linux 内存不足 调优,(2)Linux性能调优之Linux内存体系
一、前言
上一节我们谈了Linux的进程管理:
这一节我们将谈下Linux的内存体系
二、概览
进程执行过程中,Linux内核根据需要给进程分配一块内存区域。进程就把这片区域作为工作区,按要求执行操作。这就像给你分配一张自己的桌子,你可以在桌子上摆放文档,备忘录,开展自己的工作。区别在于,内核以更加动态的方式分配空间。系统上运行的进程经常是成千上万的,但是内存却是有限的。于是,Linux必须高效的处理内存问题。在本节中,将介绍Linux内存架构、地址布局、以及Linux如何高效管理内存空间。
先简单总结下,如果内存有限的情况下,比如8G,你开启了大量的应用,势必会导致电脑卡顿,运行缓慢,甚至无反应的!
三、内存体系
3.1 物理和虚拟内存
现实中,我们经常会面临32位还是64位操作系统的选择(虽然现在32位已经基本淘汰了),对用户来说,它们间最大的差别是能否支持4GB以上的虚拟内存空间。站在性能的角度来理解32位和64位的系统,Linux映射物理内存到虚拟内存的区别是十分有趣的。如下图所示,可以明显看出内存映射方式在32位和64位系统上的区别。我们不去详尽探索物理内存映射到虚拟内存的细节,对于性能调优,我们只需要了解一下Linux的内存架构的一些知识就够了。
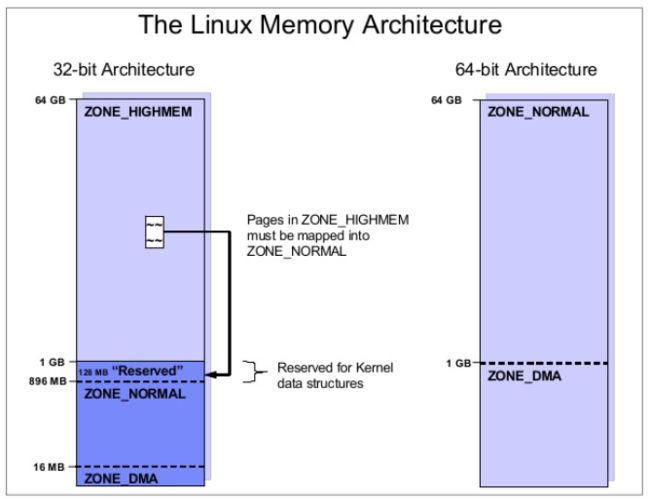
32位架构的机器上,Linux内核只能直接映射第一个GB的的物理内存(896M,因为还要考虑到保留的空间)。在此上的内存被称作ZONE_NORMAL,这部分空间必须映射到最下面的1GB。这种映射对应用程序是完全透明的,但是分配内存页到ZONE_HIGHMEM会造成一点
点性能损耗。
另一方面,在64位系统上,例如在IA-64上面,ZONE_NORMAL一直延伸到64GB或者128GB。如你所见,把内存页从ZONE_HIGHMEM映射到ZONE_NORMAL这种损耗在64位系统上是不存在的。
下图展示了32位和64位架构Linux系统的虚拟寻址布局:
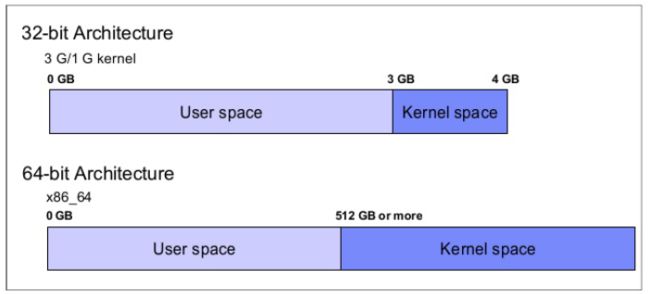
在32位架构上,单个进程可以利用的最大地址空间是4GB,这是受到了32位虚拟内存映射的限制。在标准的32位环境中,虚拟地址被划分为3GB的用户空间和1GB的内存空间,现实中也存在一些4GB/4GB地址布局。
再说64位架构,因为没有内存限制存在,每个进程能够都有可能使用巨大的地址空间。
3.2 虚拟内存管理器
由于操作系统把所有内存都映射成虚拟内存,所以,操作系统的物理内存架构对用户和应用程序通常都是不可见的。如果我们要掌握Linux内存调优的办法,就必须先理解Linux如何处理虚拟内存。如3.1所说的那样,应用程序不使用物理内存,而是向Linux内核请求一个特定大小的内存映射,并且收到一个虚拟内存的映射。如下图所示,虚拟内存不必要一定是物理内存的映射,如果某个应用程序使用了一块超大的虚拟内存,这虚拟内存其中某一部分可能是由磁盘上的swap空间映射来的。

从图中可以看出来,应用程序经常不是直接写入磁盘子系统,而是首先写入cache或者buffer,然后,在pdflush空闲的时候、或者某个文件大小超出buffer和cache的时候,由pdflush内核线程把buffer或cache中的数据写入磁盘。参考后面的写入脏buffer部分。
Linux内核管理磁盘缓存的方式,和内核写数据到文件系统的方式有紧密联系。和其它操作系统都只分配特定的部分内存作为磁盘缓存的方式相比,Linux处理内存资源更加高效。
虚拟内存管理器默认配置把所有的可用空闲内存空间作为磁盘缓存,所以,经常可以见到Linux系统明明拥有数GB级的内存,却只有20M处于空闲状态。
Linux同样高效利用swap空间,当操作系统开始使用swap空间的时候,并不表示系统出现了内存瓶颈,而是证明了Linux如何有效的使用系统资源。参考页帧回收(page frame
reclaiming)。
下面简单介绍下几个重要概念:
页帧分配(Page frame allocation)
页是物理内存或虚拟内存中一组连续的线性地址,Linux内核以页为单位处理内存,页的大小通常是4KB。当一个进程请求一定量的页面时,如果有可用的页面,内核会直接把这些页面分配给这个进程,否则,内核会从其它进程或者页缓存中拿来一部分给这个进程用。内核知道有多少页可用,也知道它们的位置。
伙伴系统(Buddy system)
Linux内核使用名为伙伴系统(Buddy system)的机制维护空闲页。伙伴系统维护空闲页面,并且尝试给发来页面申请的进程分配页面,它还努力保持内存区域是连续的。如果不考虑到零散的小页面可能会导致内存碎片,而且在要分配一个连续的大内存页时将变得很困难,这就可能导致内存使用效率降低和性能下降。下图说明了伙伴系统如何分配内存页:

如果尝试分配内存页失败,就启动回收机制。可以在/proc/buddyinfo文件看到伙伴系统的信息:

页帧回收
如果在进程请求指定数量的内存页时没有可用的内存页,内核就会尝试释放特定的内存页(以前使用过,现在没有使用,并且基于某些原则仍然被标记为活动状态)给新的请求使用。这个过程叫做内存回收。kswapd内核线程和try_to_free_page()内核函数负责页面回收。
kswapd通常在task interruptible状态下休眠,当一个区域中的空闲页低于阈值的时候,它就会被伙伴系统唤醒。它基于最近最少使用原则(LRU,Least Recently Used)在活动页中寻找可回收的页面。最近最少使用的页面被首先释放。它使用活动列表和非活动列表来维护候选页面。kswapd扫描活动列表,检查页面的近期使用情况,近期没有使用的页面被放入非活动列表中。使用vmstat -a命令可以查看有分别有多少内存被认为是活动和非活动状态:
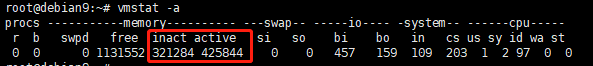
kswapd还要遵循另外一个原则。页面主要有两种用途:页面缓存(page cahe)和进程地址空间(process address space)。页面缓存是指映射到磁盘文件的页面;进程地址空间的页面(又叫做匿名内存,因为不是任何文件的映射,也没有名字)使用来做堆栈使用的。在回收内存时,kswapd更偏向于回收页面缓存。
如果大部分的页面缓存和进程地址空间来自于内存回收,在某些情况下,可能会影响性能。我们可以通过修改/proc/sys/vm/swappiness文件来控制这个行为:
![]()
swap分区
在发生页面回收时,属于进程地址空间的处于非活动列表的候选页面会发生page out。拥有交换空间本身是很正常的事情。在其它操作系统中,swap无非是保证操作系统可以分配超出物理内存大小的空间,但是Linux使用swap的空间的办法更加高效。虚拟内存由物理内存和磁盘子系统或者swap分区组成。在Linux中,如果虚拟内存管理器意识到内存页已经分配了,但是已经很久没有使用,它就把内存页移动到swap空间。
Page out和swap out:“page out”和“swap out”很容易混淆。“page out”意思是把一些页面
(整个地址空间的一部分)交换到swap;"swap out"意味着把所有的地址空间交换到swap。
复制代码
四、更通俗的理解
虚拟内存由物理内存和磁盘子系统或者swap分区组成。这话的意思是,物理内存,磁盘还有swap分区这些物理设备合在一起被抽象虚拟成了一个大内存,叫做虚拟内存。进程在虚拟内存上分配的地址会被映射道物理设备上,所以可能部分在物理内存,可能在swap分区,可能是磁盘上(个人理解)。
基于上述,有一下几点理解:
每个进程都有自己独立的4G内存空间而这4G内存空间只是虚拟内存空间,每次访问内存空间的某个地址,都需要把地址翻译为实际物理内存地址
一个新进程建立的时候,将会建立起自己的内存空间,此进程的数据,代码等从磁盘拷贝到自己的进程空间,哪些数据在哪里,都由进程控制表中的task_struct记录,task_struct中记录中一条链表,记录中内存空间的分配情况,哪些地址有数据,哪些地址无数据,哪些可读,哪些可写,都可以通过这个链表记录
所有进程共享同一物理内存,每个进程只把自己目前需要的虚拟内存空间映射并存储到物理内存上(参考3.1)。
进程要知道哪些虚拟内存地址上的数据在物理内存上,哪些不在,还有在物理内存上的位置,需要用页表来记录
页表的每一个表项分两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地址(如果在的话)
当进程访问某个虚拟地址,去看页表,如果发现对应的数据不在物理内存中,则缺页异常。缺页异常的处理过程,就是把进程需要的数据从磁盘上拷贝到物理内存中,如果内存已经满了,没有空地方了,那就找一个页覆盖,当然如果被覆盖的页曾经被修改过,需要将此页写回磁盘
五、下一节是???
谈完Linux的内存体系,下一节将会谈一下Linux的文件系统