实现yolov5漏检率与虚警次数指标计算并显示
项目场景:
某场景下,输出目标漏检率和虚警次数
本项目包含两类红外目标UAV_S与UAV_L,分别对两类目标求漏检率和虚警次数并显示,最后求平均值后显示(实际上两类目标为对数据集进行分析后进行判断得到,实际只有一类目标UAV。以10×10像素为分界分类,有助于提升网络对红外大目标与小目标特征的学习)

可以看到在这张图像中有两个无人机目标,但二者特征差距巨大。通过数据分析,10×10像素以下的无人机目标没有轮廓信息,10×10以上的无人机目标可以看出旋翼等轮廓信息。
相关原理
基础概念
(1)P=Positive:
目标检测中的类别m,设其为正样本;
(2)N=negative:
目标检测中的类别background,设其为负样本;
(3)TP=True Positive:
把m正确检测为m框的数量(正确的m框);
(4)FP=False Positive:
把background错误检测为m框的数量(错误的m框);
(5)TN=True Negative:
把background正确检测为background框的数量(正确的background框),识别为背景的框(非目标)一般在算法结束时,统一清除不显示;
(6)FN=False Negative:
把m错误检测为background框的数量(错误的background框)。
四个常用指标
(1)精确率(Precision):TP/(TP+FP)
所有判断为正例的例子中,真正为正例的所占的比例
(2)召回率(Recall):TP/(TP+FN)
所有正例中,被判断为正例的比例
(3)漏检率:FN/(TP+FN)=1-Recall
(4)虚警率:FP/(TP+FP)=1-Precision
(5)虚警次数:FP
代码:
yolov5_eval.py
import argparse
import os
import platform
import shutil
import time
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import (
check_img_size, non_max_suppression, apply_classifier, scale_coords,
xyxy2xywh, plot_one_box, strip_optimizer, set_logging)
from utils.torch_utils import select_device, load_classifier, time_synchronized
from cfg_mAP import Cfg
os.environ["CUDA_VISIBLE_DEVICES"] = "4"
cfg = Cfg
def detect(save_img=False):
out, source, weights, view_img, save_txt, imgsz = \
opt.output, opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size
webcam = source == '0' or source.startswith('rtsp') or source.startswith('http') or source.endswith('.txt')
# Initialize
set_logging()
device = select_device(opt.device)
if os.path.exists(out):
shutil.rmtree(out) # delete output folder
os.makedirs(out) # make new output folder
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
imgsz = check_img_size(imgsz, s=model.stride.max()) # check img_size
if half:
model.half() # to FP16
# Second-stage classifier
classify = False
if classify:
modelc = load_classifier(name='resnet101', n=2) # initialize
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']) # load weights
modelc.to(device).eval()
# Set Dataloader
vid_path, vid_writer = None, None
if webcam:
view_img = True
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz)
else:
save_img = True
dataset = LoadImages(source, img_size=imgsz)
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(names))]
# Run inference
t0 = time.time()
img = torch.zeros((1, 3, imgsz, imgsz), device=device) # init img
_ = model(img.half() if half else img) if device.type != 'cpu' else None # run once
test_time=[]
for path, img, im0s, vid_cap in dataset:
# Inference
t1 = time_synchronized()
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# # Inference
# t1 = time_synchronized()
pred = model(img, augment=opt.augment)[0]
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = time_synchronized()
# Apply Classifier
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process detections
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0 = path[i], '%g: ' % i, im0s[i].copy()
else:
p, s, im0 = path, '', im0s
img_name = Path(p).name
txt = open(opt.eval_imgs_name_txt, 'a')
txt.write(img_name[:-4])
txt.write('\n')
txt.close()
save_path = str(Path(out) / Path(p).name)
txt_path = str(Path(out) / Path(p).stem) + ('_%g' % dataset.frame if dataset.mode == 'video' else '')
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if det is not None and len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += '%g %ss, ' % (n, names[int(c)]) # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
txt = open(opt.eval_classtxt_path + '/%s' % names[int(cls)], 'a')
obj_conf = conf.cpu().numpy()
xyxy = torch.tensor(xyxy).numpy()
x1 = xyxy[0]
y1 = xyxy[1]
x2 = xyxy[2]
y2 = xyxy[3]
new_box = [img_name[:-4], obj_conf, x1, y1, x2, y2]
txt.write(" ".join([str(a) for a in new_box]))
txt.write('\n')
txt.close()
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * 5 + '\n') % (cls, *xywh)) # label format
if save_img or view_img: # Add bbox to image
label = '%s %.2f' % (cfg.textnames[int(cls)], conf)
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=1)
test_time.append(t2 - t1)
# Print time (inference + NMS)
print('%sDone. (%.3fs)' % (s, t2 - t1))
# Stream results
if view_img:
cv2.imshow(p, im0)
if cv2.waitKey(1) == ord('q'): # q to quit
raise StopIteration
# Save results (image with detections)
if save_img:
if dataset.mode == 'images':
cv2.imwrite(save_path, im0)
else:
if vid_path != save_path: # new video
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release() # release previous video writer
fourcc = 'mp4v' # output video codec
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*fourcc), fps, (w, h))
vid_writer.write(im0)
if save_txt or save_img:
print('Results saved to %s' % Path(out))
if platform.system() == 'Darwin' and not opt.update: # MacOS
os.system('open ' + save_path)
print('Done. (%.3fs)' % (time.time() - t0))
mean_time=sum(test_time)/len(test_time)
print('mean time:', mean_time)
print('frame: ', 1/mean_time)
if __name__ == '__main__':
dir = 'imgs_name_manual.txt'
if os.path.exists(dir):
os.remove(dir)
else:
open(dir, 'w')
predictions_manual='predictions_manual'
class_txt_manual='class_txt_manual'
cachedir_manual='cachedir_manual'
if os.path.exists(predictions_manual):
shutil.rmtree(predictions_manual) # delete output folder
os.makedirs(predictions_manual) # make new output folder
if os.path.exists(class_txt_manual):
shutil.rmtree(class_txt_manual) # delete output folder
os.makedirs(class_txt_manual) # make new output folder
if os.path.exists(cachedir_manual):
shutil.rmtree(cachedir_manual) # delete output folder
os.makedirs(cachedir_manual) # make new output folder
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='runs/exp4_exp/weights/last_exp.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='JPEGImages_manual',
help='source') # file/folder, 0 for webcam
parser.add_argument('--output', type=str, default='predictions_manual',
help='output folder') # output folder
parser.add_argument('--eval_imgs_name_txt', type=str, default='imgs_name_manual.txt',
help='output folder') # output folder
parser.add_argument('--eval_classtxt_path', type=str, default='class_txt_manual',
help='output folder') # output folder
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.5, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
parser.add_argument('--device', default='4', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
opt = parser.parse_args()
print(opt)
with torch.no_grad():
if opt.update: # update all models (to fix SourceChangeWarning)
for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']:
detect()
strip_optimizer(opt.weights)
else:
detect()
compute_mAP.py
# -*- coding: utf-8 -*-
import os
import numpy as np
from yolov5_eval import yolov5_eval # 注意将yolov4_eval.py和compute_mAP.py放在同一级目录下
from cfg_mAP import Cfg
import pickle
import shutil
cfg = Cfg
eval_classtxt_path = cfg.eval_classtxt_path # 各类txt文件路径
eval_classtxt_files = os.listdir(eval_classtxt_path)
classes = cfg.names # ['combustion_lining', 'fan', 'fan_stator_casing_and_support', 'hp_core_casing', 'hpc_spool', 'hpc_stage_5','mixer', 'nozzle', 'nozzle_cone', 'stand']
aps = [] # 保存各类ap
cls_rec = {} # 保存recall
cls_prec = {} # 保存精度
cls_ap = {}
fns = []
FNS = 0
annopath = cfg.eval_Annotations_path + '/{:s}.xml' # annotations的路径,{:s}.xml方便后面根据图像名字读取对应的xml文件
imagesetfile = cfg.eval_imgs_name_txt # 读取图像名字列表文件
cachedir = cfg.cachedir
if os.path.exists(cachedir):
shutil.rmtree(cachedir) # delete output folder
os.makedirs(cachedir) # make new output folder
for cls in eval_classtxt_files: # 读取cls类对应的txt文件
filename = eval_classtxt_path + cls
rec, prec, ap, tp, fp, FN = yolov5_eval( # yolov4_eval.py计算cls类的recall precision ap
filename, annopath, imagesetfile, cls, cachedir, ovthresh=0.01,
use_07_metric=False)
aps += [ap]
cls_ap[cls] = ap
cls_rec[cls] = rec[-1]
cls_prec[cls] = prec[-1]
fn = 1 - rec[-1]
fns += [fn]
FNS += FN
# print("aaaaa:",FNS,FN)
# print('AP for {} = {:.4f}'.format(cls, ap))
# print('recall for {} = {:.4f}'.format(cls, rec[-1]))
# print('precision for {} = {:.4f}'.format(cls, prec[-1]))
# print('FN for {} = {:.4f}'.format(cls, fn))
with open(os.path.join(cfg.cachedir, 'cls_ap.pkl'), 'wb') as in_data:
pickle.dump(cls_ap, in_data, pickle.HIGHEST_PROTOCOL)
with open(os.path.join(cfg.cachedir, 'cls_rec.pkl'), 'wb') as in_data:
pickle.dump(cls_rec, in_data, pickle.HIGHEST_PROTOCOL)
with open(os.path.join(cfg.cachedir, 'cls_prec.pkl'), 'wb') as in_data:
pickle.dump(cls_prec, in_data, pickle.HIGHEST_PROTOCOL)
# print('Mean AP = {:.4f}'.format(np.mean(aps)))
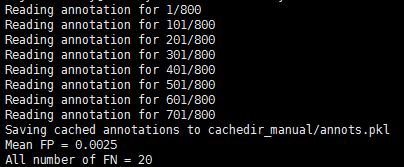
print('Mean FP = {:.4f}'.format(np.mean(fns)))
print('All number of FN = {:d}'.format(int(FNS)))
# print('~~~~~~~~')
# print('Results:')
# for ap in aps:
# print('{:.3f}'.format(ap))
# print('~~~~~~~~')
# print('{:.3f}'.format(np.mean(aps)))
# print('~~~~~~~~')
输出结果:
参考:
https://blog.csdn.net/qq_29007291/article/details/86080456
https://blog.csdn.net/tpz789/article/details/110675268