匹配(allMatch/anyMatch/noneMatch)
- 4.2.查找(findFirst/findAny)
- 4.3.聚合/遍历(count/max/min/forEach)
- 4.4.归约(reduce)
- 4.5.收集(collect)
-
- 4.5.1.归集(toList/toSet/toMap)
- 4.5.2.统计(count/averaging)
- 4.5.3.分组(partitioningBy/groupingBy)
- 4.5.4.接合(joining)
- 4.5.5.归约(reducing)
- 五.并行流与串行流
- 六.流操作分类
善意提示:学stream前提是要求掌握匿名函数、函数式接口、lambda表达式。不然学stream是很痛苦的。可以选择收藏本篇文章,开发的时候想不起来的时候看看。
Lambda表达式用法详解
一.Stream概述
Stream API说明
- Java8中有两大最为重要的改变。第一个是
Lambda 表达式;另外一个则是Stream API。 Stream API (java.util.stream)把真正的函数式编程风格引入到Java中。正是因为他的出现,lambda出现的频率才更多了一点。
Stream API作用
实际开发中,项目中多数数据源都来自于Mysql,Oracle等。但现在数据源可以更多了,有MongDB,Radis等,而这些NoSQL的数据就需要Java层面去处理。这时候就可以用stream来对返回的集合数据进行复杂的操作,例如分页、筛选、去重等等…
Stream 和 Collection 集合的区别
Collection 是一种静态的内存数据结构,而 Stream 是有关计算的。前者是主要面向内存,存储在内存中,后者主要是面向 CPU,通过 CPU 实现计算。
Stream 操作分为三个步骤
- 创建 Stream:通过数据源(如:集合、数组),获取一个流
- 中间操作:对数据源的数据进行处理,处理可能是执行很多操作,所以形成了一个操作链。
- 终止操作(终端操作)
一旦执行终止操作,就执行中间操作链,并产生结果。

注意
Stream是流,自己不会存储元素,而是按照特定的规则对数据进行计算,一般会输出结果。Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream、或者新的集合。- stream具有延迟执行特性,
只有调用终端操作时,中间操作才会执行。 - stream是流,
一旦执行终止操作,就关流了,所以就不允许再对流进行操作了,否则直接报错,但是可以对流计算出来的结果进行操作。
二.Stream 的创建
创建 Stream方式一:通过集合
Java8 中的 Collection 接口被扩展,提供了两个获取流的方法:
default Stream: 返回一个顺序流stream() default Stream: 返回一个并行流parallelStream()
List<String> list = Arrays.asList("a", "b", "c");
// 创建顺序流的两种方式
Stream<String> stream = list.stream();
Stream<String> sequential = list.stream().sequential();
// 创建一个并行流的两种方式
Stream<String> parallel = list.stream().parallel();
Stream<String> stringStream = list.parallelStream();
创建 Stream方式二:通过数组
Java8 中的 Arrays 的静态方法 stream() 可以获取数组流:
static: 返回一个流Stream stream(T[] array)
重载形式,能够处理对应基本类型的数组:
public static IntStream stream(int[] array)public static LongStream stream(long[] array)public static DoubleStream stream(double[] array)
int[] array={1,3,5,6,8};
IntStream stream = Arrays.stream(array);
创建 Stream方式三:通过Stream的of()
可以调用Stream类静态方法 of(), 通过显示值创建一个流。它可以接收任意数量的参数。
public static: 返回一个流Stream of(T... values)
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);
创建 Stream方式四:创建无限流
可以使用静态方法 Stream.iterate() 和 Stream.generate(), 创建无限流。
迭代:public static
生成:public static
public static void main(String[] args) {
// 迭代
// public static Stream iterate(final T seed, final UnaryOperator f)
Stream<Integer> stream = Stream.iterate(0, x -> x + 2);
stream.limit(10).forEach(System.out::println);
// 生成
// public static Stream generate(Supplier s)
Stream<Double> stream1 = Stream.generate(Math::random);
stream1.limit(10).forEach(System.out::println);
}
注意: 一定要配合limit截断 ,不然无限制下去了
三.Stream 的中间操作
深入理解:
多个
中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为“惰性求值”。
3.1.筛选(filter/distinct)

代码示例:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Arrays;
import java.util.List;
@Data
@AllArgsConstructor
@NoArgsConstructor
class User {
private String name;
private Integer age;
}
public class StreamTest {
public static List<User> users = Arrays.asList(
new User("lzj", 25),
new User("zhangsan", 26),
new User("lisi", 30),
new User("wanger", 18),
new User("zhaowu", 29),
new User("zhaowu", 29));
public static void main(String[] args) {
// 过滤出年龄大于20的对象,并打印出来,forEach是终止操作当中的一种
// forEach实际就是使用的 内置四大核心函数式接口之一 ,Predicate断定性函数,也就是返回false就过滤掉,只留下为true的数据
users.stream().filter(a -> a.getAge() > 20).forEach(System.out::println);
// distinct()去重,不需要传任何参数
users.stream().distinct().forEach(System.out::println);
}
}
3.2.切片(limit/skip)

代码示例:
// limit,限制从流中获得前n个数据
users.stream().limit(3).forEach(System.out::println);
// skip,跳过前n个数据
users.stream().skip(3).forEach(System.out::println);
// 中间操作可以是个链子,也就是可以多个操作,如下:过滤出年龄大于20的对象、去重后只取第一条
users.stream().filter(a->a.getAge()>20).distinct().limit(1).forEach(System.out::println);
错误示例:
如果有多个中间操作的时候一定要注意使用顺序,例如下面假如limit放前面,他会直接把其他数据全过滤掉,只留下第一条,然后再将留下来的这一条进行filter跟distinct。这也就是我们所说的中间操作链,他是个链子,就是一步一步进行执行的。
users.stream().limit(1).filter(a->a.getAge()>20).distinct().forEach(System.out::println);
3.3.映射(map/mapToDouble/flatMap)
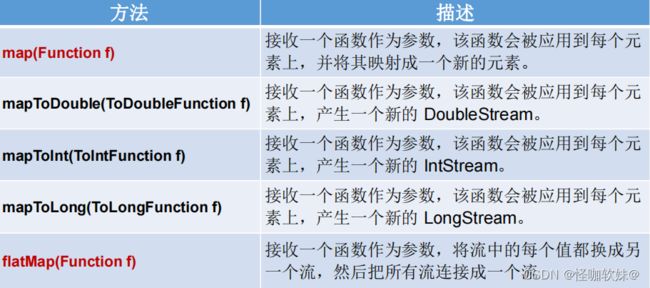
开发当中map出场率基本上是最高的,平时我们想要对集合当中每个对象做一个操作,或者是获取集合当中对象的一个属性,都可以用map来解决。
map代码示例:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.junit.Test;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
@Data
@AllArgsConstructor
@NoArgsConstructor
class User {
private String name;
private Integer age;
}
@Data
@AllArgsConstructor
@NoArgsConstructor
class UserDto {
private String name;
private Integer age;
}
public class StreamTest {
public static List<User> users = Arrays.asList(
new User("lzj", 25),
new User("zhangsan", 26),
new User("lisi", 30),
new User("wanger", 18),
new User("zhaowu", 29),
new User("zhaowu", 29));
@Test
public void Test1() {
// 将所有人年龄加1
users.stream().map(a -> a.getAge() + 1).forEach(System.out::println);
// 可能个别人要加1
users.stream().map(user -> {
if (user.getName().equals("lzj")) {
user.setAge(user.getAge() + 1);
}
return user;
}).forEach(System.out::println);
// 对象转换,在开发中也经常会遇到的,user转userdto
List<UserDto> collect = users.stream().map(user -> {
UserDto userDto = new UserDto();
userDto.setName(user.getName());
return userDto;
}).collect(Collectors.toList());
// 只取对象当中的年龄
List<Integer> collect1 = users.stream().map(user -> user.getAge()).collect(Collectors.toList());
collect1.forEach(System.out::print);
}
/**
* 这个示例主要是针对于数组流
*/
@Test
public void Test2() {
String[] strArr = {"abcd", "bcdd", "defde", "fTr"};
// 将数组元素全部转换大写,collect(Collectors.toList())作用就是转换成List
List<String> strList = Arrays.stream(strArr).map(String::toUpperCase).collect(Collectors.toList());
List<Integer> intList = Arrays.asList(1, 3, 5, 7, 9, 11);
// 将数组元素全部加3
List<Integer> intListNew = intList.stream().map(x -> x + 3).collect(Collectors.toList());
System.out.println("每个元素大写:" + strList);
System.out.println("每个元素+3:" + intListNew);
}
}
flatMap代码示例:
flatMap和map是不一样的,flatMap相当于将值给转换成了流,最终将多个流合并成了一个流(相当于流嵌套使用)。实际开发当中应该很少用。但是他可以完成的功能,使用map不一定能完成。
public void test1(){
List<String> list = Arrays.asList("m,k,l,a", "1,3,5,7");
List<String> listNew = list.stream().flatMap(s -> {
// 将每个元素转换成一个stream
String[] split = s.split(",");
Stream<String> s2 = Arrays.stream(split);
return s2;
}).collect(Collectors.toList());
System.out.println("处理前的集合:" + list);
System.out.println("处理后的集合:" + listNew);
}
输出结果:

其他的代码示例:
当我们想要获取集合当中,所有对象当中某个属性的最大值、最小值、平均值、求和等操作的时候,可以使用mapToDouble、mapToInt、mapToLong。
@Test
public void Test5() {
// 利用mapToDouble将对象的age年龄取出来进行 求和,返回的是double类型参数,users为空的时候返回0.0
DoubleStream doubleStream = users.stream().mapToDouble(s -> s.getAge())
double sum1 = doubleStream.sum();
// 取最大值返回的是OptionalDouble,跟Optional类似。
OptionalDouble max = users.stream().mapToDouble(s -> s.getAge()).max();
// users为空的时候,max直接get取值会报错的,所以用了orElse为空的时候返回0
double v = max.orElse(new Double(0));
// 取最小值
OptionalDouble min = users.stream().mapToDouble(s -> s.getAge()).min();
// 取平均值
OptionalDouble average = users.stream().mapToDouble(s -> s.getAge()).average();
// 取年龄的最大值,users为空的时候返回0
long count = users.stream().mapToDouble(s -> s.getAge()).count();
}
注意: 使用mapToDouble最后返回的就是DoubleStream,而不再是Stream了,mapToInt、mapToLong同样如此,都会返回自己对应类型的Stream,DoubleStream和Stream都是一个接口类,同样都继承了BaseStream。
Stream和DoubleStream之间的很多聚合函数方法返回的值是不一样的,以max函数为例:
-
Stream当中使用max的时候我们需要在max参数当中,创建一个Comparator函数实例来告知要比较那个属性,
当哪个值大的时候返回整个对象, -
而DoubleStream使用max函数是通过在DoubleStream将某个属性全取出来,然后调用max函数,返回最大的值,而不是对象。
Optional<Person> max = persons.stream().max((p1, p2) -> Integer.compare(p1.getAge(), p2.getAge()));
3.4.排序(sorted)
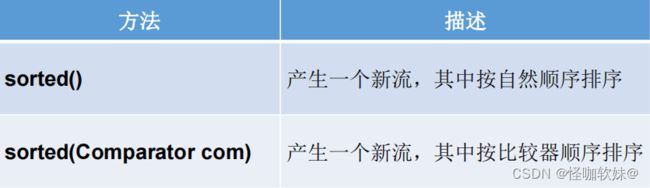
注意: 使用sorted()不携带参数的话,要求集合当中的对象必须实现Comparable接口。不然会报ClassCastException异常。一般实际开发我们一般是能不动实体类就不动实体类,所以一般都是采用lambda创建实例传参的形式,来进行排序的。
代码示例:
import lombok.AllArgsConstructor;
import lombok.Data;
import org.junit.Test;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
@Data
@AllArgsConstructor
class Person {
private String name;
private Integer salary;
private Integer age;
}
public class StreamTest1 {
public static List<Person> persons = Arrays.asList(
new Person("Sherry", 9000, 24),
new Person("Tom", 8900, 21),
new Person("Jack", 9000, 22),
new Person("Lily", 9200, 23),
new Person("Alisa", 7000, 26),
new Person("zhangsan", 6000, 28));
/**
* 排序
*/
@Test
public void Test() {
// 按工资升序排序(自然排序),这里用到了接口的Comparator提供的comparing静态方法构造器,传入的参数是一个Function
persons.stream().sorted(Comparator.comparing(Person::getSalary)).forEach(System.out::println);
// 按工资倒序排序,reversed就是将顺序倒过来,然后只取名称.
List<String> names = persons.stream().sorted(Comparator.comparing(Person::getSalary).reversed())
.map(Person::getName)
.collect(Collectors.toList());
// 先按工资再按年龄升序排序(二级排序就是当一级排序的两个元素相等的时候,再用二级排序进行比较)
persons.stream().sorted(Comparator.comparing(Person::getSalary)
.thenComparing(Person::getAge)).forEach(System.out::println);
// 先按工资再按年龄自定义排序(降序)
List<String> newList4 = persons.stream().sorted((p1, p2) -> {
if (p1.getSalary().equals(p2.getSalary())) {
return p2.getAge() - p1.getAge();
} else {
return p2.getSalary() - p1.getSalary();
}
}).map(Person::getName).collect(Collectors.toList());
newList4.forEach(System.out::println);
}
}
3.5.合并流(concat)
代码示例:
public static void main(String[] args) {
String[] arr1 = {"a", "b", "c", "d"};
String[] arr2 = {"d", "e", "f", "g"};
Stream<String> stream1 = Stream.of(arr1);
Stream<String> stream2 = Stream.of(arr2);
// concat:合并两个流 distinct:去重
List<String> newList = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());
System.out.println(newList);
}
输出结果:

四.Stream 的终止操作
- 终端操作会从流的流水线生成结果。其结果可以是任何不是流的值
例如:List、Integer,甚至是 void 。
注意: 流进行了终止操作后,不能再次使用。
4.1.匹配(allMatch/anyMatch/noneMatch)

代码示例:
public void Test1() {
// 检查集合当中 所有对象的name 是否为Tom,如果都是 则返回true,有一个不是则false,集合为空的时候返回true
boolean tom = persons.stream().allMatch(p -> p.getName().equals("Tom"));
// 检查集合当中 只要有一个对象的name为Tom,就返回true
boolean tom1 = persons.stream().anyMatch(p -> p.getName().equals("Tom"));
// 当Tom在集合当中不存在的时候返回true,和anyMatch功能相反
boolean tom2 = persons.stream().noneMatch(p -> p.getName().equals("Tom"));
}
4.2.查找(findFirst/findAny)

代码示例:
// 返回第一个元素
Optional<Person> first = persons.stream().findFirst();
// 返回当前流中任意元素
Optional<Person> first1 = persons.stream().findAny();
4.3.聚合/遍历(count/max/min/forEach)

代码示例:
public void Test2() {
// 统计年龄为22的人数,persons为空的时候返回0
long count = persons.stream().filter(person -> person.getAge()==22).count();
// 取年龄最大的
Optional<Person> max = persons.stream().max((p1, p2) -> Integer.compare(p1.getAge(), p2.getAge()));
System.out.println(max.get());
// 取年龄属性最小的
Optional<Person> min = persons.stream().min((p1, p2) -> Integer.compare(p1.getAge(), p2.getAge()));
// 循环就是用的消费函数,流当中有循环函数,集合当中也有循环函数,我们可以循环输出、可以循环给属性赋值等等
persons.forEach(person -> person.setName("张三"));
persons.stream().forEach(System.out::println);
}
4.4.归约(reduce)
归约,也称缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。
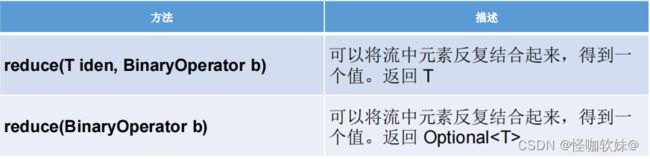
代码示例一:求Integer集合的元素之和、乘积和最大值。
public class StreamTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 3, 2, 8, 11, 4);
// 求和方式1
Optional<Integer> sum = list.stream().reduce((x, y) -> x + y);
// 求和方式2
Optional<Integer> sum2 = list.stream().reduce(Integer::sum);
// 求和方式3
Integer sum3 = list.stream().reduce(0, Integer::sum);
// 求乘积
Optional<Integer> product = list.stream().reduce((x, y) -> x * y);
// 求最大值方式1
Optional<Integer> max = list.stream().reduce((x, y) -> x > y ? x : y);
// 求最大值写法2
Integer max2 = list.stream().reduce(1, Integer::max);
System.out.println("list求和:" + sum.get() + "," + sum2.get() + "," + sum3);
System.out.println("list求积:" + product.get());
System.out.println("list求和:" + max.get() + "," + max2);
}
}
代码示例二:实际开发当中往往都是以下拿实体来对某个属性求和,求最大值等等
注意:实际开发当中,不管是求和还是取最大值,在你不确定属性是否存在为null的时候,就需要严防NPE错误。
import lombok.AllArgsConstructor;
import lombok.Data;
import org.junit.Test;
import java.math.BigDecimal;
import java.util.*;
@Data
@AllArgsConstructor
class Person {
private String name;
private Integer salary;
private BigDecimal salary1;
private Integer age;
}
public class StreamTest1 {
public static List<Person> persons = Arrays.asList(
new Person("Sherry", null, null, 24),
new Person("Tom", 8900, new BigDecimal(8900), 21),
new Person("Jack", 9000, new BigDecimal(9000), 22),
new Person("Lily", 9200, new BigDecimal(9200), 23),
new Person("Alisa", 7000, new BigDecimal(7000), 26),
new Person("zhangsan", 6000, new BigDecimal(6000), 28));
/**
* 归约(reduce)
*/
@Test
public void Test3() {
// 求工资之和方式1:
int sum1 = persons.stream()
.filter(p -> p.getSalary() != null)
.mapToInt(Person::getSalary).sum();
// 求工资之和方式2:
Optional<Integer> sum2 = persons.stream()
.filter(p -> p.getSalary() != null)
.map(Person::getSalary)
.reduce(Integer::sum);
// 求工资之和方式3:reduce一共传入了三个参数identity就是初始值的意思
Integer sumSalary2 = persons.stream()
.filter(p -> p.getSalary() != null)
.reduce(1000, (sum, p) -> sum += p.getSalary(), (a, b) -> a + b);
// 求工资之和方式4:
Integer reduce1 = persons.stream()
.filter(p -> p.getSalary() != null)
.reduce(0, (sum, p) -> sum += p.getSalary(), Integer::sum);
// 涉及到小数的一般我们都会用BigDecimal,这个是BigDecimal求和,setScale就是保留两位小数,BigDecimal.ROUND_DOWN就是不采取四舍五入
BigDecimal bigDecimal = persons.stream()
.filter(p -> p.getSalary1() != null)
.map(Person::getSalary1)
.reduce(BigDecimal.ZERO, BigDecimal::add)
.setScale(2, BigDecimal.ROUND_DOWN);
// 求最高工资方式1:
Integer maxSalary = persons.stream()
.filter(p -> p.getSalary() != null)
.reduce(0, (max, p) -> max > p.getSalary() ? max : p.getSalary(), Integer::max);
// 求最高工资方式2:
Integer maxSalary2 = persons.stream()
.filter(p -> p.getSalary() != null)
.reduce(0, (max, p) -> max > p.getSalary() ? max : p.getSalary(), (max1, max2) -> max1 > max2 ? max1 : max2);
// 求最高工资方式3:
OptionalInt max = persons.stream()
.filter(p -> p.getSalary() != null)
.mapToInt(Person::getSalary).max();
// 求最高工资方式4:
Optional<Integer> max4 = persons.stream()
.filter(p -> p.getSalary() != null)
.map(Person::getSalary).reduce(Integer::max);
}
}
4.5.收集(collect)
collect,收集,可以说是内容最繁多、功能最丰富的部分了。从字面上去理解,就是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合。

Collector 接口中方法的实现决定了如何对流执行收集的操作(如收集到 List、Set、Map)。
Collectors 提供了很多静态方法,可以方便地创建常见Collector实例。下面示例全都是基于Collectors提供的静态方法,来创建Collector实例。
4.5.1.归集(toList/toSet/toMap)
因为流不存储数据,那么在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。toList、toSet和toMap比较常用,另外还有toCollection、toConcurrentMap等复杂一些的用法。
下面用一个案例演示toList、toSet和toMap:
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 6, 3, 4, 6, 7, 9, 6, 20);
List<Integer> listNew = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toList());
Set<Integer> set = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toSet());
List<Person> personList = Arrays.asList(
new Person("Sherry", 9300, 24),
new Person("Tom", 8900, 21),
new Person("Jack", 9000, 22),
new Person("Lily", 9200, 23),
new Person("Alisa", 7000, 26),
new Person("zhangsan", 6000, 28));
Map<?, Person> map = personList.stream().filter(p -> p.getSalary() > 9000)
.collect(Collectors.toMap(Person::getName, p -> p));
System.out.println("toList:" + listNew);
System.out.println("toSet:" + set);
System.out.println("toMap:" + map);
}
输出结果:

4.5.2.统计(count/averaging)
Collectors提供了一系列用于数据统计的静态方法:
- 计数:count
- 平均值:averagingInt、averagingLong、averagingDouble
- 最值:maxBy、minBy
- 求和:summingInt、summingLong、summingDouble
- 统计以上所有:summarizingInt、summarizingLong、summarizingDouble
案例:统计员工人数、平均工资、工资总额、最高工资。
public static void main(String[] args) {
List<Person> personList = Arrays.asList(
new Person("Sherry", 9300, 24),
new Person("Tom", 8900, 21),
new Person("Jack", 9000, 22),
new Person("Lily", 9200, 23),
new Person("Alisa", 7000, 26),
new Person("zhangsan", 6000, 28));
// 求总数
Long count = personList.stream().collect(Collectors.counting());
// 求平均工资
Double average = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));
// 求最高工资
Optional<Integer> max = personList.stream().map(Person::getSalary).collect(Collectors.maxBy(Integer::compare));
// 求工资之和
Integer sum = personList.stream().collect(Collectors.summingInt(Person::getSalary));
// 一次性统计所有信息
DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));
System.out.println("员工总数:" + count);
System.out.println("员工平均工资:" + average);
System.out.println("员工工资总和:" + sum);
System.out.println("员工工资所有统计:" + collect);
}
输出结果:

4.5.3.分组(partitioningBy/groupingBy)
分区:将stream按条件分为两个Map,比如员工按薪资是否高于8000分为两部分。
分组:将集合分为多个Map,比如员工按性别分组。有单级分组和多级分组。
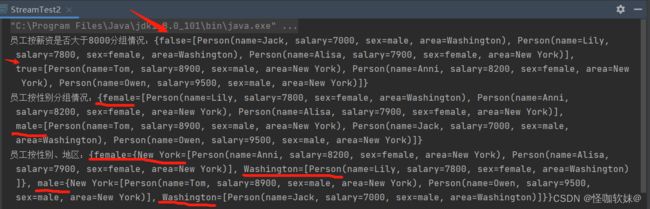
案例:将员工按薪资是否高于8000分为两部分;将员工按性别和地区分组
public static void main(String[] args) {
List<Person> personList = Arrays.asList(
new Person("Tom", 8900, "male", "New York"),
new Person("Jack", 7000, "male", "Washington"),
new Person("Lily", 7800, "female", "Washington"),
new Person("Anni", 8200, "female", "New York"),
new Person("Owen", 9500, "male", "New York"),
new Person("Alisa", 7900, "female", "New York"));
// 将员工按薪资是否高于8000分组
Map<Boolean, List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000));
// 将员工按性别分组
Map<String, List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getSex));
// 将员工先按性别分组,再按地区分组
Map<String, Map<String, List<Person>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getArea)));
System.out.println("员工按薪资是否大于8000分组情况:" + part);
System.out.println("员工按性别分组情况:" + group);
System.out.println("员工按性别、地区:" + group2);
}
输出结果:
4.5.4.接合(joining)
joining可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, "male", "New York"));
personList.add(new Person("Jack", 7000, "male", "Washington"));
personList.add(new Person("Lily", 7800, "female", "Washington"));
String names = personList.stream().map(p -> p.getName()).collect(Collectors.joining(","));
System.out.println("所有员工的姓名:" + names);
List<String> list = Arrays.asList("A", "B", "C");
String string = list.stream().collect(Collectors.joining("-"));
System.out.println("拼接后的字符串:" + string);
}
输出结果:

4.5.5.归约(reducing)
Collectors类提供的reducing方法,相比于stream本身的reduce方法,增加了对自定义归约的支持。
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, "male", "New York"));
personList.add(new Person("Jack", 7000, "male", "Washington"));
personList.add(new Person("Lily", 7800, "female", "Washington"));
// 每个员工涨薪两千,然后计算涨薪后公司的薪资支出
Integer sum = personList.stream().collect(Collectors.reducing(0, Person::getSalary, (i, j) -> (i + j + 2000)));
System.out.println("员工涨薪后工资总和:" + sum);
// stream的reduce
Optional<Integer> sum2 = personList.stream().map(Person::getSalary).reduce(Integer::sum);
System.out.println("员工薪资总和:" + sum2.get());
}
输出结果:

五.并行流与串行流
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。相比较串行的流,并行的流可以很大程度上提高程序的执行效率。
Java 8 中将并行进行了优化,我们可以很容易的对数据进行并行操作。Stream API 可以声明性地通过 parallel() 与 sequential() 在并行流与顺序流之间进行切换。
代码示例一:
使用并行流和串行流分别计算数字累计使用的时间,数字越大越明显
public static void test4() {
long start = System.currentTimeMillis();
long reduce = LongStream.rangeClosed(0, 1000000000).parallel().reduce(0, Long::sum);
System.out.println(reduce);
long end = System.currentTimeMillis();
System.out.println(end - start);// 并行流:418
}
public static void test3() {
long start = System.currentTimeMillis();
long reduce = LongStream.rangeClosed(0, 1000000000).sequential().reduce(0, Long::sum);
System.out.println(reduce);
long end = System.currentTimeMillis();
System.out.println(end - start);// 串行流:122
}
代码示例二:
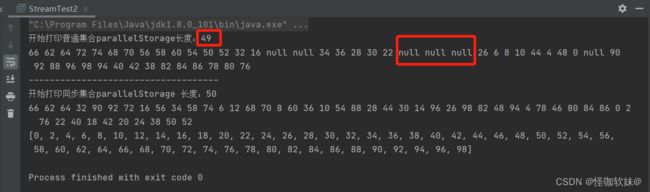
使用并行流就涉及到了多线程,那我们就需要考虑线程安全的问题,在实际开发当中一般不到迫不得已的情况,很少会使用并行流。
public static void main(String[] args) {
List<Integer> integersList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
integersList.add(i);
}
//普通集合 存储
List<Integer> parallelStorage = new ArrayList<>();
//通过并行流存入普通集合parallelStorage中
integersList
.parallelStream()
.filter(i -> i % 2 == 0)
.forEach(i -> parallelStorage.add(i));
System.out.println("开始打印普通集合parallelStorage长度:" + parallelStorage.size());
parallelStorage
.stream()
.forEachOrdered(e -> System.out.print(e + " "));
System.out.println();
System.out.print("------------------------------------");
System.out.println();
//解决线程安全问题使用 同步集合 存储
List<Integer> parallelStorage2 = Collections.synchronizedList(new ArrayList<>());
//通过并行流存入同步集合parallelStorage2中
integersList
.parallelStream()
.filter(i -> i % 2 == 0)
.forEach(i -> parallelStorage2.add(i));
System.out.println("开始打印同步集合parallelStorage 长度:" + parallelStorage2.size());
parallelStorage2
.stream()
.forEachOrdered(e -> System.out.print(e + " "));
Collections.sort(parallelStorage2);
System.out.println();
System.out.println(parallelStorage2);
}
运行结果:
通过运行结果可以看出,ArrayList是线程不安全的,在并行流的时候,出现了很多异常现象。
六.流操作分类
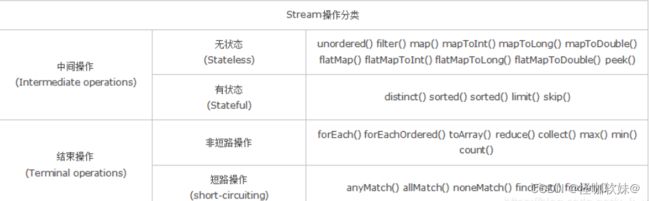
- 无状态: 指元素的处理不受之前元素的影响,可以在单个对单个的数据进行处理,不用等拿到所有结果。
- 有状态: 指该操作只有拿到所有元素之后才能继续下去。
- 非短路操作: 指必须处理所有元素才能得到最终结果;
- 短路操作: 指遇到某些符合条件的元素就可以得到最终结果,如 A || B,只要A为true,则无需判断B的结果。