数据分析方法——用户群组分析
文章目录
- 数据分析方法——用户群组分析
-
- 内容摘要
- 一、群组分析方法介绍
- 二、项目背景及目的
- 三、python实操
-
- (1)数据导入
- (2)数据处理
- (3)用户群组存留率计算
- (4)用户群组存留率可视化
- 四、总结
数据分析方法——用户群组分析
内容摘要
一、群组分析方法介绍
- 群组分析方法就是按照某个特征对数据进行分组,通过分组比较得出结论并提供指导的方法。
- 将用户数据按照性别特征,可以分成男生和女生;将用户注册时间作为特征,按注册的月不同可以进行分组。
- 群组分析的方法常常用来分析用户留存/流失问题,或者金融行业用户还款逾期的问题,其根据月份分组等分析方式较为常见。
- 群组分析主要目的是分析相似群体随时间的变化,核心就是对比、分析不同时间群组的用户在相同的周期下的行为差异,也称同期群分析。
- 群组分析的三个步骤:
1、数据分组
2、假设检验,针对问题提出假设进行检验
3、相关性分析法,对比不同假设之间的相关性
本博客以步骤一(数据分组)为主
二、项目背景及目的
某电商平台有一批用户消费记录,包括用户信息,订单信息,金额,订单日期等等。希望通过群组分析,查看用户留存率变化趋势,分析不同时间群组的用户在相同的周期下的行为差异,为后续针对不同用户群体制定策略起到基础性工作。
三、python实操
(1)数据导入
- 常规操作:导入必备的pandas、numpy库,本次数据存放在数据库中,再导入sqlalchemy库
- 使用sqlalchemy库,调用数据库
import pandas as pd
import numpy as np
import sqlalchemy
# 读取数据
engine = sqlalchemy.create_engine('mysql+pymysql://**********@localhost:3306/froghd')
sql_cmd = "select * from groups_data"
# 执行sql语句,获取数据
df = pd.read_sql(sql=sql_cmd, con=engine)
#数据展示
df.head()

- 数据集如上图所示,我们主要集中统计用户数量(userid)、订单数量(orderid)、订单日期(orderdate)和总金额(totalcharges)
(2)数据处理
- 一
- 本次群组分析的主要是针对每月的新用户的留存率进行分析,因此需要以月为尺度进行整理数据。
- 数据集中的订单日期精确到了日,我们需要将其省略至月(这里使用strftime函数进行提取)
# 生成一个新字段,用户订单月份
df["orderperiod"] = df.orderdate.apply(lambda x:x.strftime("%Y-%m"))

- 二
- 群组分析针对月份,首先要确定每个月的新用户是多少,因此需要确定每个用户的最早购买日期,也是用户群组的标志
- 之后的分析是针对时间序列的,因此每个用户每次购买的日期也需要
- 因此考虑以用户信息(userid)为分组依据比较好,但是如果直接groupby的话,需要对其余信息进行聚集,如果对消费日期进行聚集则会出现缺失日期的情况,因此不能直接对userid分组
- 主要思路是将每个用户的最早消费日期与每一次的消费日期拼接在一起
- (1)考虑将用户信息(userid)当作索引,再对索引分组
- (2)新增加一列用户的最早购买日期(即用户群组)
- (3)之后再通过重置索引列,将分组数据拆成独立的数据
# 设置userid为索引
df.set_index("userid",inplace=True)
# 这里的level=0表示第一层索引即userid,并且每次分组之后都会形成很多个dataframe
# 按照每个用户的订单的最早时期,生成用户群组
df["cohortgroup"]=df.groupby(level=0)["orderdate"].min().apply(lambda x:x.strftime("%Y-%m"))
df.reset_index(inplace=True)
df.head()

- 三
- 可以看出每一个用户每一次消费的记录后面都有两个时间,一个是本次消费的时间,一个是该用户最早的消费时间
- 之后对用户群组和消费时间进行分组
# 根据用户群组和月份字段进行分组
grouped = df.groupby(["cohortgroup","orderperiod"])
# 求每个用户群下每一个月份的用户数量、订单数量、购买金额
cohorts = grouped.agg({"userid":pd.Series.nunique,
"orderid":pd.Series.nunique,
"totalcharges":np.sum})
# 重命名
cohorts.rename(columns={"userid":"totalusers",
"orderid":"totalorders"},inplace=True)
cohorts.head()

-
四
-
随后还可以对每一个用户群组内的数据进行标签简化
-
每一个用户群组进行groupby并打标签
# 把每个群组继续购买的日期字段进行改变
def cohort_period(df):
# 给首次购买日期进行编号,第二次购买为2,第三次购买为3
df["cohortperiod"] = np.arange(len(df)) + 1
return df
# 注意的是apply后面传入的是一个个dataframe
cohorts = cohorts.groupby(level=0).apply(cohort_period)
cohorts.head()

(3)用户群组存留率计算
- 用户群组存留率计算的关键:每个用户群组初始数量,利用随后每一个月的留存量除以初始数量即可,其初始数量就是用户群组(最早日期)跟群组内日期相同那组的用户个数
- 一
- 针对之前简化后的数据可以进行索引的简化
- 调整groupby索引的方法:
-(1)先将groupby数据拆解成DataFrame数据;利用reset_index
-(2)再重新设定索引列;利用set_index([ ])
# 得到每个群组的用户量
# 重新设置索引
cohorts.reset_index(inplace=True)
cohorts.set_index(["cohortgroup","cohortperiod"],inplace=True)
cohorts.head()
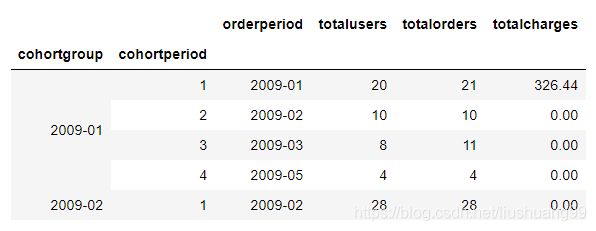
- 二
- 统计每一个用户群组初始数量:就是用户群组(最早日期)跟群组内日期相同那组的用户个数
# 得到每个群组的用户量,就是第一天的用户数据量,用作留存率的分母
cohort_group_size = cohorts["totalusers"].groupby(level=0).first()
cohort_group_size.head()

- 三
- 将数据进行调整,groupby的数据旋转过来,时间序列沿着横轴,利用unstack函数
# 计算每个群组的留存
# unstack 是把index转化为column
#unstack()中的序号表示要展示的列名
cohorts["totalusers"].unstack(0).head()

- 四
- 留存率计算,每一月的除以初始数量
# 计算留存
user_retention = cohorts["totalusers"].unstack(0).divide(cohort_group_size,axis=1)
user_retention.head()
#这里写法不唯一,可以使用apply搭配lambda函数

(4)用户群组存留率可视化
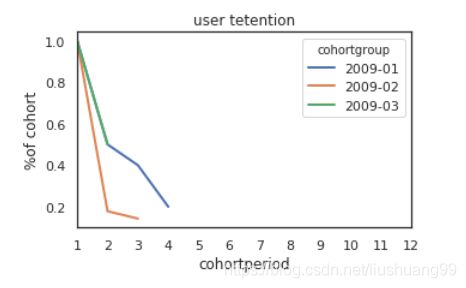
- 一
- 折线图
# 折线图展示
import matplotlib.pyplot as plt
import matplotlib as mpl
pd.set_option("max_columns",50)
mpl.rcParams["lines.linewidth"] = 2
%matplotlib inline
user_retention[["2009-01","2009-02","2009-03"]].plot(figsize=(5,3))
plt.title("user tetention")
plt.xticks(np.arange(1,12.1,1))
plt.xlim(1,12)
plt.ylabel("%of cohort")
- 二
- 热力图
# 热力图展示
import seaborn as sns
sns.set(style="white")
plt.figure(figsize=(8,4))
plt.title("co:user retention")
sns.heatmap(user_retention.T,mask=user_retention.T.isnull(),annot=True,fmt=".0%")

四、总结
-
本次主要以理解用户群组分析方法和python代码实操为主
-
用户群组分析就是将用户按照一定的特征进行分组归纳,其中一部分有些类似数据分箱;但主要应用方面是对不同时期的用户进行时间序列的分析,观察留存率,新老用户行为等等
-
python实现时间上的用户群组分析,需要注意如下几点:
(1)落脚点是用户,需要对用户进行groupby,但是要整合每个用户的最早消费日期和每次消费日期,故需要将用户信息设置成索引从而保证数据的完整性;
(2)将每个用户的两个时间整合好后,才开始进行用户群组(相同的起始时间)分析,对其进行groupby分组;
(3)留存率的分母是每一群组的起始用户数量=两个时间相同下的用户信息 -
对用户群组进行分解整理后,为后续的假设检验和相关性分析打下基础。