python 爬虫及数据可视化展示
python 爬虫及数据可视化展示
学了有关python爬虫及数据可视化的知识,想着做一些总结,加强自己的学习成果,也能给各位小伙伴一些小小的启发。
1、做任何事情都要明确自己的目的,想要做什么,打算怎么做,做到什么样的程度,自己有一个清晰的定位,虽然计划永远赶不上变化,但是按计划走,见招拆招或许也是不错的选择。
2、本项目是爬取豆瓣的250部电影,将电影名,电影链接,评分等信息爬取保存到本地。将相关信息以列表的形式展示在网页上,访问者可通我的网站直接挑转到豆瓣查看电影,将评分制作评分走势图,将电影制作成词云图在网页上展示,共有五个网页,可相互跳转。
项目流程图:
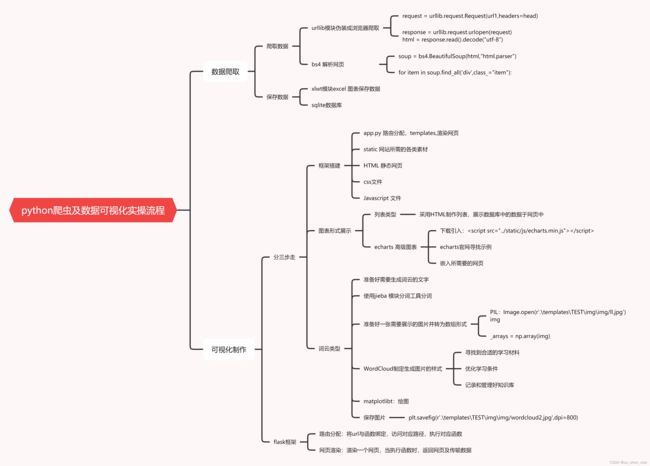
数据爬取:
# -*- codeing = utf-8 -*-
# @Time : 2022/1/11 22:39
# @Author : lj
# @File : spider.PY
# @Software: 4{PRODUCT_NAME}
import bs4 # 网页解析,获取数据 对网页的数据进行拆分
import re #正则表达式,进行文字匹配 对数据进行提炼
import urllib.request,urllib.error #指定url 获取网页数据 怕网页
import xlwt #进行excel 操作 存再excel中
import sqlite3 #进行sqllite 数据库操作 存在数据库中
import time
# 主函数
def main():
# 调用函数
url = "https://movie.douban.com/top250?start="
datalist1 = allData(url)
# savepath = "豆瓣电影top250.xls"
# savedata(datalist1,savepath)
dbpath = "move.db"
savedatasql(datalist1,dbpath)
#匹配所需内容的正则表达式
linkpattern = re.compile(r'')
#匹配图片的正则表达式
imagepattern = re.compile(r'![]() ',re.S)#re.S 忽略换行符,.表示除了换行符以外的所有字符
#匹配影名的正则表达式
namepattern = re.compile(r'(.*)')
# 影片评分
gradepattern = re.compile(r'')
# 评价人数
peoplepattern = re.compile(r'(d*)人评价')#(d*) 零个或多个
#概况
thinkpattern = re.compile(r'(.*)')
#影片的相关内容
contentpattern = re.compile(r'
',re.S)#re.S 忽略换行符,.表示除了换行符以外的所有字符
#匹配影名的正则表达式
namepattern = re.compile(r'(.*)')
# 影片评分
gradepattern = re.compile(r'')
# 评价人数
peoplepattern = re.compile(r'(d*)人评价')#(d*) 零个或多个
#概况
thinkpattern = re.compile(r'(.*)')
#影片的相关内容
contentpattern = re.compile(r'(.*?)
',re.S)#忽略换行符
#1、爬取一个网页
def getData(url1):
head = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0"}
request = urllib.request.Request(url1,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html #返回给调用的地方
# 2、爬取所有网页,匹配分析
def allData(url):
datalist = []
for i in range(0, 10): # 左闭右开 调用十次,每次二十五条信息
url1 = url + str(i * 25)
html = getData(url1) #保存获取到的网页源码
time.sleep(1)
# 逐页解析
soup = bs4.BeautifulSoup(html,"html.parser") #返回树型结构
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串,返回列表,class加下划线
data = []
item = str(item)
#link 获取到影片的超链接
link = re.findall(linkpattern,item)[0]
data.append(link)
# 影片图片
image = re.findall(imagepattern,item)[0]
data.append(image)
# 影片名
name = re.findall(namepattern,item)
if(len(name)==2):
chinaname = name[0]
data.append(chinaname)
outername = name[1].replace("/","")#.replace("/","") 列表内置的方法,将/替换为空""
data.append(outername)
else:
data.append(name[0])
data.append(' ')#外文名空出来
# 影片评分
grade = re.findall(gradepattern,item)[0]
data.append(grade)
# 影片评价人数
people = re.findall(peoplepattern, item)[0]
data.append(people)
# 影片概况
think = re.findall(thinkpattern, item)
if len(think) != 0:
think = think[0].replace("。","")
data.append(think)
else:
data.append(" ")
# 影片内容
content = re.findall(contentpattern, item)[0]
content = re.sub('数据库数据

excel数据

可视化制作
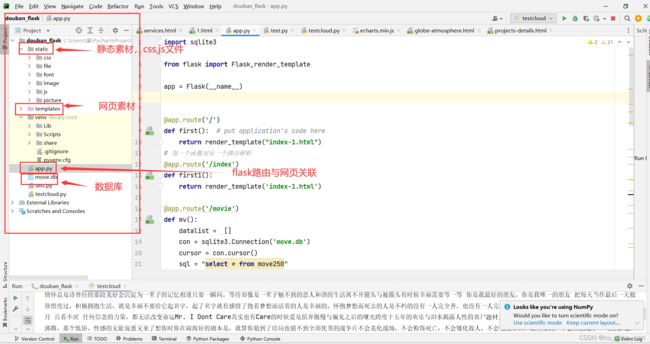
路由分配,网页渲染
import sqlite3
from flask import Flask,render_template
app = Flask(__name__)
@app.route('/')
def first(): # put application's code here
return render_template("index-1.html")
# 每一个函数对应一个路由解析
@app.route('/index')
def first1():
return render_template('index-1.html')
@app.route('/movie')
def mv():
datalist = []
con = sqlite3.Connection('move.db')
cursor = con.cursor()
sql = "select * from move250"
data = cursor.execute(sql)
for items in data:
datalist.append(items)
cursor.close()
con.close()
return render_template('about.html',mmm = datalist)
@app.route('/score')
def sc():
x = []
y = []
con = sqlite3.Connection('move.db')
cursor = con.cursor()
sql = "select grade,count(grade) from move250 group by grade"
data1 = cursor.execute(sql)
for ite in data1:
x.append(ite[0])
y.append(ite[1])
cursor.close()
con.close()
return render_template('services.html',score = x,number = y)
@app.route('/word')
def wd():
return render_template('projects-details.html')
@app.route('/team')
def te():
return render_template('team.html')
if __name__ == '__main__':
app.run()
网页源码,由于网页源码过多,只放一页
网页效果
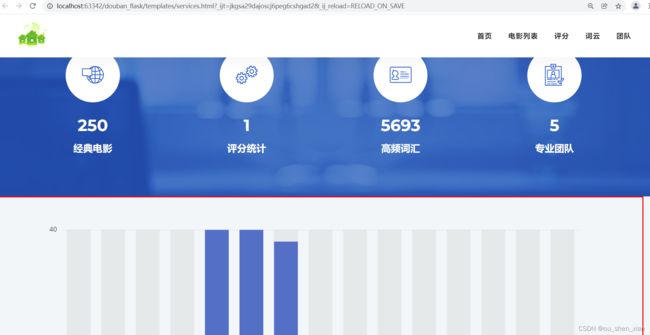
Buskey - Corporate Business Template
网页的免费模板很多,可以挑选自己喜欢的进行修改,并插入图表等。
词云图片制作,本项目采用电影的简介制作
# -*- codeing = utf-8 -*-
# @Time : 2022/2/2 12:53
# @Author : lj
# @File : testcloud.PY
# @Software: 4{PRODUCT_NAME}
import jieba
from matplotlib import pyplot as plt
from wordcloud import WordCloud
from PIL import Image
import numpy as np
import sqlite3
# 主要的流程,1.jieba提取文字,2.生成词云
#准备好数据
con = sqlite3.connect('move.db')
cur = con.cursor()
sql = 'select introduction from move250'
data = cur.execute(sql)
text = ""
for item in data:
text = text + item[0]
# print(text)
cur.close()
con.close()
#文本分词分句
cut = jieba.cut(text)
r = ' '.join(cut)
print(len(r))
# 处理图片的
img = Image.open(r'. emplatesTESTimgimg/ll.jpg')
img_arrays = np.array(img) #将图片转换为数组
#词云库封装一个对象
wc =WordCloud(
background_color='white', #输出图片的颜色
mask=img_arrays, #导入处理好的图片
font_path = 'STXINWEI.TTF' #字体的文件
)
#词云对象处理已经分好的词
wc.generate(r)
#绘制图片,plt matplotlib的库别名
fig = plt.figure(1) #matplotlib库figure方法可绘图
plt.imshow(wc) #按照wc的规则显示图片
plt.axis('off') #不显示x轴
# plt.show() #生成的词云图片
#输出词云图片到文件中,设置清晰度
plt.savefig(r'. emplatesTESTimgimg/wordcloud2.jpg',dpi=800)
词云图展示:
