PIE Engine机器学习遥感影像监督分类全流程(附源码)
目录
一、介绍
1.遥感影像分类概念
2.PIE Engine机器学习简介
二、数据准备
1.矢量行政边界数据
2.遥感影像数据
3.样本数据
①样本点导入并可视化
②样本点采样
②样本点划分
三、模型构建及训练
1.分类模型选择
2.模型训练及精度评价
四、分类结果可视化
1.图例配色
2.分类影像配色
五、面积统计
1.饼图面积统计
2.饼图可视化地物面积
3.分类结果保存
六、结论
在本文中,你将学到:
1.矢量数据与栅格数据的调用
2.分类模型的选择
3.分类模型的构建与训练
4 分类结果可视化
5 分类面积自动统计
一、介绍
1.遥感影像分类概念
遥感图像分类是遥感图像信息处理中最基本的问题之一,其分类技术是遥感应用系统中的关键技术,分类方法的精度直接影响到遥感的应用发展。
遥感影像与普通图像主要有以下区别:
1 像素多 意味着体量大,一景(影像的单位)往往在500MB--10GB,甚至更多。
2 波段多 普通图片是R,G,B三个波段,而遥感影像从1-100个波段,有的甚至有几千个波段,意味着包含的信息也很多。
3 内容不同 普通的图片一般是生活中常见的事物,而遥感影像则是从卫星角度出发拍摄的地表图片,是不同地物的综合体现。
4 格式不同 普通的图片往往是JPEG、PNG等格式,而遥感影像常常是TIFF格式。

遥感影像的本质就是图片,即图像分类也适用于遥感影像;医学影像同理。
因此,读者可以把遥感影像机器分类看作是图像分类下的一个子集。理解了图像分类与遥感的关系后再学习遥感影像分类就会轻松很多。
2.PIE Engine机器学习简介
在前文中,我已经介绍了PIE Engine平台的基本界面,这里我梳理一下该平台提供的机器学习算法,在PIE Engine的帮助文档里,我们可以清晰的看到:

平台提供了三种机器学习监督分类方法:
1 正态贝叶斯 可以处理特征值是连续数值的分类问题
2 随机森林 具有很高的预测准确率,对异常值和噪声具有很好的容忍度,且不容易出现过拟合
3 支持向量机 在解决小样本、非线性和高维模式识别的问题中表现出了许多特有的优势,并能在很大程度上克服“维数灾难”和“过学习”等问题。
本文暂只考虑监督分类,非监督分类将在之后的文章中更新。
二、数据准备
1.矢量行政边界数据
本文采用兰州市城关区的行政区划作为矢量边界,因为按name属性检索,中国有多个城关区。因此这里我使用自己上传的矢量边界数据。输入以下代码并运行:
var roi = pie.FeatureCollection("user/qianyouliang/chengguan").first().geometry();//调用上传的矢量边界数据
Map.centerObject(roi, 12);//显示界面定位至研究区,放大等级为12级
Map.addLayer(roi, { color: "red", fillColor: "00000000", width: 2 }, "研究区范围");//可视化研究区范围,边界颜色为红色,填充值透明,线宽为2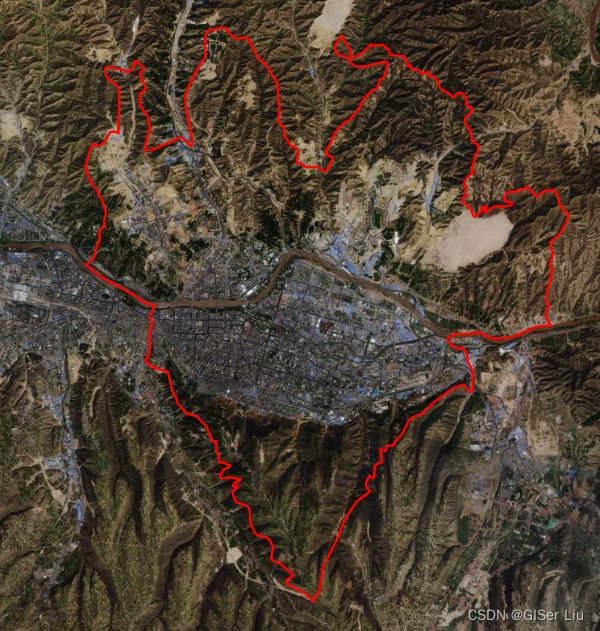
可以看到,底图上已加载出矢量边界的轮廓。若对数据导入有疑问,可以去看看这篇文章。
PIE Engine系列2 数据的上传、调用及下载(附源码超详细)_GISer Liu的博客-CSDN博客
2.遥感影像数据
本文选择的遥感影像数据是Sentinel-2号L1C数据,虽然2A数据的精度和质量更好。但平台Sentinel-2号L2A数据放大后会出现错乱的BUG,这里我们选择使用城关区2020年中旬影像的R、G、B、NIR四个波段作为可训练特征。输入以下代码并运行加载研究区影像:
var bands = ['B2','B3','B4','B8'];//选择影像数据的四个波段,以此为B、G、R、NIR
var image = pie.ImageCollection("S2/L1C")//选择Sentinel2_L1C影像作为数据源
.filterBounds(roi)//选择与矢量边界相交区域的影像
.filterDate("2020-3-1","2020-9-1")//选择拍摄时间在2020年3-9月份之间的影像
.filter(pie.Filter.lt("cloudyPixelPercentage", 5))//选择云盖量小于5%的影像
.select(bands)//从中选择我们需要的四个波段
.mosaic()//将符合以上条件的影像进行拼接
.clip(roi);//根据矢量边界裁剪影像,使其轮廓与矢量边界一致
Map.addLayer(image.select(["B4","B3","B2"]),{min:0,max:3000},"待分类影像");//以真彩色的方式可视化我们选择的影像,其中最大值最小值为像元值,不同的数据类型下值也不同。“待分类影像”为图层名
查看结果,可以看到符合条件的遥感影像已经加载到底图上。 使用print函数打印出其属性。
print(image)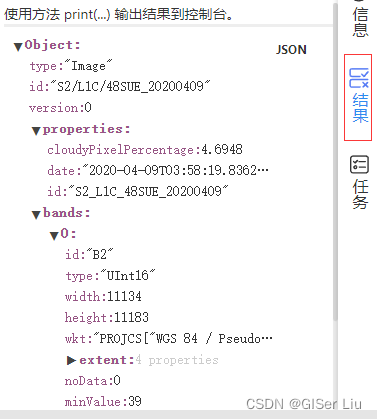
查看影像的基本信息。
3.样本数据
由于PIE Engine平台的经典机器学习监督分类只支持点类型样本。样本点采样既可以本地采样,也可以在云端采样,但是云端采样流程较多,我以后写文章讲解。作者使用的样本数据是自己本地目视解译的的样本点。本地采样使用PIE Basic或者ArcGIS采样均可。
| 地物类型 | 耕地 | 林地 | 草地 | 人造地表 | 水体 | 未利用土地 |
| 数值 | 1 | 3 | 4 | 5 | 7 | 8 |
作者使用的样本点已共享,使用本文代码即可运行测试。
①样本点导入并可视化
输入以下代码,导入并查看样本点。
var points = pie.FeatureCollection('user/qianyouliang/train_samples/chengguanpoint1');//导入样本点
Map.addLayer(points,{ color: "green"},"样本点");可视化样本点,颜色为绿色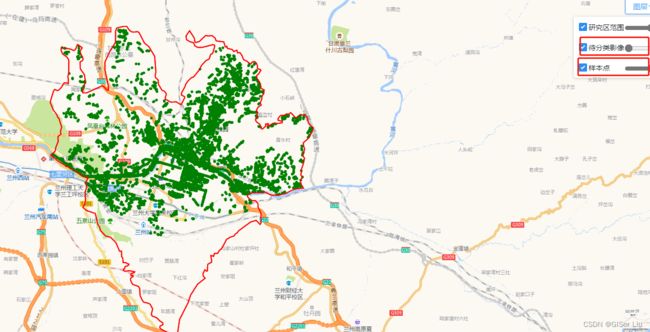
通过调整待分类影像的图层透明度,我们可以看到绿色的样本点。
这里的样本点并不能直接用于分类,它只有地物类型type字段和经纬度。我们需要使用它在影像上采样后才具有光谱像元值特征。
②样本点采样
PIE Engine提供了两种样本点采样的函数,分别是:
1 sample 基于矢量面采样,不包含分类字段,适用于非监督分类
2 sampleRegions 基于包含分类字段的样本点采样,适用于监督分类
这里我们采用后者,输入以下代码进行采样,参数介绍如下。
var sampleFeatureCollection = image.sampleRegions(points, ["type"],10, "", "", true);
1 points 样本点
2 ["type"] 所采集的样本点中的分类字段名称,若采用了其他字段,将其中的type替换即可
3 10 所采集的影像分辨率,哨兵2号是10m,这里输入10,若运算量太大,可调高该值
4 "" 地图投影,默认即可
5 "" 影像瓦片尺寸 默认即可
6 true 是否为几何图形 默认即可
②样本点划分
将样本点划分为训练集与测试集,在此之前,我们需要建立random字段。生成随机数,以随机数字段进行排序,打乱样本数据顺序后进行采样,避免过拟合。最后将样本点以7:3的比例划分为训练集和测试集。输入以下代码并运行:
var sampleFeatureCollection = sampleFeatureCollection.randomColumn("random");//建立随机数字段
var sampleTrainingFeatures = sampleFeatureCollection.filter(pie.Filter.lte("random", 0.7));//以随机数字段划分训练集,lte代表(less than or equal)小于等于。过滤掉小于等于0.7的作为训练集
var sampleTestingFeatures = sampleFeatureCollection.filter(pie.Filter.gt("random", 0.3));//以随机数字段划分测试机,gt(greater than) 大于,过滤掉大于0.3的作为测试集详情看代码注释。
三、模型构建及训练
1.分类模型选择
我们已经拥有了处理好的数据集,现在我们需要选择合适的分类器,结合模型的特点与影像特征,我们思考一下:
1 SVM模型对解决小样本、非线性和高维模式识别的问题有良好的效果,但是我们的数据中,耕地、草地之间的光谱特征较为相似,部分类别间的差异程度并不明显,且数据量较多。SVM模型更适用于光谱特征明显,与其他地物差异较大的分类。
2 随机森林模型对异常值和噪声具有很好的容忍度,且不容易出现过拟合。是集成学习的一部分,对这种类型的地物分类效果较好。
3 正态贝叶斯模型由训练样本数据估计每个分类的协方差矩阵和均值向量,然后把这两组变量代入对数函数公式中,从而得到每个分类的完整的对数似然函数。当需要预测样本时,把样本的特征属性值分别带入全部分类的对数似然函数中,最大对数似然函数对应的分类就是该样本的分类结果。这种方式的预测精度也较高,预测出来的分类影像较为干净。
这里我们选择了使用随机森林模型,如果条件允许你也可以根据影像将模型都测试一遍选择精度最高的模型进行训练。
2.模型训练及精度评价
我们选择随机森林分类器训练模型,输入以下代码:
var classifer = pie.Classifier.rTrees().train(sampleTrainingFeatures, "type", bands);//
var class_image = image.classify(classifer).focal_min(2).focal_max(2);// 分类后处理:平滑影像,进行开闭运算剔除噪声影响.进行滤波运算
print("image_class",class_image);//输出分类影像的信息
对训练好的模型进行精度评定,输入以下代码:
// 评估训练样本的精度.
var checkM = classifer.confusionMatrix();//计算训练样本的混淆矩阵
print("混淆矩阵:",checkM);//输出混淆矩阵
print("训练矩阵-ACC系数:", checkM.acc());//输出ACC系数
print("训练矩阵-Kappa系数:", checkM.kappa());//输出Kappa系数
// 评估验证样本的精度.
var predictResult = sampleTestingFeatures.classify(classifer, "classification");//利用训练好的模型在测试集上进行预测
var errorM = predictResult.errorMatrix("type", "classification");//计算误差矩阵
print("验证矩阵-ACC系数:", errorM.acc());//输出测试集ACC系数
print("验证矩阵-Kappa系数:", errorM.kappa());//输出测试集Kappa系数
通过查看模型在训练集上和测试集上的精度,我们可以看出其训练精度听不错,达到了90%。
四、分类结果可视化
1.图例配色
输入以下代码,进行图例的配色,运行查看效果:
var data = {
title: "土地利用分类图例",
colors: ["#3fc412","#328217","#c9f297","#003300","#00B3FF","#f2f3dd"],
labels: ["耕地", "林地", "草地", "人造地表","水域","其他土地"],
step: 1, // 将每个单位色块均分为1个
isvertical: false
};//配置图例内部的内容
var style = {
right: "100px", // 图例框的右侧与屏幕最右端的距离
bottom: "10px", // 图例框的底侧与屏幕底端的距离
height: "100px", // 图例框的纵向高度
width: "340px" // 图例框的横向长度
};//配置图例的布局
var legend = ui.Legend(data, style);//根据我们设置的参数实例化一个图例对象
Map.addUI(legend);//将该图例对象加入到页面UI中
图例加载成功。
2.分类影像配色
输入以下配色代码,可视化分类结果,运行查看效果。
// 分类结果显示
var visParam = {
opacity: 1,
uniqueValue: '1,3,4,5,7,8',//分类type值,根据分类结果的值进行配色
palette: '#3fc412,#328217,#c9f297,#003300,#00B3FF,#f2f3dd'
};
//加载分类后处理结果
Map.addLayer(class_image, visParam, "class_image");//使用上面的配色方案将分类结果可视化
可视化效果个人感觉较好,作者的审美并不咋滴,请大家多多见谅。
五、面积统计
1.饼图面积统计
使用平台提供的函数将研究区域的分类影像按分辨率对不同地物瓦片面积进行统计,输入以下代码并运行计算面积:
let types = [1,3,4,5,7,8];//配置像元值
for (let i=0; i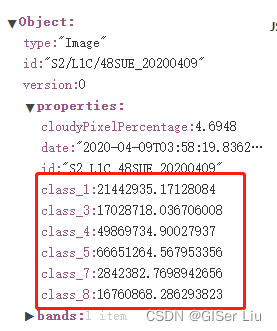
可以看出,各类地物面积已计算并成为分类影像的属性。
2.饼图可视化地物面积
对刚刚计算出地物面积进行可视化,这里我们选择饼图,当然你也可以选择其他类型可视化效果。
class_image.getInfo(function(data) {
let properties = data.properties;
let xValues = [];
let yValues = [];
let labels = [
"耕地","林地","草地","人造地表","水体","未利用土地"
];
for (let i=0; i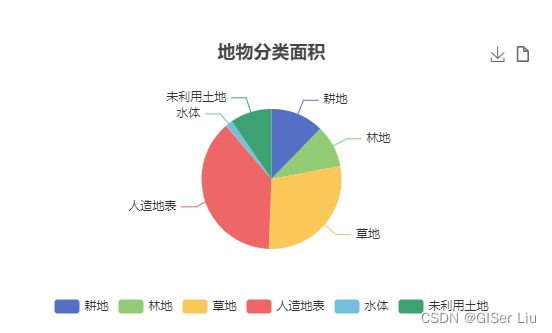
根据分类结果,我们可以看到城关区人造地表占据多数区域。可视化效果图可支持下载csv和png格式,助力科研。
3.分类结果保存
将我们处理好的分类影像保存至云盘,导出下载,输入以下代码,若有疑惑请看此文。
Export.imageToCloud({image:class_image,//选择需要导出的影像
description:"ExportToCloud",//任务名称设置,可自定义
region:roi,//导出范围为自定义研究区roi
scale:30})//导出分辨率为30m,太高可能导致导出失败,个人算力有限
六、结论
本文中,作者基于PIE Engine遥感云计算平台进行遥感影像监督分类,详细介绍了遥感影像分类的数据预处理、模型训练及结果可视化。不过,在此过程中作业也有很多疑问,因为训练好的模型精度取决于遥感影像的数据,若预测未经统一预处理,其精度也无法保证,因此单纯基于光谱像元值的经典机器学习算法在不同时间段和不同区域的泛化性并不好,但是综合多种特征的深度学习模型应该能很好的解决此问题。在之后的文章中我会尝试训练遥感影像深度学习模型来尝试通用地物分类。

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!
“本站所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_45590504/category_11752103.html?spm=1001.2014.3001.5482百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。”
系列文章
PIE Engine系列0 平台介绍(详细)_GISer Liu的博客-CSDN博客
PIE Engine系列1 遥感数据下载器的实现(含源码)_GISer Liu的博客-CSDN博客
PIE Engine系列2 数据的上传、调用及下载(附源码超详细)_GISer Liu的博客-CSDN博客