AI圈真魔幻!谷歌最新研究表明卷积在NLP预训练上竟优于Transformer?LeCun暧昧表态...

作者 | 陈大鑫、琰琰
转自:AI科技评论
AI 圈太是太魔幻了!
众所周知,近一年来Transformer火的很,把Transformer用在视觉领域真是屡试不爽,先是分类后是检测,等等等等,每次都是吊打ResNet,在CV领域中大杀四方。
另外前些天AI科技评论报道的谷歌提出的一篇MLP-Mixer(谷歌最新提出无需卷积、注意力 ,纯MLP构成的视觉架构!)也是让人在调侃 MLP->CNN->Transformer->MLP 的魔幻圈难道要成真?
然而更加魔幻的事情发生了,以往CV圈的老大「卷积模型」今日竟然来反向偷袭NLP 领域了!
究竟发生了什么?
原来是谷歌近日在arxiv上放出了一篇名为《Are Pre-trained Convolutions Better than Pre-trained Transformers?》的论文,这篇论文大致是在讲卷积模型在预训练领域就不能比Transformers更好吗?
此论文一出,立马引起了图灵奖得主、CNN元老 LeCun的关注,他对此发声了,只不过这个 Hmmm 到底是什么意思呢?
是 「嗯」?还是「嗯....」 还是「呃。。。」?
究竟是支持还是讥讽呢?(真是大佬一笑生死难料啊)

值得一提的是,目前谷歌的这篇论文刚刚被 ACL 2021录用。
接下来就来看一下这篇论文具体讲了什么吧。
1
论文介绍和方法

论文地址:https://arxiv.org/abs/2105.03322
在预训练时代,Transformer架构与预训练语言模型之间似乎存在着牢不可破的联系。BERT、RoBERTa和T5等主流模型都采用了Transformers作为基础架构,可以说近两年几乎没有任何预训练的模型采用的不是Transformers。
事实上,语境表征学习有着丰富的历史。当前预训练的语言建模始于ELMo和CoVE等模型,这些模型主要采用循环架构(如LSTM),后来因为Transformers的出现,使用这些架构的研究逐渐减少。Transformers逐渐成为NLP社区的主流架构,这似乎被默认为是一种进步。
但是近几年的一些工作证明了完全基于卷积模型还是有前景的(Wu et al., 2019; Gehring et al., 2017),例如,在(Wu et al.,2019)中提出的卷积seq2seq模型在机器翻译和语言建模等一系列规范基准上都优于Transformers。
这些发现自然而然就会产生了一种质疑——我们是否应该偶尔脱离Transformers来考虑预训练模型?
卷积模型尽管在早期取得了成功,但它在预训练语言模型时代的相关性仍然是一个悬而未决的问题。据了解,卷积体系结构尚未在预训练微调范式( pretrain-fine-tune paradigm)下得到严格的评估。
那么,只有Transformers才能发挥出预训练的好处吗?
预训练卷积模型就一定比预训练 Transformers 差吗?
如果使用不同的架构归纳偏差,通过预训练是否也会有实质性的收益?
在特定情况下,预训练卷积是否会比Transformers更好?
本文针对以上这些问题进行了探讨,经过大量实验发现基于卷积的模型有诸多优点:首先,卷积不会受到自注意力二次记忆复杂性的影响——这一点很重要,因为它催生了全新类别的“efficient”Transformers架构。
其次,卷积只进行局部操作,它不依赖于位置编码作为模型的序列信号。但这也带来了一系列坏的影响,例如它无法访问全局信息,这意味着模型无法执行跨多个序列的交叉注意力,也因此涉及到时间序列和记忆的很多NLP任务它都不能处理。
为了了解卷积架构在预训练中的真正竞争力,本文提出了一个预训练的卷积Seq2Seq模型,其中每个卷积块可以表示如下:
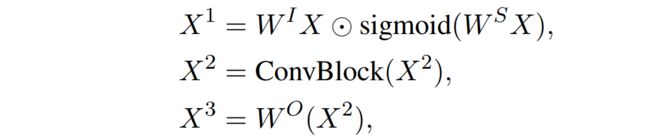
或者如下所示:

2
实验
类似于T5中采用的目标,研究人员使用基于span的Seq2Seq去噪目标来训练卷积模型,并评估了原始(无预训练)和预训练微调范式下的各种卷积变量(如扩张、轻量化、动态化等)。
通过对大量NLP任务的实验表明,在某些场景下,预训练卷积在模型质量和训练速度方面甚至优于预训练Transformers的SOTA性能。
下表是实验所使用的数据集以及在域、任务和标记数据量方面的具体情况。

基于以上数据集,下表是不同模型在toxicity检测、情感分类、新闻分类、query理解和语义分析等NLP任务中的实验结果,其中所有的模型都是12层的Seq2Seq架构,参数量都接近230M。
从下表2中不难看出卷积模型也能从预训练中受益、并且在有无预训练时都有强过Transformer的时候。

1、Toxicity 检测
如表2所示,在预训练和非预训练两种模式下,扩张卷积模型和动态卷积模型表现最佳。此外,所有卷积模型在Civil Comments和Wiki Toxic上都优于Transformers。
在预训练之前,卷积运算的性能要比Transformer高出约1.5个百分点。在预训练之后,差距有所缩小,Tranformers从Civil Comments数据集上的卷积预训练中获得更好的增益(例如,从+5.1%到+4.3%)。不过,Wiki Toxic数据集上的情况恰恰相反——它是唯一一个在预训练后出现性能下降的情况。总的来说,在这项任务中,卷积的性能要优于Transformers。
2、 情感分类
如表2所示,在IMDb评论数据集上,表现最佳的非预训练模型是轻量级卷积模型,性能优于Transformer。表现最佳的预训练模型是Transformers模型,不过,所有卷积模型与预训练的Transformers的差距都不到一个百分点。此外,在SST-2和S140任务中,无论是否经过预训练,表现最佳的模型都是卷积模型。
3、问题分类
在非预训练模型中,轻量级卷积模型表现最佳。在预训练模型中,卷积模型的性能也优于预训练的Transformers。在这项任务中,虽然大多数模型从预训练中获益,但Tranformers似乎从预训中获益更多。
4、新闻分类
新闻分类的实验结果似乎同样遵循了其他基准的趋势,即无论是在非预训练还是预训练的设置中,卷积模型都优于Transformers,其中预训练的最大增益来自于扩张卷积模型。
5、合成泛化(Compositional Generalization )和语义分析
语义分析和合成泛化任务被构造为序列生成任务。在分布测试集中,Transformers和卷积具有相同的性能(95%)。在超出分布测试集中,Tranformers的性能为77.5%,而卷积为76.9%。虽然卷积并不完全优于Tranformers,但二者微小的差距足以证明卷积的竞争力。
以上实验结果表明;
(1)未经预训练的卷积要优于未经预训练的Transformers;
(2)在七项任务中有六项证实,经过预训练的卷积优于预训练的Transformers。
(3)卷积同样能够从预训练中受益,而不是Tranformers模型所独有。
(4)在预训练的卷积模型中,扩张卷积和动态卷积通常比轻量级卷积好。
(5)模型如果在非预训练情况下表现良好,其在预训练之后表现不一定最好(反之亦然)。这一点说明通过预训练构建体系架构确实会对模型性能产生影响,但这也意味着,除了将体系架构与预训练方案结合之外,还需要注意不同的体系架构在预训练下的行为可能不同。
3
讨论与分析
为了提供一个平衡的视角,在本篇论文中,研究人员还进一步讨论了预训练卷积的优缺点,包括它可能不合适的场景,以及其性能表现对更广泛的社区的影响。
在以上实验中,预训练卷积存在一个明显缺点,即缺乏交叉注意力归纳偏差(cross-attention inductive bias),这种偏差是在Transformers编码器中通过自注意力产生的,因此,如果需要对两个或多个序列之间的关系进行建模,使用预训练的卷积并不是一个好的方法。
为了验证这一点,研究人员在SQuAD和MultiNLI基准上进行了实验,他们发现仅缺少偏置,卷积就不能达到与Transformers相当的效果。如在初步评估中,预训练的卷积在MultiNLI上的精度为75%,而Tranformers为84%。另外,Transformers在 SQuAd中达到90%精度时,卷积仅为 70%.
不过,该实验结果仅说明了交叉注意力特性对卷积的影响。如果在编码器处用一层交叉注意力来增强卷积,预训练的卷积很接近Transformers在MultiNLI上的实验结果(83%的精度)。
此外,研究人员还发现在扩大规模时,连接句子对的模式是不必要的,因为这需要对句子对的排列进行推断。相比之下,采用快速嵌入空间查找双编码器(dual encoder)的方式在实践中更为可行。鉴于卷积在一系列编码任务中的强大性能,可以期望预训练的卷积也能够在双编码器设置中表现良好。
与Transformers相比,预训练卷积模型有什么好处?
卷积运算速度更快,可更好地扩展到长序列。
下图为序列到序列任务中,卷积(LightConvs)相对于Transformers的训练速度(输入长度在{64、128、256、512、1024、2048、4096}之间的变化)。
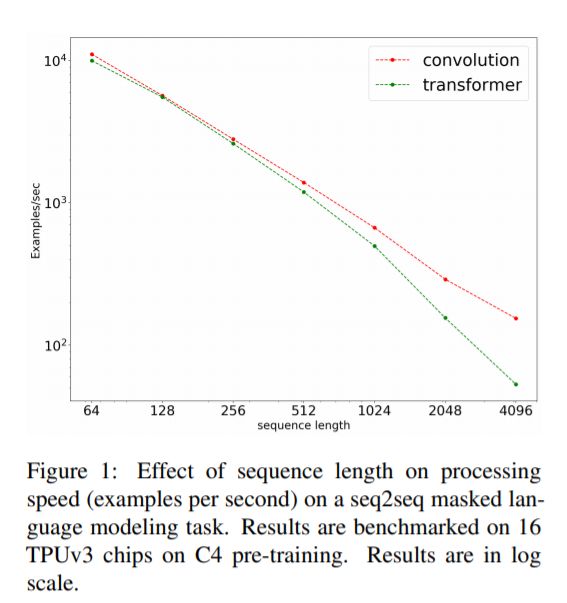
这一结果证明了卷积不仅更快(即使在较短的序列中),而且比Tranformers的可扩展性更好。卷积可以线性扩展,而Tranformers不能扩展到更长的序列。
卷积模型有高效的FLOPS
下图为随着序列长度的增加,卷积与Transformers的FLOPS数量的变化,一般来说,在所有序列长度上,卷积在浮点运算的数量上更高效。从图中可以看到,卷积在固定时间和FLOPs时都要更快。
此外,卷积的FLOP效率在序列长度上具有更好的伸缩性。

卷积是否可以完全取代Tranformers?
虽然Transformers在NLP领域占据主导地位,但本篇论文证实了卷积在模型质量、速度、FLOPs和可扩展性等方面都有不可忽视的价值。更重要的是,论文中还证实了卷积能够从预训练中受益,并达到与Transformer相当,甚至更优的性能。
不过,作者也强调经过预训练的卷积无法处理需要交叉注意力的任务,或者需要在同一序列中建模长度大于1的句子或文档。
论文中表示,如何平衡二者的优缺点,相信实践者有更好的选择,但在成熟的Transformer模型之外探索其他架构的可能性是值得鼓励的。
不要把预训练和体系架构的进步混为一谈
在本文中,作者没有将预训练与体系架构的进步结合在一起,而是展示了另外三种基于卷积的体系结构(如轻量级、动态和可扩展),并证实了它们也能够从预训练中获益,并在程度上与Tranformers模型一致。在当前的研究领域中,预训练总是与Tranformers架构紧密耦合在一起。因此,BERT、Transformers和大型语言模型的成功经常被混为一谈。
诚然,到目前为止,大规模预训练应用到的唯一成功的就是Transformers模型,但这并不意味着其他体系架构没有可能。
基于实证研究结果,研究者表示人们对于体系架构和预训练的组合的理解仍有很大的提高空间。
相信本篇论文影响的不仅仅是卷积模型在自然语言处理中的竞争力,更重要的是,在探索架构替代方案时,我们应该有一个更开放更乐观的态度。
最后,大家对这篇论文怎么看呢?
参考链接:
https://twitter.com/ylecun/status/1391591572580585475
重磅!DLer-CVPR2021论文分享交流群已成立!
大家好,这是CVPR2021论文分享群里,群里会第一时间发布CVPR2021的论文解读和交流分享会,主要设计方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

???? 长按识别,邀请您进群!