【3数据可视化】基于vue的动态数据低代码可视化实现
目录
1、数据科学的产业升级
2、数据可视化的痛点
2.1 数据分析师
2.2 想提升的非技术人员
3、数据可视如何简单化
3.1 数据部分
3.1.1 代码需求
3.1.2 无代码需求
3.2 图表部分
3.2.1 代码需求
3.2.2 无代码需求
4、动态数据的低代码实现
4.1 连接mongodb
4.2 添加数据
4.3 查询数据
4.4 修改数据
4.5 图表-获取和刷新数据
5、数据可视化的意义
6、注释
[1]Ofter数据平台
[2]V-charts图表类型
1、数据科学的产业升级
随着科技的发展,产业升级成功的一个重要标志是:工作任务能够“螺丝钉化”,而在这个过程中,需要把一个项目中的任务合理地拆分成耦合程度最小的单元。比如数据科学,如果有一天在各行业数据采集、处理、可视化、分析、安全等每一项任务能够由专门的小组来完成(每一项工作将做得更出色),而不是由一个人把这些工作都做了的话,那么数据科学领域的产业升级可以说是成功的。
ofter今天以数据可视化为例,来讲讲如何把数据可视“螺丝钉化”,未来我们还可以衍生到数据科学。
2、数据可视化的痛点
目前,有2类人正在或迫切需要学习和使用数据可视化。
2.1 数据分析师
分析师通常都有量化分析的背景,但很少受过设计方面的专业训练,虽然能够胜任数据分析的其他环节(获取数据、清洗整理数据、分析数据、建立模型),但在最终的展示沟通上力不从心,而展示恰恰是整个数据分析流程中最终受众能够接触到的唯一环节。因此,对于分析师来说,只需要找一个易用的图表工具。
2.2 想提升的非技术人员
无论是销售、产品、财务、采购,还是其他岗位,其实数据可视化的迫切性并不比分析师低。从以下例子可以看出,他们需要的是易用的数据工具和图表工具。
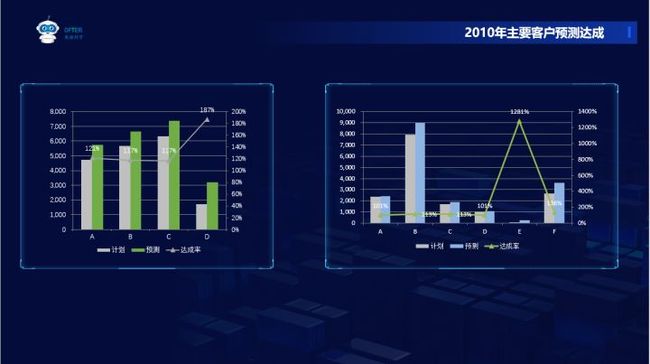
例子1:ofter几年前做过业务,每个月需要向总经理汇报业务情况,当时采用的是excel汇总统计的方式,站在个人角度看,最大的痛点是数据部分,因为我们都是每个月各销售维护自己的客户数据,在excel上维护经常会出现打架的问题,每次做图表时我还要去汇总这些数据,经过那么多人的协同作业,效率反而低下,也容易出错。通常是大家经过8个小时的汇总、核对数据,最后得到了如下图的2张图表,然后在销售会议上汇报一下就扔回收站了。
3、数据可视如何简单化
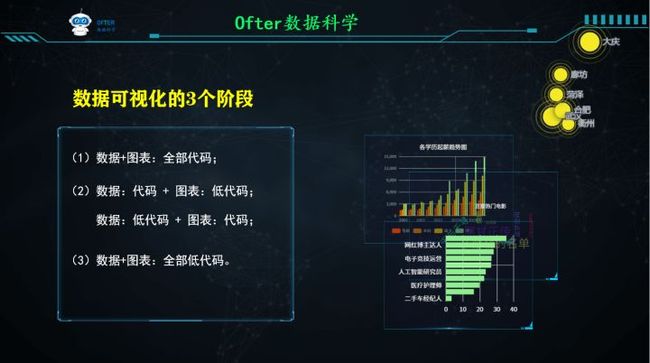
数据可视化是一项涉及数据和图表的工作,ofter将动态数据可视简单化过程主要分为3个阶段。
(1)数据+图表:全部代码;(完全自定义)
(2)数据:代码 + 图表:无代码;数据:无代码 + 图表:代码;(图表前端编写代码,可以自定义图表类型和样式)
(3)数据+图表:全部无代码。(数据、图表类型、样式等需提前封装)
3.1 数据部分
ofter认为目前市面上的平台更多注重了图表功能的开放,而数据部分功能很鸡肋(主要指付费平台),他们提供了excel上传、api接口、数据库连接、静态json数据集之类获取数据的功能。
对于第(2)类大多数非技术人员来说,api接口、连接数据库、静态json数据集是需要付出很多时间和精力才能使用的功能,而这个excel上传只能一次性使用,无法线上协同修改数据,图表中的数据也是无法动态和实时更新。当然他们的目标群体本来就不是普通大众。
3.1.1 代码需求
一般企业/组织的数据都是结构化和标准化的,因此采用关系型数据库SQL比较普遍,需要在SQL中先建立数据库表和列名,表之间的关系也需要提前定义,这就需要比较好的逻辑能力。
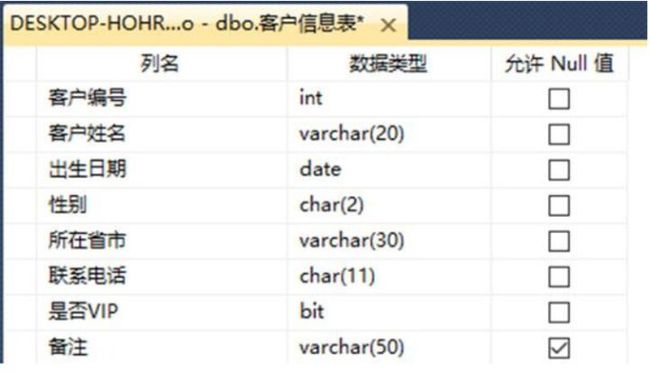
然后在编译工具中编写从数据库取数的代码,将数据用于图表的展现。

from pyecharts import options as opts
from pyecharts.charts import Bar,Page
import pymysql
from operator import itemgetter
def bar(cos): #柱状图
costomer = list(map(itemgetter(0), cos))
quantity = list(map(itemgetter(1), cos))
c = (
Bar(init_opts=opts.InitOpts(bg_color="white"))
.add_xaxis(costomer)
.add_yaxis("订单数量", quantity)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts("客户订单数量"),
datazoom_opts=opts.DataZoomOpts(is_show=True,range_start=0,range_end=100),
toolbox_opts=opts.ToolboxOpts(orient="vertical",pos_left="90%",feature=opts.ToolBoxFeatureOpts(data_zoom=opts.ToolBoxFeatureDataZoomOpts(is_show=False)))
)
)
return c
db = pymysql.connect(host="localhost", user="root", password="123456", database="warehouse_input")
sql = "select customer_name,sum(cloth_quantity) AS nums from po GROUP BY customer_name"
try:
cursor = db.cursor()
cursor.execute(sql)
cos = cursor.fetchall()
except Exception as e:
db.rollback()
print('事物处理失败',e)
else:
db.commit()
print('事物处理成功',cos)
cursor.close()
db.close()
page = Page()
page.add(
bar(cos)
)
page.render("bar.html")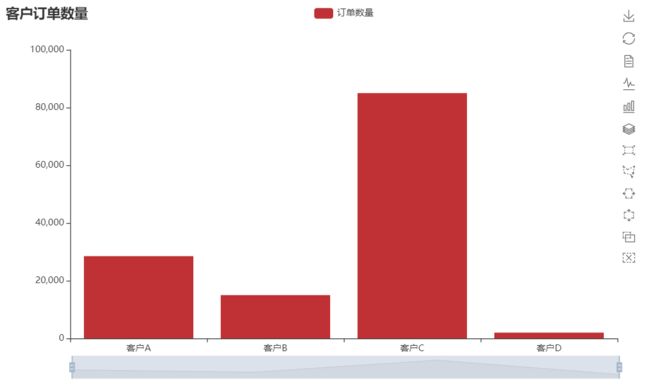
3.1.2 无代码需求
当我们需要呈现不同数据的时候,如果采用关系型数据库,势必需要维护数据库和编写代码。当非关系型数据库NoSQL出现后,这就不是问题了,常见的需求如数据可查询、添加、编辑、删除、导入、导出。
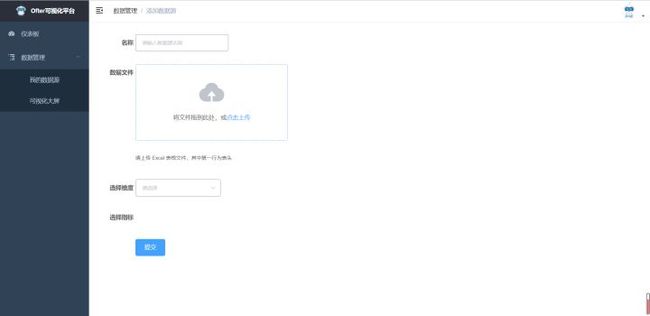
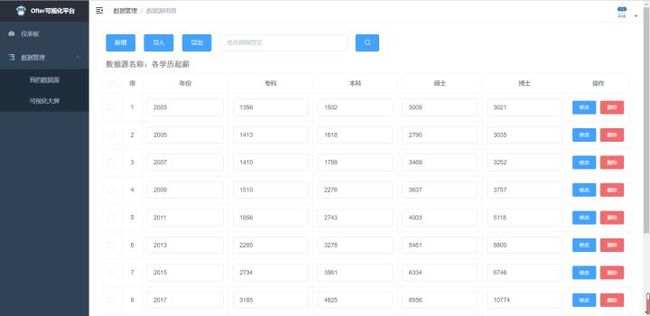
对于操作者来说,只需要将excel数据初始化上传至系统中,系统会自动解析列名和数据,可以参考ofter数据平台[1]:
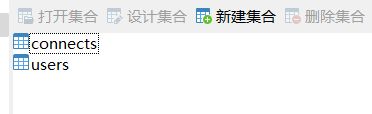
而且非关系型数据库中的数据库表也很干净,除了用户管理表users,就是数据源的表connects。
3.2 图表部分
3.2.1 代码需求
目前,绘制图表的库非常多,对于高度定制化的图表,这些库将帮助开发者减少很多时间。
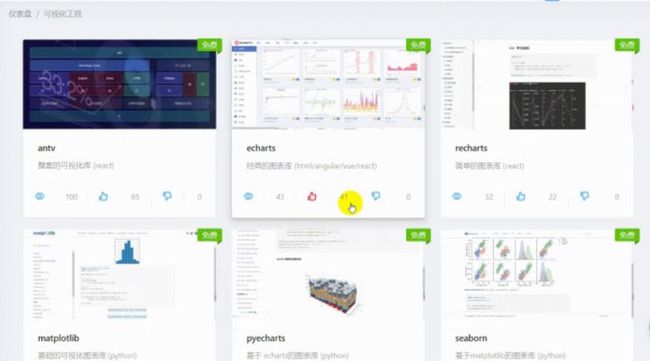
常用图表库如下:
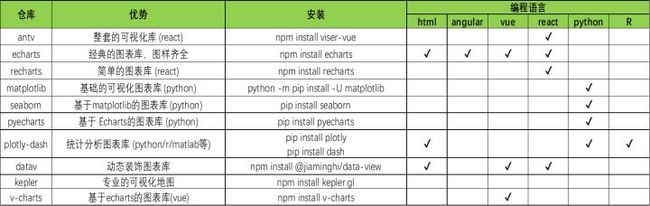
为了让开发图表变得越来越便捷,这些图表库的开发人员也是煞费苦心。如果我们觉得echarts这种大而全的库太繁杂,我们可以选择基于echarts的其他库,其中最典型的当属v-charts[2],一行代码就可以绘制可视化图表。
template部分(一行代码):
script部分(静态数据):
运行结果:

如果我们希望把图表绘制得更漂亮些,比如下图这样:
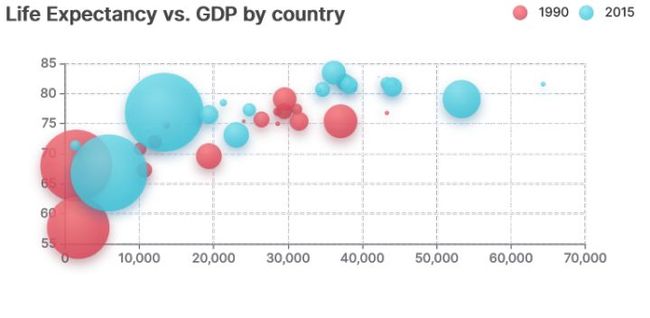
我们需要做的也就是添加下配置项:
textStyle: {
fontFamily: 'Inter, "Helvetica Neue", Arial, sans-serif'
},
title: {
text: "Life Expectancy vs. GDP by country"
},
legend: {
right: 10,
data: ["1990", "2015"]
},
xAxis: {
splitLine: {
lineStyle: {
type: "dashed"
}
}
},
yAxis: {
splitLine: {
lineStyle: {
type: "dashed"
}
},
scale: true
},
...
3.2.2 无代码需求
普遍的图表需求不外乎:
- 常用的图表库:折线图、柱状图、条形图、表格、饼图、排名图等;
- 图表样式可自定义:文字、颜色、标题、图例等;
- 组件丰富:可编辑的文字、边框、背景、动态的图表。
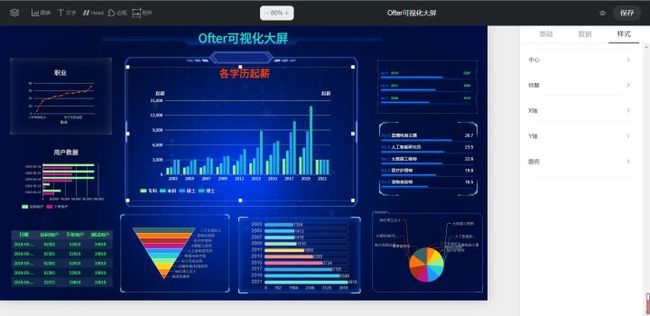
对于常规的图表需求,无代码图表平台可以很大程度上提高操作的便捷性,但是个性化的数据、图表需求让无代码平台变得不那么智能,二次开发的工作量甚至大大超过了自定义代码编写图表。ofter也会开发一些大屏模板:
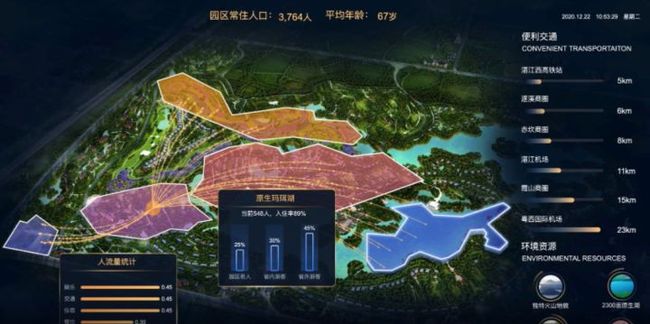
这样的模板,看起来确实充满科技感,但是复用性极低。除了自己练手和赏心悦目以外,它就是个成功的落灰案例。
4、动态数据的低代码实现
以js+mongodb为例,我们需要实现数据的添加、查询和修改。当然也可以使用python+mongodb等,自由选择。
4.1 连接mongodb
// 连接数据库
mongoose.connect("mongodb://localhost:27017/diagramData", { useNewUrlParser: true }, err => {
if (err) {
console.log('[server] MongoDB connect error: ' + err);
} else {
console.log('[server] MongoDB connected!');
}
});
在这里需要注意数据库的安全,我们需要做以下几件事:
- 服务器的入向规则,千万不要bind 0.0.0.0,使用后要及时禁用,很容易遭受勒索病毒的侵袭;
- mongodb.conf配置中,保持bind_ip = 127.0.0.1,不要改为0.0.0.0;
- 在以上两条基础上,最好设置下auth=true,设置授权用户和密码。
4.2 添加数据
// 新增excel数据源
router.post('/', async (ctx, next) => {
const body = ctx.request.body;
if (!body.name || !body.data) {
ctx.body = {
errno: 1,
errmsg: '格式错误'
}
return;
}
const result = await connectModel.create({
name: body.name,
data: body.data,
uid: body.uid,
});
ctx.body = {
errno: 0,
data: result
}
});
// 添加单条数据
router.post('/:id', async (ctx, next) => {
const body = ctx.request.body;
if (!body.data) {
ctx.body = {
errno: 1,
errmsg: '格式错误'
}
return;
}
const result = await connectModel.updateOne({_id: ctx.params.id}, {$push: {'data.rows': body.data}})
ctx.body = {
errno: 0,
data: result
}
});
4.3 查询数据
// 获取全部数据源列表
router.get('/', async (ctx, next) => {
const rows = await connectModel.find({ 'uid': ctx.request.query.uid }).select('-data');
ctx.body = {
errno: 0,
data: {
connectList: rows
}
}
});
// 获取某一数据源详情
router.get('/:id', async (ctx, next) => {
const item = await connectModel.findById(ctx.params.id);
ctx.body = {
errno: 0,
data: item
}
});
4.4 修改数据
// 修改数据
router.put('/:id/:index', async (ctx, next) => {
const body = ctx.request.body;
const rowIndex = ctx.params.index
const result = await connectModel.updateOne({_id: ctx.params.id}, {$set: {['data.rows.'+rowIndex]: body.data}})
ctx.body = {
errno: 0,
data: result
}
});
4.5 图表-获取和刷新数据
当我们完成了数据部分,图表部分获取数据将变得非常方便。只要复制数据源的id,经过getDataItem函数的处理,我们就可获取到数据库中的数据。另外,图表会按我们定义的时间1000 * 3600(3600s)自动刷新数据和更新图表。
getDataItem代码:
export function getDataItem(id) {
return request({
url: '/connect/' + id,
method: 'get',
params: { }
})
}
图表代码:
运行效果:

5、数据可视化的意义
最后,我们一定要不断审视数据可视化的目标:
- 如何让数据可视起到驱动决策的作用;
- 如何让数据可视做得越来越简单。
“数据将取代石油,成为新时代最重要的资源。”当数据可视化成为一项普适技能时,ofter相信我们的产业必定已经跨上了一个台阶。当下我们对智慧XX大屏的投入不小,那它是如何起到数据驱动决策,又是如何做得简单化的?

6、注释
[1]Ofter数据平台
体验地址:http://124.71.111.155/
用户密码:ofter / Ofter_123
备注:因为不希望删除功能影响可视化大屏的效果呈现,已把删除功能抹掉了。
[2]V-charts图表类型
VeBar,
VeLine,
VeHistogram,
VePie,
VeRing,
VeWaterfall,
VeFunnel,
VeRadar,
VeChart,
VeMap,
VeSankey,
VeHeatmap,
VeScatter,
VeCandle,
VeGauge,
VeTree,
VeLiquidfill,
VeWordcloud