云原生 | 混沌工程工具 ChaosBlade Operator 入门篇
近日,国内多家网站同时发生短期服务不可用现象,一夜冲上圈内热搜。据官方答复,是由于部分服务器机房发生故障,导致网站无法访问。为了避免这种情况,提高系统架构的可靠性,保障业务的连续性,希望能在故障之前找到导致 “崩盘” 的缺口。
十多年前,国外的互联网公司就已经在云化、分布式、微服务等前沿技术的使用过程中,遇到了类似的问题,并由此诞生了混沌工程。
什么是混沌工程?
混沌工程即 Chaos Engineering[1],被定义为在分布式系统上进行实验的学科,目的是建立对系统抵御生产环境中失控条件的能力以及信心。混沌工程属于一门新兴的技术学科,是一种提高技术架构弹性能力的复杂技术手段。最早由 Netflix 技术部门创建了名为 Chaos Monkey 的项目,通过随机性测试,来检测系统架构的健康情况,并设计足够的预案来应对可能到来的新一轮故障。

随着云化技术的发展和云原生(Cloud Native)的概念的提出,混沌工程的反脆弱哲学思想,也引入了云原生体系,可简单高效地为系统提高容错能力。
什么是 ChaosBlade Operator?
ChaosBlade[2] 是阿里巴巴开源的一款遵循混沌工程原理和混沌实验模型的实验注入工具,帮助企业提升分布式系统的容错能力,并且在企业上云或往云原生系统迁移过程中业务连续性保障。

而 ChaosBlade Operator[3] 是 Kubernetes 平台实验场景的实现,将混沌实验通过 Kubernetes 标准的 CRD 方式定义,很方便的使用 Kubernetes 资源操作的方式来创建、更新、删除实验场景,包括使用 kubectl、client-go 等方式执行,而且还可以使用上述的 chaosblade cli 工具执行。
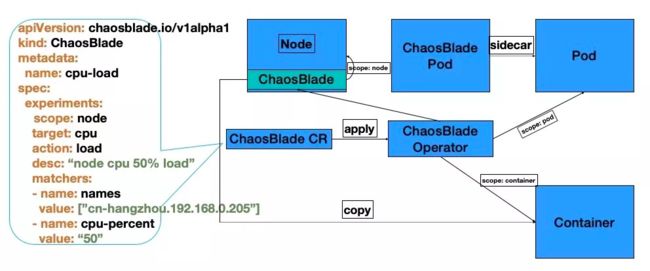
把实验定义为 Kubernetes CRD 资源,将实验模型中的四部分映射为 Kubernetes 资源属性,完美将混沌实验模型与 Kubernetes 声明式设计结合在一起(依靠混沌实验模型便捷开发场景,并结合 Kubernetes 设计理念)。
-
通过 kubectl 或者编写代码直接调用 Kubernetes API 来创建、更新、删除混沌实验,可清晰获取资源模拟实验的执行状态,实现 Kubernetes 故障注入的标准化。
-
通过 Chaosblade cli 方式可非常方便的执行 Kubernetes 实验场景,查询实验状态等。
-
ChaosBlade 混沌实验模型与 Kubernetes CRD 的结合,实现基础资源、应用服务、Docker 容器等场景复用,方便 Kubernetes 场景的扩展。
支持的场景
目前支持的实验场景有以下三大类(持续更新中):

部署 ChaosBlade Operator
执行 Kubernetes 实验场景前,需提前部署 ChaosBlade Operator。
Helm 包下载地址:https://github.com/chaosblade-io/chaosblade-operator/releases
本系列文章默认 Helm v3 版本
注意:需要新建一个 namespace !
部署指令:
helm install kube-system/chaosblade-operator-1.2.0-v3.tgz
helm install chaosblade-operator chaosblade-operator-1.2.0-v3.tgz --namespace chaosblade
回显示例:

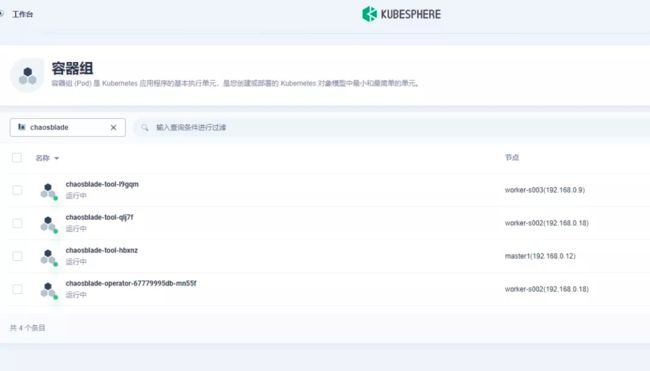
ChaosBlade Operator 启动后,将在每个节点分别部署 chaosblade-tool 和 chaosblade-operator Pod。通过如下指令查看部署结果,若 Pod 都处于 Running 状态,则部署成功。
kubectl get pod -n chaosblade -o wide | grep chaosblade
查询部署结果示例:

关于部署失败的常见原因,请关注后续混沌工程工具系列专题介绍。
实验环境
本系列文章将使用在 KubeSphere 上安装的 ChaosBlade Operator,对 RadonDB 系列容器化产品进行测试。
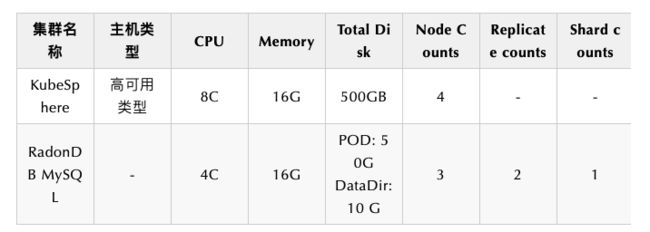
KubeSphere 环境参数:
-
规格 8 核 16G
-
磁盘大小 500GB
-
节点数 4
在 KubeSphere 环境部署成功后,控制台状态如下图所示。
测试对象
基于 KubeSphere 平台的 RadonDB MySQL 容器化数据库进行测试。
RadonDB MySQL 部署说明请参见 在 KubeSphere 中部署 RadonDB MySQL 集群。
环境参数
测试环境部署完成后,即可从以下五个针对节点的场景做相应验证。
CPU 负载场景
1. 测试目标
指定节点做 CPU 负载 80% 验证。
2. 开始测试
配置 yaml 测试参数值。
apiVersion: chaosblade.io/v1alpha1
kind: ChaosBlade
metadata:
name: cpu-lode
spec:
experiments:
- scope: node
target: cpu
action: fulllode
desc: "increase node cpu load by names" #实验模型名称
matchers:
- name: names
value:
- "worker-s001" #测试对象 node 名称
- name: cpu-percent
value: "80" #节点负载百分比
- name: ip
value:192.168.0.20 #节点负载百分比
选择一个节点,修改 node_cpu_load.yaml 中的 names 值。

3. 测试验证
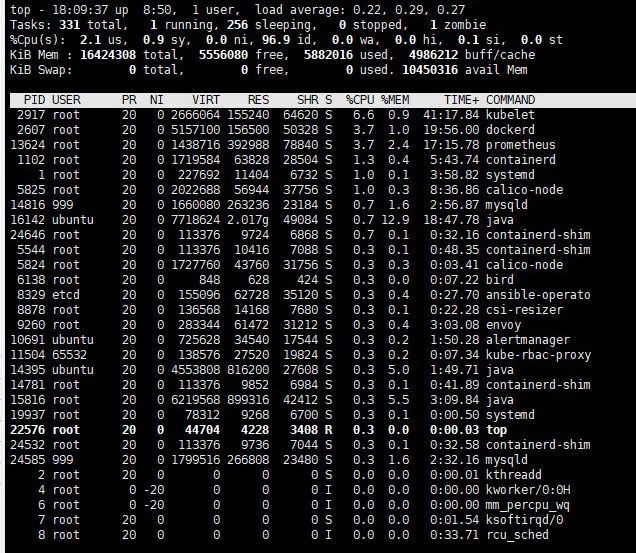
在 Node 节点,使用 top 命令可以看到节点 CPU 达到负载 80% 预期效果。
网络延迟场景
1. 测试准备
登录 Node 节点,使用 ifconfig 命令查看网卡信息,将系统默认的网卡名称指定到 eth0。
2. 测试目标
指定节点 worker-s001 添加 3000 毫秒访问延迟,延迟时间上下浮动 1000 毫秒。
3. 开始测试
选择一个节点,修改 delay_node_network_by_names.yaml 中的 names 值。对 worker-s001 节点访问丢包率 100%。
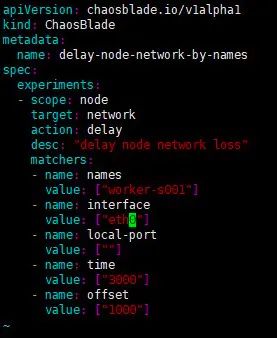
开始测试。
kubectl apply -f delay_node_network_by_names.yaml
![]()
查看实验状态。
kubectl get blade delay-node-network-by-names -o json
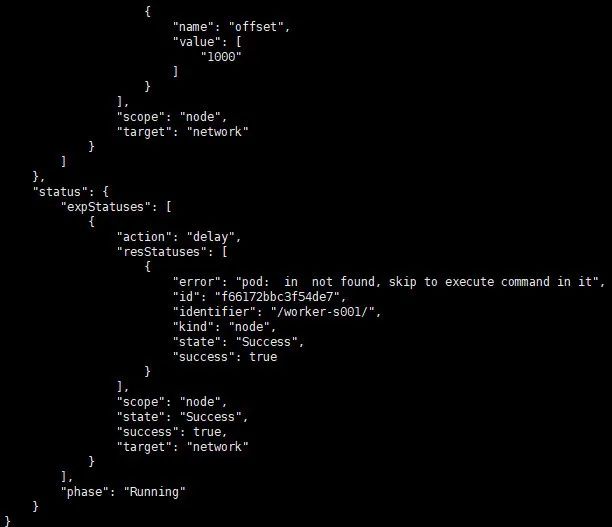
4. 测试验证
从节点访问 Guestbook。
$ time echo "" | telnet 192.168.0.18
echo "" 0.00s user 0.00s system 35% cpu 0.003 total
telnet 192.168.1.129 32436 0.01s user 0.00s system 0% cpu 3.248 total

停止测试。可以删除测试进程或者直接删除 blade 资源。
kubectl delete -f delay_node_network_by_names.yaml
kubectl delete blade delay-node-network-by-names
![]()
网络丢包场景
1. 测试目标
指定节点注入丢包率 100% 的故障。
2. 开始测试
选择一个节点,修改 loss_node_network_by_names.yaml 中的 names 值。

执行以下命令,开始测试。
kubectl apply -f loss_node_network_by_names.yaml
![]()
执行以下命令,查看实验状态。
kubectl get blade loss-node-network-by-names -o json
3. 测试验证
端口为 Guestbook nodeport 端口,访问实验端口无响应,但是访问未开启实验的端口可以正常使用。
获取节点 IP。
$ kubectl get node -o wide

从实验节点访问 Guestbook - 无法访问。
$ telnet 192.168.0.20
![]()
从非实验节点访问 Guestbook - 正常访问。
$ telnet 192.168.0.18
此外还可直接从浏览器访问地址,验证测试结果。
停止测试。可以删除测试进程或者直接删除 blade 资源。
kubectl delete -f delay_node_network_by_names.yaml
kubectl delete blade delay-node-network-by-names
![]()
kill 指定进程
1. 测试目标
删除指定节点上的 MySQL 进程。
2. 开始测试
选择一个节点,修改 kill_node_process_by_names.yaml 中的 names 值。

执行以下命令,开始测试。
$ kubectl apply -f kill_node_process_by_names.yaml
![]()
执行以下命令,查看实验状态。
kubectl get blade kill-node-process-by-names -o json
执行以下命令,查看实验状态。

3. 测试验证
进入实验 node。
$ ssh 192.168.0.18
查看 mysql 进程号。
$ ps -ef | grep mysql
root 10913 10040 0 14:10 pts/0 00:00:00 grep --color=auto mysql
可以看到进程号发生了变化。
$ ps -ef | grep mysql
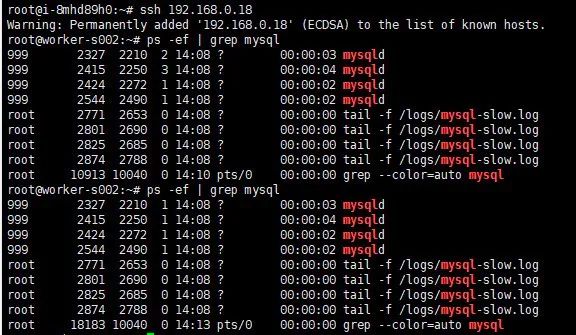
MySQL 的进程号发生改变,说明被杀掉后,又被重新拉起。
停止测试。可以删除测试进程或者直接删除 blade 资源。
kubectl delete -f delay_node_network_by_names.yaml
kubectl delete blade delay-node-network-by-names
![]()
stop 指定进程
1. 测试目标
挂起指定节点上的 MySQL 进程。
2. 开始测试
选择一个节点,修改 stop_node_process_by_names.yaml 中的 names 值。
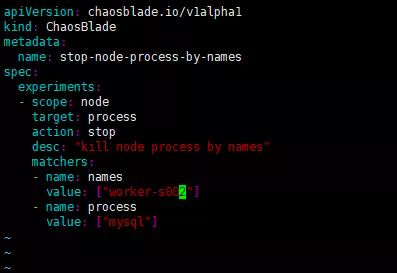
执行以下命令,开始测试。
$ kubectl apply -f stop_node_process_by_names.yaml
![]()
执行以下命令,查看实验状态。
kubectl get blade stop-node-process-by-names -o json
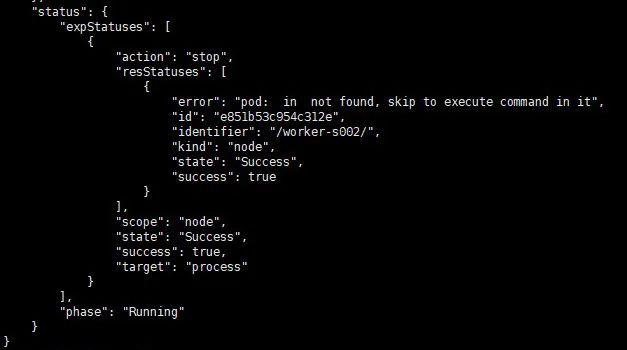
3. 测试验证
进入实验 node。
$ ssh 192.168.0.18
查看 mysql 进程号。
$ ps -ef | grep mysql
root 10913 10040 0 14:10 pts/0 00:00:00 grep --color=auto mysql
可以看到进程号发生了变化。
$ ps -ef | grep

MySQL 的进程号发生改变,说明被杀掉后,又被重新拉起。
停止测试。可以删除测试进程或者直接删除 blade 资源。
kubectl delete -f delay_node_network_by_names.yaml
kubectl delete blade delay-node-network-by-names
![]()
结语
通过使用 ChaosBlade Operator 对 KubeSphere Node 资源进行混沌工程实验,可得出如下结论:
对于 Node 节点,ChaosBlade 依旧有简单的配置及操作来完成复杂的实验,可以通过自由组合,实现各种 Node 节点级别的复杂故障,验证 Kubernetes 集群的稳定性及可用性。同时当真正的故障来临时,由于早已模拟了各种故障情况,可以快速定位故障源,做到处变不惊,轻松处理故障。
[1]. 混沌工程原则:https://principlesofchaos.org
[2]. ChaosBlade:https://github.com/chaosblade-io/chaosblade
[3]. ChaosBlade Operator:https://github.com/chaosblade-io/chaosblade-operator
[4]. Kubernetes 中文文档:https://chaosblade-io.gitbook.io/chaosblade-help-zh-cn/blade
作者
丁源 RadonDB 测试负责人