Python数据分析与展示——Pandas基本操作
1.Pandas介绍
Pandas 一个强大的分析结构化数据的工具集,基础是 [Numpy](提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
pandas 的好处:
-
便捷的数据处理能力
-
读取文件方便
-
封装了 Matplotlib、Numpy 的画图和计算
2.DataFrame属性和方法
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
-
data:一组数据(ndarray、series, map, lists, dict 等类型)。
-
index:索引值,或者可以称为行标签。
-
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
-
dtype:数据类型。
-
copy:拷贝数据,默认为 False。
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,可以看成是既有行索引,又有列索引的二维数组。图为没有指定索引则默认行列索引。
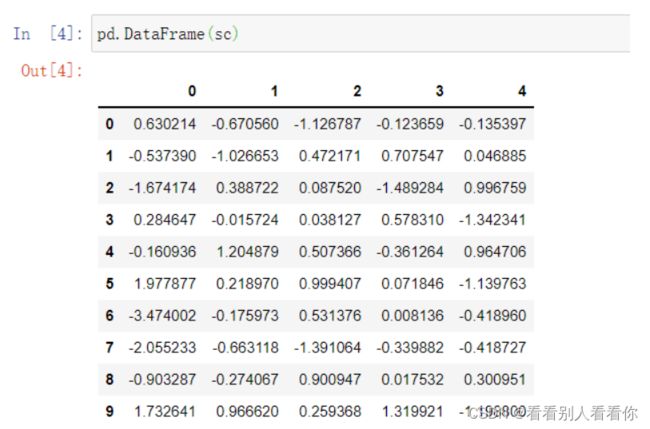
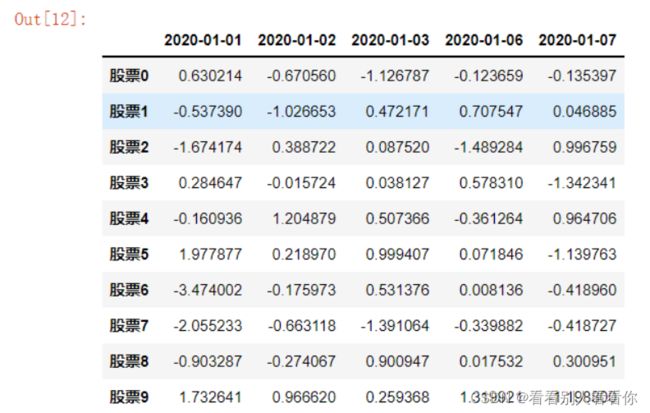
若要指定行列索引,需要先添加字符串:
#添加行索引
stock = ["股票{}".format(i) for i in range(10)]
pd.DataFrame(sc,index=stock)

#添加列索引 date = pd.date_range(start="20200101",periods=5,freq="B") #pd中生成日期 pd.DataFrame(sc,index=stock,columns=date)
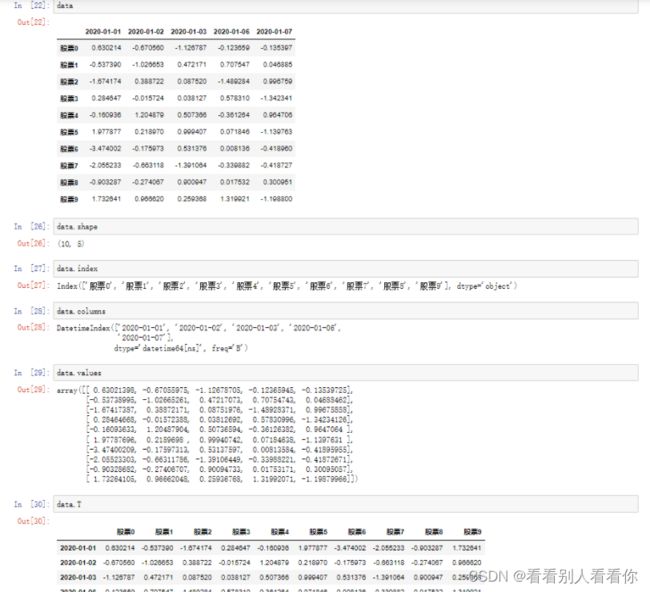
2.1常用属性
-
shape
-
index(行索引)
-
columns(列索引)
-
value(直接获取其中 array 的值)
-
T(转置)
使用 pd.date_ range0: 用于生成一组连续的时间序列
date_range(start=None , end=None, periods=None, freq='B')start:开始时间
end:结束时间
perlods:时间天数
freq:递进单位,默认1天,'B' 默认略过周末
2.2常用方法
-
head() 默认返回前5行,也可以指定行数
-
tail() 默认返回后5行,也可以指定行数
-
info() 返回表格的一些基本信息
3.DataFrame索引设置
3.1修改行列索引值
DataFrame不可单独修改索引,只能整体修改。
错误修改方式:
-
data. index[3] = '股票_3'
正确的方式:
-
stock_ code = ["股票“+ str(1)for 1 inrange(stock change. shape[01)]
必须整体全部修改
-
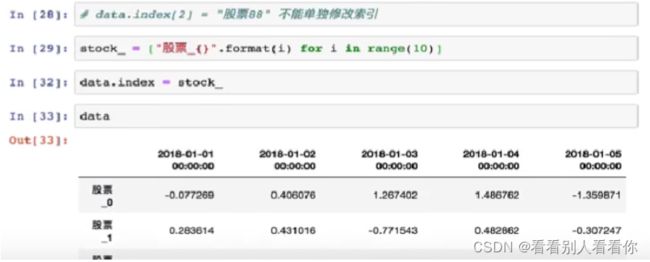
data. index = stock_ code
图中可见行索引名已改变。
3.2重设索引
-
reset_ index(drop=False)
-
设置新的下标索引
-
drop:默认为 False,不删除原来索引(数据多一列),如果为 True,删除原来的索引值
-
3.3设置新索引
用字典创建DataFrame:
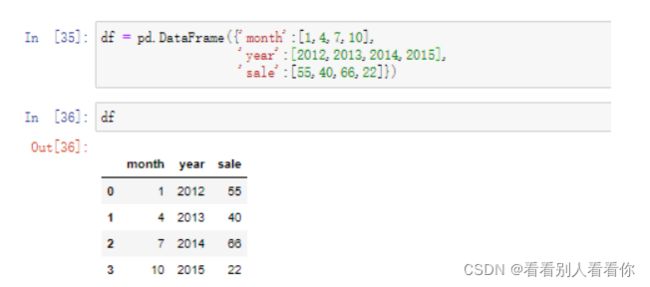
PS:All arrays must be of the same length
以某列值设置为新的索引
-
set index(keys, drop-True)
-
keys :列索引名成或者列索引名称的列表
-
drop : boolean, default True 当做新的索引,删除原来的列。
-

4.Series
Series 类似表格中的一个列(column),类似于一维数组,只有行索引,可以保存任何数据类型。

pandas.Series( data, index, dtype, name, copy)
参数说明:
-
data:一组数据(ndarray 类型)。
-
index:数据索引标签,如果不指定,默认从 0 开始。
-
dtype:数据类型,默认会自己判断。
-
name:设置名称。
-
copy:拷贝数据,默认为 False。
创建Series
1.通过已有数据创建
-
指定内容,默认索引
-
pd.Series(np.arange(10))
-
-
指定索引
-
pd.Series([6.7, 5.6, 3, 10, 2], index=[1, 2, 3, 4, 5])
-
2.通过字典数据创建
-
pd.Series({'red':100, 'blue':200, ‘green': 500, ‘yellow':1000})
Series获取索引和值
-
index
-
values
可以说DataFrame是Series的容器,Panle是DataFrame的容器。
5.CSV文件得读取和存储
5.1读取csv——read_csv()
pandas.read_csv(filepath_or_buffer, sep =',', delimiter = None)
-
filepath_or_buffer:文件路径
-
usecols:指定读取的列名,列表形式,usecols有效参数可能是 [0,1,2]或者是 [‘foo’, ‘bar’, ‘baz’]
-
names:若原csv文件只有数据没有字段,names参数则可以添加字段。
-
sep : str, default ‘,’ 指定分隔符。如果不指定参数,则会尝试使用逗号分隔。分隔符长于一个字符并且不是‘\s+’,将使用python的语法分析器。并且忽略数据中的逗号。正则表达式例子:’\r\t’
-
delimiter : str, default None 定界符,备选分隔符(如果指定该参数,则sep参数失效)
import pandas as pd
df = pd.read_csv('test.csv')
print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 ... 代替。
5.2输出csv——to_csv()
DataFrame.to_csv (path_or_buf=None, sep=', ', columns=None, header=True, index=True, index_Jabel=None, mode='w', encoding=None)
-
path_or_buf :string or file handle, default None
-
sep :character, default .
-
columns :sequence, optional
-
mode:'w':重写,'a'追加
-
index:是否写进行索引
-
header :boolean or list of string, default True,是否写进列索引值
6.JSON文件的读取与存储
6.1读取JSON——read_json()
pd.read_json(path)
需要用到的参数:
-
orient = “records”:告诉 API 以怎样的格式展示读取的 json 文件
-
'split' : dict like {index -> [index], columns -> [columns], data -> [values])
-
'records' : list like [fcolumn -> value}, ... , {column -> value}]
-
'index' : dict like {index -> {column -> value})
-
'columns' : dict like {column -> {index -> value},默认该格式
-
'values' : just the values array
-
-
lines = True/False:
是否按行读取 json 对象
实例:
pd.read_hdf ( "test.h5" , key="close" ).head( ) sa = pd.read_json ( "test.json", orient = "records ", line = True) //以一行作为一个样本
6.2存储JSON——to_json()
df.to_json(path)
需要用到的参数(与读取相同):
-
orient = “records”
-
lines = True/False
实例:
In: sa.to_json ( "test-json" , orient="records" ) #未指定 lines 后保存的当前文件夹下的 json 文件未以一行为样本,仅用逗号分隔。 sa.to_json ( "test-json" , orient="records" , lines = True) #此时保存的文件格式就是以一行为样本。

7.数据清洗
7.1缺失值处理
如何处理:
-
删除含有确实值的样本
-
替换/插补
处理nan:
-
判断数据中心是否存在nan
-
pd.isnull(df)
-
pd.notnull(df)
-
-
删除含有确实值的样本
-
df.dropna(inplace=False) #删除含有缺失值的行
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
-
axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
-
how:默认为 'any' 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how='all' 一行(或列)都是 NA 才去掉这整行。
-
thresh:设置需要多少非空值的数据才可以保留下来的。
-
subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
-
inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据
-
-
-
替换/插入
-
df.fillna(value,inplace=False)
-
True:会修改原始数据
False:不会替换元数据,生成新的对象
-
不是缺失值nan,有默认标记
7.2处理其他标记的缺失值(替换)
-
df.replace(to_replace=""?", value=np.nan)
-
to_replace:替换前的值
-
value:替换后的值
-
处理缺失值步骤:
-
读取数据
-
data = pd. read_csv (path, names=name)
-
-
替换
-
data_new = data.replace(to_replace=" ? ", value=np.nan) //刚刚“?”的部分已经变成 nan data_new.head()
-
-
删除缺失值
-
data_new.dropna (inplace = True) data_new.isnull().any() //全部返回 False 说明不存在缺失值了
-
7.3数据离散化
数据离散化示例:
将性别分为 男 女,将物种分为 猪 狗 老鼠等。
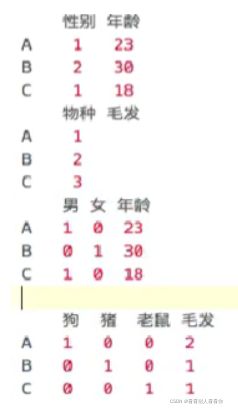
离散化,把无限空间中有限的个体映射到有限的空间中去,以此提高算法的时空效率,离散化仅适用于只关注元素之间的大小关系而不关注元素本身的值。
如何实现数据离散化
-
分组
-
自动分组 sr = pd.qcut(data,bins) #bins为组数
-
自定义分组 sr = pd.cut(data,[]) #将定义好的区间以列表的形式传进来
-
-
将分组好的结果转换成one-hot编码
-
pd.get_dummies(sr,prefix(前缀)=)
-
7.4pd.concat实现合并
按方向拼接
-
pd.concat([data1,data2],axis=1)
-
按照行或列进行合并,axis=0为列索引(竖直拼接),axis=1为行索引(水平拼接),切记方式不要拼接错误
-
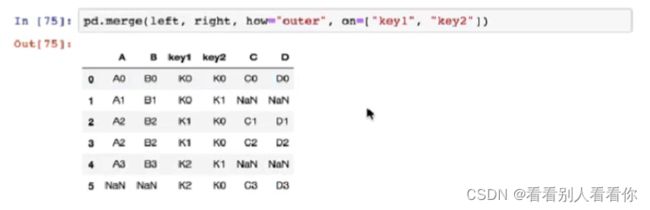
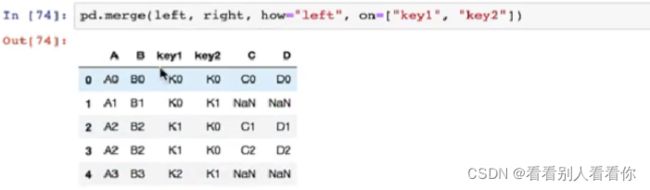
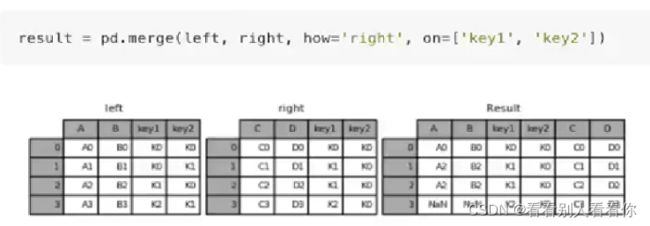
7.5pd.merge实现合并
按索引拼接
-
pd.merge(left,right,how="inner",on=[索引])
-
how参数可取 inner left right outer
给出两个表
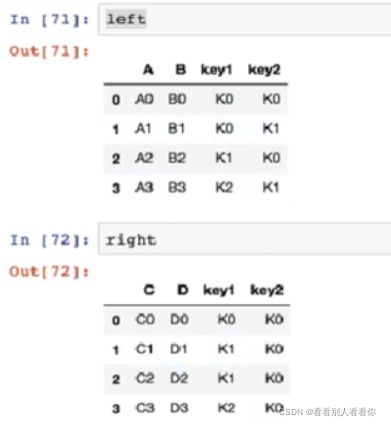
-
内连接

-
左连接
-
右连接
-
外连接