百度文档去摩尔纹比赛分享
百度网盘文档图像摩尔纹消除比赛分享

百度网盘文档图像摩尔纹消除比赛是百度网盘开放平台 面向AI开发者和爱好者发起的计算机视觉领域挑战赛。AI时代已到来,百度网盘与百度飞桨AI Studio强强联合,旨在基于个人云存储的生态能力开放,通过比赛机制,鼓励选手结合当下前沿的计算机视觉技术与图像处理技术,完成模型设计搭建与训练优化,产出基于飞桨框架的开源模型方案,为中国开源生态建设贡献一份力量。
比赛链接:https://aistudio.baidu.com/aistudio/competition/detail/128/0/introduction
赛题概述
图像去摩尔纹是一项涉及纹理和颜色恢复的多层面图像恢复任务。需要建立模型,对比赛给定的带有摩尔纹的图片进行处理,消除屏摄产生的摩尔纹噪声,还原图片原本的样子,并提交模型输出的结果图片。
因为我们平时也做一些其他的图像修复的任务,所以觉得这个比赛可以尝试一下。官方虽然给出了一些参考论文和代码,但是限制只能用paddle框架,考虑到后面torch模型或者tensorflow的模型在转paddle的时候可能会出现一些Bug,我们就只在官方给的基准线上进行修改。

数据分析
比赛公布的数据集分为训练集、A榜测试集、B榜测试集,训练集共1000个样本,A榜测试集共200个样本,B榜测试集共200个样本。仅有训练集数据提供gts ,A榜测试集、B榜测试集数据均不提供gts,images 与 gts 中的图片是一一对应的。
通过观察训练数据,我们发现有这样一些问题:1.字体图案与摩尔纹难以区分;2.摩尔纹的尺度与频率跨度较大;3.摩尔纹图案在颜色上分布也不均匀。

所以,针对以上问题,我们想先在前人工作的基础上,先用baseline实现一个基本的摩尔纹消除效果,然后通过调整参数找到这个问题的瓶颈,从而进一步优化这个结果。为了方便我们自己的工作,我们使用官方的基线模型为基础。
官方基线:https://aistudio.baidu.com/aistudio/projectdetail/3220041?shared=1
数据处理
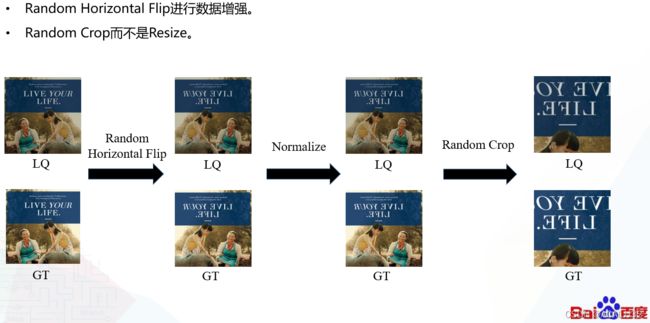
在官方提供的基线中,输入的图像是resize到(512,512),然后再输入模型进行训练的,考虑到resize本质上是在做插值运算,所以我们就通过随机裁剪的方法进行处理;数据增强方面我们就使用了随机裁剪,没有再进行其他的操作。
模型搭建与优化
官方给的基线是WDNet,但是没有给DPM模块的实现,虽然我们在比赛中也尝试进行了复现,但是DPM模块会带来很大的计算量,所以我们放弃了这个模块。
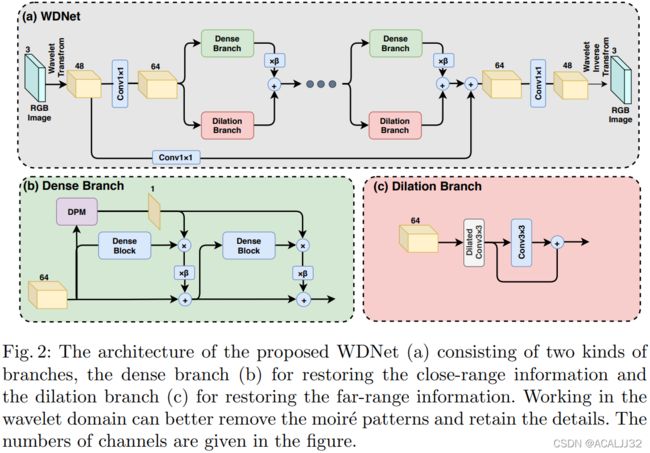
我们的比赛模型经过最后的讨论,结构如下:

之所以这样做,是因为我们发现虽然用一个单纯的去摩尔纹模型能够实现摩尔纹的消除,但是任何一个这样的模型都有自己的极限,单模型输出的结果中,文本图像中的字体会出现模糊,我们想再通过一个去模糊网络让图像中的字体变清楚,提高感官质量。我们第一阶段模型的结构如下:
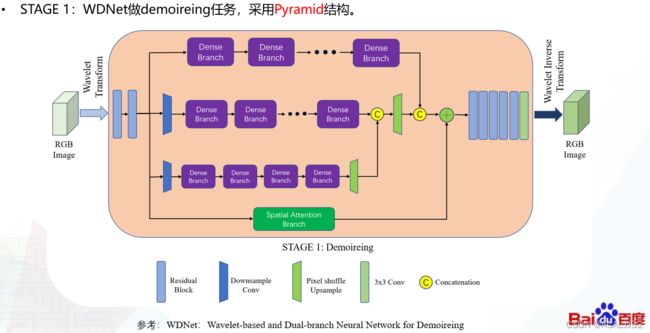
第一阶段的模型中,我们仍然保留了原本的Dense Branch的主要结构,因为我们尝试过用一般的残差块去替换这个Dense Branch,但是很难有提升。Dense Branch的实现如下:
class ResidualDenseBlock_5C(nn.Layer):
"""
Residual Dense Block
style: 5 convs
The core module of paper: (Residual Dense Network for Image Super-Resolution, CVPR 18)
"""
def __init__(self, nc, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
norm_type=None, act_type='leakyrelu', mode='CA'):
super(ResidualDenseBlock_5C, self).__init__()
# gc: growth channel, i.e. intermediate channels
self.conv1 = conv_block(nc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv2 = conv_block(nc + gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv3 = conv_block(nc + 2 * gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv4 = conv_block(nc + 3 * gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
if mode == 'CNA':
last_act = None
else:
last_act = act_type
self.conv5 = conv_block(nc + 4 * gc, nc, 3, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=last_act, mode=mode)
# spatial attention
# self.spatial_fusion = SpatialAttentionExtractor(nc, nc)
def forward(self, x):
# dense block
x1 = self.conv1(x)
x2 = self.conv2(paddle.concat((x, x1), 1))
x3 = self.conv3(paddle.concat((x, x1, x2), 1))
x4 = self.conv4(paddle.concat((x, x1, x2, x3), 1))
x5 = self.conv5(paddle.concat((x, x1, x2, x3, x4), 1)) * 0.2
# spatial attention
# out = self.spatial_fusion(x5)
return x5
相比较于官方提供的基线模型,我们增加了多尺度分支,这样可以让模型学习到更丰富的表征,在A榜前期测的时候,我们将分支数改为3,实验效果就得到了很大的提升,对比如下:

我们多分支的实现如下:
# model.py
# pyramid downsample conv
self.down_sample_conv1 = DownSample(in_channels=mid_channel, mid_channels=mid_channel)
self.down_sample_conv2 = DownSample(in_channels=mid_channel, mid_channels=mid_channel)
# upsample conv
self.upsample1 = PixelShufflePack(mid_channel, mid_channel, 2, 3)
self.upsample2 = PixelShufflePack(mid_channel, mid_channel, 2, 3)
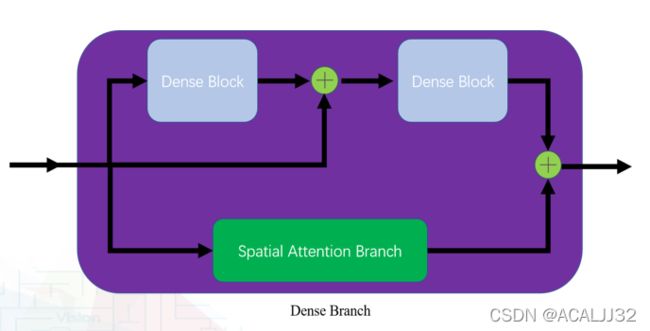
其中,我们认为Dilation Branch过于简单,我们认为这个模块虽然能保留特征的信息,但是没有其他的辅助作用,所以我们用空间注意力模块去进行替换:
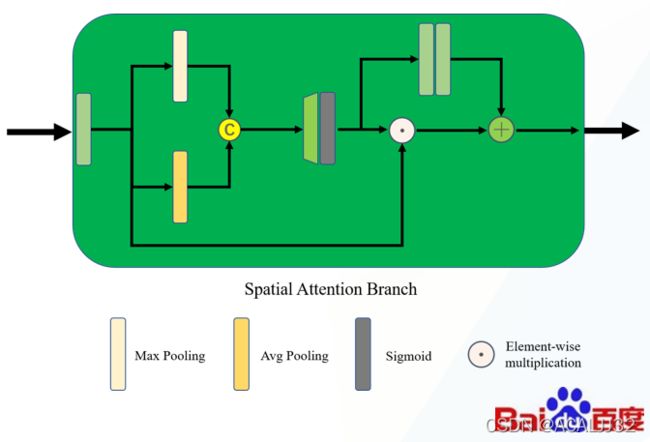
最后发现,这个空间注意力模块会带来不错的提升。
在观察实验结果的时候,我们发现虽然整体的摩尔纹虽然去除得很好了,但是文档中的字体却变得比以前模糊了,所以我们想找一个轻量的模型去做一个去模糊的任务,后来我们找到了一个比较合适的模型PAN:
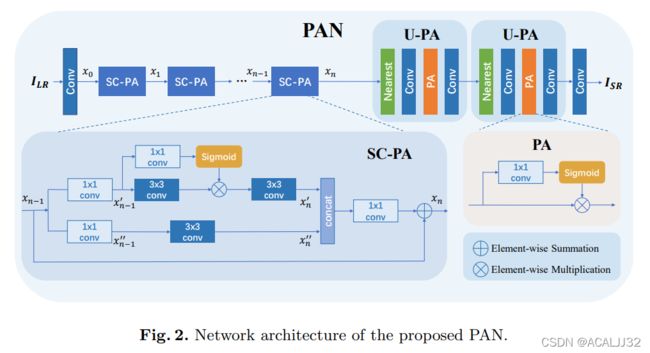
我们在实际应用的过程中,模型是这样的:
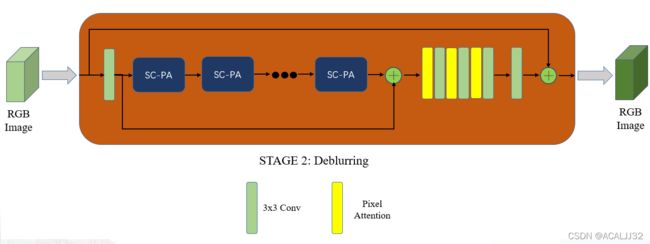
只有最后的几层是不一样的,其他的模块完全没有改动。
实验详情
学习率,batch_size,损失函数等等我们主要还是使用原论文提供的参数,但是在训练策略上有一个很重要的提升分数的点,就是分阶段训练,首先让patch size固定为128x128,训练至收敛,再增大到256x256,最后增加到512x512,就能得到一个不错的分数:

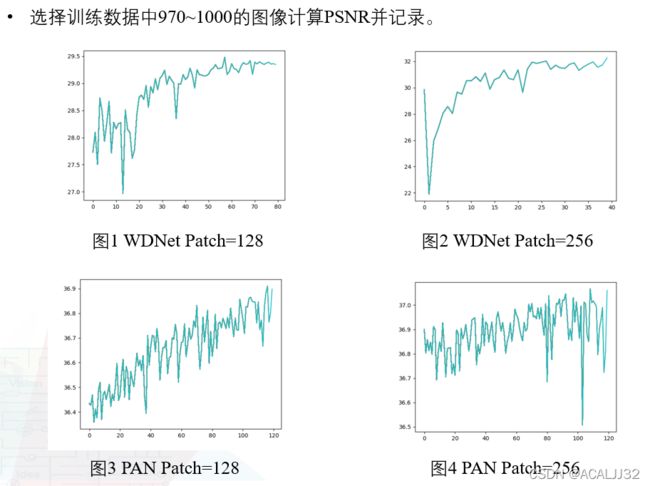
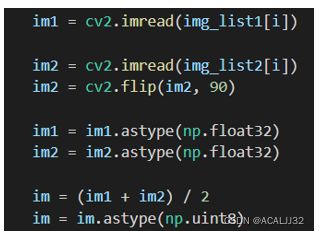
数据后处理
考虑到模型在训练的过程中,有的图像是进过水平翻转的,所以我们将图像翻转后输入模型,最后计算图像的均值,发现也可以提高分数。
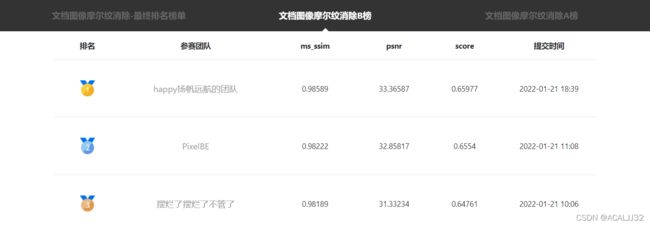
比赛结果
B榜结果,我们是B榜上的第三名
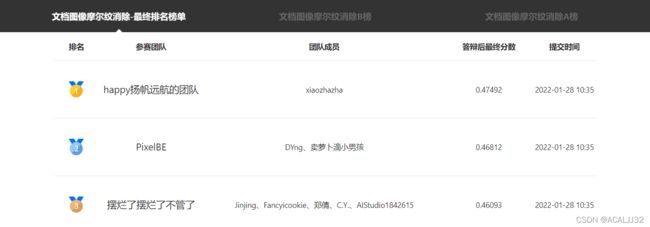
答辩综合结果:
小结
通过这次比赛,我们小队也有不少的收获,很多实验上的尝试也打破了自己以往的想法:有时候你觉得你的改进一定有效,但是分数就是不涨,让人很郁闷。在比赛过程中,自己对实验的总结与归纳也有问题,比如一次改动太多,哪种改进会带来提升我们自己也解释不清楚。所以总结一下:
- 在比赛前期,还是要尽可能多得阅读相关文献,寻找解决方案,多做尝试,任何一种模型都有自己的瓶颈,如果你一开始就死盯着一个模型去调整,那最后很可能陷入到某一个坑里,再想跳出来还是很难的。
- 找到问题的关键:在调整模型参数的时候,需要通过观察实验结果,感知到限制你模型性能的模块在哪个部分,针对这部分再去做修改;不要对模型一次性进行太大的改动,这样做你会很难清楚你的哪一种改动对提高分数是有帮助的,做好实验记录,每次保存好你的model.py。
- 和队友多沟通:一个人的力量毕竟是有限的,比赛时应该集思广益,和队友们多多沟通讨论,分享改进的心得,这样也更容易打出好成绩。
比赛给我带来的另一个好处就是,让我比平时更有紧迫感,我们需要在有限的时间内做出好的结果,这次比赛中的核心:两阶段模型,本质上我自己被逼急了,train一个单模型总是train不起来,索性就用两个模型来做,然后发现效果还不错,这也是我们能拿到好成绩的关键。希望我们的比赛经验对大家有所帮助。
代码
github:https://github.com/ACALJJ32/WDNet_PAN.git
AI studio: https://aistudio.baidu.com/aistudio/projectdetail/3439026?shared=1