机器学习-白板推导系列(五)-降维(Dimensionality Reduction)
5. 降维
5.1 简介
- 过拟合
- 在机器学习中,我们最关心的是泛化误差,在降低泛化误差的过程中,我们需要克服的最大困难便是过拟合(overfitting)。
- 在线性回归中介绍过,解决过拟合的问题中,我们常用的方法是:增加数据量、正则化和降维。我们也曾用过Lasso和Ridge两种正则化方法,增加penalty使得 w w w趋向于 0 0 0,来消除一些特征。
- 维度灾难(Curse of Dimensionality)
- Def:通常是指在涉及到向量的计算的问题中,随着维数的增加,计算量呈指数倍增长的一种现象。高维度有更大的特征空间,需要更多的数据才可以进行较准确的估计。
若特征是二值的,则每增加一个特征,所需数据量都在以2的指数级进行增长,更何况很多特征不只是二值的。
- 几何角度1
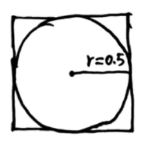
- 上图表示一个多维空间(以二维为例),设正方形边长为 1 1 1,则其内切圆半径为 0.5 0.5 0.5,则正方形面积为 1 1 1,内切圆面积为 π ( 0.5 ) 2 \pi (0.5)^2 π(0.5)2 。若将此变为三维情况下,正方体体积为 1 1 1,内切球体积为 4 3 π ( 0.5 ) 3 {4\over 3}\pi (0.5)^3 34π(0.5)3。
- 因此球体的体积可以表示为 k ( 0.5 ) D k (0.5)^D k(0.5)D(D为维度),则 lim D → ∞ k ( 0.5 ) D = 0 \lim_{D\to \infty}k (0.5)^D=0 limD→∞k(0.5)D=0,其内切超球体的体积为 0 0 0。由此可知, 高 维 情 况 下 , 数 据 大 都 分 布 在 四 角 ( 正 方 形 内 , 内 切 圆 外 ) \color{red}高维情况下,数据大都分布在四角(正方形内,内切圆外) 高维情况下,数据大都分布在四角(正方形内,内切圆外),稀疏性太大,不好分类。
维度越大,超球体体积越小。说明落在超球体内的样本越少,因为超球体是超立方体的内切球。不在球内,那只能在角落!
- 几何角度2

1. 上图也表示一个多维空间(以二维为例),则其中图形的体积有如下关系:外圆半径 r = 1 r=1 r=1,内圆半径为 r − ε r-\varepsilon r−ε。同样在高维情况下,外圆体积为 V 外 圆 = k 1 D = k V_{外圆}=k1^D=k V外圆=k1D=k ,中间的圆环体积为 V 圆 环 = k − k ( 1 − ε ) D V_{圆环}=k-k(1-\varepsilon)^D V圆环=k−k(1−ε)D,则:
lim D → ∞ V 圆 环 V 外 圆 = lim D → ∞ k − k ( 1 − ε ) D k = lim D → ∞ 1 − ( 1 − ε ) D = 1 \lim_{D\to \infty}{V_{圆环}\over V_{外圆}}=\lim_{D\to \infty}{k-k(1-\varepsilon)^D\over k}=\lim_{D\to \infty}1-({1-\varepsilon})^D=1 D→∞limV外圆V圆环=D→∞limkk−k(1−ε)D=D→∞lim1−(1−ε)D=1高维情况下,圆环几乎占据了整个外圆,内圆体积趋向于0,导致数据稀疏。
- Def:通常是指在涉及到向量的计算的问题中,随着维数的增加,计算量呈指数倍增长的一种现象。高维度有更大的特征空间,需要更多的数据才可以进行较准确的估计。
结论:
- 三维的角度来看,是非常震惊的;这类似于人的大脑,几乎所有的智慧都集中在大脑皮层。
- 由此可以看出,二维或三维上的一些理解,在高维是不适用的。
- 降维方法
降维可以作为一种防止过拟合的方式,其具体的方法包含下列几种:
降 维 { 直 接 降 维 ( 特 征 选 择 ) 线 性 降 维 ( P C A 、 M D S ) 非 线 性 降 维 ( 流 形 ) 降维\left\{\begin{matrix} 直接降维(特征选择)\\ 线性降维(PCA、MDS)\\ 非线性降维(流形) \end{matrix}\right. 降维⎩⎨⎧直接降维(特征选择)线性降维(PCA、MDS)非线性降维(流形)- 直接降维:特征选择:直接把不重要的特征扔掉;
- 线性降维:PCA,MDS(多维空间缩放);
- 非线性降维:流形(嵌入了高维空间的地维结构), 等度量映射(ISOMAP), 局部线性嵌入(LLE)。
5.2 样本均值&样本方差的矩阵表示
PCA和SVD都是在矩阵上进行操作,所以本节计算一下样本均值和样本方差的矩阵表示形式。
5.2.1 概述
- 数据
假设有以下数据:
x i ∈ R p , i = 1 , 2 , ⋯ , N X = ( x 1 , x 1 , ⋯ , x N ) T = ( x 1 T x 2 T ⋮ x N T ) = ( x 11 x 12 ⋯ x 1 p x 21 x 22 ⋯ x 2 p ⋮ ⋮ ⋱ ⋮ x N 1 x N 2 ⋯ x N p ) N × p x_{i}\in \mathbb{R}^{p},i=1,2,\cdots ,N\\ X=(x_{1},x_{1},\cdots ,x_{N})^{T}=\begin{pmatrix} x_{1}^{T}\\ x_{2}^{T}\\ \vdots \\ x_{N}^{T} \end{pmatrix}=\begin{pmatrix} x_{11} & x_{12} & \cdots &x_{1p} \\ x_{21} & x_{22}& \cdots &x_{2p} \\ \vdots & \vdots & \ddots &\vdots \\ x_{N1}& x_{N2} & \cdots & x_{Np} \end{pmatrix}_{N \times p} xi∈Rp,i=1,2,⋯,NX=(x1,x1,⋯,xN)T=⎝⎜⎜⎜⎛x1Tx2T⋮xNT⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛x11x21⋮xN1x12x22⋮xN2⋯⋯⋱⋯x1px2p⋮xNp⎠⎟⎟⎟⎞N×p - 样本均值与样本方差
- 样本均值(Sample Mean):
X ‾ p × 1 = 1 N ∑ i = 1 N x i \overline X_{p\times 1}={1\over N}\sum_{i=1}^N x_i Xp×1=N1i=1∑Nxi - 样本方差(Sample Convariance):
S p × p = 1 N ∑ i = 1 N ( x i − X ‾ ) ( x i − X ‾ ) T S_{p\times p}={1\over N} \sum^{N}_{i=1}(x_i - \overline X)(x_i - \overline X)^T Sp×p=N1i=1∑N(xi−X)(xi−X)T
- 样本均值(Sample Mean):
5.2.2 矩阵化均值与方差
- 均值矩阵化:
x ˉ = 1 N ∑ i = 1 N x i = 1 N ( x 1 x 2 ⋯ x N ) ⏟ X T ( 1 1 ⋮ 1 ) = 1 N X T 1 N \bar{x}=\frac{1}{N}\sum_{i=1}^{N}x_{i}=\frac{1}{N}\underset{X^{T}}{\underbrace{\begin{pmatrix} x_{1} & x_{2} & \cdots & x_{N} \end{pmatrix}}}\begin{pmatrix} 1\\ 1\\ \vdots \\ 1 \end{pmatrix}=\frac{1}{N}X^{T}1_{N} xˉ=N1i=1∑Nxi=N1XT (x1x2⋯xN)⎝⎜⎜⎜⎛11⋮1⎠⎟⎟⎟⎞=N1XT1N
规定向量: 1 N = ( 1 1 ⋮ 1 ) N × 1 1_{N}=\begin{pmatrix} 1\\ 1\\ \vdots \\ 1 \end{pmatrix}_{N\times 1} 1N=⎝⎜⎜⎜⎛11⋮1⎠⎟⎟⎟⎞N×1 - 方差矩阵化
S = 1 N ∑ i = 1 N ( x i − x ˉ ) ( x i − x ˉ ) T = 1 N ( x 1 − x ˉ x 2 − x ˉ ⋯ x N − x ˉ ) ( ( x 1 − x ˉ ) T ( x 2 − x ˉ ) T ⋮ ( x N − x ˉ ) T ) S=\frac{1}{N}\sum_{i=1}^{N}(x_{i}-\bar{x})(x_{i}-\bar{x})^{T}\\ =\frac{1}{N}\begin{pmatrix} x_{1}-\bar{x} & x_{2}-\bar{x} & \cdots & x_{N}-\bar{x} \end{pmatrix}\begin{pmatrix} (x_{1}-\bar{x})^{T}\\ (x_{2}-\bar{x})^{T}\\ \vdots \\ (x_{N}-\bar{x})^{T} \end{pmatrix} S=N1i=1∑N(xi−xˉ)(xi−xˉ)T=N1(x1−xˉx2−xˉ⋯xN−xˉ)⎝⎜⎜⎜⎛(x1−xˉ)T(x2−xˉ)T⋮(xN−xˉ)T⎠⎟⎟⎟⎞
上式中 ( x 1 − x ˉ x 2 − x ˉ ⋯ x N − x ˉ ) = ( x 1 x 2 ⋯ x N ) − ( x ˉ x ˉ ⋯ x ˉ ) \begin{pmatrix} x_{1}-\bar{x} & x_{2}-\bar{x} & \cdots & x_{N}-\bar{x} \end{pmatrix}=\begin{pmatrix} x_{1} & x_{2} & \cdots & x_{N} \end{pmatrix}-\begin{pmatrix} \bar{x} & \bar{x} & \cdots & \bar{x} \end{pmatrix} (x1−xˉx2−xˉ⋯xN−xˉ)=(x1x2⋯xN)−(xˉxˉ⋯xˉ),则:
S = X T − x ˉ ( 1 1 ⋯ 1 ) = X T − x ˉ 1 N T = X T − 1 N X T 1 N 1 N T = X T ( I N − 1 N 1 N 1 N T ) S=X^{T}-\bar{x}\begin{pmatrix} 1 & 1 & \cdots & 1 \end{pmatrix}\\ =X^{T}-\bar{x}1_{N}^{T} =X^{T}-\frac{1}{N}X^{T}1_{N}1_{N}^{T}\\ =X^{T}(I_{N}-\frac{1}{N}1_{N}1_{N}^{T}) S=XT−xˉ(11⋯1)=XT−xˉ1NT=XT−N1XT1N1NT=XT(IN−N11N1NT)
则 S = 1 N X T ( I N − 1 N 1 N 1 N T ) ⏟ H ( I N − 1 N 1 N 1 N T ) T X ( H 称 为 中 心 矩 阵 , c e n t e r i n g m a t r i x ) S=\frac{1}{N}X^{T}\underset{H}{\underbrace{(I_{N}-\frac{1}{N}1_{N}1_{N}^{T})}}(I_{N}-\frac{1}{N}1_{N}1_{N}^{T})^{T}X\\ (H称为中心矩阵,centering\ matrix) S=N1XTH (IN−N11N1NT)(IN−N11N1NT)TX(H称为中心矩阵,centering matrix)
则 S = 1 N X T H H T X \color{red}S=\frac{1}{N}X^{T}HH^{T}X S=N1XTHHTXc e n t e r i n g m a t r i x centering \ matrix centering matrix的作用是将一组数据中心化, H H H矩阵有如下性质:
- 性质: ① H T = H \color{red}①\; H^{T}=H ①HT=H
H T = ( I N − 1 N 1 N 1 N T ) T = I N − 1 N 1 N 1 N T = H H^{T}=(I_{N}-\frac{1}{N}1_{N}1_{N}^{T})^{T}=I_{N}-\frac{1}{N}1_{N}1_{N}^{T}=H HT=(IN−N11N1NT)T=IN−N11N1NT=H - 性质: ② H n = H \color{red}②\; H^{n}=H ②Hn=H
H 2 = H ⋅ H = ( I N − 1 N 1 N 1 N T ) ( I N − 1 N 1 N 1 N T ) = I N − 2 N 1 N 1 N T + 1 N 2 1 N 1 N T 1 N 1 N T = I N − 2 N ( 1 1 ⋮ 1 ) ( 1 1 ⋯ 1 ) + 1 N 2 ( 1 1 ⋮ 1 ) ( 1 1 ⋯ 1 ) ( 1 1 ⋮ 1 ) ( 1 1 ⋯ 1 ) = I N − 2 N [ 1 1 ⋯ 1 1 1 ⋯ 1 ⋮ ⋮ ⋱ ⋮ 1 1 ⋯ 1 ] N × N + 1 N 2 [ 1 1 ⋯ 1 1 1 ⋯ 1 ⋮ ⋮ ⋱ ⋮ 1 1 ⋯ 1 ] N × N [ 1 1 ⋯ 1 1 1 ⋯ 1 ⋮ ⋮ ⋱ ⋮ 1 1 ⋯ 1 ] N × N = I N − 2 N [ 1 1 ⋯ 1 1 1 ⋯ 1 ⋮ ⋮ ⋱ ⋮ 1 1 ⋯ 1 ] N × N + 1 N 2 [ N N ⋯ N N N ⋯ N ⋮ ⋮ ⋱ ⋮ N N ⋯ N ] N × N = I N − 2 N [ 1 1 ⋯ 1 1 1 ⋯ 1 ⋮ ⋮ ⋱ ⋮ 1 1 ⋯ 1 ] N × N + 1 N [ 1 1 ⋯ 1 1 1 ⋯ 1 ⋮ ⋮ ⋱ ⋮ 1 1 ⋯ 1 ] N × N = I N − 1 N 1 N 1 N T = H H^{2}=H\cdot H=(I_{N}-\frac{1}{N}1_{N}1_{N}^{T})(I_{N}-\frac{1}{N}1_{N}1_{N}^{T})\\ =I_{N}-\frac{2}{N}1_{N}1_{N}^{T}+\frac{1}{N^{2}}1_{N}1_{N}^{T}1_{N}1_{N}^{T}\\ =I_{N}-\frac{2}{N}\begin{pmatrix} 1\\ 1\\ \vdots \\ 1 \end{pmatrix}\begin{pmatrix} 1 & 1 & \cdots & 1 \end{pmatrix}+\frac{1}{N^{2}}\begin{pmatrix} 1\\ 1\\ \vdots \\ 1 \end{pmatrix}\begin{pmatrix} 1 & 1 & \cdots & 1 \end{pmatrix}\begin{pmatrix} 1\\ 1\\ \vdots \\ 1 \end{pmatrix}\begin{pmatrix} 1 & 1 & \cdots & 1 \end{pmatrix}\\ =I_{N}-\frac{2}{N}\begin{bmatrix} 1 & 1 & \cdots & 1 \\ 1 & 1 & \cdots & 1 \\ \vdots & \vdots & \ddots & \vdots \\ 1 & 1 & \cdots & 1 \end{bmatrix}_{N\times N}+\frac{1}{N^{2}}\begin{bmatrix} 1 & 1 & \cdots & 1 \\ 1 & 1 & \cdots & 1 \\ \vdots & \vdots & \ddots & \vdots \\ 1 & 1 & \cdots & 1 \end{bmatrix}_{N\times N}\begin{bmatrix} 1 & 1 & \cdots & 1 \\ 1 & 1 & \cdots & 1 \\ \vdots & \vdots & \ddots & \vdots \\ 1 & 1 & \cdots & 1 \end{bmatrix}_{N\times N}\\ =I_{N}-\frac{2}{N}\begin{bmatrix} 1 & 1 & \cdots & 1 \\ 1 & 1 & \cdots & 1 \\ \vdots & \vdots & \ddots & \vdots \\ 1 & 1 & \cdots & 1 \end{bmatrix}_{N\times N}+\frac{1}{N^{2}}\begin{bmatrix} N & N & \cdots & N \\ N & N & \cdots & N \\ \vdots & \vdots & \ddots & \vdots \\ N & N & \cdots & N \end{bmatrix}_{N\times N}\\ =I_{N}-\frac{2}{N}\begin{bmatrix} 1 & 1 & \cdots & 1 \\ 1 & 1 & \cdots & 1 \\ \vdots & \vdots & \ddots & \vdots \\ 1 & 1 & \cdots & 1 \end{bmatrix}_{N\times N}+\frac{1}{N}\begin{bmatrix} 1 & 1 & \cdots & 1 \\ 1 & 1 & \cdots & 1 \\ \vdots & \vdots & \ddots & \vdots \\ 1 & 1 & \cdots & 1 \end{bmatrix}_{N\times N}\\ =I_{N}-\frac{1}{N}1_{N}1_{N}^{T} =H H2=H⋅H=(IN−N11N1NT)(IN−N11N1NT)=IN−N21N1NT+N211N1NT1N1NT=IN−N2⎝⎜⎜⎜⎛11⋮1⎠⎟⎟⎟⎞(11⋯1)+N21⎝⎜⎜⎜⎛11⋮1⎠⎟⎟⎟⎞(11⋯1)⎝⎜⎜⎜⎛11⋮1⎠⎟⎟⎟⎞(11⋯1)=IN−N2⎣⎢⎢⎢⎡11⋮111⋮1⋯⋯⋱⋯11⋮1⎦⎥⎥⎥⎤N×N+N21⎣⎢⎢⎢⎡11⋮111⋮1⋯⋯⋱⋯11⋮1⎦⎥⎥⎥⎤N×N⎣⎢⎢⎢⎡11⋮111⋮1⋯⋯⋱⋯11⋮1⎦⎥⎥⎥⎤N×N=IN−N2⎣⎢⎢⎢⎡11⋮111⋮1⋯⋯⋱⋯11⋮1⎦⎥⎥⎥⎤N×N+N21⎣⎢⎢⎢⎡NN⋮NNN⋮N⋯⋯⋱⋯NN⋮N⎦⎥⎥⎥⎤N×N=IN−N2⎣⎢⎢⎢⎡11⋮111⋮1⋯⋯⋱⋯11⋮1⎦⎥⎥⎥⎤N×N+N1⎣⎢⎢⎢⎡11⋮111⋮1⋯⋯⋱⋯11⋮1⎦⎥⎥⎥⎤N×N=IN−N11N1NT=H
则 H n = H H^{n}=H Hn=H,其中 1 N 1 N T 1 N 1 N T 1_N1_N^T1_N1_N^T 1N1NT1N1NT为元素全是 N N N的矩阵。
- 性质: ① H T = H \color{red}①\; H^{T}=H ①HT=H
最终可以得到
x ˉ = 1 N X T 1 N S = 1 N X T H X \color{red}\bar{x}=\frac{1}{N}X^{T}1_{N}\\ S=\frac{1}{N}X^{T}HX xˉ=N1XT1NS=N1XTHX
5.3 主成分分析(PCA)—最大投影方差角度
5.3.1 概述
-
PCA的思想可以总结为: 一 个 中 心 , 两 个 基 本 点 \color{red}一个中心,两个基本点 一个中心,两个基本点。
- 一 个 中 心 \color{red}一个中心 一个中心:PCA是对原始特征空间的重构,将原来的线性相关的向量转换成线性无关的向量;
- 两 个 基 本 点 \color{red}两个基本点 两个基本点: 最 大 投 影 方 差 \color{red}最大投影方差 最大投影方差和 最 小 重 构 距 离 \color{red}最小重构距离 最小重构距离,这是本质相同的两种方法。
-
最大投影方差
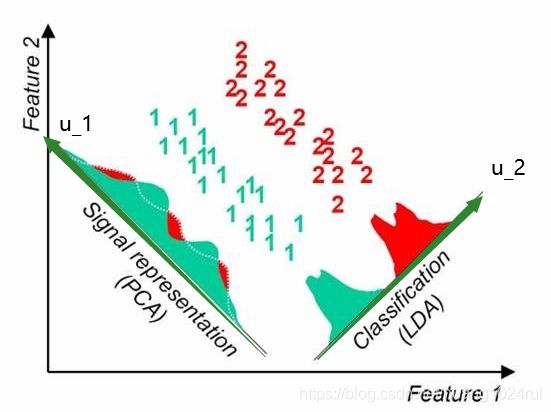
这一组数据点投影到 u 1 u_1 u1 方向后方差更大,数据更分散,而投影到 u 2 u_2 u2 方向会很密集,因此我们称 u 1 u_1 u1 方向为主成份。主成份分析的意思是找到一组线性无关的基,这组基就是主成份,若我们想降到 q q q 维,便选择其前 q q q 个基即可。
- LDA对应的是: 类 内 小 , 类 间 大 \color{red}类内小, 类间大 类内小,类间大;
- PCA对应的是 最 大 投 影 方 差 \color{red}最大投影方差 最大投影方差。
-
最小重构距离
- 最小重构距离:以最小代价将投影后的数据重构回去。
- 其本质与最大投影方差类似,若投影后数据越分散,则重构越容易;若数据越集中,甚至重合到一个点,便很难重构回去。因此最小重构距离也需要寻找投影后数据最分散的方向。
-
数据
- X = ( x 1 x 2 ⋯ x N ) T = ( x 1 T x 2 T ⋮ x N T ) = ( x 11 x 12 ⋯ x 1 p x 21 x 22 ⋯ x 2 p ⋮ ⋮ ⋱ ⋮ x N 1 x N 2 ⋯ x N p ) N × p X=\begin{pmatrix} x_1&x_2& \cdots& x_N \end{pmatrix}^T= \begin{pmatrix} x_1^T\\x_2^T\\\vdots\\x_N^T \end{pmatrix}= \begin{pmatrix} x_{11}&x_{12} & \cdots& x_{1p}\\ x_{21}&x_{22}&\cdots&x_{2p}\\ \vdots&\vdots&\ddots&\vdots\\ x_{N1}&x_{N2}&\cdots &x_{Np} \end{pmatrix}_{N\times p} X=(x1x2⋯xN)T=⎝⎜⎜⎜⎛x1Tx2T⋮xNT⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛x11x21⋮xN1x12x22⋮xN2⋯⋯⋱⋯x1px2p⋮xNp⎠⎟⎟⎟⎞N×p
其中 x i ∈ R p , i = 1 , 2 , ⋯ , N x_i \in \mathbb R^p ,\ \ i=1, 2, \cdots, N xi∈Rp, i=1,2,⋯,N。 - 样本均值为: x ‾ = 1 N ∑ i = 1 N x i = 1 N X T 1 N \overline x={1\over N}\sum_{i=1}^N x_i={1\over N}X^T1_N x=N1i=1∑Nxi=N1XT1N
- 样本方差为: S p × p = 1 N ∑ i = 1 N ( x i − X ‾ ) ( x i − X ‾ ) T = 1 N X T H X S_{p\times p}={1\over N} \sum^{N}_{i=1}(x_i - \overline X)(x_i - \overline X)^T={1\over N}X^THX Sp×p=N1i=1∑N(xi−X)(xi−X)T=N1XTHX
其中: 1 N = ( 1 1 ⋮ 1 ) 1_N=\begin{pmatrix} 1\\1\\\vdots\\1 \end{pmatrix} 1N=⎝⎜⎜⎜⎛11⋮1⎠⎟⎟⎟⎞, H N = I N − 1 N 1 N 1 N T H_N=I_N-{1\over N}1_N1_N^T HN=IN−N11N1NT, X ‾ ∈ R p \overline X\in \mathbb R^p X∈Rp, S ∈ R p × p S\in \mathbb R^{p\times p} S∈Rp×p。
- X = ( x 1 x 2 ⋯ x N ) T = ( x 1 T x 2 T ⋮ x N T ) = ( x 11 x 12 ⋯ x 1 p x 21 x 22 ⋯ x 2 p ⋮ ⋮ ⋱ ⋮ x N 1 x N 2 ⋯ x N p ) N × p X=\begin{pmatrix} x_1&x_2& \cdots& x_N \end{pmatrix}^T= \begin{pmatrix} x_1^T\\x_2^T\\\vdots\\x_N^T \end{pmatrix}= \begin{pmatrix} x_{11}&x_{12} & \cdots& x_{1p}\\ x_{21}&x_{22}&\cdots&x_{2p}\\ \vdots&\vdots&\ddots&\vdots\\ x_{N1}&x_{N2}&\cdots &x_{Np} \end{pmatrix}_{N\times p} X=(x1x2⋯xN)T=⎝⎜⎜⎜⎛x1Tx2T⋮xNT⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛x11x21⋮xN1x12x22⋮xN2⋯⋯⋱⋯x1px2p⋮xNp⎠⎟⎟⎟⎞N×p
5.3.2 最大投影方差角度模型建立
假设投影方向为 u i u_i ui,由于我们只关注投影的方向,因此将 u u u的模设置为 1 1 1,即 u i T u i = 1 \color{red}{u_i}^{T}{u_i}=1 uiTui=1。
- 将数据进行中心化
x i ′ = x i − x ^ x'_i=x_i-\hat x xi′=xi−x^ - 将 x i ′ x'_i xi′投影到 u i {u_i} ui
p r o j e c t i o n = ∥ x ′ ∥ cos θ projection=\Vert x'\Vert \cos{\theta} projection=∥x′∥cosθ
其中 θ \theta θ为 x ′ x' x′与 u i {u_i} ui的夹角。
x ′ ⋅ u i = ∥ x ′ ∥ ∥ u i ∥ cos θ = ∥ x ′ ∥ cos θ x' \cdot {u_i} = \Vert x'\Vert\Vert {u_i}\Vert \cos{\theta}=\Vert x'\Vert \cos{\theta} x′⋅ui=∥x′∥∥ui∥cosθ=∥x′∥cosθ
因为 x ′ ⋅ u i = x ′ T u i x' \cdot {u_i} = x'^T {u_i} x′⋅ui=x′Tui,所以:
p r o j e c t i o n = x ′ T u i projection=x'^T {u_i} projection=x′Tui
由于 x ′ x' x′已经中心化,其均值为 0 0 0,因此投影方差为 ( x ′ T u i ) 2 = ( ( x i − x ‾ ) T u i ) 2 (x'^T {u_i})^2= \color{red}((x_i-\overline x)^T{u_i})^2 (x′Tui)2=((xi−x)Tui)2。 - 目标函数
我们定义损失函数如下:
J ( u i ) = 1 N ∑ i = 1 N ( ( x i − x ^ ) T u i ) 2 = ∑ i = 1 N 1 N u i T ( x i − x ^ ) ( x i − x ^ ) T u i = u 1 T [ 1 N ∑ i = 1 N ( x i − x ^ ) ( x i − x ^ ) T ] ⏟ S u i J({u_i})=\frac{1}{N}\sum_{i=1}^{N}((x_{i}-\hat{x})^{T}{u_i})^{2}\\ =\sum_{i=1}^{N}\frac{1}{N}{u_i}^{T}(x_{i}-\hat{x})(x_{i}-\hat{x})^{T}{u_i}\\ =u_1^{T}\underset{S}{\underbrace{[\frac{1}{N}\sum_{i=1}^{N}(x_{i}-\hat{x})(x_{i}-\hat{x})^{T}]}}{u_i} J(ui)=N1i=1∑N((xi−x^)Tui)2=i=1∑NN1uiT(xi−x^)(xi−x^)Tui=u1TS [N1i=1∑N(xi−x^)(xi−x^)T]ui
其中 1 N ∑ i = 1 N ( x i − x ^ ) ( x i − x ^ ) T \frac{1}{N}\sum_{i=1}^{N}(x_{i}-\hat{x})(x_{i}-\hat{x})^{T} N1∑i=1N(xi−x^)(xi−x^)T 正是协方差矩阵 S S S ,因此:
J ( u i ) = u i T S u i J({u_i}) ={u_i}^{T}S{u_i} J(ui)=uiTSui - 最大投影方差角度问题
因此最大投影方差角度问题就转换为以下最优化问题:
{ u i ^ = a r g m a x u i u i T S u i s . t . u i T u i = 1 \color{blue}\left\{\begin{matrix} \hat{{u_i}}=\underset{{u_i}}{argmax}\;{u_i}^{T}S{u_i}\\ s.t.\; \;{u_i}^{T}{u_i}=1 \end{matrix}\right. {ui^=uiargmaxuiTSuis.t.uiTui=1 - 求解模型
使用拉格朗日乘子法进行求解:
L ( u i , λ ) = u i T S u i + λ ( 1 − u i T u i ) ∂ L ∂ u i = 2 S u i − 2 λ u i = 0 L({u_i},\lambda )={u_i}^{T}S{u_i}+\lambda (1-{u_i}^{T}{u_i})\\ \frac{\partial L}{\partial {u_i}}=2S{u_i}-2\lambda {u_i}=0 L(ui,λ)=uiTSui+λ(1−uiTui)∂ui∂L=2Sui−2λui=0 S u i 特 征 向 量 = λ 特 征 值 u i \color{red}S\underset{特征向量}{{u_i}}=\underset{特征值}{\lambda} {u_i} S特征向量ui=特征值λui- 此式是协方差矩阵 S S S 的特征方程,其中 λ \lambda λ 为特征值, u i {u_i} ui 为特征向量。
- 此式中,特征向量 u i {u_i} ui 便是投影方向, 特 征 值 最 大 的 特 征 向 量 是 投 影 方 差 最 大 的 主 成 份 \color{red}特征值最大的特征向量是投影方差最大的主成份 特征值最大的特征向量是投影方差最大的主成份。
- 降维
想要降到 q q q维 ( q < p ) (q
( x 1 T x 2 T ⋮ x N T ) N × p ( u 1 u 2 ⋯ u q ) p × q = [ x 1 T u 1 x 1 T u 2 ⋯ x 1 T u q x 2 T u 1 x 2 T u 2 ⋯ x 2 T u q ⋮ ⋮ ⋱ ⋮ x N T u 1 x N T u 2 ⋯ x N T u q ] N × q \begin{pmatrix} x_{1}^{T}\\ x_{2}^{T}\\ \vdots \\ x_{N}^{T} \end{pmatrix}_{N\times p}\begin{pmatrix} u_{1} & u_{2} & \cdots & u_{q} \end{pmatrix}_{p\times q}=\begin{bmatrix} x_{1}^{T}u_{1}& x_{1}^{T}u_{2}& \cdots & x_{1}^{T}u_{q}\\ x_{2}^{T}u_{1}& x_{2}^{T}u_{2}& \cdots & x_{2}^{T}u_{q}\\ \vdots & \vdots & \ddots & \vdots \\ x_{N}^{T}u_{1}& x_{N}^{T}u_{2}& \cdots & x_{N}^{T}u_{q} \end{bmatrix}_{N\times q} ⎝⎜⎜⎜⎛x1Tx2T⋮xNT⎠⎟⎟⎟⎞N×p(u1u2⋯uq)p×q=⎣⎢⎢⎢⎡x1Tu1x2Tu1⋮xNTu1x1Tu2x2Tu2⋮xNTu2⋯⋯⋱⋯x1Tuqx2Tuq⋮xNTuq⎦⎥⎥⎥⎤N×q- 特征向量表示投影变换的方向,特征值表示投影变换的强度。通过降维,我们希望减少冗余信息,提高识别的精度,或者希望通过降维算法来寻找数据内部的本质结构特征。
- 找最大的特征值是因为 ,在降维之后要最大化保留数据的内在信息,并期望在所投影的维度上的离散最大。
5.4 主成分分析(PCA)—最小重构代价角度
上节课从最大方差角度来计算了降维时最优投影方向:特征值较大的特征向量。
5.4.1 概述
-
如下图,假设维度为2,即 p = 2 p=2 p=2 , x i x_i xi 为某一个样本点, u 1 , u 2 u_1,u_2 u1,u2 为数据集 X X X 协方差矩阵的特征向量( u i T ⋅ u i = 1 u_i^T\cdot u_i = 1 uiT⋅ui=1 ),其对应的特征值为 λ 1 , λ 2 \lambda_1, \lambda_2 λ1,λ2。
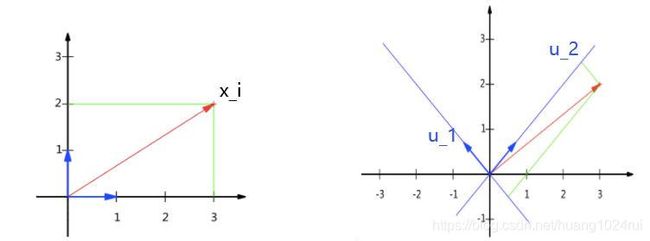
- 将 x i x_i xi投影到 u 1 u_1 u1 和 u 2 u_2 u2 后的坐标为 ( x i T u 1 ) u 1 + ( x i T u 2 ) u 2 (x_i^Tu_1)u_1+(x_i^Tu_2)u_2 (xiTu1)u1+(xiTu2)u2;
其中 ( x i T u i ) (x_i^Tu_i) (xiTui) 为投影到 u 1 u_1 u1 向量后的长度,其中 ∣ u i ∣ = 1 \vert u_i\vert=1 ∣ui∣=1。
- 若将 X X X降到 1 1 1维,选取 u 2 u_2 u2,而不是 u 1 u_1 u1(因为 u 2 u_2 u2的投影更大,损失更小),则 x i ′ = ( x i T u 2 ) u 2 x'_i = (x_i^Tu_2)u_2 xi′=(xiTu2)u2。
以上便是从 2 2 2维降到 1 1 1维。同样可以推广到:从 p p p 维降到 q q q维( p > q p>q p>q),可以实现最小重构代价角度。
- 将 x i x_i xi投影到 u 1 u_1 u1 和 u 2 u_2 u2 后的坐标为 ( x i T u 1 ) u 1 + ( x i T u 2 ) u 2 (x_i^Tu_1)u_1+(x_i^Tu_2)u_2 (xiTu1)u1+(xiTu2)u2;
-
已知数据
- X = ( x 1 x 2 ⋯ x N ) T = ( x 1 T x 2 T ⋮ x N T ) = ( x 11 x 12 ⋯ x 1 p x 21 x 22 ⋯ x 2 p ⋮ ⋮ ⋱ ⋮ x N 1 x N 2 ⋯ x N p ) N × p X=\begin{pmatrix} x_1&x_2& \cdots& x_N \end{pmatrix}^T= \begin{pmatrix} x_1^T\\x_2^T\\\vdots\\x_N^T \end{pmatrix}= \begin{pmatrix} x_{11}&x_{12} & \cdots& x_{1p}\\ x_{21}&x_{22}&\cdots&x_{2p}\\ \vdots&\vdots&\ddots&\vdots\\ x_{N1}&x_{N2}&\cdots &x_{Np} \end{pmatrix}_{N\times p} X=(x1x2⋯xN)T=⎝⎜⎜⎜⎛x1Tx2T⋮xNT⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛x11x21⋮xN1x12x22⋮xN2⋯⋯⋱⋯x1px2p⋮xNp⎠⎟⎟⎟⎞N×p
其中 x i ∈ R p , i = 1 , 2 , ⋯ , N x_i \in \mathbb R^p ,\ \ i=1, 2, \cdots, N xi∈Rp, i=1,2,⋯,N。 - 样本均值为: x ˉ = 1 N ∑ i = 1 N x i = 1 N X T 1 N \bar x={1\over N}\sum_{i=1}^N x_i={1\over N}X^T1_N xˉ=N1i=1∑Nxi=N1XT1N
- 样本方差为: S p × p = 1 N ∑ i = 1 N ( x i − X ‾ ) ( x i − X ‾ ) T = 1 N X T H X S_{p\times p}={1\over N} \sum^{N}_{i=1}(x_i - \overline X)(x_i - \overline X)^T={1\over N}X^THX Sp×p=N1i=1∑N(xi−X)(xi−X)T=N1XTHX
其中: 1 N = ( 1 1 ⋮ 1 ) 1_N=\begin{pmatrix} 1\\1\\\vdots\\1 \end{pmatrix} 1N=⎝⎜⎜⎜⎛11⋮1⎠⎟⎟⎟⎞, H N = I N − 1 N 1 N 1 N T H_N=I_N-{1\over N}1_N1_N^T HN=IN−N11N1NT, X ‾ ∈ R p \overline X\in \mathbb R^p X∈Rp, S ∈ R p × p S\in \mathbb R^{p\times p} S∈Rp×p。
- X = ( x 1 x 2 ⋯ x N ) T = ( x 1 T x 2 T ⋮ x N T ) = ( x 11 x 12 ⋯ x 1 p x 21 x 22 ⋯ x 2 p ⋮ ⋮ ⋱ ⋮ x N 1 x N 2 ⋯ x N p ) N × p X=\begin{pmatrix} x_1&x_2& \cdots& x_N \end{pmatrix}^T= \begin{pmatrix} x_1^T\\x_2^T\\\vdots\\x_N^T \end{pmatrix}= \begin{pmatrix} x_{11}&x_{12} & \cdots& x_{1p}\\ x_{21}&x_{22}&\cdots&x_{2p}\\ \vdots&\vdots&\ddots&\vdots\\ x_{N1}&x_{N2}&\cdots &x_{Np} \end{pmatrix}_{N\times p} X=(x1x2⋯xN)T=⎝⎜⎜⎜⎛x1Tx2T⋮xNT⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛x11x21⋮xN1x12x22⋮xN2⋯⋯⋱⋯x1px2p⋮xNp⎠⎟⎟⎟⎞N×p
5.4.2 最小重构代价
-
中心化
x i ′ = x i − x ˉ , ( i = 1 , 2 , ⋯ , N ) x'_i = x_i-\bar x,\;(i=1, 2, \cdots, N) xi′=xi−xˉ,(i=1,2,⋯,N) -
将 X X X 重构到以特征向量为基的向量空间
重构到以特征向量 ( u 1 , u 2 , . . . , u p ) (u_1,u_2,...,u_p) (u1,u2,...,up)为基的向量空间
x i ′ ′ = ∑ k = 1 p ( x ′ i T u k ) u k , ( i = 1 , 2 , ⋯ , N ) x''_i=\sum_{k=1}^p(x{'}_i^Tu_k)u_k,\;(i=1, 2, \cdots, N) xi′′=k=1∑p(x′iTuk)uk,(i=1,2,⋯,N) -
将 X X X降维
将 X X X从 p p p降维到 q q q维( p > q p>q p>q),假设特征向量 u i u_i ui按照特征值 λ i \lambda_i λi的大小, 从 大 到 小 排 列 \color{red}从大到小排列 从大到小排列( u 1 u_1 u1对应的 λ 1 \lambda_1 λ1最大, u p u_p up 对应的 λ p \lambda_p λp最小)。则降维可以表示为:
x i ′ ′ ^ = ∑ k = 1 q ( x ′ i T u k ) u k \hat {x''_i}=\sum_{k=1}^q(x{'}_i^Tu_k)u_k xi′′^=k=1∑q(x′iTuk)uk -
目标函数
最小重构距离是指将降维后的 x i ′ ′ ^ \hat {x''_i} xi′′^还原为 x i ′ ′ x''_i xi′′所需代价最小,因此其代价可以用二者差值来表示:
J = 1 N ∑ i = 1 N ∥ ( x i − x ˉ ) − x ^ i ∥ 2 = 1 N ∑ i = 1 N ∥ ∑ k = q + 1 p ( ( x i − x ˉ ) T u k ) u k ∥ 2 J=\frac{1}{N}\sum_{i=1}^{N}\left \| (x_{i}-\bar{x})-\hat{x}_{i}\right \|^{2}\\ =\frac{1}{N}\sum_{i=1}^{N}\left \| \sum_{k=q+1}^{p}((x_{i}-\bar{x})^{T}u_{k})u_{k}\right \|^{2} J=N1i=1∑N∥(xi−xˉ)−x^i∥2=N1i=1∑N∥∥∥∥∥∥k=q+1∑p((xi−xˉ)Tuk)uk∥∥∥∥∥∥2x ′ i T u k x{'}_i^Tu_k x′iTuk是 x i ′ x'_i xi′在第 k k k维的投影。则:
J = 1 N ∑ i = 1 N ∑ k = q + 1 p ( ( x i − x ˉ ) T u k ) 2 = ∑ k = q + 1 p 1 N ∑ i = 1 N ( ( x i − x ˉ ) T u k ) 2 ⏟ u k T S u k J=\frac{1}{N}\sum_{i=1}^{N}\sum_{k=q+1}^{p}((x_{i}-\bar{x})^{T}u_{k})^{2}\\ =\sum_{k=q+1}^{p}\underset{u_{k}^{T}Su_{k}}{\underbrace{\frac{1}{N}\sum_{i=1}^{N}((x_{i}-\bar{x})^{T}u_{k})^{2}}} J=N1i=1∑Nk=q+1∑p((xi−xˉ)Tuk)2=k=q+1∑pukTSuk N1i=1∑N((xi−xˉ)Tuk)2
则最小重构距离问题可以转化为以下最优化问题:
{ u ^ = a r g m i n ∑ k = q + 1 p u k T S u k s . t . u k T u k = 1 \left\{\begin{matrix} \hat{u}=argmin\sum_{k=q+1}^{p}u_{k}^{T}Su_{k}\\ s.t.\; u_{k}^{T}u_{k}=1 \end{matrix}\right. {u^=argmin∑k=q+1pukTSuks.t.ukTuk=1 -
求解优化问题
此优化问题与上一节一致,使用拉格朗日乘子法,很容易求得:
S u k = λ k u k Su_k=\lambda_k u_k Suk=λkuk目标 u k u_k uk为协方差矩阵 S S S的前 q q q个特征向量(前 q q q大的特征值对应的特征向量)。
5.5 SVD角度看PCA和PCoA
本节将从奇异值分解(SVD)的角度来看PCA。
已知数据
- X = ( x 1 x 2 ⋯ x N ) T = ( x 1 T x 2 T ⋮ x N T ) = ( x 11 x 12 ⋯ x 1 p x 21 x 22 ⋯ x 2 p ⋮ ⋮ ⋱ ⋮ x N 1 x N 2 ⋯ x N p ) N × p X=\begin{pmatrix} x_1&x_2& \cdots& x_N \end{pmatrix}^T= \begin{pmatrix} x_1^T\\x_2^T\\\vdots\\x_N^T \end{pmatrix}= \begin{pmatrix} x_{11}&x_{12} & \cdots& x_{1p}\\ x_{21}&x_{22}&\cdots&x_{2p}\\ \vdots&\vdots&\ddots&\vdots\\ x_{N1}&x_{N2}&\cdots &x_{Np} \end{pmatrix}_{N\times p} X=(x1x2⋯xN)T=⎝⎜⎜⎜⎛x1Tx2T⋮xNT⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛x11x21⋮xN1x12x22⋮xN2⋯⋯⋱⋯x1px2p⋮xNp⎠⎟⎟⎟⎞N×p
其中 x i ∈ R p , i = 1 , 2 , ⋯ , N x_i \in \mathbb R^p ,\ \ i=1, 2, \cdots, N xi∈Rp, i=1,2,⋯,N。 - 样本均值为: x ˉ = 1 N ∑ i = 1 N x i = 1 N X T 1 N \bar x={1\over N}\sum_{i=1}^N x_i={1\over N}X^T1_N xˉ=N1i=1∑Nxi=N1XT1N
- 样本方差为: S p × p = 1 N ∑ i = 1 N ( x i − X ‾ ) ( x i − X ‾ ) T = 1 N X T H X S_{p\times p}={1\over N} \sum^{N}_{i=1}(x_i - \overline X)(x_i - \overline X)^T={1\over N}X^THX Sp×p=N1i=1∑N(xi−X)(xi−X)T=N1XTHX
其中: 1 N = ( 1 1 ⋮ 1 ) 1_N=\begin{pmatrix} 1\\1\\\vdots\\1 \end{pmatrix} 1N=⎝⎜⎜⎜⎛11⋮1⎠⎟⎟⎟⎞, H N = I N − 1 N 1 N 1 N T H_N=I_N-{1\over N}1_N1_N^T HN=IN−N11N1NT, X ‾ ∈ R p \overline X\in \mathbb R^p X∈Rp, S ∈ R p × p S\in \mathbb R^{p\times p} S∈Rp×p。
5.5.1 SVD角度看PCA的特征向量选取
将 X X X从 p \color{Teal}p p降维到 q \color{Teal}q q维( p > q \color{Teal}p>q p>q),有以下2个方法:
- 通过协方差矩阵S奇异值分解
协方差矩阵S的特征分解:因为 S S S为对称矩阵,所以 S = G K G T \color{red}S=GKG^{T} S=GKGT,其中
G T G = I , K = [ k 1 k 2 ⋱ k p ] , k 1 ≥ k 2 ≥ ⋯ ≥ k p G^{T}G=I,K=\begin{bmatrix} k_{1} & & & \\ & k_{2} & & \\ & & \ddots & \\ & & & k_{p} \end{bmatrix},k_{1}\geq k_{2}\geq \cdots \geq k_{p} GTG=I,K=⎣⎢⎢⎡k1k2⋱kp⎦⎥⎥⎤,k1≥k2≥⋯≥kp
协方差矩阵 S S S的前 q q q个特征向量(前 q q q大的特征值对应的特征向量)即为PCA的转换后的坐标。 - 通过数据X奇异值分解
- 首先,将数据 X X X进行中心化,左乘中心矩阵 H N H_N HN,即: H X HX HX。
- 将中心化后的 H X HX HX进行奇异值分解:
H X = U Σ V T HX=U\Sigma V^T HX=UΣVTU U U 为 R N × N \mathbb R^{N\times N} RN×N 的矩阵,列正交,并且 U T U = I \color{blue}U^TU=I UTU=I; Σ \Sigma Σ 为 R N × P \mathbb R^{N\times P} RN×P 的矩阵且为 对 角 矩 阵 \color{blue}对角矩阵 对角矩阵; V T V^T VT 为 R P × P \mathbb R^{P\times P} RP×P 的矩阵,正交矩阵,并且 V T V = V V T = I \color{blue}V^TV=VV^T=I VTV=VVT=I
- 将 H X HX HX与 S S S进行联系
5.2节的结论 S = 1 N X T H X \color{red}S={1\over N}X^THX S=N1XTHX,且 H H H有以下性质: H = H T , H 2 = H H=H^T,H^2=H H=HT,H2=H。则:
S p × p = 1 N X T H X = 1 N X T H T H X = 1 N V Σ T U T U Σ V T = 1 N V Σ T Σ V T S_{p\times p}=\frac{1}{N}X^{T}HX=\frac{1}{N}X^{T}H^{T}HX=\frac{1}{N}V\Sigma^{T} U^{T}U\Sigma V^{T}=\frac{1}{N}V\Sigma^{T}\Sigma V^{T} Sp×p=N1XTHX=N1XTHTHX=N1VΣTUTUΣVT=N1VΣTΣVT
因此 S = 1 N V Σ T Σ V T \color{red}S=\frac{1}{N}V\Sigma^{T}\Sigma V^{T} S=N1VΣTΣVT是 S S S的特征值分解, Σ T Σ \Sigma^{T}\Sigma ΣTΣ 即为上式子中的 K K K。
由于通常求解 S \color{red}S S并对其奇异值分解比较困难,我们可以用计算 H X \color{red}HX HX奇异值分解找到需要转换的 q \color{Teal}q q维度。
5.5.2 SVD角度看PCA的坐标转换
找到 q \color{Teal}q q维度后,接下来寻找 X X X投影到主成份的方向后的坐标。我们构造矩阵 T N × N T_{N\times N} TN×N:
T N × N = H X X T H T = U Σ V T V Σ T U T = U Σ Σ T U T T_{N\times N}=HXX^{T}H^{T}=U\Sigma V^{T}V\Sigma^{T} U^{T}=U\Sigma \Sigma^{T} U^{T} TN×N=HXXTHT=UΣVTVΣTUT=UΣΣTUT
其中 U Σ Σ T U T U\Sigma \Sigma^{T} U^{T} UΣΣTUT是 T T T的特征值分解, Σ Σ T \Sigma \Sigma^{T} ΣΣT为特征值矩阵。则寻找转换后的坐标有以下两种方法:
- H X ⋅ V \color{red}HX\cdot V HX⋅V
将 S S S进行特征分解然后得到投影的方向,也就是主成分,然后矩阵 H X V HXV HXV即为重构坐标系的坐标矩阵。即:
H X ⋅ V = U Σ V T V = U Σ HX\cdot V=U\Sigma V^TV=U\Sigma HX⋅V=UΣVTV=UΣ - 将 T N × N \color{red}T_{N\times N} TN×N奇异值分解
将 T T T进行特征分解可以直接获得坐标矩阵 U Σ U\Sigma UΣ,即:
T N × N U Σ = U Σ Σ T U T U Σ = U Σ ( Σ T Σ ) T_{N\times N}{\color{Red} {U\Sigma}} =U\Sigma \Sigma^{T} U^{T}U\Sigma ={\color{Red} {U\Sigma}} (\Sigma^{T} \Sigma ) TN×NUΣ=UΣΣTUTUΣ=UΣ(ΣTΣ)
也就是说 U Σ U\Sigma UΣ是 T N × N T_{N\times N} TN×N的特征向量组成的矩阵。把这种方法叫做PCoA(Principle Coordinate Analysis)。
注:
- 应保证 S S S和 T N × N T_{N\times N} TN×N特征分解得到的特征向量是 单 位 向 量 \color{blue}单位向量 单位向量。
- ⽅差矩阵 S ∈ R p × p S\in\mathbb R^{p\times p} S∈Rp×p的,⽽ T N × N ∈ R N × N T_{N\times N}\in \mathbb R^{N\times N} TN×N∈RN×N的,当样本量较少( N 较 少 \color{red}N较少 N较少)的时候可以采⽤ PCoA的⽅法。
5.6 概率PCA(p-PCA)
5.6.1 概述
前面几节课从最大投影方差、最小重构代价和SVD 3个角度解决了PCA问题,本节将从概率角度来看PCA,这种方法也被称为P-PCA(Probabilistic PCA)
- 数据
假设有以下数据:
x ∈ R p , z ∈ R q , p > q x\in \mathbb{R}^{p},z\in \mathbb{R}^{q},p>q x∈Rp,z∈Rq,p>q
其中 x x x是原始数据, z z z是降维后的数据,可以将 z z z看做隐变量(latent variable), x x x看做观测变量(observed variable),则p-PCA就可以看做生成模型。 - 假设
假设 x x x和 z z z满足以下关系:
{ z ∼ N ( 0 p , I p ) x = W z + μ + ε ε ∼ N ( 0 , σ ⋅ I p ) ε ⊥ z ( 独 立 ) \begin{cases} z\sim N(0_p, I_p)\\ x=Wz+\mu+\varepsilon\\ \varepsilon\sim N(0, \sigma\cdot I_p)\\ \varepsilon \bot z(独立) \end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧z∼N(0p,Ip)x=Wz+μ+εε∼N(0,σ⋅Ip)ε⊥z(独立)
这是一个线性高斯模型,其中 ε \varepsilon ε是噪声,其中 σ ⋅ I p \sigma \cdot I_p σ⋅Ip。 - 求解
求解P-PCA有如下两个步骤:
P − P C A { I n f e r e n c e : 求 p ( z ∣ x ) L e a r n i n g : 求 解 参 数 W , μ , σ 2 → E M 算 法 P-PCA \begin{cases} Inference:求p(z|x)\\ Learning:求解参数W,\mu,\sigma^2 \rightarrow EM算法 \end{cases} P−PCA{Inference:求p(z∣x)Learning:求解参数W,μ,σ2→EM算法
x x x的生成过程如下:
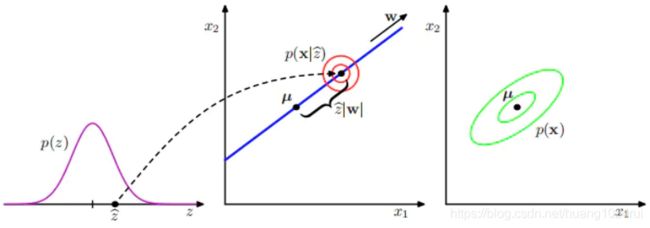
上图中数据空间为⼆维,潜在空间为⼀维。⼀个观测数据点 x x x的⽣成⽅式为:⾸先从潜在变量的先验分布 p ( z ) p(z) p(z)中抽取⼀个潜在变量的值 z ^ \hat{z} z^,然后从⼀个各向同性的⾼斯分布(⽤红⾊圆圈表示)中抽取⼀个 x x x的值,这个各向同性的⾼斯分布的均值为 W z ^ + μ W\hat{z}+\mu Wz^+μ,协⽅差为 σ 2 I σ^{2}I σ2I。绿⾊椭圆画出了边缘概率分布 p ( x ) p(x) p(x)的密度轮廓线。 - 推断(inference)
求解 P ( z ∣ x ) P(z|x) P(z∣x)的过程如下:
P ( z ) → P ( x ∣ z ) → P ( x ) → P ( z ∣ x ) P(z)\rightarrow P(x|z)\rightarrow P(x)\rightarrow P(z|x) P(z)→P(x∣z)→