清华、复旦、人大联合推出43页预训练模型综述!
卷友们好,我是rumor。
好久没追预训练模型的前沿了,这两天刷到Arixv上新挂的一篇综述,由清华朱军老师领衔主创,决定拿来看一看。没想到居然有43页,我瞬间裂开,幸好参考文献就占了13页,算一算才30页我就又支棱起来了。
Survey无论是对于刚入门还是老司机来说都是有帮助的,可以帮新手进行论文筛选,也可以帮老司机进行体系梳理、查漏补缺。
这篇文章主要从模型结构、数据、计算效率、可解释性四方面梳理了PTMs(Pre-trained Models)的进展,并提出了一些有空间的优化方向,还是有挺多启发的。这里带大家速读全文,有时间推荐去精读一下~

题目:Pre-Trained Models: Past, Present and Future
地址:https://arxiv.org/abs/2106.07139发展背景
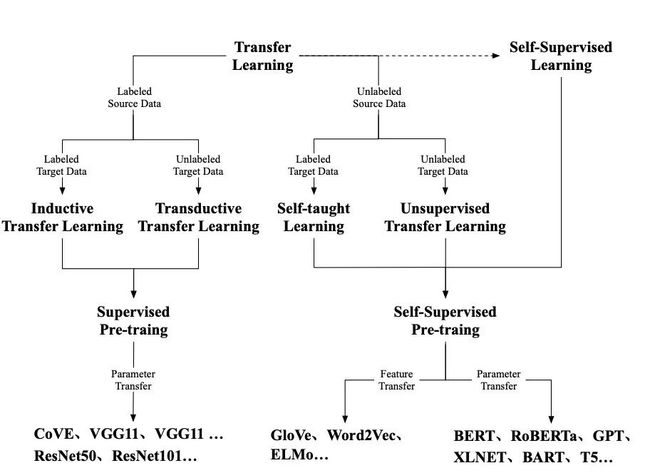
在自监督预训练火起来以前,主要是迁移学习的天下。毕竟我们不能给每个任务都标一堆数据,于是可以参考人类的能力,根据已有知识去解决未知问题。
图像领域有ImageNet这个宝藏,可以对模型进行有监督预训练然后迁移到下游任务,而NLP领域的数据标注难度太大了,于是以无监督训练为主。最开始是词向量这类的Feature transfer,把训练好的词表示作为下游模型的输入,但feature是死的,「我要吃苹果」和「苹果手机」里的苹果用的是一个表示,于是再提升就有了基于上下文的表示,直接把预训练的模型迁移到任务,再加深加数据,就有了BERT。
P.S. 大家(比如我)有时候会把无监督和字监督搞混,可以认为自监督是无监督的一种(因为数据没有label),但也可以它们是两个东西,无监督主要指聚类、异常检测这种模式识别任务,而自监督的目标其实还是监督学习。
模型结构演进
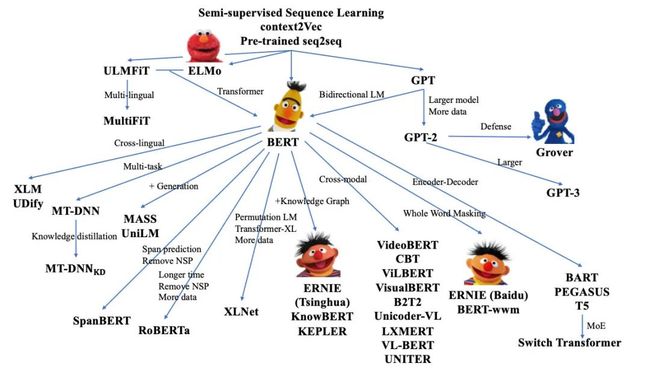
模型结构的演进有很多方向,作者着重梳理了两种,一种是想统一NLU和NLG任务,另一种是想模仿人类认知能力。
Unified Sequence Modeling
想做大统一的模型可以从两方面着手,第一是任务混合,第二是结构混合。
任务混合指将NLU和NLG同时进行预训练,比如XLNet、MPNet采用的Permutaioon language modeling,兼顾上下文与自回归;或者是UniLM, GLM采用的Multi-task training,通过对注意力矩阵的设计使得这两种任务同时训练。
结构混合则更多使用Seq2seq去做理解和生成。比如MASS、T5和BART。但也面临如下挑战:
编码器-解码器占用更多的参数,即使共享了,参数使用效率仍然值得怀疑
Seq2seq的结构在NLU任务上表现差,好于BERT但低于RoBERTa和GLM
Cognitive-Inspired Architectures
事实上,人脑远比Attention复杂的多,想达到人类智能,还需要决策能力、逻辑推理能力、反实时推理能力(脑淫「如果当时..」的技能)。
为了具备以上几种能力,需要模型有短时记忆与长期记忆,短时记忆用来决策和推理,长期记忆用来回忆事实和经验。
像Transformer-XL, CogQA, CogLTX这类模型,就是增加了Maintainable Working Memory,通过样本维度的记忆提升长距离理解能力,实现推理;REALM, RAG这类模型则是对语料、实体或者三元组进行记忆,具有Sustainable Long-Term Memory,将信息提前编码,在需要的时候检索出来。
其他工作
除了以上两条故事线,还有不少其他结构演进,比如:
提升mask策略,如SpanBERT、百度ERNIR、NEZHA、WWM
使用其他自监督目标,如ELECTRA
使用多源数据
除了优化模型结构外,跨语言、多模态也挖出了不少新坑。
Multilingual Pre-Training
BERT之前的跨语言学习主要有两种方法:
参数共享,比如使用跨语言平行语料让模型可以同时学到不同知识
学习语言无关的约束,将编码结偶为语言相关的部分和无关的部分
有了预训练方法之后,我们就可以在不同语言进行预训练了。mBERT在Wiki数据上进行多语言的MLM,之后XLM-R用了更好的语料后表现有所提升。但这两个模型都没有利用平行语料,于是XLM同时利用了平行语料,在平行语料做MLM,利用另一个语言的知识预测mask token。
后续研究还有Unicoder、ALM、InfoXLM、HICTL、ERNIE-M等,生成任务则有mBART、XNLG。
Multimodal Pre-Training
人在学习知识的时候其实都是多模态的,比如还是小baby的时候我们会学习看图识字,把猫啊狗啊印到自己脑子里。
多模态这个方向在去年火了一阵,比如VideoBERT、ViLBERT、VL-BERT等等。最近比较知名的就是OpenAI的DALLE和CLIP了,从CLIP的一些可视化研究中也可以看到数字和图像feature被很好的结合了起来,但image2text还是比text2image难不少,至今没看到亮眼的效果。
Knowledge-Enhanced Pre-Training
预训练模型可以从大量语料中进行学习,但知识图谱、领域知识不一定能学到。
对于这个问题可以有两种解决方案,一种是外挂型,把知识通过各种方法和文本一起输入进去,比如清华ERNIE、K-BERT,另一种是强迫型,在领域数据、结构化文本上精调,让模型记住这些知识,比如百度ERNIE、WWM。
提升计算效率
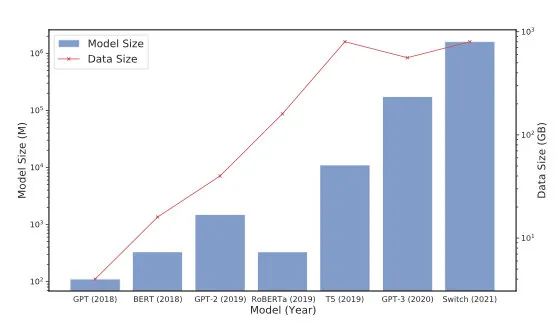
现在的工作愈加倾向用大模型暴力解决问题,每隔几个月就提升一个量级,试探公司的预算边界,提升训练效率、框架变成了很重要的方向。
System-Level Optimization
针对不同场景,优化策略是不一样的(可以参考这篇文章):
如果模型放得下,数据没那么多(百万内),单机就够了,速度提升可以用混合精度、提督检查点
如果模型放得下,数据很多,可以用数据并行,但优化器的状态还是会被整个传递,ZeRO optimizer则可以将优化器状态进行切分
模型放不下时,可以考虑模型并行,把矩阵运算切开,也可以用Pipeline并行方法,将模型不同层放在各个机器上,可以参考GPipe、TeraPipe
Efficient Pre-Training
对于训练效率的提升,也可以从两方面入手:
改进训练方法:BERT只mask 15%的token,学习效率较低,ELECTRA则可以对所有token进行学习;另外大batch很难学,可以用warmup strategy;如果对不同层使用不同学习率、先学浅层再逐渐加深也有利于模型收敛
提升结构效率:减小模型复杂度,增加稀疏性,比如Switch Transformers使用的Mix-of-experts
Model Compression
模型瘦身的方法也已经有很多了:
参数共享:比如ALBERT那样共享所有层的参数
模型剪枝:可以修剪head或者砍掉层
知识蒸馏
模型量化:常用的是FP16,也可以缩减到8bits甚至是1、2bits,但低比特模型跟硬件强相关,很难泛化
可解释性
Knowledge of PTMs
知识分为语言知识和世界知识,语言知识可以通过以下方法探测:
Representation Probing:接一个线性层,通过下游任务探测表示中是否含有语言知识
Representation Analysis:对表示进行统计分析
Attention analysis:分析注意力矩阵
Generation Analysis:预测单词或句子的分布,观察现象
从一些研究中发现,PTMs可以学习到句法、语义、局部以及长距离信息。同时在句子级别的特征抽取上表现也更好。
对于世界知识,可以设置一些任务来探查,已经有研究从PTMs中抽取出了三元组。
Robustness of PTMs
检验模型鲁棒性,可以设计对抗样本,比如同义词替换,现在更倾向于human-in-the-loop的方法来设计更自然的对抗样本。总的来说现在模型的鲁棒性表现仍然堪忧。
Structural Sparsity of PTMs
大型Transformer存在严重的过参数化,部分研究表明移除head反而得到更好的表现,一些head的注意力pattern也是相似的。也有研究正时去掉30-40%参数也不会影响表现,模型中可以找到表现相当的子结构。
Theoretical Analysis of PTMs
这部分主要探究为什么预训练可以work。有学者认为,预训练可以带来:
better optimization:预训练是模型更接近全局最优
better regularization:预训练带来更好的泛化能力
也有研究通过对比学习的分析,猜测对比学习的loss是下游任务loss的上界,所以迁移到下游时可以有更低的loss。
未来方向
Architectures and Pre-Training Methods
New Architectures:降低Transformer计算复杂度、适配更多终端设备、针对任务设计更适合的结构
New Pre-Training Tasks:现在最有效的任务是MLM,但这个任务需要很深的网络,也更难收敛
Beyond Fine-Tuning:现在对每个下游任务都要精调一个模型,能否统一成一个,再加上浅层进行任务适配?GPT-3的精调方式就是一个很好的尝试
Reliability:提升鲁棒性、可解释性
Multilingual and Multimodal Pre-Training
More Modalities:视频、语音同样重要,但在这类数据上预训练的成本太大了,需要更有效的方法进行复杂模态的预训练
More Insightful Interpretation:为什么加上图像work?单模态有什么缺陷?
More Downstream Applications:现在多模态模型主要用于检索、生成,是否有更接近现实的应用?
Transfer Learnin:多模态预训练无法学习隐性知识,比如在同声翻译中,需要先把语音转成文字,进行文字翻译后再转为语音,能否通过多模态、多语言PTMs一步到位?
Computational Efficiency
Data Movement:现在分布式很大的瓶颈在设备通信上,能否设计自动化的策略提升数据传递效率?
Parallelism Strategies:模型并行、Pipeline并行都依赖网络结构和设备配置,能否有更自动的策略,减少人工设计成本?
Large-Scale Training Tools, Wrappers and Plugins
Theoretical Foundation
Uncertainty:模型对预测过于自信,比如问“你的脚有几只眼睛?”这种问题也会回答,已经有研究在利用贝叶斯方法研究这个问题
Generalization and Robustness:预训练为何能提升泛化性?如何提升鲁棒性?
Modeledge Learning
P.S. Modeledge指模型表示中蕴藏的知识。
Knowledge-Aware Tasks:已经有研究证实PTMs中存储着知识,但如何更好的利用这些知识呢?
Modeledge Storage and Management:如何对知识进行更好的存储和管理,在其他语料训练需要大量计算并避免灾难性遗忘,是否可以把不同模型的知识合并到一起?
Cognitive and Knowledgeable Learning
Knowledge Augmentation:如何利用更好的结构、预训练方法,把异构的知识融入到文本中?
Knowledge Support:利用先验知识对数据进行处理,加速PTMs的训练和理解
Knowledge Supervision:利用KG进行预训练
Cognitive Architecture:更接近人脑的结构
Explicit and Controllable Reasoning:增强复杂推理、多跳推理能力
Interactions of Knowledge:PTMs内部是否把知识存储到了不同部分,它们是如何交互的?
Applications
Natural Language Generation:低资源生成
Dialog Systems:为对话定制的预训练任务
Domain-Specific PTMs:有更多领域知识的预训练模型
Domain Adaptation and Task Adaptation:领域和任务数据总是较少的,对于大模型会欠拟合,如何更高效地精调?
最后,NLP还有这么多坑等着填,我们的卷王群岂能怠慢!第4个群上周又满了,5群等着你鸭~


大家好我是rumor
一个热爱技术,有一点点幽默的妹子
欢迎关注我
带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「看花了眼」