一文带你理解云原生

作者:William 孟祥龙,腾讯 CDG 系统架构师,从事云原生技术赋能金融科技。
本文是一篇云原生的关键知识科普,希望给大家提供一扇云原生的“窗户”,传达三个目标:1、透过窗户看到一棵大树代表:云原生的蓝图全貌;2、树上会有很多核心树干代表:云原生的关键技术;3、希望树干上能摘到果实代表:云原生对我的启发。
开始阅读文章前,请角色切换:设想你作为一位中小型 IT 公司 CTO,面对云原生技术决策,你需要回答两个问题:
1、为什么需要上云?

2、上云有何弊端?

作为一家公司的技术决策者,必须理解上云的利与弊,并结合公司各阶段发展目标给出最适合的技术方案。
1 云原生-概述

1.1 云原生-定义



云原生的定义,业界也是“百家争鸣”各持观点,从技术视角理解云原生会相对清晰。云原生的关键技术包括:

• 微服务架构:服务与服务之间通过高内聚低耦合的方式交互;
• 容器:作为微服务的最佳载体,提供了一个自包含的打包方式;
• 容器编排:解决了微服务在生产环境的部署问题;
• 服务网络:作为基础设施,解决了服务之间的通信;
• 不可变基础:设施提升发布效率,方便快速扩展;
• 声明式 API:让系统更加健壮;
命令式 API:可以直接发出让服务器执行的命令,例如:“运行容器”、”停止容器”等;
声明式 API:可以声明期望的状态,系统将不断地调整实际状态,直到与期望状态保持一致。
• DevOps:缩短研发周期,增加部署频率,更安全地方便:
Culture :达成共识
Automation:基础设施自动化
Measurement:可度量
Sharing:你中有我,我中有你
【私人观点】
云原生的定义:应用因云而生,即云原生。
应用原生被设计为在云上以最佳方式运行,充分发挥云的优势,是上云的最短路径。
1.2 云原生-技术生态


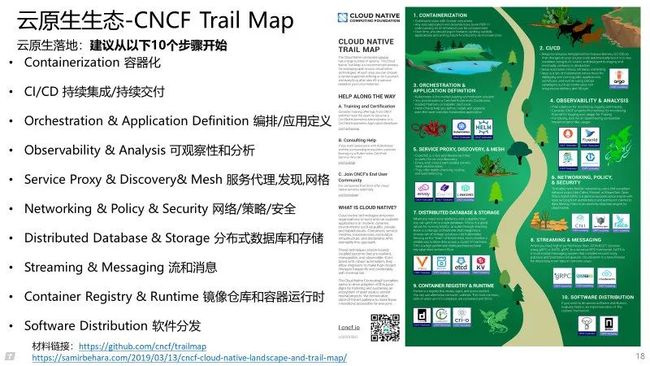
1.3 云原生-关键技术
云原生关键技术包括:微服务,容器,容器编排,服务网络,不可变基础,声明式 API。
1.3.1 微服务
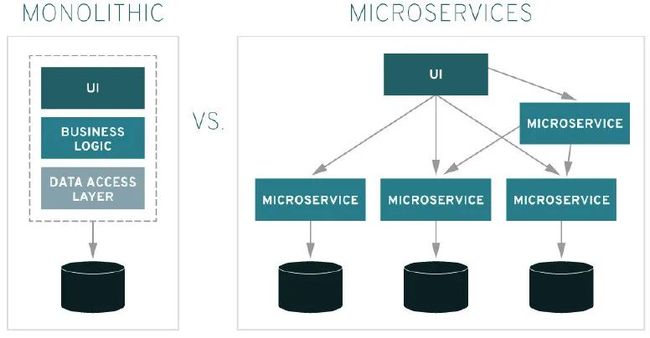
微服务是一种用于构建应用的架构方案。
将一个复杂的应用拆分成多个独立自治的服务,服务与服务间通过“高内聚低耦合”的形式交互。

微服务典型架构包括:
服务重构:单体改造成符合业务的微服务架构;
服务注册与发现:微服务模块间的服务生命周期管理;
服务网关:身份认证、路由服务、限流防刷、日志统计;
服务通信:通信技术方案如,RPC vs REST vs 异步消息;
可靠性:服务优雅降级,容灾,熔断,多副本。
1.3.2 容器
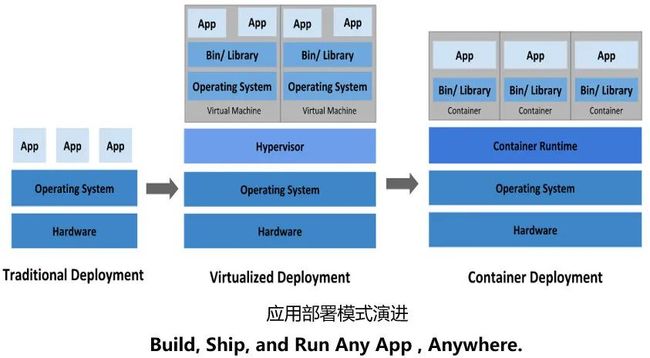
容器是一种打包应用的方式,可以打包应用中的所有软件和软件所依赖的环境,并可实现跨平台部署。
容器关键技术:namespac 视图隔离,cgroups 资源隔离 ,Union File System 联合文件系统。
容器优势:
更高效的利用资源;
更快速的启动时间;
一致性的运行环境。
1.3.3 容器编排

容器编排包括:自动化管理和协调容器的系统,专注于容器的生命周期管理和调度。
核心功能:
容器调度:依据策略完成容器与母机绑定;
资源管理:CPU、MEM、GPU、Ports、Device;
服务管理:负载均衡、健康检查。
1.3.4 服务网格
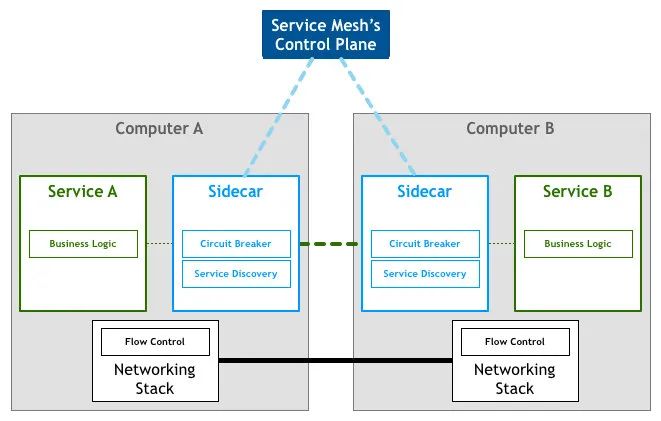
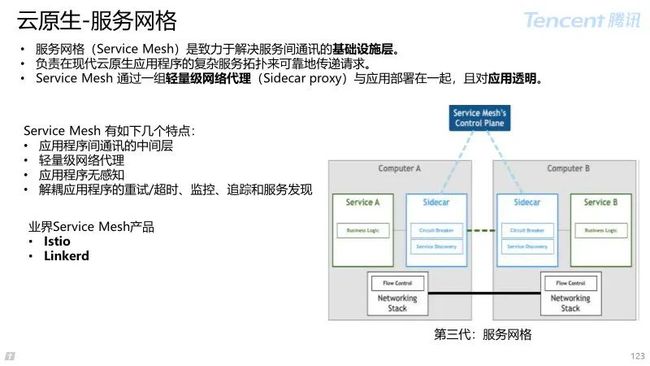
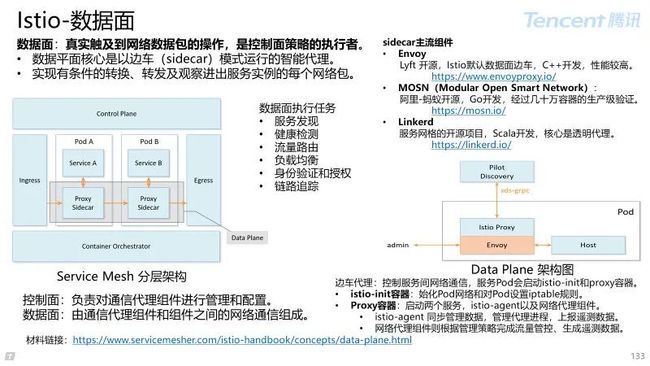
服务网格(Service Mesh)是致力于解决服务间通讯的基础设施层。
Service Mesh 应对云原生应用的复杂服务拓扑,提供可靠的通信传递;
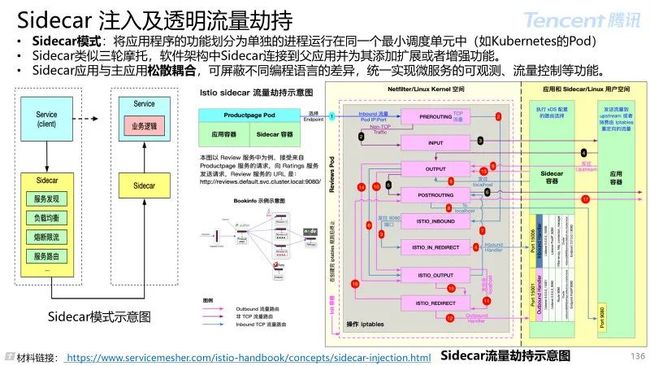
通过一组轻量级网络代理(Sidecar proxy),与应用程序代码部署在一起来实现,且对应用程序透明。
Service Mesh 特点:
应用程序间通讯的中间层;
轻量级网络代理,应用程序无感知;
解耦应用的重试、监控、追踪、服务发现。
Service Mesh 主流组件:Istio、MOSN(Modular Open Smart Network)Linkerd。
1.3.5 不可变基础设施

不可变基础设施(Immutable Infrastructure)(宠物 VS 牲畜)
任何基础设施实例(服务器、容器等各种软硬件)一旦创建之后便成为一种只读状态,不可对其进行任何更改;
如果需要修改或升级实例,唯一方式是创建一批新实例以替换。
不可变基础设施的优势
提升发布应用效率;
没有雪花服务器;
快速水平扩展。
1.3.6 声明式 API

命令式 API:可直接发出让服务器执行的命令,例如:“运行容器”、“停止容器”等;
声明式 API:可声明期望的状态,系统将不断地调整实际状态,直到与期望状态保持一致。
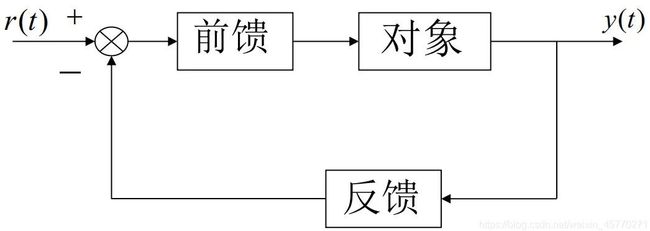
为什么声明式使系统更加健壮?
可以类比理解成自动化工程学的闭环自适应模型。
1.3.7 DevOps
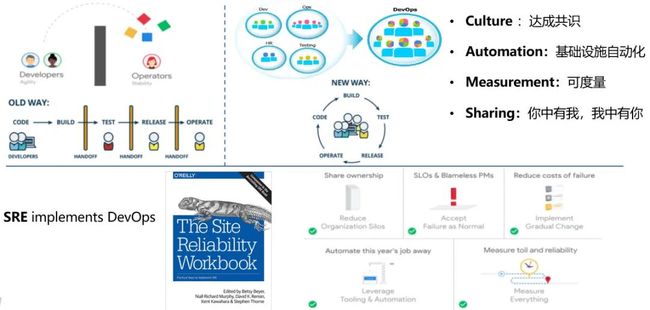
DevOps 目标 :缩短开发周期,增加部署频率,更可靠地发布。
从历史上开发和运维相对孤立到开发和运维之间建立合作,可以增加信任,更快速地发布新版本。
DevOps 是一组过程,方法和系统的统称包括:
Culture:
文化是 DevOps 中的第一成功要素。
由于目标不同,开发和运维形成一堵墙,DevOps 通过建立开发和运维之间合作和沟通的文化来消除墙。
Automation:
自动化软件的开发和交付,通常包含持续集成,持续交付和持续部署,云原生时代还包括基础架构的自动化,即 IaC(Infrastructureas code)。
Measurement:
度量尤其重要,通过客观的测量来确定正在发生的事情的真实性,验证是否按预期进行改变。并为不同职能部门达成一致建立客观基础。
Sharing:
开发和运维团队之间长期存在摩擦的主要原因是缺乏共同的基础。
开发参与运维值班,参与软件的部署和发布,运维参与架构设计。
2 容器-Docker

2.1 Docker 概述

为什么学习容器技术?
云时代从业者:Docker 已成云平台运行分布式、微服务化应用的行业标准。
作为有技术追求的程序员,有必要理解云原生的关键技术:容器。

Docker 核心概念:镜像、容器、仓库。
镜像(Image):
一个只读模板;
由一堆只读层(read-only layer)重叠;
统一文件系统(UnionFileSystem)整合成统一视角。
容器(Container):
通过镜像创建的相互隔离的运行实例;
容器与镜像区别:最上面那一层可读可写层;
运行态容器定义:一个可读写的统一文件系统,加上隔离的进程空间,以及包含在其中的应用进程。
仓库(Repository):
集中存放镜像文件的地方;
Docker Registry 可包含多个仓库(Repository),每个仓库可包含多个标签(Tag),每个标签对应一个镜像。



2.2 Docker 关键技术
2.2.1 Namespace 视图隔离
Linux namespace 是一种内核级别的环境隔离机制,使得其中的进程好像拥有独立的系统环境。


Network namespace 在 Linux 中创建相互隔离的网络视图,每个网络名字空间都有自己独立的网络配置,包括:网络设备、路由表、IPTables 规则,路由表、网络协议栈等。(默认操作是主机默认网络名字空间)
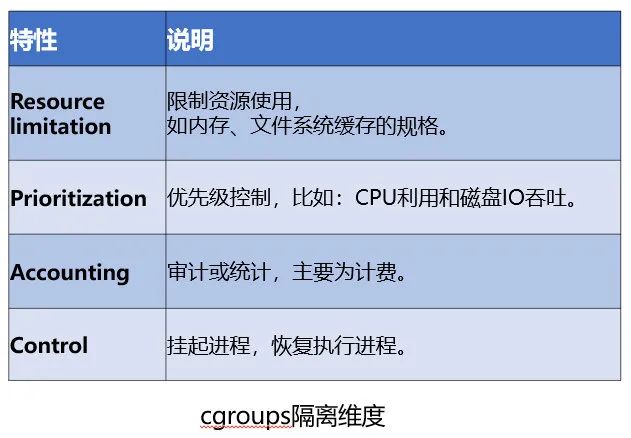
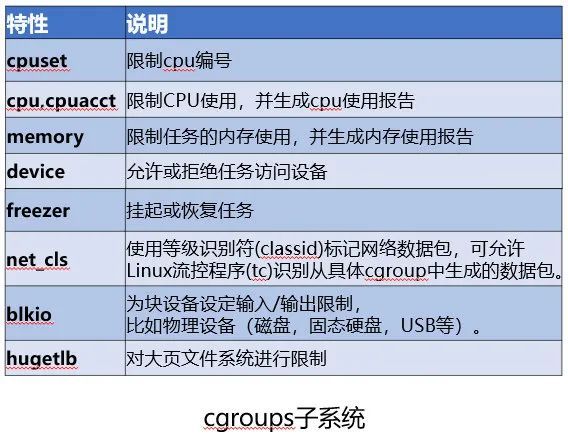
2.2.2 control groups(资源隔离)
Linux Control Group 是内核用于限制进程组资源使用的功能。资源包括:CPU,内存,磁盘 IO 等。
2.2.3 Union File System(联合文件系统)

Union File System, 联合文件系统:将多个不同位置的目录联合挂载(union mount)到同一个目录下。
Docker 利用联合挂载能力,将容器镜像里的多层内容呈现为统一的 rootfs(根文件系统);
Rootfs 打包整个操作系统的文件和目录,是应用运行所需要的最完整的“依赖库”。



2.3 Docker-网络技术


Bridge 模式:Docker0 充当网桥,在默认情况下,被限制在 Network Namespace 里的容器进程,是通过 Veth Pair 设备 +宿主机网桥的方式,实现跟同其他容器的数据交换。
一旦一张虚拟网卡被“插”在网桥上,它就会变成该网桥的“从设备”。
从设备会被“剥夺”调用网络协议栈处理数据包的资格,从而“降级”成为网桥上的一个端口。
而这个端口唯一的作用,就是接收流入的数据包,然后把这些数据包全部交给对应的网桥,由网桥完成转发或者丢弃。


Veth 提供一种连接两个 network namespace 的方法。Veth 是 Linux 中一种虚拟以太设备,总是成对出现常被称为 Veth pair。
可以实现点对点的虚拟连接,可看成一条连接两张网卡的网线。一端网卡在容器的 Network Namespace 上,另一端网卡在宿主机 Network Namespace 上。任何一张网卡发送的数据包,都可以对端的网卡上收到。
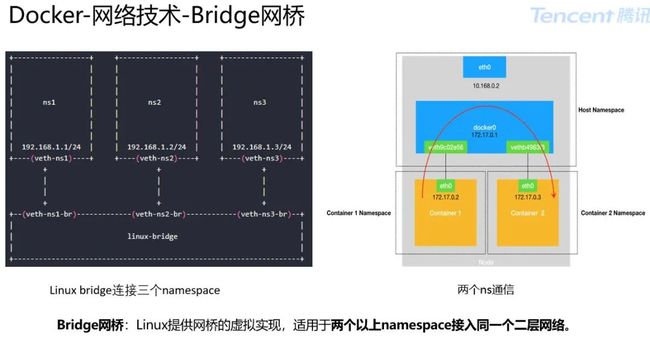
在物理网络中,如果需要连接多个主机,会用交换机。在 Linux 中,能够起到虚拟交换机作用的网络设备,是网桥(Bridge)。它是一个工作在数据链路层的设备,主要功能是根据 MAC 地址学习来将数据包转发到网桥的不同端口(Port)上。
Bridge 网桥类似交换机,两个以上 namespace 接入同一个二层网络。veth pair 一端虚拟网卡加入到 namespace,另一端到网桥上。

路由 routing是通过互联的网络把信息从源地址传输到目的地址的活动,发生在 OSI 模型的第三层(网络层)。Linux 内核提供 IPForwarding 功能,实现不同子网接口间转发 IP 数据包。
路由器工作原理:
路由器上有多个网络接口,每个网络接口处于不同的三层子网上。
根据内部路由转发表将从一个网络接口中收到的数据包转发到另一个网络接口,实现不同三层子网间互通。
3 容器编排-Kubernetes

3.1 概述&架构&核心组件


我认为 Kubernetes 最大成功:让容器应用进入大规模工业生产。
Kubernetes 的提供特性,几乎覆盖一个分布式系统在生产环境运行的所有关键事项。包括:
Automated rollouts and rollbacks(自动化上线和回滚)
使用 Kubernetes 描述已部署容器的所需状态,受控的速率将实际状态更改为期望状态。
Self-healing(自我修复)
Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。
Service discovery and load balancing(服务发现与负载均衡)
Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果进入容器的流量很大,Kubernetes 可以负载均衡并分配网络流量,从而实现部署稳定。
Storage orchestration(存储编排)
Kubernetes 允许你自动挂载选择的存储系统,例如本地存储、公厂商等。
Automatic bin packing(自动装箱)
Kubernetes 允许指定每个容器所需 CPU 和内存(RAM)。当容器指定资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。
Secret and configuration management(安全和配置管理)
Kubernetes 允许存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。你可在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
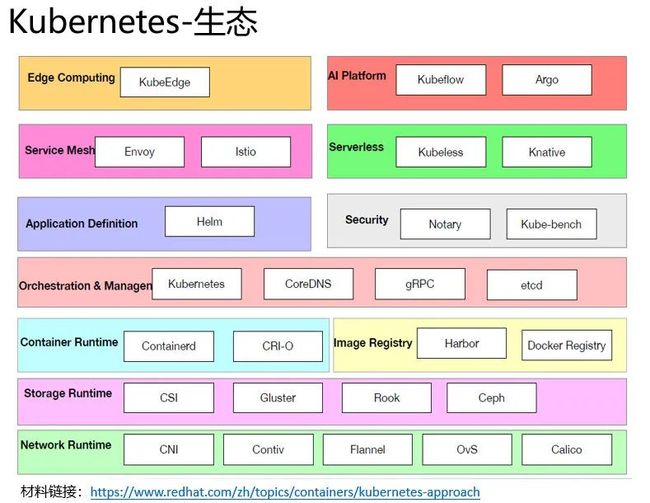

API Service: Kubernetes 各组件通信中枢。
资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制;
为 Pod, Deployment, Service 等各种对象提供 Restful 接口;
与 etcd 交互的唯一组件。
Scheduler:负责资源调度,按照预定调度策略将 Pod 调度到相应的机器。
Predicates(断言):淘汰制
Priorities(优先级):权重计算总分。
Controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等。
etcd:分布式的 K-V 存储,独立于 Kubernetes 的开源组件。
主要存储关键的原数据,支持水平扩容保障元数据的高可用性;
基于Raft 算法实现强一致性,独特的watch 机制是 Kubernetes 设计的关键。
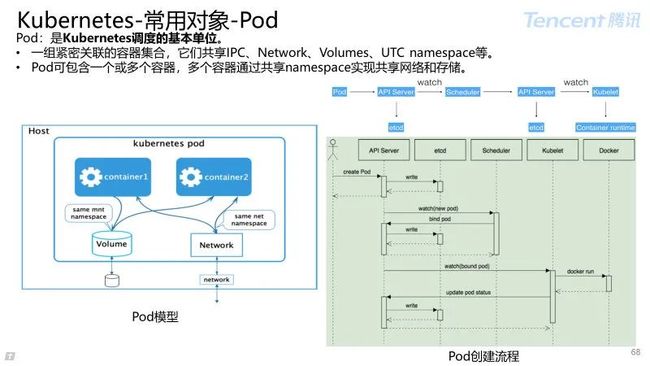
kubelet :负责维护 Pod 的生命周期,同时负责 Volume(CVI)和网络(CNI)的管理。
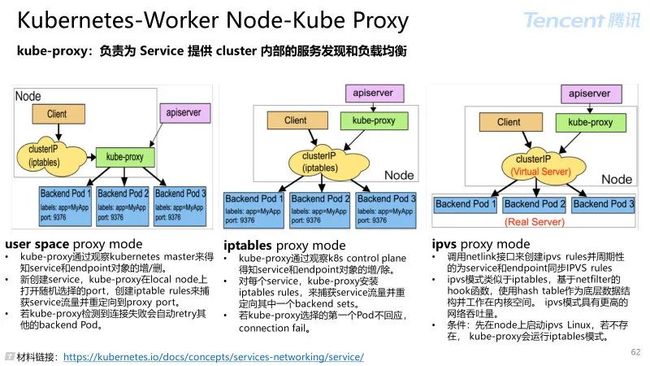
kube-proxy:负责为 Service 提供 cluster 内部的服务发现和负载均衡
kube-proxy 通过在节点上添加 iptables 规则以及从中移除这些规则来管理此端口重新映射过程。




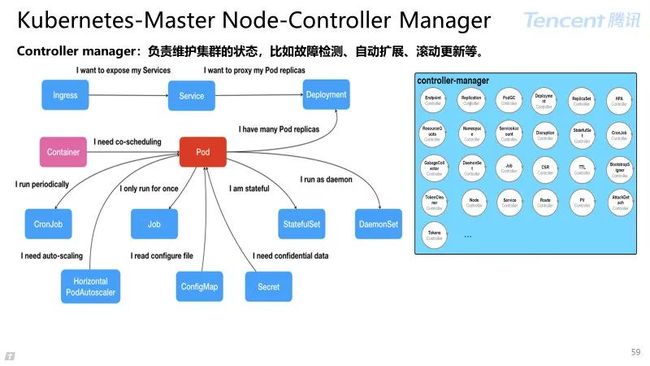
控制器模式的设计思想:
容器类比集装箱,集装箱固然好用,但是如果它各面光秃秃的,吊车还怎么把它吊起来摆放好呢?
Pod 对象其实就是容器的升级版,对容器进行组合,添加更多属性和字段。就好比在集装箱上安装了吊环,Kubernetes 这台“吊车”可以更轻松操作容器。
然而Kubernetes 操作这些“集装箱”的逻辑都是由控制器完成的。
Kubernetes 通过“控制器模式” 的设计思想,来统一编排各种对象和资源。





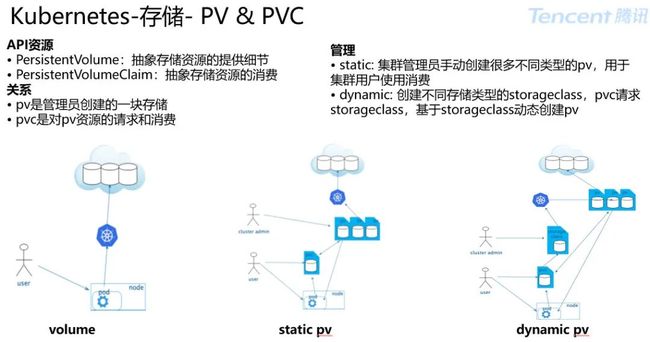
3.2 部署&资源控制&存储

Kubernetes-集群部署架构
所有组件通过 kubelet staticpod 的方式启动保证宿主机各组件的高可用,systemd 提供 kubelet 的高可用;
每个 Master 的使用 hostNetwork 网络,controller-manager 和 scheduler 通过 localhost 连接到本节点 apiserver;
controller-manager 和 scheduler 的高可用通过自身提供的 leader 选举功能(--leader-elect=true);
apiserver 高可用,可通过经典的 haporxy+keepalived 保证,集群对外暴露 VIP;
外部访问通过 TLS 证书,在 LB 节点做 TLS Termination,LB 出来 http 请求到对应 apiserver 实例。apiserver 到 kubelet、kube-proxy 类似。









3.3 Kubernetes-网络技术
3.3.1 对外服务

Service是一个逻辑概念,一组提供相同功能 Pods 的逻辑集合,并提供四层负载统一入口和定义访问策略。
交互流程:Service 可通过标签选取后端服务。匹配标签的 Pod IP 和端口列表组成 endpoints,有 kube-proxy 负责均衡到对应 endpoint。
为什么需要 service?
对外提供入口(容器如何被外部访问);
克服 Pod 动态性(Pod IP 不一定可以稳定依赖);
服务发现和稳定的服务( Pod 服务发现、负载、高可用)。
Service Type 四种方式
Cluster IP:配置 endpoint 列表;
NodePort:默认端口范围:30000-32767,通过 nodeIP:nodePort 访问 ;
LoadBalancer:适用于公有云,云厂商实现负载,配置 LoadBalance 到 podIP ;
ExternalName:服务通过 DNS CNAME 记录方式转发到指定的域名。
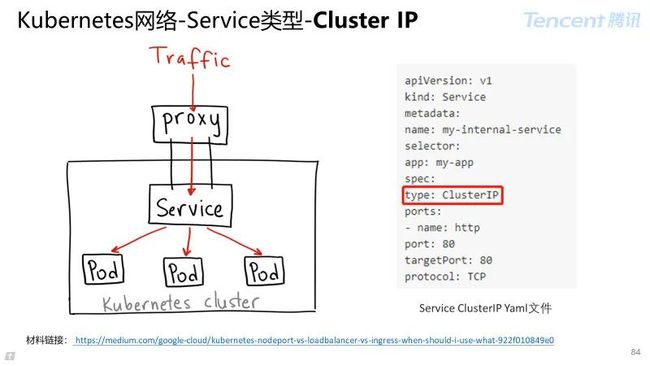
Service Type 为 Cluster IP:
Kubernetes 的默认服务,配置 endpoint 列表,可以通过 proxy 模式来访问该对应服务;
类似通过 Nginx 实现集群的 VIP。
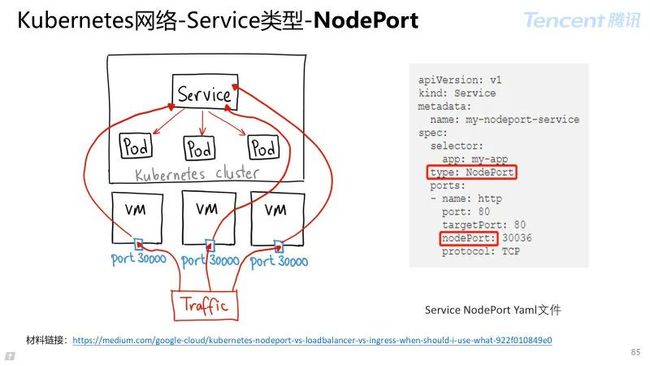
Service Type 为 Node Port:
在集群所有节点上开放特定端口,任何发送到该端口流量借助 Service 的 Iptables 规则链发送到后端 Pod。
注意事项:
每个服务对应一个端口,端口范围只有 30000–32767;
需要感知和发现节点变化,流量转发增加 SNAT 流程,Iptables 规则会成倍增长。
适用场景:服务高可用性要求不高或成本不敏感,例如:样例服务或临时服务。
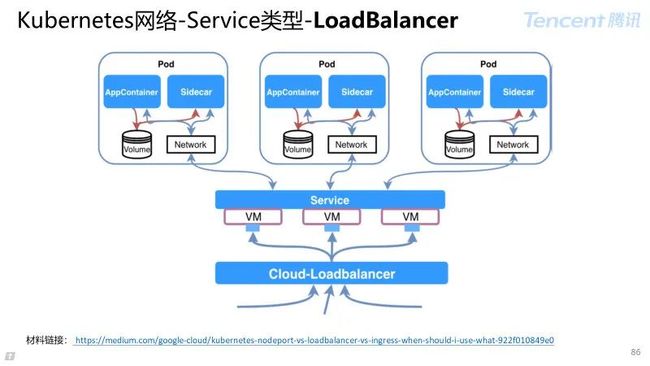
Service Type 为 Load Balancer:
对公网暴露服务建议采用此方式,Service 没有对其行为做任何规范,依赖云厂商 LB 具体实现(云厂商收费服务)如:腾讯公有云:CLB。

Service Type 为 External Name :
DNS 作为服务发现机制,在集群内提供服务名到 Cluster IP 的解析。
CoreDNS :DNS 服务,CNCF 第 04 个毕业项目,KUBERNETES 的 1.11 版本已支持。
CoreDNS 实现的高性能、插件式、易扩展的 DNS 服务端,支持自定义 DNS 记录及配置 upstream DNS Server,可以统一管理 Kubernetes 基于服务的内部 DNS。
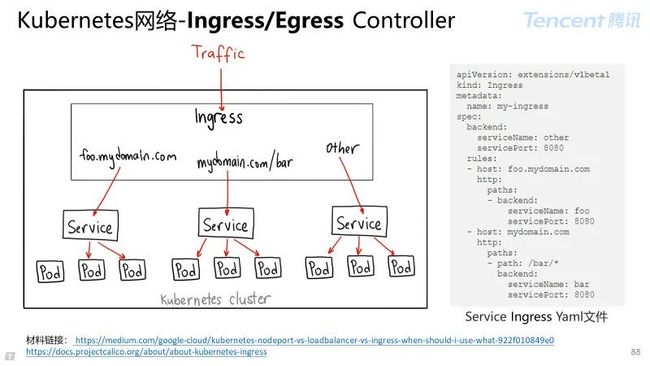
Ingress Controller:定义入流量规则,可做七层 HTTP 负载君合。
Egress Controller:定义出流量规则。
交互流程:通过与 Kubernetes API 交互,动态感知集群 Ingress 规则,按照自定义的规则生成(负载均衡器)配置文件,并通过 reload 来重新加载。
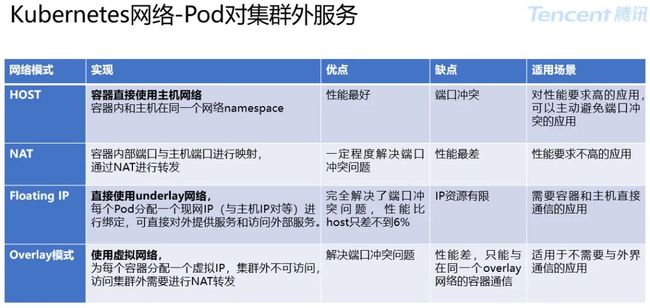
3.3.2 Underlay 与 Overlay 网络

Underlay 网络模式: 底层承载网络,是网络通信的基础。
优势:复用基建,网络扁平,性能优势;
劣势:协作复杂,安全问题,管理成本。
很多场景下业务方希望容器、物理机和虚拟机可以在同一个扁平面中直接通过 IP 进行通信,通过 Floating-IP 网络实现。
Floating-IP 模式将宿主机网络同一网段的 IP 直接配置到容器中。
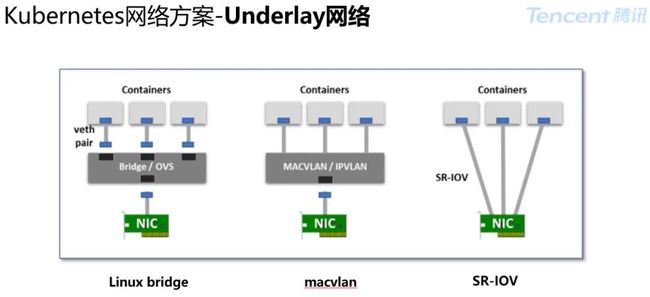
这种模式为了保证容器与宿主机的交换机二层连通,需要在物理机上搭一个虚拟网桥。具体选择哪种网桥,主流有:Linux bridge、MacVlan、SRIOV 三种模式。
BridgeBridge:设备内核最早实现的网桥,性能与 OVS 相当,可以使用到所有场景;
MacVlan:一个简化版的 bridge 设备,为了隔离需要内核,实现时不允许 MacVlan 容器访问其宿主机 IP 和 ServiceCluster IP;
SR-IOV 技术:一种基于硬件的虚拟化解决方案,可提高性能和可伸缩性;
SR-IOV 标准允许在虚拟机之间高效共享 PCIe(快速外设组件互连)设备,并且它是在硬件中实现的,可以获得能够与本机性能媲美的 I/O 性能。

Overlay 网络:是一种建立在另一网络之上的计算机网络。
优势:独立自治,快速扩展,网络策略;
劣势:复杂层级,性能损失,定制成本。
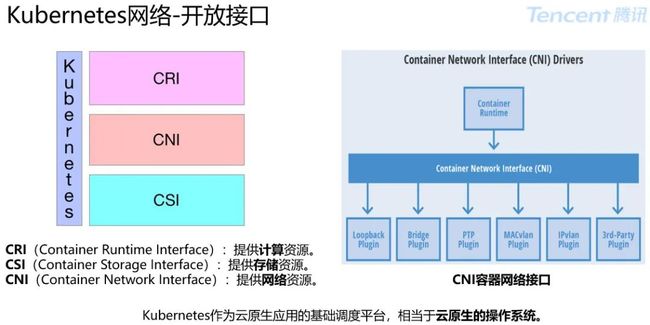
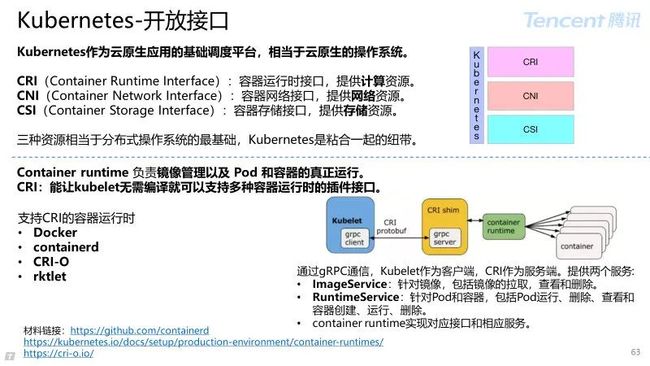
Kubernetes 相当于云原生的操作系统。
有人会问,凭什么云原生的操作系统这杆大旗?
主要原因是:Kubernetes 解决了一个分布式操作系统最核心的计算、存储、网络三种资源。
CNI 容器网络统一标准:
CNCF 项目,为 Linux 容器提供配置网络接口的标准和以该标准扩展插件提供基础函数库;
CNI 命令行调用规范,其插件在主机上直接切换进入容器网络命名空间,为容器创建网络设备,配置 IP,路由信息。
CNI 规范内容:
输入:ADD/DEL 控制指令,CNI 目录,容器 ID,网络命名空间,网卡名称。
配置文件:标准部分:cniVersion,Name,Type,IPAM。
输出:设备列表、IP 资源列表、DNS 信息。
插件应用如:
Bridge:Linux 网桥 CNI 实现,采用网卡对链接网桥和容器;
Host-device:将主机设备直接移动到容器命名空间中;
PTP:创建虚拟网卡对,采用路由方式实现对外互联;
MacVlan:网卡多 Mac 地址虚拟技术完整支持 vlan;
Vlan:Vlan 设备 CNI 实现,允许容器和主机分属不同 LAN;
IPVlan:网卡上基于 IP 实现流量转发。
3.3.3 Overlay 网络-Flannel 方案
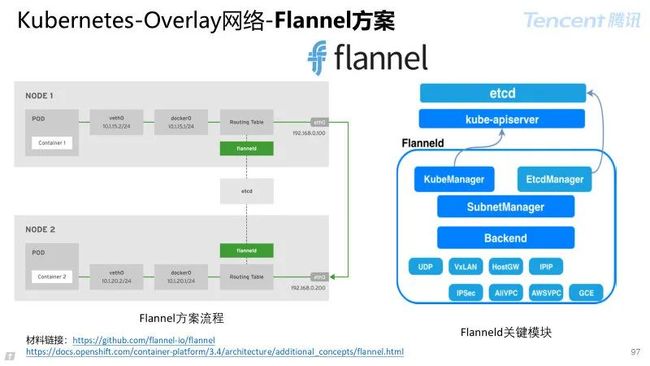
CoreOS(被 Red Hat 收购)为 Kubernetes 专门定制设计的 overlay 网络方案。
03 层网络方案实现:在每台主机部署 flanneld 进程实现网段分配,路由控制,采用多种转发机制实现流量跨机交互。
Flannel 职责
子网管理:每个主机分配唯一的子网;
互联方式:为同 Overlay 平面容器分配唯一 IP。
Etcd 存储:容器之间路由映射;
SubNetManager:子网资源划分、IP 资源申请释放的接口定义;
Backend:针对网络互联方式的接口定义。
UDP,UDP 封包转发,建议仅调试使用;
VxLAN(建议),使用内核 vxlan 特性实现封包转发;
Host-GW,主机 2 层互联情况下较高性能互联方式;
IPIP,使用 IPIP 隧道完成封包和转发;
IPSec,使用 IPSecurity 实现加密封包转发;
AliVPC,对接阿里云 VPC 路由表实现网络互联;
AWSVPC,对接 Amazon VPC 路由表实现网络互联。

Flannel 的单机互联方案:
子网分配:充当虚拟交换机/网关角色,连接所有本机容器,完成虚拟子网构建;
Bridge:通过 NAT 借助主机网络实现外部服务访问;
Veth pair:一端设置到容器网络 namespace,一端链接 bridge 实现容器接入网络;
对外访问:为每个节点分配独立不冲突的 24 位子网。

Overlay 解决方案:跨 Node 的 Pod 之间通信通过 Node 之间的 Overlay 隧道。
职责:路由控制,数据转发。
主要流程:
本节点设置:设备创建、本地路由创建、回写本地信息;
监听其他节点信息:更新 ARP 信息、更新 FDB、更新路由信息。
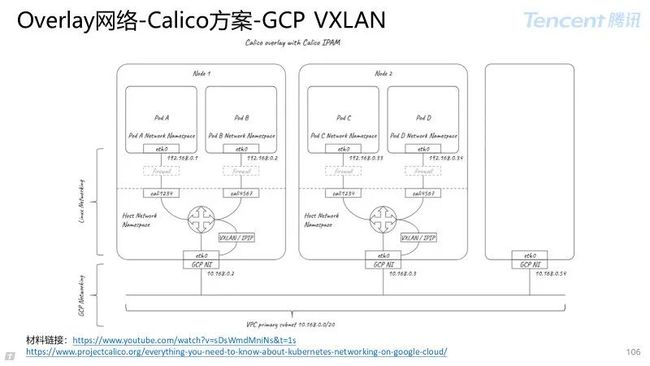
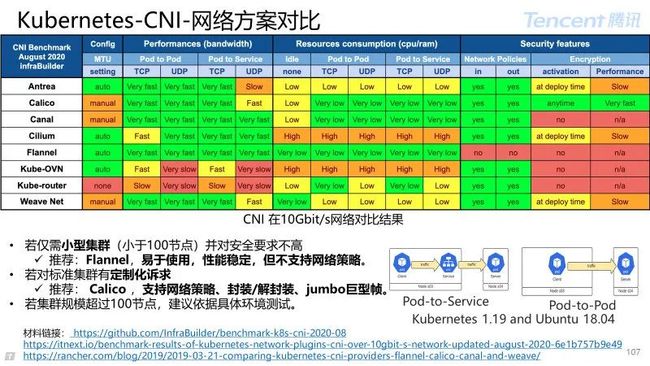
3.3.4 Overlay 网络-Calico 方案


Calico 项目:是纯三层的虚拟网络解决方案,旨在简化、扩展和保护云网络的容器方案。
Calico 优势:
可扩展性:采用 IP 路由支持大规模网络。扩展便利,容错性高;
网络安全:支持 Kubernetes 网络策略,支持自定义网络策略;
广泛集成:集成 Kubernetes ,Mesos,支持 OpenStack,AWS,GCE,Azure。
Calico 不足:
BGP 支持问题:需要网路设备支持 BGP 协议,否则需要追加 IPIP 隧道;
规划 2 层直连:需要节点做良好的规划实现 2 层网络直接互联;
大规模配置复杂:网络规划,手动部署 Route Reflector,增加 API 代理。
关键组件:
BGP Client:和其他节点互联,发布当前节点路由并学习其他节点路由;
Confd:同步节点配置信息启动 BGPClient;
Felix:负责虚拟设备监控,ACL 控制、状态同步的 agent;
Calico:CNI 插件,负责容器设备创建;
Calico-IPAM:CNI 插件,负责容器网段管理与 IP 地址管理;
RouteReflector:对接 BGPclient 实现路由中转;
Etcd/Kube-apiserver:Calico 数据存储;
typha:应对大规模节点接入时作为数据缓存 proxy;
RouteReflector 安装:集群超过100 个节点时强烈建议启用,通过 RR 中转全局路由信息。
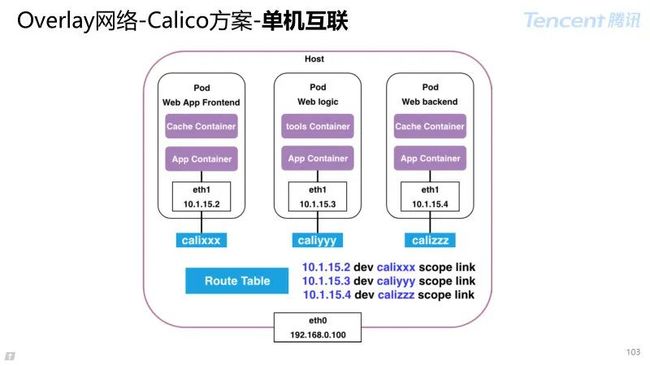
Calico 单机互联方案:
Veth-pair:一端设置到容器,一端放置在主机上,为容器提供网络出入口;
路由策略:针对 IP 和设备设置路由条目,在主机上实现互联。
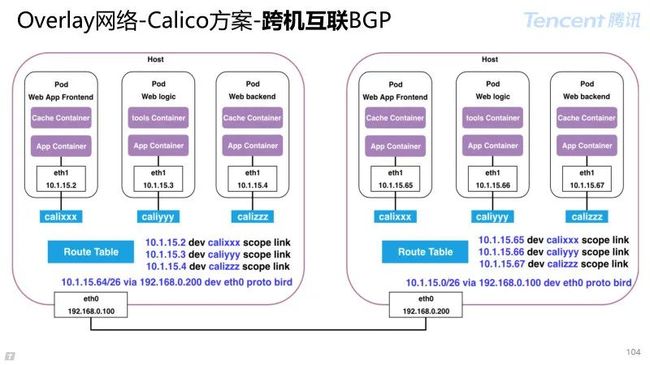
Calico 跨机互联方案:
同网段/BGP 支持:主机之间通过 2 层直连或者网络支持路由转发至目标主机;
跨网段 IPIP 互联:网络设备不支持 BGP 协议情况下,采用 IPIP 隧道实现跨网段互联;
跨网段 VxLAN 互联(Cannel):集成 flannel,底层通过 VxLAN 实现跨机转发。

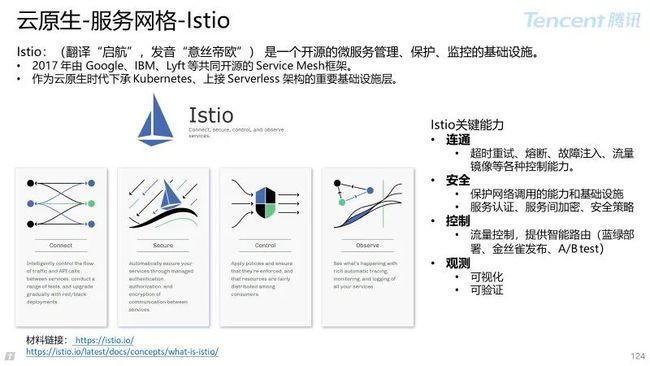
4 服务网格 Istio

4.1 服务网格概述

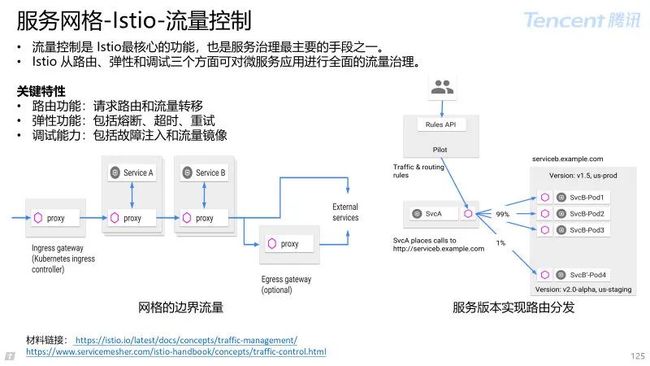
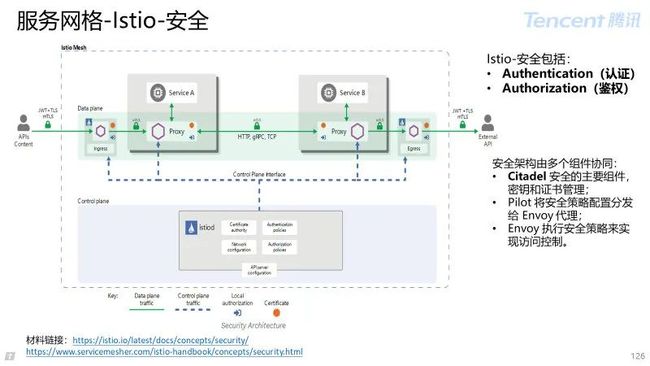
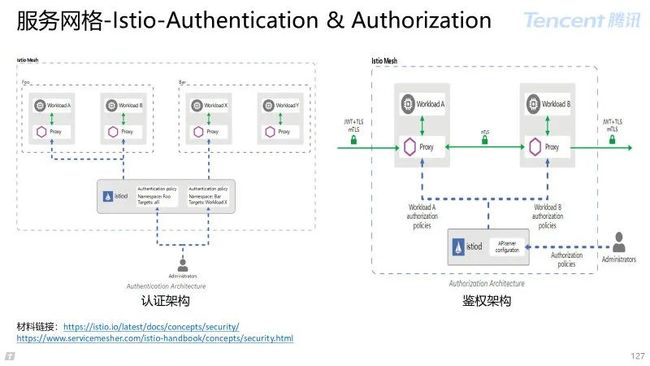


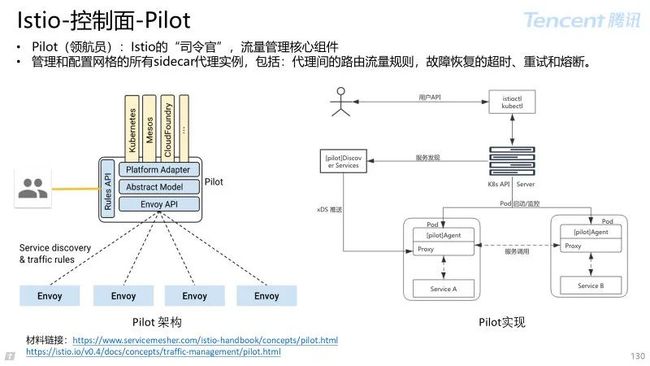
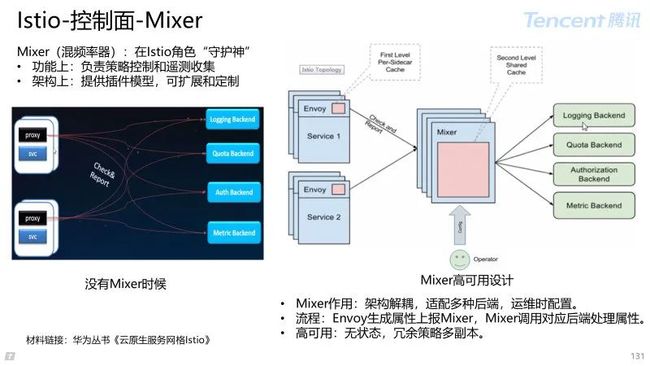
4.2 Istio 控制面

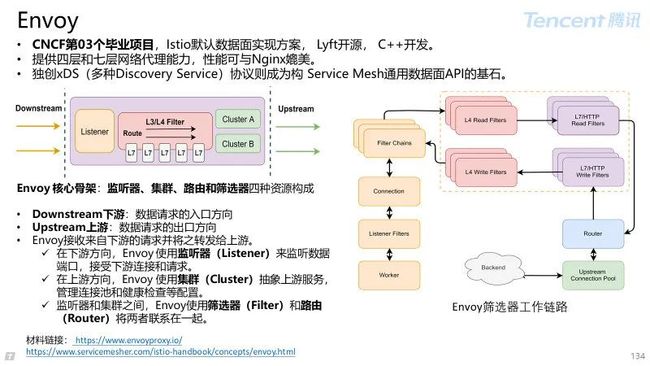
4.3 Istio 数据面




5 云原生-主流组件

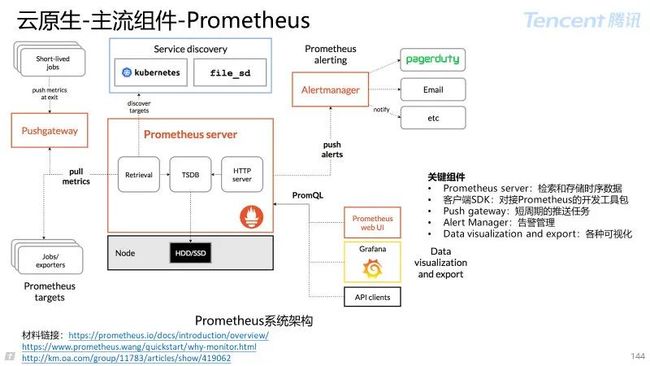
5.1 Prometheus

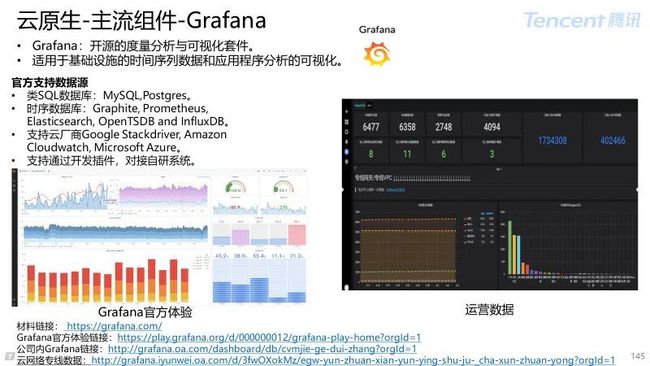
5.2 Grafana
5.3 Elasticsearch + Fluentd + Kibana

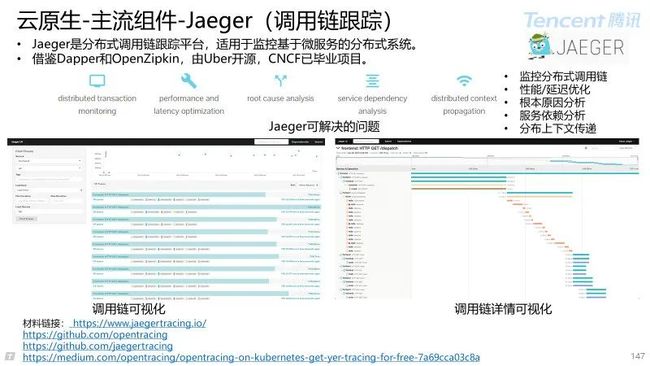
5.4 Jaeger
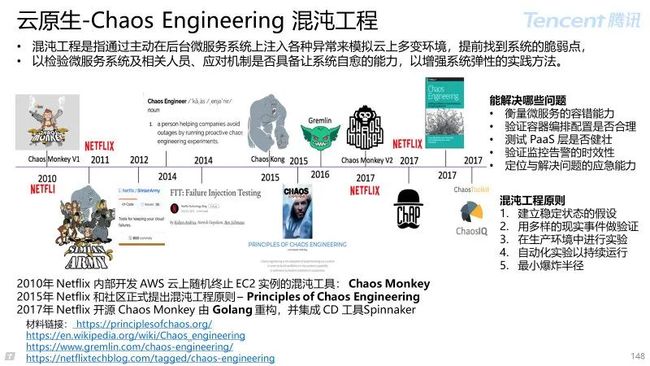
5.5 Chaos Engineering


6 云原生-常用网络技术

6.1 主机网络

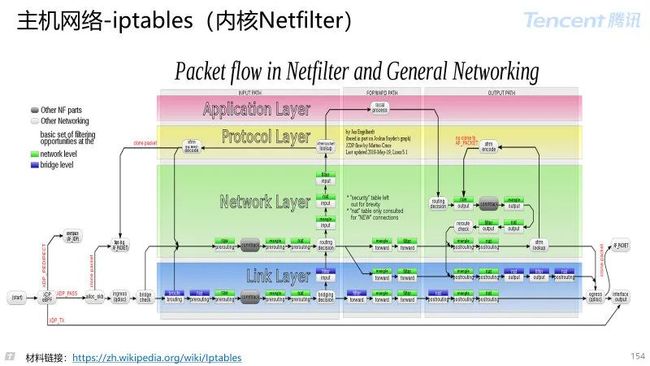
iptables是运行在用户空间的应用软件,通过控制Linux 内核 netfilter,来管理网络数据包的处理和转发。
存在“表(tables)”、“链(chain)”和“规则(rules)”三个层面:
每个“表”指的是不同类型的数据包处理流程,例如 filter 表表示进行数据包过滤,而 NAT 表针对连接进行地址转换操作;
每个表中又可以存在多个“链”,系统按照预订的规则将数据包通过某个内建链,例如将从本机发出的数据通过 OUTPUT 链;
在“链”中可以存在若干“规则”,这些规则会被逐一进行匹配,如果匹配,可以执行相应的动作,例如修改数据包,或者跳转。
6.2 Underlay 网络技术

VLAN 虚拟局域网:是将一个物理 LAN 在逻辑上划分成多个广播域的通信技术。每个 VLAN 是一个广播域,VLAN 内的主机间通信就和在一个 LAN 内一样。
没有划分 VLAN:LAN 局域网:
优势:简单,静态,IP 地址与交换机关联;
劣势:迁移域受限,不能机房内随意迁移。交换机下 IP 需要提前规划好,约束虚拟比。
划分 VLAN:虚拟局域网:
优势:IP 地址与交换机无关,虚拟机可以在机房范围内迁移。VLAN 间则不能直接互通,这样广播报文就被限制在一个 VLAN 内。
有人会问:交换如何区分不同 VLAN?
交换机能够分辨不同 VLAN 的报文,需要在报文中添加标识 VLAN 信息的字段。数据帧中的VID(VLAN ID)字段标识了该数据帧所属的 VLAN,数据帧只能在其所属 VLAN 内进行传输。
6.3 Overlay 网络技术

VXLAN 虚拟扩展局域网:
是对传统 VLAN 协议的一种扩展;
是一种网络虚拟化技术,试图改善云计算部署的可扩展性问题。
解决哪些问题?
vlan 的数量限制(12bit->24bit),VLAN 报文 Header 预留长度只有 12bit,只支持 4096 个终端;
VNI(VXLAN Network Index)标识某条指定隧道;
不改变 IP 实现服务器迁移。
传统二三层网络架构限制了虚拟机的动态迁移范围。
VXLAN 在两台 TOR 交换机之间建立一条隧道,将服务器发出的原始数据帧加以“包装”,好让原始报文可以在承载网络(比如 IP 网络)上传输。
当到达目的服务器所连接的 TOR 交换机后,离开 VXLAN 隧道,并将原始数据帧恢复出来,继续转发给目的服务器。VXLAN 将整个数据中心基础网络虚拟成了一台巨大的“二层交换机”
VXLAN 网络模型
UDP 封装(L2 over L4):将 L2 的以太帧封装到 UDP 报文即(L2overL4)中,并在 L3 网络中传输;
VTEP,VXLAN 隧道端点,对 VXLAN 报文进行封装和解封装;
VNI,VXLAN 隧道标识,用于区分不同 VXLAN 隧道。


矢量性协议:使用基于路径、网络策略或规则集来决定路由;
AS(自治域):AS 是指在一个实体管辖下的拥有相同选路策略的 IP 网络;
BGP 网络中的每个 AS 都被分配一个唯一的 AS 号,用于区分不同的 AS;
eBGP(域外 BGP):运行于不同 AS 之间的 BGP,为了防止 AS 间产生环路;
为了防止 AS 间产生环路,当 BGP 设备接收 EBGP 对等体发送的路由时,会将带有本地 AS 号的路由丢弃;
iBGP(域内 BGP):运行于同一 AS 内部的 BGP,为了防止 AS 内产生环路;
RR(路由反射器):通过集中反射同步,解决全连通的网状网格结构路由同步问题。
EBGP+IBGP 实现 AS 间的路由传递:一个常见的 IP 骨干网的拓扑结构,骨干层和汇聚层分别是两个自治系统,AS100 有两个出口设备 SwitchC 和 SwitchD,两个 AS 之间需要进行路由互通。
7 总结-云原生

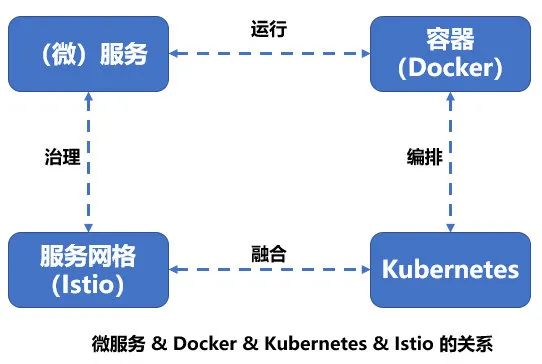
云原生应用:docker 应用打包、发布、运行,Kubernetes 服务部署和集群管理,Istio 构建服务治理能力。

云计算以“资源”为中心,关键技术:
虚拟化:SDX,NFV;
资源池化:弹性快速扩缩容;
多租化:提升云厂商的资源利用率;
典型代表:计算、网络、存储三大基础设施的云化。
云计算以“应用”为中心,关键导向:
设计之初,关注更好适应云,充分发挥云优势;
云原生已成为企业数字创新的最短路径;
云原生一系列 IAAS、PAAS、SAAS 层技术,支撑产品高效交付、稳定运维、持续运营。
【私人观点】
以“资源”为中心的云,将成为“底层基础设施”,利用云原生以“应用”为中心赋能自身业务;
云的时代,已经来临。作为云的使用者、从业者,更多思考如何利用云赋能业务产品;
商业市场模式从“大鱼吃小鱼”靠信息不对称,向“快鱼吃慢鱼”转变。我们必须利用趋势,拥抱云原生。
8 鸣谢
以下小伙伴给出宝贵建议,非常感谢。
鸣谢 CDG-FiT 线:Hawkliu、Cafeeqiu
鸣谢腾讯 OTeam:Kubernetes 开源协同技术讲师
9 学习资料
《SRE Google 运维解密》
《Kubernetes 权威指南》
《Kubernetes in Action》
《深入剖析 Kubernetes》
《Docker 容器与容器云》-浙大
《云原生服务网格 Istio》华为丛书
《Kubernetes 开源协同技术课程》
CNCF 官网:https://www.cncf.io/
Huawei-Cloud Native : https://github.com/huawei-cloudnative
Docker 官方文档:https://docs.docker.com/
Kubernetes 官网:https://kubernetes.io/
Istio 官网:https://istio.io/
10 英雄帖
欢迎对 云原生或金融科技 感兴趣的小伙伴随时交流,更欢迎加入我们团队。
邮箱地址:[email protected]
视频号最新视频