libtorch+YOLOV5配置踩坑记
电脑配置:
CPU:Intel i7-10750H
内存:16G
显卡:GeForce GTX 1650 Ti(4GB显存)
操作系统:Windows 10 家庭中文版
CUDA:10.2
CUDNN:8.2
libtorch:1.8.2
Visual Studio:2017
YOLOV5:v6.0
Opencv:3.4.6
第一步:安装Visual Studio 2017,目前VS2017并未提供离线版安装文件,可以通过在线安装的方式进行安装,具体安装过程在此不再赘述。
第二步:安装CUDA 10.2,通常来讲按照默认配置安装即可。
第三步:安装CUDNN,打开压缩包,将下图的三个文件夹复制到“C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\”目录下即可。

第四步:使用以下指令安装CUDA10.2版本的pytorch1.8.2(切记版本和CUDA版本要与libtorch的版本、CUDA版本保持一致,否则在加载模型或者前向推理过程中会出现异常而崩溃)。
pip install torch==1.8.2+cu102 torchvision==0.9.2+cu102 torchaudio===0.8.2 -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html第五步:使用以下指令配置YOLOV5。本文采用v6.0版本,亲测可用。若版本升级导致libtorch调用存在问题,可以在此处下载。
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt第六步:在此处下载YOLOV5的预训练模型,若链接失效,可至此处下载预训练模型。
第七步:使用YOLOV5官方的export.py进行模型转换,libtorch采用的转换格式为torchscript,注意export.py默认转换为CPU版本的权重,保险起见最好转换为GPU版本的权重。github上的官方转换教程TFLite, ONNX, CoreML, TensorRT Export · Issue #251 · ultralytics/yolov5 · GitHub。

python path/to/export.py --weights yolov5s.pt --img 640 --include torchscript onnx coreml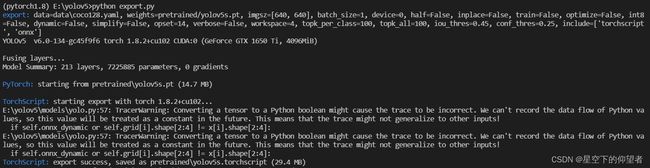
第八步:在libtorch官网下载CUDA10.2版本的libtorch1.8.2。注意windows版本的libtorch的文件名中包含“libtorch-win-shared-with-deps-1.8.2%2Bcu102.zip”,若下载成linux版本的会出现“无法打开asmjit.lib”的情况。
第九步:在opencv官网上下载opencv3.4.6。
第十步:在VS2017中配置libtorch,首先创建一个C++工程,在此基础上进行相应的配置。需要配置的内容如下图所示:




asmjit.lib
c10.lib
c10d.lib
caffe2_detectron_ops_gpu.lib
caffe2_module_test_dynamic.lib
clog.lib
cpuinfo.lib
dnnl.lib
fbgemm.lib
gloo.lib
libprotobuf-lite.lib
libprotobuf.lib
libprotoc.lib
mkldnn.lib
torch.lib
torch_cuda.lib
torch_cpu.lib
opencv_world348.lib
c10_cuda.lib
/INCLUDE:?warp_size@cuda@at@@YAHXZ注意:“/INCLUDE:?warp_size@cuda@at@@YAHXZ”是必要的,否则无法调用CUDA
第十一步:配置完后创建cpp文件,复制粘贴以下代码:
#include
#include
#include
#include
#include
#include
using namespace std;
std::vector non_max_suppression(torch::Tensor preds, float score_thresh = 0.5, float iou_thresh = 0.5)
{
std::vector output;
for (size_t i = 0; i < preds.sizes()[0]; ++i)
{
torch::Tensor pred = preds.select(0, i);
// Filter by scores
torch::Tensor scores = pred.select(1, 4) * std::get<0>(torch::max(pred.slice(1, 5, pred.sizes()[1]), 1));
pred = torch::index_select(pred, 0, torch::nonzero(scores > score_thresh).select(1, 0));
if (pred.sizes()[0] == 0) continue;
// (center_x, center_y, w, h) to (left, top, right, bottom)
pred.select(1, 0) = pred.select(1, 0) - pred.select(1, 2) / 2;
pred.select(1, 1) = pred.select(1, 1) - pred.select(1, 3) / 2;
pred.select(1, 2) = pred.select(1, 0) + pred.select(1, 2);
pred.select(1, 3) = pred.select(1, 1) + pred.select(1, 3);
// Computing scores and classes
std::tuple max_tuple = torch::max(pred.slice(1, 5, pred.sizes()[1]), 1);
pred.select(1, 4) = pred.select(1, 4) * std::get<0>(max_tuple);
pred.select(1, 5) = std::get<1>(max_tuple);
torch::Tensor dets = pred.slice(1, 0, 6);
torch::Tensor keep = torch::empty({ dets.sizes()[0] });
torch::Tensor areas = (dets.select(1, 3) - dets.select(1, 1)) * (dets.select(1, 2) - dets.select(1, 0));
std::tuple indexes_tuple = torch::sort(dets.select(1, 4), 0, 1);
torch::Tensor v = std::get<0>(indexes_tuple);
torch::Tensor indexes = std::get<1>(indexes_tuple);
int count = 0;
while (indexes.sizes()[0] > 0)
{
keep[count] = (indexes[0].item().toInt());
count += 1;
// Computing overlaps
torch::Tensor lefts = torch::empty(indexes.sizes()[0] - 1);
torch::Tensor tops = torch::empty(indexes.sizes()[0] - 1);
torch::Tensor rights = torch::empty(indexes.sizes()[0] - 1);
torch::Tensor bottoms = torch::empty(indexes.sizes()[0] - 1);
torch::Tensor widths = torch::empty(indexes.sizes()[0] - 1);
torch::Tensor heights = torch::empty(indexes.sizes()[0] - 1);
for (size_t i = 0; i < indexes.sizes()[0] - 1; ++i)
{
lefts[i] = std::max(dets[indexes[0]][0].item().toFloat(), dets[indexes[i + 1]][0].item().toFloat());
tops[i] = std::max(dets[indexes[0]][1].item().toFloat(), dets[indexes[i + 1]][1].item().toFloat());
rights[i] = std::min(dets[indexes[0]][2].item().toFloat(), dets[indexes[i + 1]][2].item().toFloat());
bottoms[i] = std::min(dets[indexes[0]][3].item().toFloat(), dets[indexes[i + 1]][3].item().toFloat());
widths[i] = std::max(float(0), rights[i].item().toFloat() - lefts[i].item().toFloat());
heights[i] = std::max(float(0), bottoms[i].item().toFloat() - tops[i].item().toFloat());
}
torch::Tensor overlaps = widths * heights;
// FIlter by IOUs
torch::Tensor ious = overlaps / (areas.select(0, indexes[0].item().toInt()) + torch::index_select(areas, 0, indexes.slice(0, 1, indexes.sizes()[0])) - overlaps);
indexes = torch::index_select(indexes, 0, torch::nonzero(ious <= iou_thresh).select(1, 0) + 1);
}
keep = keep.toType(torch::kInt64);
output.push_back(torch::index_select(dets, 0, keep.slice(0, 0, count)));
}
return output;
}
int main()
{
// Loading Module
cout << "cuda是否可用:" << torch::cuda::is_available() << "\t显卡数量:" << torch::cuda::device_count() << endl;
cout << "cudnn是否可用:" << torch::cuda::cudnn_is_available() << endl;
torch::jit::script::Module module = torch::jit::load("E:/yolov5/pretrained/yolov5s.torchscript");
auto device = at::kCUDA;
module.to(device);
std::vector classnames;
std::ifstream f("class.names");
std::string name = "";
while (std::getline(f, name))
{
classnames.push_back(name);
}
cv::VideoCapture cap = cv::VideoCapture(0);
cap.set(cv::CAP_PROP_FRAME_WIDTH, 1920);
cap.set(cv::CAP_PROP_FRAME_HEIGHT, 1080);
cv::Mat frame, img;
while (cap.read(frame))
{
if (frame.empty())
break;
clock_t start = clock();
cv::resize(frame, img, cv::Size(640, 640)); //384
cv::cvtColor(img, img, cv::COLOR_BGR2RGB);
torch::Tensor imgTensor = torch::from_blob(img.data, { 1, img.rows, img.cols,img.channels() }, torch::kByte);
imgTensor = imgTensor.to(device);
imgTensor = imgTensor.permute({ 0,3,1,2 }).contiguous();
imgTensor = imgTensor.toType(torch::kFloat);
imgTensor = imgTensor.div(255);
std::vector inputs;
torch::NoGradGuard no_grad;
inputs.emplace_back(imgTensor);
auto output = module.forward(inputs);
torch::Tensor preds = output.toTuple()->elements()[0].toTensor();
auto dets = non_max_suppression(preds.to(at::kCPU), 0.4, 0.5);
if (dets.size() > 0)
{
// Visualize result
for (size_t i = 0; i < dets[0].sizes()[0]; ++i)
{
float left = dets[0][i][0].item().toFloat() * frame.cols / 640;
float top = dets[0][i][1].item().toFloat() * frame.rows / 640; // 384
float right = dets[0][i][2].item().toFloat() * frame.cols / 640;
float bottom = dets[0][i][3].item().toFloat() * frame.rows / 640; //384
float score = dets[0][i][4].item().toFloat();
int classID = dets[0][i][5].item().toInt();
cv::rectangle(frame, cv::Rect(left, top, (right - left), (bottom - top)), cv::Scalar(0, 255, 0), 2);
cv::putText(frame,
classnames[classID] + ": " + cv::format("%.2f", score),
cv::Point(left, top),
cv::FONT_HERSHEY_SIMPLEX, (right - left) / 200, cv::Scalar(0, 255, 0), 2);
}
}
cv::putText(frame, "FPS: " + std::to_string(int(1e7 / (clock() - start))),
cv::Point(50, 50),
cv::FONT_HERSHEY_SIMPLEX, 1, cv::Scalar(0, 255, 0), 2);
cv::imshow("video", frame);
if (cv::waitKey(20) > 0)//按下任意键退出摄像头 因电脑环境而异,有的电脑可能会出现一闪而过的情况
break;
}
//frame = cv::imread("bus.jpg");
return 0;
} 第十二步:若编译通过,但是报“缺乏*.dll"之类的错误,需要将libtorch和opencv中的“.dll”文件复制至工程生成的“.exe”的文件目录下。

常见问题:
1:“c10::Error,位于内存位置 0x0000006E4B6FC970 处。” 该问题常常出现于以下情况
1)pytorch与libtorch版本或者CUDA版本不一致;
2)pytorch导出的模型输入尺寸与调用libtorch时输入的图像尺寸不一致;
3)模型与数据不在同一设备,典型的比如模型在GPU上但是数据在CPU上;
4)模型或者图像路径错误;
2:计算非极大抑制时报错,该问题常常由于不同的数据不在同一设备导致的。