pytorch函数详解
pytorch函数详解
在typora这里写之后复制到简书上
1. torchvision
1.1 transforms.Compose(transforms)
把几个转换组合

example:
from PIL import Image
t_tran = []
t_tran.append(transforms.Resize(image_size)) # 64
t_tran.append(transforms.CenterCrop(image_size))
img = Image.open(data_dir + '/img_align_celeba/000013.jpg')
for i, tran in enumerate(t_tran):
img = tran(img)
print(img.size)
plt.subplot(1, len(t_tran), i+1)
plt.imshow(img)
1.2 transforms.RandomResizedCrop
T.RandomResizedCrop(n)将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为制定的大小(即先随机采集,然后对裁剪得到的图像缩放为同一大小)
该操作的含义:即使只是该物体的一部分,我们也认为这是该l类物体
比如 猫的图片别裁剪缩放后,仍然认为这是一个猫。
参考:https://blog.csdn.net/qq_32425195/article/details/84998030
CLASStorchvision.transforms. RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=2)
Crop the given PIL Image to random size and aspect ratio.
A crop of random size (default: of 0.08 to 1.0) of the original size and a random aspect ratio (default: of 3/4 to 4/3) of the original aspect ratio is made. This crop is finally resized to given size. This is popularly used to train the Inception networks.
-
Parameters
size – expected output size of each edge
scale – range of size of the origin size cropped
ratio – range of aspect ratio of the origin aspect ratio cropped
interpolation – Default: PIL.Image.BILINEAR
1.3 transforms.ToTensor
Convert a PIL Image or numpy.ndarray to tensor.
如果是PIL Image或者ndarray,并且数值在[0, 255],则把形状转换成 (C x H x W) 并且数值从 [0, 255] 缩放到 [0.0, 1.0]。其它情况下仅仅把格式返回成tensor不进行缩放。
Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0] if the PIL Image belongs to one of the modes (L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1) or if the numpy.ndarray has dtype = np.uint8
In the other cases, tensors are returned without scaling.
1.4 transforms.Normalize
torchvision.transforms.``Normalize(mean, std, inplace=False)
标准化,使得到的数据变成均值为0,方差为1的分布(标准正态分布)。
Normalize a tensor image with mean and standard deviation. Given mean: (mean[1],...,mean[n]) and std: (std[1],..,std[n]) for n channels, this transform will normalize each channel of the input torch.*Tensor i.e., output[channel] = (input[channel] - mean[channel]) / std[channel]
example:
# 输入是BGR图像
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), # mean and std
Further Reading: Normalizing for neuron
深入理解Normalize
2. torch.nn
2.1 torch.nn.Conv2d()
CLASS
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’)
import torch
x = torch.randn(2,1,7,3)
conv = torch.nn.conv2d(1,8,(2,3))
res = conv(x)
print(res.shape) # shape = (2, 8, 6, 1)
输入
x
[ batch_size, channels, height_1, width_1 ]
batch_size 一个batch中样例的个数 2
channels 通道数,也就是当前层的深度 1
height_1, 图片的高 7
width_1, 图片的宽 3
————————————————
Conv2d的参数
[ in_channels, out_channels, (height_2, width_2) ]
channels, 通道数,和上面保持一致,也就是当前层的深度 1
output 输出的深度 8
height_2, 过滤器filter的高 2
width_2, 过滤器filter的宽 3
如果padding不是0,会在输入的每一边添加相应数目0
————————————————
输出:
res
[ batch_size,output, height_3, width_3 ]
batch_size, 一个batch中样例的个数,同上 2
output 输出的深度 8
height_3, 卷积结果的高度 6 = height_1 - height_2 + 1 = 7-2+1
width_3, 卷积结果的宽度 1 = width_1 - width_2 +1 = 3-3+1
如果使用padding,则height_3, width_3重新计算
H o u t = H i n + 2 × p a d d i n g [ 0 ] − d i l a t i o n [ 0 ] × ( k e r n e l s i z e [ 0 ] − 1 ) − 1 s t r i d e [ 0 ] + 1 H_{out} = \frac{H_{in} + 2\times padding[0] -dilation[0]\times (kernel_size[0]-1) -1 }{stride[0]} + 1 Hout=stride[0]Hin+2×padding[0]−dilation[0]×(kernelsize[0]−1)−1+1
W o u t = H i n + 2 × p a d d i n g [ 1 ] − d i l a t i o n [ 1 ] × ( k e r n e l s i z e [ 1 ] − 1 ) − 1 s t r i d e [ 1 ] + 1 W_{out} = \frac{H_{in} + 2\times padding[1] -dilation[1]\times (kernel_size[1]-1) -1 }{stride[1]} + 1 Wout=stride[1]Hin+2×padding[1]−dilation[1]×(kernelsize[1]−1)−1+1
————————————————
例子
>>> # With square kernels and equal stride
>>> m = nn.Conv2d(16, 33, 3, stride=2)
>>> # non-square kernels and unequal stride and with padding
>>> m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
>>> # non-square kernels and unequal stride and with padding and dilation
>>> m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
>>> input = torch.randn(20, 16, 50, 100)
>>> output = m(input)
2.2 torch.nn.MaxPool2d
CLASS torch.nn.MaxPool2d (kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
一般只写kernel_size,如果为2,则
H o u t = H i n / 2 H_{out} = H_{in}/2 Hout=Hin/2
2.3 nn.CrossEntropyLoss()
class torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction=‘elementwise_mean’)
loss ( x , class ) = − log ( exp ( x [ class ] ) ∑ j exp ( x [ j ] ) ) = − x [ class ] + log ( ∑ j exp ( x [ j ] ) ) \operatorname{loss}(x, \text { class })=-\log \left(\frac{\exp (x[\text { class }])}{\sum_{j} \exp (x[j])}\right)=-x[\text { class }]+\log \left(\sum_{j} \exp (x[j])\right) loss(x, class )=−log(∑jexp(x[j])exp(x[ class ]))=−x[ class ]+log(j∑exp(x[j]))
softmax + 交叉熵损失,等价于nn.logSoftmax()和nn.NLLLoss()的整合。一般来说loss_func(output, target) 中output是神经网络输出向量,target是目标分类(标量)。
理解: 交叉熵损失,x[class] 占比例越大损失越小,想象 y=-log(x) 函数图像,越接近1越小。
https://blog.csdn.net/geter_CS/article/details/84857220?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
2.4 nn.BCELoss and nn.BCEWithLogitsLoss
CLASS torch.nn. BCELoss (weight=None, size_average=None, reduce=None, reduction=‘mean’)
这是一个二分类问题,目标是[0, 1]。首先给出公式,如果reduction = none, 实例化nn.BCELoss后为criterion,那么对于criterion(x, y):
ℓ ( x , y ) = L = { l 1 , … , l N } ⊤ , l n = − [ y n ⋅ log x n + ( 1 − y n ) ⋅ log ( 1 − x n ) ] \ell(x, y) = L = \{l_1,\dots,l_N\}^\top, \quad l_n = - \left[ y_n \cdot \log x_n + (1 - y_n) \cdot \log (1 - x_n) \right] ℓ(x,y)=L={l1,…,lN}⊤,ln=−[yn⋅logxn+(1−yn)⋅log(1−xn)]
其中N为batch size,一般loss都是一个标量嘛,所以就设置reduction:
ℓ ( x , y ) = { mean ( L ) , if reduction = ′ mean’ sum ( L ) , if reduction = ′ sum ′ \ell(x, y)=\left\{\begin{array}{ll} \operatorname{mean}(L), & \text { if reduction }=' \text { mean' } \\ \operatorname{sum}(L), & \text { if reduction }=' \operatorname{sum}^{\prime} \end{array}\right. ℓ(x,y)={mean(L),sum(L), if reduction =′ mean’ if reduction =′sum′
- 我们观察上式,x必须都在(0, 1)范围,所以计算loss之前必须要先用Sigmoid函数给这些值都搞到0~1之间(logit)。
m = nn.Sigmoid()
所以就有了nn.BCEWithLogitsLoss,把Sigmoid-BCELoss合成一步。(看来这就是定义神经网络时每一层后面加一个sigmiod,原来是为了把数值变到(0, 1)之间)
csdn
https://pytorch.org/docs/stable/nn.html#torch.nn.BCELoss
2.5 nn.Linear
线性层 ax + b
2.6 激活函数
- nn.ReLU()
nn.ReLU(inplace=False)
ReLU ( x ) = ( x ) + = max ( 0 , x ) \text{ReLU}(x) = (x)^+ = \max(0, x) ReLU(x)=(x)+=max(0,x)
inplace=True可以节省内存。
relu: rectifified linear function.
AlexNet第一次使用,非线性激活函数ReLU(如果不是很了解激活函数,可以参考我的另一篇博客 激活函数Activation Function(https://blog.csdn.net/weixin_42111770/article/details/81186441),并验证其效果在较深的网络超过Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。 该函数可以解决当x增大时影响变小的问题。
2.7 torch.nn.Embedding 词嵌入
def __init__(self,
num_embeddings: int,
embedding_dim: int,
padding_idx: Optional[int] = ...,
max_norm: Optional[float] = ...,
norm_type: float = ...,
scale_grad_by_freq: bool = ...,
sparse: bool = ...,
_weight: Optional[Tensor] = ...) -> None
就是初始化一个词嵌入矩阵, nn.Embedding(10, 5) 代表把10个词用5维向量代表。
归一化层
torch.nn.(BatchNorm、LayerNorm、InstanceNorm、GroupNorm)
(42条消息) PyTorch学习之归一化层(BatchNorm、LayerNorm、InstanceNorm、GroupNorm)_mingo_敏-CSDN博客
BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm总结_I am what i am-CSDN博客
BN,LN,IN,GN从学术化上解释差异:
BatchNorm:batch方向做归一化,算NHW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布
LayerNorm:channel方向做归一化,算CHW的均值,主要对RNN作用明显;
InstanceNorm:一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束。
SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
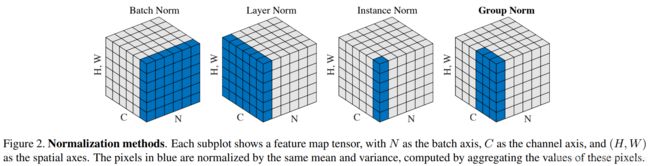
BatchNorm
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
torch.nn.BatchNorm3d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
参数:
num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum: 动态均值和动态方差所使用的动量。默认为0.1。
affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
LayerNorm
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True)
参数:
normalized_shape: 输入尺寸
[∗×normalized_shape[0]×normalized_shape[1]×…×normalized_shape[−1]]
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
elementwise_affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
3 torch.nn.functional
3.1 torch.nn.functional.relu
Applies the rectified linear unit function element-wise:
R e L U ( x ) = m a x ( 0 , x ) ReLU(x)=max(0,x) ReLU(x)=max(0,x)
3.2 torch.nn.functional.max_pool2d(*args, **kwargs)
Applies a 2D max pooling over an input signal composed of several input planes.
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
max_pool2d(x, 2, 2) 就是H, W都除以2
4. Tensor方法
-
view(*shape) → TensorReturns a new tensor with the same data as the
selftensor but of a differentshape.形状转换
# 比如MNIST数据集,(batch_size, 28, 28) -> (batch_size, 28*28)
x.view(x.shape[0], -1)
expand
expand(*sizes)
返回tensor的一个新视图,单个维度扩大为更大的尺寸。 tensor也可以扩大为更高维,新增加的维度将附在前面。 扩大tensor不需要分配新内存,只是仅仅新建一个tensor的视图,其中通过将stride设为0,一维将会扩展位更高维。任何一个一维的在不分配新内存情况下可扩展为任意的数值。
>>> x = torch.Tensor([[1], [2], [3]])
>>> x.size()
torch.Size([3, 1])
>>> x.expand(3, 4)
1 1
1 1
2 2 2 2
3 3 3 3
[torch.FloatTensor of size 3x4]
expand_as(other) # 将 tensor 扩展为参数 other 的大小。该操作等效于: self.expand(tensor.size())
masked_fill_(mask, value)
在mask值为1的位置处用value填充。mask的元素个数需和本tensor相同,但尺寸可以不同。
Fills elements of self tensor with value where mask is True. The shape of mask must be broadcastable with the shape of the underlying tensor.
5. torch
5.1 torch.max
torch.max(input, dim, keepdim=False, out=None) -> (Tensor, LongTensor)
Returns a namedtuple (values, indices) where values is the maximum value of each row of the input tensor in the given dimension dim. And indices is the index location of each maximum value found (argmax).
example
>>> a = torch.randn(4, 4)
>>> a
tensor([[-1.2360, -0.2942, -0.1222, 0.8475],
[ 1.1949, -1.1127, -2.2379, -0.6702],
[ 1.5717, -0.9207, 0.1297, -1.8768],
[-0.6172, 1.0036, -0.6060, -0.2432]])
>>> torch.max(a, 1)
torch.return_types.max(values=tensor([0.8475, 1.1949, 1.5717, 1.0036]), indices=tensor([3, 0, 0, 1]))
5.2 in-place
in-place operation 在 pytorch中是指改变一个tensor的值的时候,不经过复制操作,而是在运来的内存上改变它的值。可以把它称为原地操作符。
在pytorch中经常加后缀 “_” 来代表原地in-place operation, 比如 .add_() 或者.scatter()
python 中里面的 += *= 也是in-place operation。
下面是正常的加操作,执行结束加操作之后x的值没有发生变化:
import torch
x=torch.rand(2) #tensor([0.8284, 0.5539])
print(x)
y=torch.rand(2)
print(x+y) #tensor([1.0250, 0.7891])
print(x) #tensor([0.8284, 0.5539])
下面是原地操作,执行之后改变了原来变量的值:
import torch
x=torch.rand(2) #tensor([0.8284, 0.5539])
print(x)
y=torch.rand(2)
x.add_(y)
print(x) #tensor([1.1610, 1.3789])
5.3 torch.stack
torch.stack((Tensor), dim)
拼接张量,dim 是在哪一维拼接,Tensor 的shape必须是一样的
a = torch.IntTensor([[1,2,3],[11,22,33]])
b= torch.IntTensor([[4,5,6],[44,55,66]])
c=torch.stack([a,b],0)
d=torch.stack([a,b],1)
e=torch.stack([a,b],2)
print(c)
print(d)
print(e)
>>> print(c)
tensor([[[ 1, 2, 3],
[11, 22, 33]],
[[ 4, 5, 6],
[44, 55, 66]]], dtype=torch.int32)
>>> print(d)
tensor([[[ 1, 2, 3],
[ 4, 5, 6]],
[[11, 22, 33],
[44, 55, 66]]], dtype=torch.int32)
>>> print(e)
tensor([[[ 1, 4],
[ 2, 5],
[ 3, 6]],
[[11, 44],
[22, 55],
[33, 66]]], dtype=torch.int32)
torch.squeeze / unsqueeze
torch.squeeze(input, dim=None, out=None) → Tensor
除去输入张量input中数值为1的维度,并返回新的张量。如果输入张量的形状为(A×1×B×C×1×D),那么输出张量的形状为(A×B×C×D)。
当通过dim参数指定维度时,维度压缩操作只会在指定的维度上进行。如果输入向量的形状为(A×1×B),squeeze(input, 0)会保持张量的维度不变,只有在执行 squeeze(input, 1)时,输入张量的形状会被压缩至(A×B)。
如果一个张量只有1个维度,那么它不会受到上述方法的影响。
输出的张量与原张量共享内存,如果改变其中的一个,另一个也会改变。
https://www.cnblogs.com/jiangkejie/p/10683531.html
6. torchtext
6.1 get_tokenizer
如果使用 ‘spacy’ 导入,需要下载对应的分词器。
! python -m spacy download en
! python -m spacy download de
! python -m spacy download de_core_news_sm
from torchtext.data.utils import get_tokenizer
de_tokenizer = get_tokenizer('spacy', language='de')
en_tokenizer = get_tokenizer('spacy', language='en')
一些torch的坑
6.1 tensor除法
先看一段代码
a = torch.tensor(3)
b = 2
c = a / b
e = 3
print(c, e / b)
"""
tensor(1) 1.5
"""
如果是tensor和一个整数相除,结果为除数(整数),如果想得到小数,有下面几种方法:
- 使用
.item取出数。 - 把整数变成2.0,也就是把除数变成float。
a = torch.tensor(3)
b = 2
c = a / 2.0
e = a / float(b)
print(c, e)
参考:
torch.nn.Conv2d
torch.nn.MaxPool2d
6.2 pytorch Kfold数据集划分
今天想使用K折方法进行训练,发现 pytorch dataloader 中没有需要的一键操作的代码,我自己写了一个。
首先得到数据量,然后使用 sklearn.model_selection 的 KFold 方法划分数据索引,最后使用 torch.utils.data.dataset.Subset 方法得到划分后的子数据集。代码思路如下。
import torch
from sklearn.model_selection import KFold
data_induce = np.arange(0, data_loader_old.dataset.length)
kf = KFold(n_splits=5)
for train_index, val_index in kf.split(data_induce):
train_subset = torch.utils.data.dataset.Subset(Dataset(params), train_index)
val_subset = torch.utils.data.dataset.Subset(Dataset(params), val_index)
data_loaders['train'] = torch.utils.data.DataLoader(train_subset, ...)
data_loaders['val'] = data.pair_provider_subset(val_subset, ...)
参考:https://scikit-learn.org/stable/modules/cross_validation.html
https://stackoverflow.com/questions/60883696/k-fold-cross-validation-using-dataloaders-in-pytorch
pytorch 小方法
1.获取网络任意一层输出
有两种比较有效的方法:
- 重写一个 model (不推荐)
- 通过hook的方式。
- 通过列表索引的方式直接选择。(想要获得提取的特征等)
https://blog.csdn.net/Hungryof/article/details/80921417
2. 分布式gpu
两种方法,第一是 nn.DataParallel 使用简单,第二是 torch.distributed,推荐使用第二个。
注意:
- 自己定义的模型属性方法,并行化后无法使用,torch.distributed 使用 model = model.module 即可解决,但是 nn.DataParallel 使用之后就会变成非并行。
- os.environ[‘CUDA_VISIBLE_DEVICES’] = ‘2,3’ 需要放到第一次使用 torch 之前,否则不会起作用。
- torch.distributed 使用比较麻烦,还需要修改 dataloader 的 sampler 属性。此时 shuffle 必须为 False。可以在 DistributedSampler 中修改 shuffle 为 True.
nn…DataParallel 使用代码
# -*- encoding: utf-8 -*-
import torch
import torch.nn as nn
import os
import math
import sys
os.environ['CUDA_VISIBLE_DEVICES'] = '2,3'
class TransformNet(nn.Module):
"""
加入 BatchNorm, activation, dropout
"""
def __init__(self):
super().__init__()
self.iters = 0
self.a = torch.nn.Sequential(
torch.nn.Linear(3, 1),
torch.nn.Flatten(0, 1)
)
def forward(self, input_x):
self.iters = 1 + self.iters
return self.a(input_x)
def train(self, input_x):
return self.forward(input_x)
model = TransformNet()
def data_parallel(model):
global device
device = torch.device("cuda")
model = nn.DataParallel(model)
model = model.to(device)
model = model.module
print(model.iters)
return model
model = data_parallel(model)
x = torch.linspace(-math.pi, math.pi, 2000).to(device)
y = torch.sin(x).to(device)
p = torch.tensor([1, 2, 3]).to(device)
xx = x.unsqueeze(-1).pow(p).to(device)
loss_fn = torch.nn.MSELoss(reduction='sum')
learning_rate = 1e-6
for t in range(20000):
print('model iter:', model.iters)
# Forward pass: compute predicted y by passing x to the model. Module objects
# override the __call__ operator so you can call them like functions. When
# doing so you pass a Tensor of input data to the Module and it produces
# a Tensor of output data.
y_pred = model.train(xx)
# Compute and print loss. We pass Tensors containing the predicted and true
# values of y, and the loss function returns a Tensor containing the
# loss.
loss = loss_fn(y_pred, y)
if t % 100 == 99:
print(t, loss.item())
# Zero the gradients before running the backward pass.
model.zero_grad()
# Backward pass: compute gradient of the loss with respect to all the learnable
# parameters of the model. Internally, the parameters of each Module are stored
# in Tensors with requires_grad=True, so this call will compute gradients for
# all learnable parameters in the model.
loss.backward()
# Update the weights using gradient descent. Each parameter is a Tensor, so
# we can access its gradients like we did before.
with torch.no_grad():
for param in model.parameters():
param -= learning_rate * param.grad
torch.distributed 使用代码
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import os
from torch.utils.data.distributed import DistributedSampler
input_size = 5
output_size = 2
batch_size = 30
data_size = 90
# 1) 初始化
torch.distributed.init_process_group(backend='nccl')
# 2) 配置每个进程的gpu
local_rank = torch.distributed.get_rank()
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
model.to(device)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)
model = model.module
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size).to('cuda')
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
dataset = RandomDataset(input_size, data_size)
# 3)使用DistributedSampler
rand_loader = DataLoader(dataset=dataset,
batch_size=batch_size,
sampler=DistributedSampler(dataset))
class Model(nn.Module):
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print(" In Model: input size", input.size(),
"output size", output.size())
return output
model = Model(input_size, output_size)
# 4) 封装之前要把模型移到对应的gpu
model.to(device)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# 5) 封装
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[local_rank],
output_device=local_rank)
for data in rand_loader:
if torch.cuda.is_available():
input_var = data
else:
input_var = data
output = model(input_var)
print("Outside: input size", input_var.size(), "output_size", output.size())
https://zhuanlan.zhihu.com/p/74792767
https://blog.csdn.net/weixin_38739735/article/details/110944658
https://blog.csdn.net/xiezongsheng1990/article/details/108713405
3. 获取一个 tensor 矩阵的描述性统计
# 注意需要 pandas > 1.0
import pandas as pd
df = pd.DataFrame(np.array(score.detach().cpu().numpy()), dtype=float)
dfd = df.describe()
print('min', dfd.min(axis=1))
print('max', dfd.max(axis=1))
4. 模型设置层的名字,通过字典访问模型
主要是使用 self.add_module 方法。
class VisTransformNetList(nn.Module):
def __init__(self, opt, space_dict: dict):
super().__init__()
self.vis_net_space_dict = space_dict
for each in space_dict.keys():
self.add_module(each, TransformNet((opt.vis_fc_layers[0], space_dict[each]), opt))
def forward(self, vis_input):
out_features = {}
module_dict = dict(self.named_modules())
for name in self.vis_net_space_dict.keys():
out_features[name] = module_dict[name](vis_input)
return out_features
保存模型常量
state_dict() 只能保存 nn.Mudule 这种模型,如果想保存常量的话,可以
- 重写 state_dict()
- 用 nn.Linear(1, 1, False) 来保存
我说一下第二种方法。
class Attention_1(nn.Module):
def __init__(self):
self.global_emb_weight_net = nn.Linear(1, 1, False) # 存储 raw_global_emb 的权重
self.change_raw_global_emb_weight(1)
def get_raw_global_emb_weight(self):
return self.global_emb_weight_net.weight.item()
def change_raw_global_emb_weight(self, new_value: float):
self.global_emb_weight_net.weight.data.fill_(new_value)
对外提供 get_raw_global_emb_weight 和 change_raw_global_emb_weight 两种方法,对常量进行操作。