【AI达人创造营第二期】基于Jetson nano的餐厅自助结账系统部署
基于Jetson nano的餐厅自助结账系统部署
- 一. 前言
- 二. 开发环境
-
- 2.1 硬件
- 2.2 软件
- 三. Jetson nano基础环境配置
-
- 3.1 镜像烧录
- 3.2 网络连接
- 3.3 更换镜像源
- 3.4 安装pip并换源
- 3.5 远程登录
- 四. 摄像头测试
- 五. 安装PaddlePaddle开发环境
- 六. 测试Paddle Inference
-
- 6.1 跑通demo
- 6.2 扩大运行内存
- 七. 部署自己的目标检测模型
-
- 7.1 导出推理模型
- 7.2 准备预测部署程序
- 7.3 添加GUI界面
- 7.4 更改预测模式
- 八. 效果展示
- 九. 总结
一. 前言
本文是餐厅自助结账系统的硬件部署部分,关于目标检测部分请大家移步:【AI达人创造营第二期】餐厅自助结账系统之目标检测部分
本文全程参考了这三位大佬的文章,在此特表示感谢:
-
【从踩坑到入门】基于Jetson Nano的深度学习模型部署教程
-
在Jetson Nano上基于python部署Paddle Inference
-
【飞桨领航团AI创造营+部署】EdgeBoard上实现电梯电瓶车检测
二. 开发环境
2.1 硬件
- Jetson nano
- 笔记本电脑
- 支持HDMI的屏幕
- 外接鼠标和键盘
- 网线
- CSI摄像头
- 32G存储卡
2.2 软件
Jetson nano
- Ubuntu 18.04
- Jetson nano软核 4.6.1
- Python 3.6.9
- PaddlePaddle 2.2.3
笔记本电脑
- Windows 10
- Python 3.6.5
三. Jetson nano基础环境配置
3.1 镜像烧录
Jetson Nano初体验之写入官方Ubuntu镜像
这里需要注意两点:
1. 烧录的镜像一定要去官网下载最新版本,否则会出错
2. 第一次登录Jetson nano一定要连接显示屏进行基础配置
3.2 网络连接
我采用的是利用网线连接nano和PC,共享PC网络的方法来实现网络连接:
- Jetson Nano——通过网线实现笔记本ssh远程连接
- Jetson Nano通过笔记本实现网络连接
偶尔可能出现突然连不上的情况,此时需要将无线网卡的共享关闭,插拔网线连接,再重新打开共享功能即可。
关于其他联网方法,大家可以参考:
- Jetson Nano主板的五种联网方法
- jetson nano 命令行连接wifi
- Jetson nano 开机自动连接 Wifi
- jetson nano设置静态ip和发出热点
3.3 更换镜像源
官方镜像默认的是Ubuntu官方源,在国内使用该源下载程序速度较慢,所以需要更换。
ubuntu镜像源更换_Jetson Nano 修改源镜像
3.4 安装pip并换源
Jetson Nano——安装pip并换源
3.5 远程登录
jetson nano远程登录教程(PuTTYssh远程登录、远程桌面VNC、winSCP文件传输)
四. 摄像头测试
CSI摄像头的连接方式如图所示,将插槽往上提即可打开插槽插入排线。

在终端输入ls /dev/video*,如果出现/dev/video0则说明摄像头连接成功。用下面这段程序测试一下摄像头是否正常,如果是USB摄像头,摄像头初始化改为cap = cv2.VideoCapture(0)。
import cv2
import numpy as np
def video_demo():
print("init")
capture = cv2.VideoCapture("nvarguscamerasrc \
!video/x-raw(memory:NVMM), width=640, height=480, format=NV12, framerate=30/1\
!nvvidconv flip-method=0 ! videoconvert ! video/x-raw, format=BGR ! appsink")#0为电脑内置摄像头
while(True):
ret, frame = capture.read()#摄像头读取,ret为是否成功打开摄像头,true,false。 frame为视频的每一帧图像
frame = cv2.flip(frame, 1)#摄像头是和人对立的,将图像左右调换回来正常显示。
print("OK")
cv2.imshow("video", frame)
c = cv2.waitKey(50)
if c == 27:
break
capture.release()
video_demo()
cv2.destroyAllWindows()
五. 安装PaddlePaddle开发环境
首先查看Jetpack的版本:cat /etc/nv_tegra_release

然后根据Jetpack和Python的版本在官网上下载对应的PaddlePaddle,比如我的Jetpack版本为6.1,Python版本为3.6.9。

将.whl文件下载后通过远程文件传输软件winscp上传到Jetson nano中,进入.whl所在的文件夹并输入以下命令安装:pip3 install paddlepaddle_gpu-2.1.1-cp36-cp36m-linux_aarch64.whl,最后测试一下PaddlePaddle是否安装成功:
# 打开python3测试
import paddle
paddle.fluid.install_check.run_check()

六. 测试Paddle Inference
6.1 跑通demo
首先拉取官方最新版本的Paddle-Inference-demo并解压:
#拉取Paddle-Inference-Demo
!git clone https://github.com/PaddlePaddle/Paddle-Inference-Demo.git
#解压
!unzip -oq /home/aistudio/Paddle-Inference-Demo-master.zip
在Paddle-Inference-Demo/python路径下面可以看到官方提供了很多测试文件。

以口罩检测为例,进入mask_detection文件夹,仔细阅读README.md文件,首先下载模型:
cd models
sh model_downloads.sh
然后修改cam_video.py如下所示,并运行程序:
# -*- coding: UTF-8 -*-
import cv2
from mask_detect import MaskPred
# The MaskPred class implements the function of face mask detection,
# including face detection and face mask classification
mp = MaskPred(True ,True, 0)
# Turn on the first camera, 0 means device ID
cap = cv2.VideoCapture("nvarguscamerasrc \
!video/x-raw(memory:NVMM), width=640, height=480, format=NV12, framerate=30/1\
!nvvidconv flip-method=0 ! videoconvert ! video/x-raw, format=BGR ! appsink")
#cv2.namedWindow('Mask Detect')
while True:
ret, frame = cap.read()
frame = cv2.flip(frame, 1)
print("OK")
result = mp.run(frame)
result_img = result['img']
# h, w, _ = result_img.shape
# result_img = cv2.resize(result_img, (int(w * 0.3), int(h * 0.3)))
cv2.imshow("image", result_img)
c = cv2.waitKey(10)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
⭐需要注意的是摄像头结束时一定要释放掉cap.release(),否则下一次将无法正常开启。
#运行程序
python3 cam_video.py
其他案例的运行方法详见各个文件夹内的README.md文件,或者可以直接运行run.sh文件,但是需要事先将所有run.sh文件底部的python改为python3。
# 运行run.sh
chmod +x run.sh
./run.sh
6.2 扩大运行内存
如果在运行demo的过程中出现了卡死的情况,可以通过以下方法扩大运行内存,至少8G:
sudo fallocate -l 8G /var/swapfile8G
sudo chmod 600 /var/swapfile8G
sudo mkswap /var/swapfile8G
sudo swapon /var/swapfile8G
sudo bash -c 'echo "/var/swapfile8G swap swap defaults 0 0" >> /etc/fstab'
七. 部署自己的目标检测模型
7.1 导出推理模型
在【AI达人创造营第二期】餐厅自助结账系统之目标检测部分中我们已经训练得到了目标检测模型,在该项目中我才用的是ppyolov2_r50vd_dcn模型,由于该模型推理速度慢,而且不支持TRT加速,所以我换成了yolov3_mobilenet_v1训练了一个新模型,训练步骤完全相同,训练完成后模型保存在PaddleDetection/output路径下。

运行下面这行命令将模型导出,如果想导出其他模型修改.yml和.pdparams的路径即可:
# 模型导出
!python -u PaddleDetection/tools/export_model.py -c PaddleDetection/configs/yolov3/yolov3_mobilenet_v1_ssld_270e_voc.yml --output_dir=./339 \
-o weights=PaddleDetection/output/yolov3_mobilenet_v1_ssld_270e_voc/319.pdparams
导出后我们得到得到以下两个文件:
- 存储模型结构的
inference.pdmodel - 存储模型参数的
inference.pdiparams

将这两个模型文件传入Jetson nano即可,我为大家准备好了模型,大家可以自行下载:链接。
7.2 准备预测部署程序
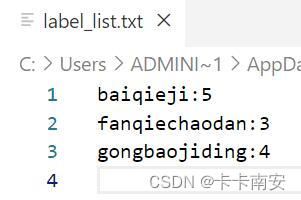
新建一个.txt文件,用来存放标签及其对应的价格:
以下代码请在Jetson Nano上运行。
1. 导入资源库
import cv2
import numpy as np
from paddle.inference import Config
from paddle.inference import PrecisionType
from paddle.inference import create_predictor
import yaml
import time
import threading
2. 图像预处理
def resize(img, target_size):
"""resize to target size"""
if not isinstance(img, np.ndarray):
raise TypeError('image type is not numpy.')
im_shape = img.shape
im_size_min = np.min(im_shape[0:2])
im_size_max = np.max(im_shape[0:2])
im_scale_x = float(target_size) / float(im_shape[1])
im_scale_y = float(target_size) / float(im_shape[0])
img = cv2.resize(img, None, None, fx=im_scale_x, fy=im_scale_y)
return img
def normalize(img, mean, std):
img = img / 255.0
mean = np.array(mean)[np.newaxis, np.newaxis, :]
std = np.array(std)[np.newaxis, np.newaxis, :]
img -= mean
img /= std
return img
def preprocess(img, img_size):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
img = resize(img, img_size)
img = img[:, :, ::-1].astype('float32') # bgr -> rgb
img = normalize(img, mean, std)
img = img.transpose((2, 0, 1)) # hwc -> chw
return img[np.newaxis, :]
3. 模型配置和预测
def predict_config(model_file, params_file):
'''
函数功能:初始化预测模型predictor
函数输入:模型结构文件,模型参数文件
函数输出:预测器predictor
'''
# 根据预测部署的实际情况,设置Config
config = Config()
# 读取模型文件
config.set_prog_file(model_file)
config.set_params_file(params_file)
# Config默认是使用CPU预测,若要使用GPU预测,需要手动开启,设置运行的GPU卡号和分配的初始显存。
config.enable_use_gpu(500, 0)
# 可以设置开启IR优化、开启内存优化。
config.switch_ir_optim()
config.enable_memory_optim()
config.enable_tensorrt_engine(workspace_size=1 << 30, precision_mode=PrecisionType.Half,max_batch_size=1, min_subgraph_size=5, use_static=False, use_calib_mode=False)
predictor = create_predictor(config)
return predictor
def predict(predictor, img):
'''
函数功能:初始化预测模型predictor
函数输入:模型结构文件,模型参数文件
函数输出:预测器predictor
'''
input_names = predictor.get_input_names()
for i, name in enumerate(input_names):
input_tensor = predictor.get_input_handle(name)
input_tensor.reshape(img[i].shape)
input_tensor.copy_from_cpu(img[i].copy())
# 执行Predictor
predictor.run()
# 获取输出
results = []
# 获取输出
output_names = predictor.get_output_names()
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_handle(name)
output_data = output_tensor.copy_to_cpu()
results.append(output_data)
return results
4. 后处理
def draw_bbox_image(frame, result, label, threshold=0.5):
for res in result:
cat_id, score, bbox = res[0], res[1], res[2:]
if score < threshold:
continue
for i in bbox:
int(i)
xmin, ymin, xmax, ymax = bbox
cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), (255,0,255), 2)
print('category id is {}, bbox is {}'.format(cat_id, bbox))
try:
label_id = label[int(cat_id)]
# #cv2.putText(图像, 文字, (x, y), 字体, 大小, (b, g, r), 宽度)
cv2.putText(frame, label_id, (int(xmin), int(ymin-2)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 2)
cv2.putText(frame, str(round(score,2)), (int(xmin), int(ymin+8)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,255,0), 2)
except KeyError:
pass
def show_price(frame, result, label, price, threshold=0.5):
w, h, _ = img.shape
price_sum = 0 #记录总价
label_sum = [] #记录购买的食物
for res in result:
cat_id, score, bbox = res[0], res[1], res[2:]
if score < threshold:
continue
label_sum.append(label[int(cat_id)])
price_sum += int(price[int(cat_id)])
cv2.putText(frame, "price:"+str(price_sum), (int(w-4), 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,255), 2)
if len(label_sum) > 0:
print("您挑选了%d份食物,总共%d元" % (len(label_sum),price_sum))
else:
print("请挑选食物")
5. 定义摄像头类
在实际运行过程中,如果摄像头帧率较高,但nano的处理速度跟不上时,会出现卡帧的情况,这时我们可以通过多线程的技巧改善这一问题。
class Camera:
def __init__(self, src=0):
self.src = src
self.stream = cv2.VideoCapture(src)
self.stopped = False
self.thread = threading.Thread(target=self.update, args=())
for _ in range(10): #warm up the camera
(self.grabbed, self.frame) = self.stream.read()
def start(self):
self.thread.start()
def update(self):
while True:
if self.stopped:
return
(self.grabbed, self.frame) = self.stream.read()
def read(self):
return self.grabbed, self.frame
def stop(self):
self.stopped = True
def release(self):
self.stream.release()
6. 主函数
# 从.txt文件中读取label
f = open("./label_list.txt")
label_list = f.read().splitlines()
label = [i.split(":")[0] for i in label_list]
price = [i.split(":")[1] for i in label_list]
print(label)
print(price)
f.close()
# 配置模型参数
model_file = "./model/yolo/model.pdmodel"
params_file = "./model/yolo/model.pdiparams"
# 初始化预测模型
predictor = predict_config(model_file, params_file)
cap = Camera("nvarguscamerasrc \
!video/x-raw(memory:NVMM), width=640, height=480, format=NV12, framerate=30/1\
!nvvidconv flip-method=0 ! videoconvert ! video/x-raw, format=BGR ! appsink")
cap.start()
# 图像尺寸相关参数初始化
ret, img = cap.read()
if ret==False:
while True:
print("error")
im_size = 608
scale_factor = np.array([im_size * 1. / img.shape[0], im_size * 1. / img.shape[1]]).reshape((1, 2)).astype(np.float32)
im_shape = np.array([im_size, im_size]).reshape((1, 2)).astype(np.float32)
while True:
ret, frame = cap.read()
# print(frame)
# 预处理
data = preprocess(frame, im_size)
time_start = time.time()
# 预测
result = predict(predictor, [im_shape, data, scale_factor])
# print(result)
print('Time Cost:{}'.format(time.time()-time_start) , "s")
draw_bbox_image(frame, result[0], label, threshold=0.5)
show_price(frame, result[0], label, price, threshold=0.5)
cv2.imshow("frame", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
print("break")
cap.stop()
cap.release()
cv2.destroyAllWindows()
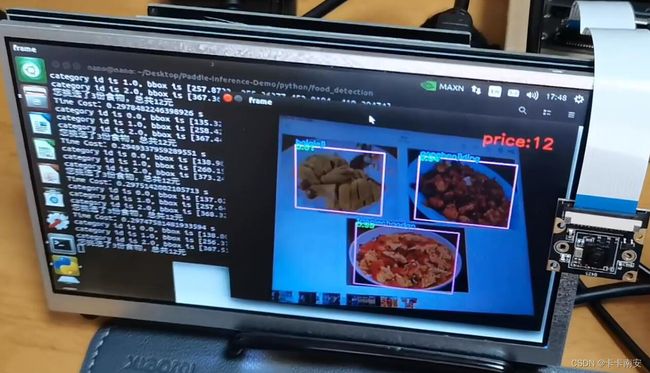
运行后效果如图所示:
7.3 添加GUI界面
为了增强系统的操作性,我在前面目标检测的基础上增加了GUI界面。为了提高程序的可读性,我将代码分成了detect.py和GUI.py两个文件:
detect.py: 包括图像预处理、模型的配置和预测、图像后处理等与目标检测相关的函数。GUI.py: 包括GUI界面显示相关函数和主函数。
1. detec.py
import cv2
import numpy as np
from paddle.inference import Config
from paddle.inference import PrecisionType
from paddle.inference import create_predictor
import yaml
import time
import threading
def resize(img, target_size):
"""resize to target size"""
if not isinstance(img, np.ndarray):
raise TypeError('image type is not numpy.')
im_shape = img.shape
im_size_min = np.min(im_shape[0:2])
im_size_max = np.max(im_shape[0:2])
im_scale_x = float(target_size) / float(im_shape[1])
im_scale_y = float(target_size) / float(im_shape[0])
img = cv2.resize(img, None, None, fx=im_scale_x, fy=im_scale_y)
return img
def normalize(img, mean, std):
img = img / 255.0
mean = np.array(mean)[np.newaxis, np.newaxis, :]
std = np.array(std)[np.newaxis, np.newaxis, :]
img -= mean
img /= std
return img
def preprocess(img, img_size):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
img = resize(img, img_size)
img = img[:, :, ::-1].astype('float32') # bgr -> rgb
img = normalize(img, mean, std)
img = img.transpose((2, 0, 1)) # hwc -> chw
return img[np.newaxis, :]
def predict_config(model_file, params_file):
'''
函数功能:初始化预测模型predictor
函数输入:模型结构文件,模型参数文件
函数输出:预测器predictor
'''
# 根据预测部署的实际情况,设置Config
config = Config()
# 读取模型文件
config.set_prog_file(model_file)
config.set_params_file(params_file)
# Config默认是使用CPU预测,若要使用GPU预测,需要手动开启,设置运行的GPU卡号和分配的初始显存。
config.enable_use_gpu(500, 0)
# 可以设置开启IR优化、开启内存优化。
config.switch_ir_optim()
config.enable_memory_optim()
#config.enable_tensorrt_engine(workspace_size=1 << 30, precision_mode=PrecisionType.Half,max_batch_size=1, min_subgraph_size=5, use_static=False, use_calib_mode=False)
predictor = create_predictor(config)
return predictor
def predict(predictor, img):
'''
函数功能:初始化预测模型predictor
函数输入:模型结构文件,模型参数文件
函数输出:预测器predictor
'''
input_names = predictor.get_input_names()
for i, name in enumerate(input_names):
input_tensor = predictor.get_input_handle(name)
input_tensor.reshape(img[i].shape)
input_tensor.copy_from_cpu(img[i].copy())
# 执行Predictor
predictor.run()
# 获取输出
results = []
# 获取输出
output_names = predictor.get_output_names()
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_handle(name)
output_data = output_tensor.copy_to_cpu()
results.append(output_data)
return results
def draw_bbox_image(frame, result, label, threshold=0.5):
for res in result:
cat_id, score, bbox = res[0], res[1], res[2:]
if score < threshold:
continue
for i in bbox:
int(i)
xmin, ymin, xmax, ymax = bbox
cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), (255,0,255), 2)
#print('category id is {}, bbox is {}'.format(cat_id, bbox))
try:
label_id = label[int(cat_id)]
# #cv2.putText(图像, 文字, (x, y), 字体, 大小, (b, g, r), 宽度)
cv2.putText(frame, label_id, (int(xmin), int(ymin-2)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 2)
cv2.putText(frame, str(round(score,2)), (int(xmin), int(ymin+8)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,255,0), 2)
except KeyError:
pass
def show_price(frame, result, label, price, threshold=0.5):
w, h, _ = frame.shape
price_sum = 0 #记录总价
label_sum = [] #记录购买的食物
for res in result:
cat_id, score, bbox = res[0], res[1], res[2:]
if score < threshold:
continue
label_sum.append(label[int(cat_id)])
price_sum += int(price[int(cat_id)])
cv2.putText(frame, "price:"+str(price_sum), (int(w-4), 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,255), 2)
if len(label_sum) > 0:
print("您挑选了%d份食物,总共%d元" % (len(label_sum),price_sum))
else:
print("请挑选食物")
return label_sum,price_sum
class Camera:
def __init__(self, src=0):
self.src = src
self.stream = cv2.VideoCapture(src)
self.stopped = False
self.thread = threading.Thread(target=self.update, args=())
for _ in range(10): #warm up the camera
(self.grabbed, self.frame) = self.stream.read()
def start(self):
self.thread.start()
def update(self):
while True:
if self.stopped:
return
(self.grabbed, self.frame) = self.stream.read()
def read(self):
return self.grabbed, self.frame
def stop(self):
self.stopped = True
def release(self):
self.stream.release()
def isOpened(self):
return self.stream.isOpened()
2. GUI.py
当摄像头采用多线程时系统运行过程中会出现意外的现象,因此这里摄像头不采用多线程。
from glob import glob
import cv2
import tkinter
from tkinter import messagebox
import numpy as np
from PIL import Image,ImageTk
import matplotlib.pyplot as plt
import time
from detect import *
'''预测模型准备工作开始'''
# 从.txt文件中读取label
f = open("./label_list.txt")
label_list = f.read().splitlines()
label = [i.split(":")[0] for i in label_list]
price = [i.split(":")[1] for i in label_list]
print(label)
print(price)
f.close()
# 配置模型参数
model_file = "./model/yolo/model.pdmodel"
params_file = "./model/yolo/model.pdiparams"
# 初始化预测模型
predictor = predict_config(model_file, params_file)
cap = cv2.VideoCapture("nvarguscamerasrc !video/x-raw(memory:NVMM), width=640, height=480, format=NV12, framerate=30/1 !nvvidconv flip-method=0 ! videoconvert ! video/x-raw, format=BGR ! appsink")
# cap = Camera("nvarguscamerasrc \
# !video/x-raw(memory:NVMM), width=640, height=480, format=NV12, framerate=30/1\
# !nvvidconv flip-method=0 ! videoconvert ! video/x-raw, format=BGR ! appsink")
# cap.start()
# 图像尺寸相关参数初始化
ret, img = cap.read()
if ret==False:
while True:
print("error")
im_size = 608 #开启TensorRT加速后改为608,否则为640
scale_factor = np.array([im_size * 1. / img.shape[0], im_size * 1. / img.shape[1]]).reshape((1, 2)).astype(np.float32)
im_shape = np.array([im_size, im_size]).reshape((1, 2)).astype(np.float32)
# cap.stop()
cap.release()
'''预测模型准备工作结束'''
'''tkinter准备'''
win = tkinter.Tk()
win.title("餐厅自助结账系统")
win.geometry("600x570")
image_path = '1.jpg' #系统初始封面地址
root = win
cap = None
#设置显示的图像大小
img_width = 550
img_height=400
#图像处理
def TKImages(frame):
#摄像头翻转
#frame = cv2.flip(frame,1)
image =cv2.cvtColor(frame,cv2.COLOR_BGR2RGBA)
image = image.astype(np.uint8)
PILimage = Image.fromarray(image)
PILimage = PILimage.resize((img_width,img_height),Image.ANTIALIAS)
try:
tkImage = ImageTk.PhotoImage(image=PILimage)
except:
return 0
return tkImage
def Canvas():
# 创建画布
canvas = tkinter.Canvas(root, bg='white', width=img_width, height=img_height)
canvas.place(x=25, y=35)
# 创建标签
label1 = tkinter.Label(root, text='餐厅自助结账系统', font=('黑体', 14), width=15, height=1)
# `anchor=nw`则是把图片的左上角作为锚定点
label1.place(x=223, y=0, anchor='nw')
label2 = tkinter.Label(root, text='制作人:陈悦江', font=('黑体', 14), width=15, height=1)
# `anchor=nw`则是把图片的左上角作为锚定点
label2.place(x=430, y=510, anchor='nw')
return canvas
#关闭系统
def Destroy_all():
global cap
if cap != None and cap.isOpened():
#cap.stop()
cap.release()
cv2.destroyAllWindows()
root.destroy()
#这里需要将tkImage设置为全局变量,不然显示不出图片
tkImage=''
def set_BackGround():
global tkImage
canvas = Canvas()
img = cv2.imread(image_path)
tkImage = TKImages(img)
canvas.create_image(0, 0, anchor='nw', image=tkImage)
#停止检测函数
def Close_Video():
global cap
#cap.stop()
cap.release()
cv2.destroyAllWindows()
Init()
#初始化整个界面
def Init():
set_BackGround()
btn_2 = tkinter.Button(root, text='开始检测', font=('黑体', 14), height=1, width=15,command=lambda: Detect_Real_Time())
btn_2.place(x=220, y=435)
btn_close=tkinter.Button(root,text='退出检测',font=('黑体', 14), width=15,height=1,command=lambda: Destroy_all())
btn_close.place(x=220,y=480)
def Detect_Real_Time():
print("开始检测")
global cap
cap = cv2.VideoCapture("nvarguscamerasrc !video/x-raw(memory:NVMM), width=640, height=480, format=NV12, framerate=30/1 !nvvidconv flip-method=0 ! videoconvert ! video/x-raw, format=BGR ! appsink")
# cap = Camera("nvarguscamerasrc \
# !video/x-raw(memory:NVMM), width=640, height=480, format=NV12, framerate=30/1\
# !nvvidconv flip-method=0 ! videoconvert ! video/x-raw, format=BGR ! appsink")
#cap.start()
#停止检测按钮
btn = tkinter.Button(root, text='停止检测', font=('黑体',14),width=15,height=1,command=lambda :Close_Video())
btn.place(x=220, y=435)
#退出检测按钮
btn_close=tkinter.Button(root,text='退出检测',font=('黑体', 14), width=15,height=1,command=lambda: Destroy_all())
btn_close.place(x=220,y=480)
canvas = Canvas()
i=0 #标志位
while True:
print("正在检测")
'''目标检测'''
OK,frame=cap.read()
if OK==False:
print('检测失败')
break
# 预处理
data = preprocess(frame, im_size)
#time_start = time.time()
# 预测
result = predict(predictor, [im_shape, data, scale_factor])
#print('Time Cost:{}'.format(time.time()-time_start) , "s")
# 绘制边框
draw_bbox_image(frame, result[0], label, threshold=0.7)
#显示价格
label_sum, price_sum = show_price(frame, result[0], label, price, threshold=0.7)
if len(label_sum) > 0: #判断识别到的种类是否大于0
if i == 0: #第一次识别到
label_sum_last = label_sum
i += 1
else:
if label_sum_last == label_sum: # 如果这次识别的跟上一次的一样
i += 1
else:
i = 0
label_sum_last = label_sum
else:
i = 0
'''tkinter'''
pic=TKImages(frame)
canvas.create_image(0,0,anchor='nw',image=pic)
#连续10帧识别到一样的食物
if i==10:
buy = tkinter.messagebox.askquestion(title="请确认支付", message="您挑选了%d份食物,总共%d元" % (len(label_sum),price_sum))
if buy=='yes':
qrcode = Image.open("2.jpg") #二维码地址
qrcode = qrcode.resize((292,400),Image.ANTIALIAS)
qrcode.show()
while True:
c = input("请确认支付:")
if c=='qr' or c=='qx':
break
else:
print("支付失败")
continue
if c=='qr':
print("已支付")
else:
print("已取消")
else:
print("已取消")
i=0
root.update()
root.after(1)
#cap.stop()
cap.release()
cv2.destroyAllWindows()
Init()
win.mainloop()
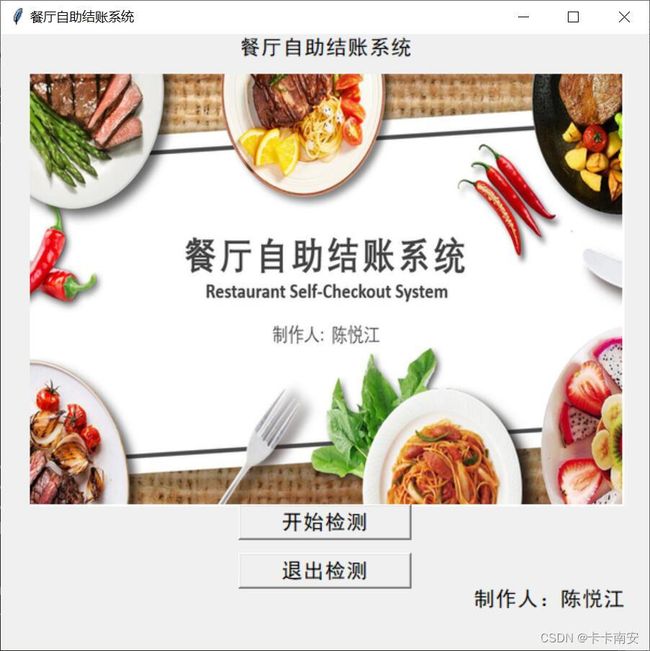
运行GUI.py后得到运行效果如图所示:
7.4 更改预测模式
所有的模式都在predict_config()函数中,其中:
- GPU预测:
config.enable_use_gpu(500, 0)(注释掉该代码即为CPU模式) - 开启IR优化、开启内存优化:
config.switch_ir_optim()和config.enable_memory_optim()(一般都开启) - TensorRT加速:
config.enable_tensorrt_engine()
关于TRT的资料可以参考:https://paddle-inference.readthedocs.io/en/master/optimize/paddle_trt.html ,其中静态shape支持以下模型:

我给大家提供的两个模型分别是ppyolo和yolo3,其中ppyolo不支持TRT加速,GPU预测每帧大约为0.85s左右;yolo3采用GPU预测每帧大约为0.29s左右,TRT加速后每帧大约为0.16s左右。
八. 效果展示
【AI达人训练营第二期】基于Jetson nano的餐厅自助结账系统部署
九. 总结
- 整个部署流程断断续续花了一周的时间完成,在这一周的时间里自己对于目标检测及Linux操作等技术都有了明显地提升,在此非常感谢百度飞桨能提供这次宝贵的机会,同时也非常感谢群里为我解答问题的小伙伴和各位百度飞桨的开源工作者。
- 当前只是完成了一个最基本的部署部分,要想实现项目的落地还有很多功能需要完善,比如提高模型检测精度,与语音播报系统、二维码扫描支付等系统相结合等。