【1数据采集】数据爬虫的完整学习路径
必读:数据道德与法规
无论出于什么目的,需要采用数据爬虫或类似的技术,请务必首先阅读和严格遵守《中华人民共和国数据安全法》以及相关的法律法规。另外,法规中的未尽之处,也请出于社会道德风尚,谨慎行事,切不可利用潜在漏洞和技术手段,影响组织或个人的正常工作和生活。

1、爬虫的基础知识

1.1 什么是爬虫
一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
1.2 爬虫架构
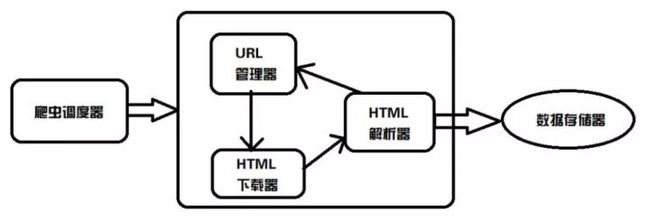
主要由五个部分组成:爬虫调度器、URL管理器、网页下载器、网页解析器、数据存储器(应用程序)。
1.3 python十大常用爬虫框架
- scrapy:提取结构性数据而编写的应用框架。
- PySpider:带有强大的WebUI,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优先级等。
- Crawley:可以高速爬取对应网站的内容,支持关系和非关系数据库,数据可以导出为JSON、XML等。
- Portia:不需要任何编程知识的情况下爬取网站,简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
- Newspaper:可以用来提取新闻、文章和内容分析。使用多线程,支持10多种语言等。
- Beautiful Soup:可以从HTML或XML文件中提取数据,获取html元素的常用库。
- Grab:可以处理数百万个网页的复杂异步网站抓取工具。
- Cola:分布式的爬虫框架,对于用户来说,只需编写几个特定的函数,而无需关注分布式运行的细节。任务会自动分配到多台机器上,整个过程对用户是透明的。
- Selenium:自动化测试工具,支持多种语言开发,比如 Java,C,Ruby,python等等。
- Python-goose:可提取的信息包括:文章主体内容、主要图片、文章中嵌入的任何Youtube/Vimeo视频、元描述、元标签。
2、爬虫进阶之路
数据爬虫从技术的复杂性来看,可以粗略分为3个阶段:入门、中级、高级。
2.1 入门
1)网络基础:tcp/ip协议、socket网络编程、http协议;
2)web前端:HTML, CSS, JavaScript, DOM, Ajax, jQuery, json 等;
3)正则表达式:能使用正则表达式提取网页中的信息;
4)HTML解析:beautifulsoup,xpath和css选择器;
5)HTML下载:urllib, requests进行简单的数据抓取;
6)其他常识:python等编程语言语法,数据库知识。
入门的实战可参考:1896-2021历届奥运会奖牌动态排序动画(Python数据采集)_Ofter数据科学的博客-CSDN博客阅读本文大约需要 5 分钟摘 要通过前4篇数据分析文章的讲解,本周开始OF要为大家带来数据分析的实战。实战的选材呢,OF是随机选取的,如果大家有什么想要分析的难题,可以私信沟通。本来想从网上直接下一份历届奥运会的奖牌数据进行动态呈现(包括1896-2021各届、年份、国家/地区、金牌、银牌、铜牌、合计、排名),说来也奇怪,在网上竟然找不到能满足这些条件的,最多能找到1896-2012的数据,但是也不全。没办法了,只能自己去爬虫采集数据啦,当然建议大家有现成数据的还是不要花费这时间.https://blog.csdn.net/weixin_42341655/article/details/119961749?spm=1001.2014.3001.5501
2.2 中级
1)模拟登录:会使用MD5,Hash等加解密算法,设置代理user-agent和Nginx协议,模拟post/get请求,抓取客户端cookie或session登录;
2)验证码识别:包括最基本的验证码识别,比如ocr识别,对于复杂的验证码需要会调用第三方服务;
3)动态网页分析:使用selenium+phantomjs/chromedriver抓取一些动态网页信息;
4)多线程和并发:线程间通信和同步,以及通过并行下载加速数据爬取;
5)ajax请求数据:使用抓包工具捕获ajax请求对应的数据包,从数据包中提取url和对应的请求参数,请求的发送(处理参数),获取json格式响应数据 response.json()。
2.3 高级
1)机器学习:使用机器学习应对一些反爬策略,避免被封禁;
2)数据存储:使用常用的数据库进行数据存储,查询,并通过缓存避免重复下载的问题;
3)分布式爬虫:使用一些开源框架如scrapy,scrapy-redis,部署分布式爬虫进行大规模数据爬取;
4)其他相关应用,如移动端数据的爬取,监控和运维爬虫......
3、爬虫的难点
数据爬虫最大的难点在于爬和反爬的博弈过程,当我们开发出一门爬取技术,就会有对应的反爬策略应运而生,然后再研究出新的爬取手段,周而复始。当然,对于正常的爬取,也会有比较复杂的过程存在:进程与线程、断点续爬、分布式、爬虫监控、异常通知。
