pybullet-GGCNN神经网络搭建及训练
环境配置
推荐配置
py3.7
程序介绍
文件主体包含几个文件夹和两个编码文件
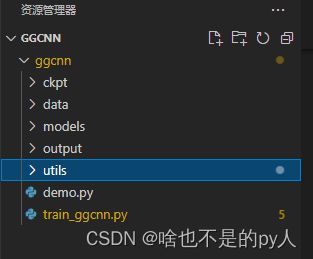
主程序就是train_ggcnn.py
就是用它来训练
 ckpt保存的是训练好的模型
ckpt保存的是训练好的模型
 data是保存用来测试平面抓取的图像
data是保存用来测试平面抓取的图像
 models是存储的网络
models是存储的网络
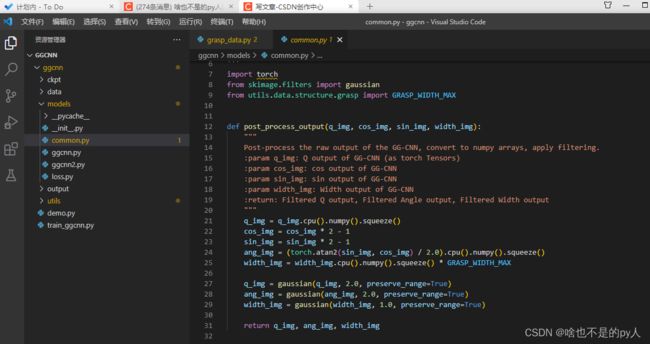
common.py是一个后处理文件
utils主要是数据加载类的编码

其中
该文件处理的是cornell数据集的内容
因为cornell没有提供.tiff格式的文件而是点云形式的.txt文件
见下图(其实就是点云文件)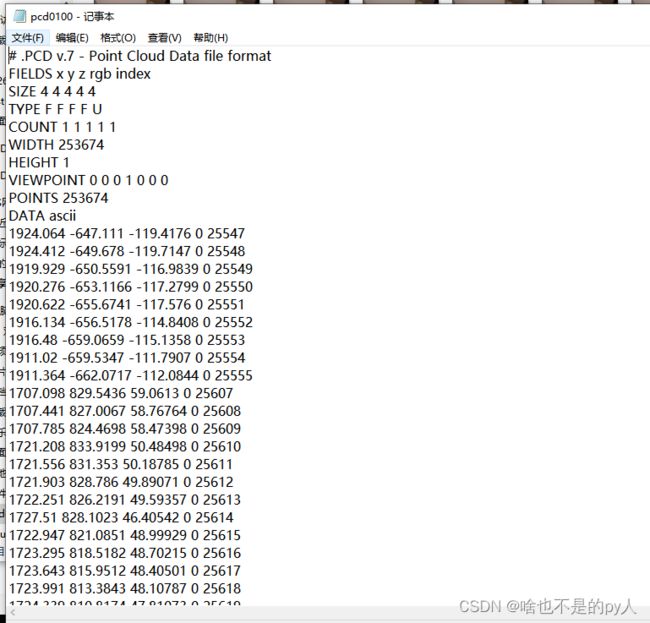
该程序就是把点云格式文件转换成.tiff格式文件
以及评估性能的文件

主程序理解
下图为主程序
看run()函数
def run():
# 设置随机数种子
# setup_seed(2)可以设置随机数种子方便复现
这里注释掉了
Python seed() 函数 | 菜鸟教程
超参数部分
然后读取超参数
args = parse_args()
可以选择读取ggcnn或者ggcnn2
设置之前标注好的数据集路径
![]()
# 训练超参数
parser.add_argument('--batch-size', type=int, default=2, help='Batch size')
parser.add_argument('--epochs', type=int, default=1000, help='Training epochs')
parser.add_argument('--lr', type=float, default=1e-3, help='学习率')
parser.add_argument('--weight-decay', type=float, default=0, help='权重衰减 L2正则化系数')
parser.add_argument('--num-workers', type=int, default=2, help='Dataset workers') # pytorch 线程batch size就是把数据分成几批的意思
机器学习中的batch_size是什么?_勤奋的大熊猫的博客-CSDN博客_batch size是什么意思
weight-decay就是正则化系数防止过拟合
【神经网络】权重衰减(weight-decay)_ZSYL的博客-CSDN博客_权重衰减
用于把矩形图像修改为正方形图像
# 抓取表示超参数
parser.add_argument('--output-size', type=int, default=360, help='output size')以下是设置的保存地址
# 保存地址
parser.add_argument('--outdir', type=str, default='output', help='Training Output Directory')
parser.add_argument('--modeldir', type=str, default='models', help='model保存地址')
parser.add_argument('--logdir', type=str, default='tensorboard', help='summary保存文件夹')
parser.add_argument('--imgdir', type=str, default='img', help='中间预测图保存文件夹')
parser.add_argument('--max_models', type=int, default=3, help='最大保存的模型数')tensorboard是可视化训练工具
注:因为每一个epoch都会有一个模型如果都保存的话就太大了
这里设置成只保存三个 最新的epoch的模型结果
![]()
这里选择跑的设备
# device
parser.add_argument('--device-name', type=str, default='cpu', choices=['cpu', 'cuda:0'], help='是否使用GPU')
# description![]() 这里改成用gpu跑
这里改成用gpu跑
这里是设置保存文件夹的名字
# description
parser.add_argument('--description', type=str, default='hx_test', help='Training description')这里是防止突发情况,可以选择之前的网络进行训练
# 从已有网络继续训练
parser.add_argument('--goon-train', type=bool, default=False, help='是否从已有网络继续训练')
parser.add_argument('--model', type=str, default='output/models/211128_1147_new/epoch_0145_acc_0.0000.pth', help='保存的模型')
parser.add_argument('--start-epoch', type=int, default=146, help='继续训练开始的epoch')
args = parser.parse_args()
return args比如说这里设置的是 从之前断开的epoch145加载开始训练,那么下一个就是epoch146
