Python写网络爬虫(一)
文章目录
-
- 网络爬虫简介
- 爬虫在使用场景中的分类
- 爬虫的矛与盾
- 需要知道的协议
- 常用请求头信息
- 常用响应头信息
- requests模块
- 如何使用requests:(requests模块的编码流程)
- 新手实战演练
- 正式入门爬虫
- get 方法的常用参数:
- 简易网页采集器
首先,在学习网络爬虫之前,需要先了解它是什么!
网络爬虫简介
网络爬虫:web crawler(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
上面这些都是百度百科晦涩难懂的官话,用我们自己的话来说,
爬虫就是:通过我们自己编写的程序,模拟浏览器上网,然后让其去互联网抓取我们想要的数据的过程。
爬虫在使用场景中的分类
- 通用爬虫:
抓取系统的重要组成部分。即抓取互联网中一整张页面数据。 - 聚焦爬虫:
建立在通用爬虫的基础之上。抓取的是页面中特定的局部内容。
PS:先用通用爬虫爬取一整张页面信息,再用聚焦爬虫抓取局部内容。 - 增量式爬虫:
检测网站中数据更新的情况。即只会抓取网站中最新更新出来的数据。
爬虫的矛与盾
- 反爬机制(盾):
门户网站可以通过制订相应的策略和技术手段,防止爬虫程序进行网站数据的爬取。 - 反反爬机制(矛):
爬虫程序可以制订相关的策略和技术手段,破解门户网站中具备的反爬机制,从而可以获取门户网站中相关的数据。
需要知道的协议
-
robots.txt协议:
君子协议。规定了网站中哪些数据可以被爬虫爬取,哪些不能。
(额 但实际上想爬就爬了,拦不住。但人要有道德!,也要谨防进橘子)这个是某网站的robots.txt协议的规定

-
http协议:
通俗来说就是 服务器和客户端进行数据交互的一种形式 -
https协议:
简单说就是 安全的http(超文本传输)协议
常用请求头信息
-
User-Agent:
请求载体的身份标识
(请求载体:当前浏览器;身份标识:操作系统版本,当前浏览器版本等信息)
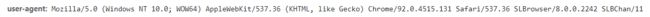
-
Connection:请求完毕后,是断开连接(close)还是保持连接(keep-alive)

常用响应头信息
- Content-Type:
服务器响应回客户端的数据类型
requests模块
Python中原生的一款基于网络请求的模块,功能非常强大,简单便携,效率极高。
作用:
模拟浏览器发请求。
以上就是我们在学习爬虫之前需要了解的内容
接下来我们正式进入爬虫领域
首先思考我们自己上网的步骤:
第一步:打开浏览器
第二步:在浏览器中录入网址
第三步:回车
最后就会得到我们想找的网址
但其实回车后会先对指定网址发送http或https请求,请求成功后才会获得对应的响应数据,即我们想找的页面。
通过我们自己的上网行为即可初见requests的使用方式。
如何使用requests:(requests模块的编码流程)
- 指定url (网页地址,即网址)
- 发起请求 (http/https请求,输网址按回车后计算机干的事)
- 获取响应数据 (页面打开了)
- 持久化存储 (把爬取到的数据存储到本地或数据库中)
用requests之前要先进行环境安装:
pip install requests
或
在PyCharm中 File --> Settings --> Project --> Interpreter -->点击+即可添加
话不多说,上代码!
新手实战演练
# 我的第一个爬虫程序
import requests
url = "https://www.csdn.net/" # step 1:指定url
response = requests.get(url) # step 2:发起请求,get方法会返回一个响应对象
page_text = response.text # step 3:获取响应数据,text返回的是字符串形式的数据
with open('CSDN.html', 'w', encoding='utf-8') as f: # step 4:持久化存储
f.write(page_text)
print('爬取数据结束')
下面是爬取结果

这样我们就得到了CSDN网页的源代码
接下来我们逐个解析上面的代码:
-
URL 等于的是我们要爬取的网页地址
-
我们看到

网页请求方式(Request Method)是GET类型,那么我们在用requests模拟浏览器请求时也要用get请求!!!
那么,requests.get(url)就是向指定的url发送请求。
用response接收请求成功后返回的响应对象,即 response = requests.get(url) -
response是响应对象,它也有属性 — text 。这个text会返回一组字符串,这组字符串就是我们想要 拿到的响应数据,即网页的html源码数据。
所以 response.text 就是网页的源码数据 ,把这组数据返回给 page_text 这个变量,就是
page_text = response.text 的意思 -
持久化存储
with open('CSDN.html', 'w', encoding='utf-8') as f: # step 4:持久化存储
f.write(page_text)
把爬取到的数据存入.html文件中
 这样,一个最简单的爬虫就完成了!
这样,一个最简单的爬虫就完成了!
正式入门爬虫
刚才写的那个爬虫呀 不太完整,为什么呢?这就不得不提到我们的UA检测了
反爬策略—UA检测:
门户网站的服务器会检测对应请求的载体身份标识,如果检测到请求的载体身份标识为某一款浏览器,说明该请求是一个正常的请求。但如果检测到请求的载体身份标识不是基于某一款浏览器的,则表示该请求为不正常的请求(爬虫),那么服务器端会拒绝该次请求。
对于UA检测爬虫就毫无办法了吗?nonono
反反爬策略—UA伪装:
让爬虫对应的请求载体身份标识伪装成某款浏览器。
做法:将对应的 user-agent 封装到字典中

在开发者工具(F12)中找我们需要的 user-agent
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (HTML, like Gecko) Chrome/84.0.4147.89 '
'Safari/537.36 SLBrowser/7.0.0.12151 SLBChan/30 '
}
通过UA伪装,爬虫才能更好的爬取网页数据。UA伪装必不可少!!!
get 方法的常用参数:
requests.get (url , params , headers)
- url参数 是网址
- headers参数 是头请求
- params参数 设定好后,网页会和 params 通过 get 方法自动拼接
params = {
'看网页搜索的具体参数': '参数的值'
}
简易网页采集器
先上代码
import requests
url = 'https://www.so.com/s?' # 处理url携带的参数
head = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 '
'Safari/537.36 SLBrowser/7.0.0.12151 SLBChan/30 '
}
select = input('请输入想搜索的关键字:')
param = {
'q': select,
'src': 'srp'
'fr': 'none'
'psid': 'f2641bdd48089a579ce6697ac9e1f467'
}
response = requests.get(url, params=param, headers=head, verify=False)
page_text = response.text
FileName = select + '.html'
with open(FileName, 'w', encoding='utf-8') as f:
f.write(page_text)
print('爬取数据完成!!!')
这是我选择的网址
https://www.so.com/s?ie=utf-8&fr=none&src=home-sug-store&nlpv=basezc&q=%E5%91%A8%E6%9D%B0%E4%BC%A6
我们首先要知道,?后面那一堆都是参数,参数我们可以通过get方法与url拼接,所以在写url时要把它删掉,所以 url = ‘https://www.so.com/s?’
往下是headers头请求不用多说,每个爬虫程序都要写!
再往下就该处理参数了,我是怎么知道这些参数的呢?还得借助 F12 !

这些就是我们需要的参数了。咦,有没有感觉很熟悉呢?
没错,它们就是刚刚删除?后的乱码。
https://www.so.com/s?ie=utf-8&fr=none&src=home-sug-store&nlpv=basezc&q=%E5%91%A8%E6%9D%B0%E4%BC%A6
这下发现了吧(额,这张图是我后来截的,参数变了,和写代码时不一样了,不过不影响运行,因为影响结果的参数q没变化。至于参数为什么会变,就要到计网里找答案了)
我们把参数封装在一个字典里,就成了这个样子
param = {
'q': select,
'src': 'srp'
'fr': 'none'
'psid': 'f2641bdd48089a579ce6697ac9e1f467'
}
但我想要实现动态查询,即输入什么查询什么,所以我不把参数 ‘q’ 写死,而是用了个变量 select 作为 ‘q’ 的值。
接下来按部就班:
- 发起请求
- 获得响应数据
- 持久化存储
就OK了 ,是不是很简单呢
运行结果:

需要注意的是,有些电脑缺少证书,请求时就要加上 verify=False
我身边人都不用,就我用
最后,感谢铁甲小宝同学对我的指导,他是我学习的领路人,未来继续跟大佬学习
