【计量经济学】时间序列分析笔记(上)
时间序列复习
密码 2022年6月11日-6月13日
额外的参考资料:北大金融时间序列的备课笔记
文章目录
- 时间序列复习
- Chapter 2 Difference Equations and Their Solutions
-
-
- 通解的描述
- 差分方程的求解过程
- lag operators
- 特征方程
- stability conditions
-
- Chapter 3 Univariate Time Series
-
- 介绍MA(q), AR(p), ARMA(p,q)
-
- white noise
- stationarity
- MA(q) models
- AR(p) models
- ARMA(p,q) models
- ACF
- Yule-Walker equations
- partial autocorrelation function(PACF)
- ARMA(p,q)阶数的识别
-
- t test
- Joint Test (Ljung-Box Q-statistics)
- Criteria: AIC, BIC
- Box-Jenkins Approach
-
- 极大似然估计?
- 预测
-
- test whether a forecast is accurate or not
- Diebold-Mariano Test
- time series with trend
- 周期性或季节性ARMA model
- Chapter 4 Modeling Volatility
-
-
- ARCH(q) 自回归条件异方差
- ϵ t 2 \epsilon_t^2 ϵt2
- Heavy tails
- G A R C H ( p , q ) G A R C H(p, q) GARCH(p,q) model :
-
- Identification of A R C H \mathrm{ARCH} ARCH and GARCH Models
- Testing for ARCH Effects
- Estimation of ARCH/GARCH Models
- Model Checking
-
- heavy tail 是用来干啥的以及以上
- Forecasting Variances using ARCH Models
-
- Interval Forecasting
- real data example 考吗?
-
Chapter 2 Difference Equations and Their Solutions
通解的描述
This solution y t = A ϕ 1 t y_{t}=A \phi_{1}^{t} yt=Aϕ1t to the homogeneous equation is called the homogeneous solution.
- If ∣ ϕ 1 ∣ < 1 \left|\phi_{1}\right|<1 ∣ϕ1∣<1, ==the homogeneous solution converges to zero as t → ∞ t \rightarrow \infty t→∞.==Convergence is direct if 0 < ϕ 1 < 1 0<\phi_{1}<1 0<ϕ1<1 and oscillatory if − 1 < ϕ 1 < 0 -1<\phi_{1}<0 −1<ϕ1<0
- If ∣ ϕ 1 ∣ > 1 \left|\phi_{1}\right|>1 ∣ϕ1∣>1, the homogeneous solution is divergent. If ϕ 1 > 1 \phi_{1}>1 ϕ1>1, the solution approaches ∞ \infty ∞ as t t t increases. If ϕ 1 < − 1 \phi_{1}<-1 ϕ1<−1, the solution oscillates explosively.
- If ϕ 1 = 1 \phi_{1}=1 ϕ1=1, any arbitrary constant A A A satisfies the homogeneous equation and y t = y t − 1 y_{t}=y_{t-1} yt=yt−1. If ϕ 1 = − 1 , y t = A \phi_{1}=-1, y_{t}=A ϕ1=−1,yt=A for even values of t t t and y t = − A y_{t}=-A yt=−A for odd values of t t t, and y t = − y t − 1 y_{t}=-y_{t-1} yt=−yt−1.
odd:奇数 even: 偶数
差分方程的求解过程
- 找到齐次方程并求解
- 找到特解
- 得到通解
- 代入初始条件,得到一些常数参数的取值(如果有的话)
lag operators
For ∣ a ∣ < 1 |a|<1 ∣a∣<1, the infinite sum
( 1 + a L + a 2 L 2 + a 3 L 3 + ⋯ ) y t = y t 1 − a L \left(1+a L+a^{2} L^{2}+a^{3} L^{3}+\cdots\right) y_{t}=\frac{y_{t}}{1-a L} (1+aL+a2L2+a3L3+⋯)yt=1−aLyt
可以通过等比数列的求和公式得到
可以使用lag来求解差分方程
It is straightforward to use lag operators to solve linear difference equations. If ∣ ϕ 1 ∣ < 1 \left|\phi_{1}\right|<1 ∣ϕ1∣<1, we obtain
y t = ( 1 − ϕ 1 L ) − 1 ( ϕ 0 + x t ) = ( 1 + ϕ 1 L + ϕ 1 2 L 2 + ⋯ ) ( ϕ 0 + x t ) = ϕ 0 1 − ϕ 1 + ∑ j = 0 ∞ ϕ 1 j x t − j \begin{aligned} y_{t} &=\left(1-\phi_{1} L\right)^{-1}\left(\phi_{0}+x_{t}\right)=\left(1+\phi_{1} L+\phi_{1}^{2} L^{2}+\cdots\right)\left(\phi_{0}+x_{t}\right) \\ &=\frac{\phi_{0}}{1-\phi_{1}}+\sum_{j=0}^{\infty} \phi_{1}^{j} x_{t-j} \end{aligned} yt=(1−ϕ1L)−1(ϕ0+xt)=(1+ϕ1L+ϕ12L2+⋯)(ϕ0+xt)=1−ϕ1ϕ0+j=0∑∞ϕ1jxt−j
特征方程
characteristic equation and inverse characteristic equation
求解
A α t = ϕ 1 A α t − 1 + ϕ 2 A α t − 2 ⇒ α 2 − ϕ 1 α − ϕ 2 = 0 ⏟ characteristic equation A \alpha^{t}=\phi_{1} A \alpha^{t-1}+\phi_{2} A \alpha^{t-2} \Rightarrow \underbrace{\alpha^{2}-\phi_{1} \alpha-\phi_{2}=0}_{\text {characteristic equation }} Aαt=ϕ1Aαt−1+ϕ2Aαt−2⇒characteristic equation α2−ϕ1α−ϕ2=0
Case 1: If ϕ 1 2 + 4 ϕ 2 > 0 , α 1 , α 2 = ϕ 1 ± ϕ 1 2 + 4 ϕ 2 2 \phi_{1}^{2}+4 \phi_{2}>0, \alpha_{1}, \alpha_{2}=\frac{\phi_{1} \pm \sqrt{\phi_{1}^{2}+4 \phi_{2}}}{2} ϕ12+4ϕ2>0,α1,α2=2ϕ1±ϕ12+4ϕ2
y t = A 1 α 1 t + A 2 α 2 t y_{t}=A_{1} \alpha_{1}^{t}+A_{2} \alpha_{2}^{t} yt=A1α1t+A2α2t
Case 2: If ϕ 1 2 + 4 ϕ 2 = 0 , α 1 = α 2 = ϕ 1 2 \phi_{1}^{2}+4 \phi_{2}=0, \alpha_{1}=\alpha_{2}=\frac{\phi_{1}}{2} ϕ12+4ϕ2=0,α1=α2=2ϕ1
y t = A 1 ( ϕ 1 2 ) t + A 2 t ( ϕ 1 2 ) t y_{t}=A_{1}\left(\frac{\phi_{1}}{2}\right)^{t}+A_{2} t\left(\frac{\phi_{1}}{2}\right)^{t} yt=A1(2ϕ1)t+A2t(2ϕ1)t
Case 3: If ϕ 1 2 + 4 ϕ 2 < 0 , α 1 , α 2 = ϕ 1 ± i − ϕ 1 2 − 4 ϕ 2 2 \phi_{1}^{2}+4 \phi_{2}<0, \alpha_{1}, \alpha_{2}=\frac{\phi_{1} \pm i \sqrt{-\phi_{1}^{2}-4 \phi_{2}}}{2} ϕ12+4ϕ2<0,α1,α2=2ϕ1±i−ϕ12−4ϕ2.
α 1 = ϕ 1 + i − ϕ 1 2 − 4 ϕ 2 2 = r ( cos θ + i sin θ ) α 2 = ϕ 1 − i − ϕ 1 2 − 4 ϕ 2 2 = r ( cos θ − i sin θ ) \begin{aligned} &\alpha_{1}=\frac{\phi_{1}+i \sqrt{-\phi_{1}^{2}-4 \phi_{2}}}{2}=r(\cos \theta+i \sin \theta) \\ &\alpha_{2}=\frac{\phi_{1}-i \sqrt{-\phi_{1}^{2}-4 \phi_{2}}}{2}=r(\cos \theta-i \sin \theta) \end{aligned} α1=2ϕ1+i−ϕ12−4ϕ2=r(cosθ+isinθ)α2=2ϕ1−i−ϕ12−4ϕ2=r(cosθ−isinθ)
where r = − ϕ 2 r=\sqrt{-\phi_{2}} r=−ϕ2 is the modulus of α 1 \alpha_{1} α1 and α 2 \alpha_{2} α2,
and θ = arccos ( ϕ 1 2 − ϕ 2 ) \theta=\arccos \left(\frac{\phi_{1}}{2 \sqrt{-\phi_{2}}}\right) θ=arccos(2−ϕ2ϕ1) is the argument of α 1 \alpha_{1} α1 and α 2 \alpha_{2} α2.
y t = A 1 α 1 t + A 2 α 2 t ≡ B 1 r t cos ( θ t + B 2 ) y_{t}=A_{1} \alpha_{1}^{t}+A_{2} \alpha_{2}^{t} \equiv B_{1} r^{t} \cos \left(\theta t+B_{2}\right) yt=A1α1t+A2α2t≡B1rtcos(θt+B2)
stability conditions
Stability requires that all characteristic roots (defined in Eq. (10)) lie within the unit circle, i.e. ∣ α j ∣ < 1 \left|\alpha_{j}\right|<1 ∣αj∣<1 for all j j j.
- a necessary condition for stability : ∑ j = 1 p ϕ j < 1 \sum_{j=1}^{p} \phi_{j}<1 ∑j=1pϕj<1.
- a sufficient condition for stability : ∑ j = 1 p ∣ ϕ j ∣ < 1 \sum_{j=1}^{p}\left|\phi_{j}\right|<1 ∑j=1p∣ϕj∣<1.
- At least one characteristic root equals unity if
∑ j = 1 p ϕ j = 1 \sum_{j=1}^{p} \phi_{j}=1 j=1∑pϕj=1

Chapter 3 Univariate Time Series
介绍MA(q), AR§, ARMA(p,q)
white noise
{ ϵ t } \left\{\epsilon_{t}\right\} {ϵt} is called a white noise process if for all t t t
E ( ϵ t ) = 0 mean zero E ( ϵ t 2 ) = var ( ϵ t ) = σ 2 variance σ 2 E ( ϵ t ϵ τ ) = cov ( ϵ t , ϵ τ ) = 0 , for all τ ≠ t uncorrelated across time \begin{aligned} E\left(\epsilon_{t}\right) &=0 \quad \text { mean zero } \\ E\left(\epsilon_{t}^{2}\right) &=\operatorname{var}\left(\epsilon_{t}\right)=\sigma^{2} \quad \text { variance } \sigma^{2} \\ E\left(\epsilon_{t} \epsilon_{\tau}\right) &=\operatorname{cov}\left(\epsilon_{t}, \epsilon_{\tau}\right)=0, \text { for all } \tau \neq t \quad \text { uncorrelated across time } \end{aligned} E(ϵt)E(ϵt2)E(ϵtϵτ)=0 mean zero =var(ϵt)=σ2 variance σ2=cov(ϵt,ϵτ)=0, for all τ=t uncorrelated across time
If in addition, { ϵ t } \left\{\epsilon_{t}\right\} {ϵt} is independent across time, then it is called an independent white noise process.
If furthermore, ϵ t ∼ N ( 0 , σ 2 ) \epsilon_{t} \sim N\left(0, \sigma^{2}\right) ϵt∼N(0,σ2), then we have the Gaussian white noise process.
stationarity
Strict or strong stationarity :
- distributions are time-invariant. This is a very strong condition that is hard to verify empirically.
- 均值和方差不一定有限
Weak stationarity( covariance stationary) :
- first 2 moments are time-invariant. In this course, we are mainly concerned with weakly stationary series.
A stochastic process { y t } \left\{y_{t}\right\} {yt} having a finite mean and variance is covariance stationary (weakly stationary) if
(1) Mean (or expectation) is the same for each period:
E ( y t ) = μ for all t E\left(y_{t}\right)=\mu \text { for all } t E(yt)=μ for all t
(2) Variance (variability) is the same for each period:
var ( y t ) = E [ ( y t − μ ) 2 ] = σ y 2 for all t \operatorname{var}\left(y_{t}\right)=E\left[\left(y_{t}-\mu\right)^{2}\right]=\sigma_{y}^{2} \text { for all } t var(yt)=E[(yt−μ)2]=σy2 for all t
(3) Lag-k autocovariance :
γ k = cov ( y t , y t − k ) = E [ ( y t − μ ) ( y t − k − μ ) ] f o r a l l t a n d a n y k \gamma_{k}=\operatorname{cov}\left(y_{t}, y_{t-k}\right)=E\left[\left(y_{t}-\mu\right)\left(y_{t-k}-\mu\right)\right]~~ for ~all~ t ~and ~any~k γk=cov(yt,yt−k)=E[(yt−μ)(yt−k−μ)] for all t and any k
与t无关,都是常数
Lag-k autocorrelation (or serial correlation)
ρ k ≡ cov ( y t , y t − k ) var ( y t ) = γ k γ 0 \rho_{k} \equiv \frac{\operatorname{cov}\left(y_{t}, y_{t-k}\right)}{\operatorname{var}\left(y_{t}\right)}=\frac{\gamma_{k}}{\gamma_{0}} ρk≡var(yt)cov(yt,yt−k)=γ0γk
在多元模型行中,自协方差是指 y t y_t yt和其滞后项之间的协方差,而协方差是指一个序列和另一个序列之间的协方差。在一元时间序列模型中不会产生歧义。
MA(q) models
x t = μ + ∑ j = 0 q β j ϵ t − j M A ( q ) m o d e l s x_{t}=\mu+\sum_{j=0}^{q} \beta_{j} \epsilon_{t-j}\qquad M A(q)~ models xt=μ+j=0∑qβjϵt−jMA(q) models
β 0 \beta_{0} β0 is always set to be unity for normalization.
使用stationarity的定义可以得到MA(q)是stationarity的
绝对值求和收敛那么平方和也收敛
AR§ models
y t = ϕ 0 + ∑ j = 1 p ϕ j y t − j + ϵ t , A R ( p ) model. y_{t}=\phi_{0}+\sum_{j=1}^{p} \phi_{j} y_{t-j}+\epsilon_{t}, \quad \mathrm{AR}(\mathrm{p}) \text { model. } yt=ϕ0+j=1∑pϕjyt−j+ϵt,AR(p) model.
Without initial conditions, the general solution to Eq.(6) is:
y t = A ϕ 1 t + ϕ 0 1 − ϕ 1 + ∑ j = 0 ∞ ϕ 1 j ϵ t − j , if ∣ ϕ 1 ∣ < 1. y_{t}=A \phi_{1}^{t}+\frac{\phi_{0}}{1-\phi_{1}}+\sum_{j=0}^{\infty} \phi_{1}^{j} \epsilon_{t-j}, \quad \text { if }\left|\phi_{1}\right|<1 . yt=Aϕ1t+1−ϕ1ϕ0+j=0∑∞ϕ1jϵt−j, if ∣ϕ1∣<1.
- The characteristic root ϕ 1 \phi_{1} ϕ1 must be less than unity in absolute value.
- The homogeneous solution A ϕ 1 t A \phi_{1}^{t} Aϕ1t must be zero. Either the sequence must have started infinitely far in the past (so that ϕ 1 t ≈ 0 \phi_{1}^{t} \approx 0 ϕ1t≈0 ) or the process must always be in equilibrium (so that A = 0 ) A=0) A=0)
或者
Stationarity conditions for AR§ processes
- ∣ α j ∣ < 1 \left|\alpha_{j}\right|<1 ∣αj∣<1 for all j = 1 , ⋯ , p j=1, \cdots, p j=1,⋯,p.
- The homogeneous solution must be zero. Either the sequence must have started infinitely far in the past or the process must always be in equilibrium (so that the arbitrary constants are zero).
ARMA(p,q) models
y t = ϕ 0 + ∑ j = 1 p ϕ j y t − j + ∑ j = 0 q β j ϵ t − j , ARMA ( p , q ) model. y_{t}=\phi_{0}+\sum_{j=1}^{p} \phi_{j} y_{t-j}+\sum_{j=0}^{q} \beta_{j} \epsilon_{t-j}, \quad \operatorname{ARMA}(\mathrm{p}, \mathrm{q}) \text { model. } yt=ϕ0+j=1∑pϕjyt−j+j=0∑qβjϵt−j,ARMA(p,q) model.
特解:
y t = c + ∑ j = 0 ∞ c j ϵ t − j y_{t}=c+\sum_{j=0}^{\infty} c_{j} \epsilon_{t-j} yt=c+j=0∑∞cjϵt−j
特解+齐次方程的通解即可得到ARMA(p,q)的解
ACF
-
The plot of== γ k \gamma_{k} γk==against k k k is called the autocovariance function.
-
ACF: The plot of== ρ k \rho_{k} ρk== against k k k is called the autocorrelation function (ACF) or correlogram.
ρ k ≡ cov ( y t , y t − k ) var ( y t ) = γ k γ 0 \rho_{k} \equiv \frac{\operatorname{cov}\left(y_{t}, y_{t-k}\right)}{\operatorname{var}\left(y_{t}\right)}=\frac{\gamma_{k}}{\gamma_{0}} ρk≡var(yt)cov(yt,yt−k)=γ0γk
Yule-Walker equations
用于分析ACF
The first p p p Yule-Walker equations determine the initial conditions.
- The key point is that { γ k } \left\{\gamma_{k}\right\} {γk} and { ρ k } \left\{\rho_{k}\right\} {ρk} eventually will satisfy the homogeneous equation of this A R ( p ) A R(p) AR(p) process.
- ACF should converge to zero geometrically if the series is stationary.
一定要注意每一项之间的关系,不要漏掉
Form the Yule-Walker equations :
E ( y t y t ) = ϕ 1 E ( y t − 1 y t ) + ϕ 2 E ( y t − 2 y t ) + E ( ϵ t y t ) ⇒ γ 0 = ϕ 1 γ 1 + ϕ 2 γ 2 + σ 2 E ( y t y t − 1 ) = ϕ 1 E ( y t − 1 y t − 1 ) + ϕ 2 E ( y t − 2 y t − 1 ) + E ( ϵ t y t − 1 ) ⇒ γ 1 = ϕ 1 γ 0 + ϕ 2 γ 1 E ( y t y t − k ) = ϕ 1 E ( y t − 1 y t − k ) + ϕ 2 E ( y t − 2 y t − k ) + E ( ϵ t y t − k ) ⇒ γ k = ϕ 1 γ k − 1 + ϕ 2 γ k − 2 for k ≥ 2 \begin{aligned} E\left(y_{t} y_{t}\right) &=\phi_{1} E\left(y_{t-1} y_{t}\right)+\phi_{2} E\left(y_{t-2} y_{t}\right)+E\left(\epsilon_{t} y_{t}\right) \\ & \Rightarrow \gamma_{0}=\phi_{1} \gamma_{1}+\phi_{2} \gamma_{2}+\sigma^{2} \\ E\left(y_{t} y_{t-1}\right)=& \phi_{1} E\left(y_{t-1} y_{t-1}\right)+\phi_{2} E\left(y_{t-2} y_{t-1}\right)+E\left(\epsilon_{t} y_{t-1}\right) \\ \Rightarrow & \gamma_{1}=\phi_{1} \gamma_{0}+\phi_{2} \gamma_{1} \\ E\left(y_{t} y_{t-k}\right)=& \phi_{1} E\left(y_{t-1} y_{t-k}\right)+\phi_{2} E\left(y_{t-2} y_{t-k}\right)+E\left(\epsilon_{t} y_{t-k}\right) \\ \Rightarrow & \gamma_{k}=\phi_{1} \gamma_{k-1}+\phi_{2} \gamma_{k-2} \quad \text { for } k \geq 2 \end{aligned} E(ytyt)E(ytyt−1)=⇒E(ytyt−k)=⇒=ϕ1E(yt−1yt)+ϕ2E(yt−2yt)+E(ϵtyt)⇒γ0=ϕ1γ1+ϕ2γ2+σ2ϕ1E(yt−1yt−1)+ϕ2E(yt−2yt−1)+E(ϵtyt−1)γ1=ϕ1γ0+ϕ2γ1ϕ1E(yt−1yt−k)+ϕ2E(yt−2yt−k)+E(ϵtyt−k)γk=ϕ1γk−1+ϕ2γk−2 for k≥2
partial autocorrelation function(PACF)
y t = ϕ 1 , 0 + ϕ 1 , 1 y t − 1 + e 1 t y t = ϕ 2 , 0 + ϕ 2 , 1 y t − 1 + ϕ 2 , 2 y t − 2 + e 2 t y t = ϕ 3 , 0 + ϕ 3 , 1 y t − 1 + ϕ 3 , 2 y t − 2 + ϕ 3 , 3 y t − 3 + e 3 t y t = ϕ 4 , 0 + ϕ 4 , 1 y t − 1 + ϕ 4 , 2 y t − 2 + ϕ 4 , 3 y t − 3 + ϕ 4 , 4 y t − 4 + e 4 t ⋮ \begin{aligned} y_{t} &=\phi_{1,0}+\phi_{1,1} y_{t-1}+e_{1 t} \\ y_{t} &=\phi_{2,0}+\phi_{2,1} y_{t-1}+\phi_{2,2} y_{t-2}+e_{2 t} \\ y_{t} &=\phi_{3,0}+\phi_{3,1} y_{t-1}+\phi_{3,2} y_{t-2}+\phi_{3,3} y_{t-3}+e_{3 t} \\ y_{t} &=\phi_{4,0}+\phi_{4,1} y_{t-1}+\phi_{4,2} y_{t-2}+\phi_{4,3} y_{t-3}+\phi_{4,4} y_{t-4}+e_{4 t} \\ & \vdots \end{aligned} ytytytyt=ϕ1,0+ϕ1,1yt−1+e1t=ϕ2,0+ϕ2,1yt−1+ϕ2,2yt−2+e2t=ϕ3,0+ϕ3,1yt−1+ϕ3,2yt−2+ϕ3,3yt−3+e3t=ϕ4,0+ϕ4,1yt−1+ϕ4,2yt−2+ϕ4,3yt−3+ϕ4,4yt−4+e4t⋮
{ ϕ k , k , k ≥ 1 } \left\{\phi_{k, k}, k \geq 1\right\} {ϕk,k,k≥1} is the partial autocorrelation function.
- e i t e_{it} eit 不一定是白噪音
- e i t e_{it} eit 与 y t − 1 , y t − 2 , ⋯ y_{t-1},y_{t-2},\cdots yt−1,yt−2,⋯ 无关
我们可以利用Yule-Walker方程从ACF中推导出PACF。
E ( y t y t − 1 ) = ϕ 2 , 1 E ( y t − 1 y t − 1 ) + ϕ 2 , 2 E ( y t − 2 y t − 1 ) + E ( y t − 1 e 2 t ) ⇒ γ 1 = ϕ 2 , 1 γ 0 + ϕ 2 , 2 γ 1 ⇒ ρ 1 = ϕ 2 , 1 + ϕ 2 , 2 ρ 1 E ( y t y t − 2 ) = ϕ 2 , 1 E ( y t − 1 y t − 2 ) + ϕ 2 , 2 E ( y t − 2 y t − 2 ) + E ( y t − 2 e 2 t ) ⇒ γ 2 = ϕ 2 , 1 γ 1 + ϕ 2 , 2 γ 0 ⇒ ρ 2 = ϕ 2 , 1 ρ 1 + ϕ 2 , 2 \begin{aligned} E\left(y_{t} y_{t-1}\right) &=\phi_{2,1} E\left(y_{t-1} y_{t-1}\right)+\phi_{2,2} E\left(y_{t-2} y_{t-1}\right)+E\left(y_{t-1} e_{2 t}\right) \\ & \Rightarrow \gamma_{1}=\phi_{2,1} \gamma_{0}+\phi_{2,2} \gamma_{1} \Rightarrow \rho_{1}=\phi_{2,1}+\phi_{2,2} \rho_{1} \\ E\left(y_{t} y_{t-2}\right) &=\phi_{2,1} E\left(y_{t-1} y_{t-2}\right)+\phi_{2,2} E\left(y_{t-2} y_{t-2}\right)+E\left(y_{t-2} e_{2 t}\right) \\ & \Rightarrow \gamma_{2}=\phi_{2,1} \gamma_{1}+\phi_{2,2} \gamma_{0} \Rightarrow \rho_{2}=\phi_{2,1} \rho_{1}+\phi_{2,2} \end{aligned} E(ytyt−1)E(ytyt−2)=ϕ2,1E(yt−1yt−1)+ϕ2,2E(yt−2yt−1)+E(yt−1e2t)⇒γ1=ϕ2,1γ0+ϕ2,2γ1⇒ρ1=ϕ2,1+ϕ2,2ρ1=ϕ2,1E(yt−1yt−2)+ϕ2,2E(yt−2yt−2)+E(yt−2e2t)⇒γ2=ϕ2,1γ1+ϕ2,2γ0⇒ρ2=ϕ2,1ρ1+ϕ2,2
Thus ϕ 2 , 2 = ρ 2 − ρ 1 2 1 − ρ 1 2 \phi_{2,2}=\frac{\rho_{2}-\rho_{1}^{2}}{1-\rho_{1}^{2}} ϕ2,2=1−ρ12ρ2−ρ12. For any ϕ k , k , k ≥ 1 \phi_{k, k}, k \geq 1 ϕk,k,k≥1, the similar procedure works.
y t = ϕ 0 + ∑ j = 1 p ϕ j y t − j + ∑ j = 0 q β j ϵ t − j , ARMA ( p , q ) model. y_{t}=\phi_{0}+\sum_{j=1}^{p} \phi_{j} y_{t-j}+\sum_{j=0}^{q} \beta_{j} \epsilon_{t-j}, \quad \operatorname{ARMA}(\mathrm{p}, \mathrm{q}) \text { model. } yt=ϕ0+j=1∑pϕjyt−j+j=0∑qβjϵt−j,ARMA(p,q) model.
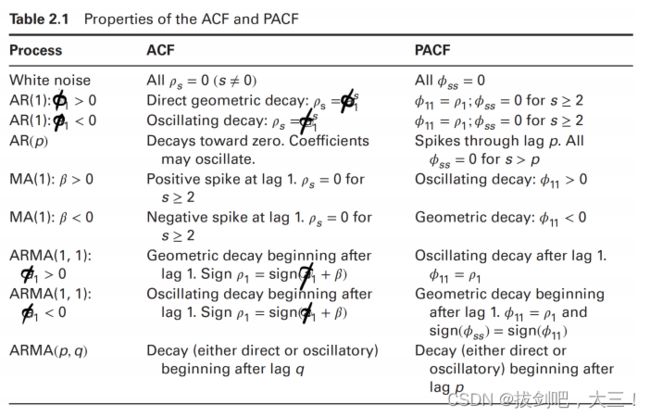
-
假设一个序列是平稳的,我们可以使用样本均值、方差、ACF和PACF来估计实际数据生成过程的参数。
-
样本ACF和样本PACF可以与各种理论函数进行比较,以帮助识别数据生成过程的实际性质。
Sample mean : y ˉ = ∑ t = 1 T y t T \bar{y}=\frac{\sum_{t=1}^{T} y_{t}}{T} yˉ=T∑t=1Tyt
Sample variance : σ ^ y 2 = ∑ t = 1 T ( y t − y ˉ ) 2 T : \widehat{\sigma}_{y}^{2}=\frac{\sum_{t=1}^{T}\left(y_{t}-\bar{y}\right)^{2}}{T} :σ y2=T∑t=1T(yt−yˉ)2.
Lag-k sample autocorrelation:
ρ ^ k = ∑ t = k + 1 T ( y t − y ˉ ) ( y t − k − y ˉ ) ∑ t = 1 T ( y t − y ˉ ) 2 k ≥ 1. \widehat{\rho}_{k}=\frac{\sum_{t=k+1}^{T}\left(y_{t}-\bar{y}\right)\left(y_{t-k}-\bar{y}\right)}{\sum_{t=1}^{T}\left(y_{t}-\bar{y}\right)^{2}} \quad k \geq 1 . ρ k=∑t=1T(yt−yˉ)2∑t=k+1T(yt−yˉ)(yt−k−yˉ)k≥1.
The statistics { ρ ^ 1 , ρ ^ 2 , … } \left\{\widehat{\rho}_{1}, \widehat{\rho}_{2}, \ldots\right\} {ρ 1,ρ 2,…} are called the sample ACF of { y t } \left\{y_{t}\right\} {yt}
ARMA(p,q)阶数的识别
t test
检验ACF的,即判断q有几阶
For a given positive integer k k k, test H 0 : ρ k = 0 H_{0}: \rho_{k}=0 H0:ρk=0 against H 1 : ρ k ≠ 0 H_{1}: \rho_{k} \neq 0 H1:ρk=0
-
If { y t } \left\{y_{t}\right\} {yt} is a stationary Gaussian series satisfying ρ j = 0 \rho_{j}=0 ρj=0 for j ≥ k j \geq k j≥k (i.e., if { y t } \left\{y_{t}\right\} {yt} is an M A ( k − 1 ) \mathrm{MA}(\mathrm{k}-1) MA(k−1) with normally distributed { ϵ t } \left\{\epsilon_{t}\right\} {ϵt} ), then ρ ^ k \widehat{\rho}_{k} ρ k is asymptotically normal with mean zero and variance 1 + 2 ∑ j = 1 k − 1 ρ j 2 T \frac{1+2 \sum_{j=1}^{k-1} \rho_{j}^{2}}{T} T1+2∑j=1k−1ρj2. Therefore, the test statistic is
t ratio = ρ ^ k ( 1 + 2 ∑ j = 1 k − 1 ρ ^ j 2 ) / T ⟶ D N ( 0 , 1 ) , as T → ∞ \mathrm{t} \text { ratio }=\frac{\widehat{\rho}_{k}}{\sqrt{\left(1+2 \sum_{j=1}^{k-1} \widehat{\rho}_{j}^{2}\right) / T}} \stackrel{\mathcal{D}}{\longrightarrow} \mathcal{N}(0,1), \quad \text { as } T \rightarrow \infty t ratio =(1+2∑j=1k−1ρ j2)/Tρ k⟶DN(0,1), as T→∞
where ⟶ D \stackrel{\mathcal{D}}{\longrightarrow} ⟶D denotes “converge in distribution”. -
If { y t } \left\{y_{t}\right\} {yt} is an i.i.d. sequence satisfying var ( y t ) < ∞ \operatorname{var}\left(y_{t}\right)<\infty var(yt)<∞ (i.e., if { y t } \left\{y_{t}\right\} {yt} is an i.i.d. M A ( 0 ) ) \left.\mathrm{MA}(0)\right) MA(0)), then ρ ^ k \widehat{\rho}_{k} ρ k is asymptotically normal with mean zero and variance 1 T \frac{1}{T} T1 for any k ≥ 1 k \geq 1 k≥1. Thus t t t ratio = ρ ^ k 1 / T ⟶ D N ( 0 , 1 ) =\frac{\widehat{\rho}_{k}}{\sqrt{1 / T}} \stackrel{\mathcal{D}}{\longrightarrow} \mathcal{N}(0,1) =1/Tρ k⟶DN(0,1), for sufficiently large T T T.
-
{ ρ ^ 1 , ρ ^ 2 , … } \left\{\widehat{\rho}_{1}, \widehat{\rho}_{2}, \ldots\right\} {ρ 1,ρ 2,…} will be calculated along with the acceptance intervals (significance level = 5 % =5 \% =5% ) under this i.i.d. assumption, once you put the data into Eviews or MATLAB.
检验过程
t>|1.96|拒绝 t<|1.96|接受
- H 0 : ρ 1 = 0 H 1 : q ≥ 1 H_0: \rho_1=0~ H_1:q\ge1 H0:ρ1=0 H1:q≥1. $t=\frac{\widehat{\rho}_{k}}{\sqrt{1 / T}} $
- 拒绝原假设,则继续检验
- H 0 : ρ 2 = 0 H 1 : q ≥ 2 H_0: \rho_2=0~ H_1:q\ge2 H0:ρ2=0 H1:q≥2. t ratio = ρ ^ k ( 1 + 2 ∑ j = 1 k − 1 ρ ^ j 2 ) / T {t} \text { ratio }=\frac{\widehat{\rho}_{k}}{\sqrt{\left(1+2 \sum_{j=1}^{k-1} \widehat{\rho}_{j}^{2}\right) / T}} t ratio =(1+2∑j=1k−1ρ j2)/Tρ k
- 直到接受原假设,此时可与得到q的阶数
Joint Test (Ljung-Box Q-statistics)
联合检验ACF,判断q值
- Significance test for a group of autocorrelations H 0 : ρ I = ⋯ = ρ m = 0 H_{0}: \rho_{I}=\cdots=\rho_{m}=0 H0:ρI=⋯=ρm=0 against H 1 : ρ i ≠ 0 H_{1}: \rho_{i} \neq 0 H1:ρi=0 for some 1 ≤ i ≤ m 1 \leq i \leq m 1≤i≤m
- Under the assumption that { y t } \left\{y_{t}\right\} {yt} is an i.i.d. sequence with certain moment conditions
Q ( m ) = T ( T + 2 ) ∑ k = 1 m ρ ^ k 2 T − k ⟶ D χ m 2 Q(m)=T(T+2) \sum_{k=1}^{m} \frac{\widehat{\rho}_{k}^{2}}{T-k} \stackrel{\mathcal{D}}{\longrightarrow} \chi_{m}^{2} Q(m)=T(T+2)k=1∑mT−kρ k2⟶Dχm2 - Decision rule : reject H 0 H_{0} H0 if Q ( m ) > χ m 2 ( α ) Q(m)>\chi_{m}^{2}(\alpha) Q(m)>χm2(α), where χ m 2 ( α ) \chi_{m}^{2}(\alpha) χm2(α) denotes the 100 ( 1 − α ) 100(1-\alpha) 100(1−α) th percentile of a chi-squared distribution with m m m degrees of freedom.
Q检验也可以判断残差是否为白噪音,但自由度会减小
Q ( m ) = T ( T + 2 ) ∑ k = 1 m ρ ~ k 2 T − k ⟶ D χ m − g 2 , Q(m)=T(T+2) \sum_{k=1}^{m} \frac{\tilde{\rho}_{k}^{2}}{T-k} \stackrel{\mathcal{D}}{\longrightarrow} \chi_{m-g}^{2}, Q(m)=T(T+2)k=1∑mT−kρ~k2⟶Dχm−g2,
where ρ ~ k \tilde{\rho}_{k} ρ~k is the sample ACF of estimation residuals, and g g g denotes 模型中固定的常数的个数
PACF可以帮助识别P
对于平稳的AR§模型
ϕ ^ k , k \widehat{\phi}_{k, k} ϕ k,k converges to ϕ k , k \phi_{k, k} ϕk,k in probability as the sample size T T T goes to infinity.
- ϕ p , p = ϕ p \phi_{p, p}=\phi_{p} ϕp,p=ϕp
- ϕ k , k = 0 \phi_{k, k}=0 ϕk,k=0 for k > p k>p k>p.
For k > p , ϕ ^ k , k k>p, \widehat{\phi}_{k, k} k>p,ϕ k,k is asymptotically normal with mean zero and variance 1 T \frac{1}{T} T1
t>|1.96|拒绝 t<|1.96|接受
- H 0 : ρ 1 = 0 H 1 : p ≥ 1 H_0: \rho_1=0~ H_1:p\ge1 H0:ρ1=0 H1:p≥1. $|PACF|>\frac{ 1.96}{\sqrt{1 / T}} $ 拒绝原假设
- 拒绝原假设,则继续检验
- H 0 : ρ 2 = 0 H 1 : p ≥ 2 H_0: \rho_2=0~ H_1:p\ge2 H0:ρ2=0 H1:p≥2. $|PACF|>\frac{ 1.96}{\sqrt{1 / T}} $ 拒绝原假设
- 直到接受原假设,此时可与得到q的阶数
Criteria: AIC, BIC
自由度和残差的一些trade off
-
Akaike information criterion (AIC):
A I C ( I ) = log ( σ ~ l 2 ) ⏟ goodness of fit + 2 I T ⏟ penalty function A I C(I)=\underbrace{\log \left(\tilde{\sigma}_{l}^{2}\right)}_{\text {goodness of fit }}+\underbrace{\frac{2 I}{T}}_{\text {penalty function }} AIC(I)=goodness of fit log(σ~l2)+penalty function T2I
where / / / is the number of parameters estimated and σ ~ I 2 = S S R T \tilde{\sigma}_{I}^{2}=\frac{S S R}{T} σ~I2=TSSR. -
Bayesian information criterion (BIC) or Schwarz information criterion ( S B C , S I C ) (\mathrm{SBC}, \mathrm{SIC}) (SBC,SIC) :
B I C ( I ) = log ( σ ~ l 2 ) ⏟ goodness of fit + log ( T ) T ⏟ penalty function B I C(I)=\underbrace{\log \left(\widetilde{\sigma}_{l}^{2}\right)}_{\text {goodness of fit }}+\underbrace{\frac{\log (T)}{T}}_{\text {penalty function }} BIC(I)=goodness of fit log(σ l2)+penalty function Tlog(T)
Choose the model with minimum A I C \mathrm{AIC} AIC or B I C \mathrm{BIC} BIC. -
BIC适用于大样本。BIC将渐近地提供正确的模型,而AIC则倾向于选择一个过参数化的模型。
-
在小样本中,AIC比BIC工作得更好。在BIC的背景下,来自给定总体中不同样本的选定模型顺序的平均变化将大于AIC。
如果他们建议不同的模型,应该选择哪个IC?
- 由于BIC选择了更简洁的模型,因此您应该检查以确定残差是否显示为白噪声。
- 由于AIC可以选择一个过度参数化的模型,因此所有系数的t-统计量在传统水平上都应该是显著的。
- 可能无法找到一个明显占优于所有其他模型的模型
检验 : 残差是否为白噪音 预测未来的数据
Box-Jenkins Approach
Box and Jenkins ( 1970 , 1976 ) (1970,1976) (1970,1976) popularized a three-stage method to estimate an ARMA model in a systematic manner.
-
Identification
-
Estimation
-
Model diagnostic checking
-
Identification
- First of all, one might visually examine the time plot of the series, sample ACF and sample PACF. A comparison of the sample ACF and PACF to those of various theoretical ARMA processes may suggest several candidate models.
- Model specification: AIC, BIC.
Parsimony简洁原则
- Similar processes can be approximated by very different models.
- Common factor problem.
- Each coefficient is significantly different from zero at the conventional level.
- Estimation
Estimation can be done using least squares or maximum likelihood depending on the model.
- AR models : least squares method or maximum likelihood method
- MA and ARMA models : maximum likelihood method
残差平方和最小和极大似然估计
Stationarity and Invertibility
- t-stats, ACF, Q-stats, ⋯ \cdots ⋯ all assume that the process is stationary.
- Be suspicious of implied roots near the unit circle.
- Invertibility implies the model has an AR representation.
- No unit root in MA part of the model. 在MA模型中无单位根
- ARMA(p,q)过程的可逆性条件完全由它的MA部分决定。
极大似然估计?
待完善。。。
- Model diagnostic checking
- Residual diagnostics :
- Plot residuals : look for outliers and periods of poor fit.
- Residuals should be serially uncorrelated : examine ACF, PACF, Q-stats of residuals.残差要序列不相关
- Divide sample into subperiods 样本内预测,看拟合效果
- Out-of-sample forecasts 样本外预测
预测
条件均值(期望)
This result is really quite general: for any stationary ARMA model, the conditional forecast of y t + j y_{t+j} yt+j converges to the unconditional mean as j → ∞ j \rightarrow \infty j→∞.
e t ( j ) = y t + j − E t y t + j e_t(j)=y_{t+j}-E_ty_{t+j} et(j)=yt+j−Etyt+j
The 95 % 95 \% 95% confidence interval for the j j j-step ahead forecast is :
[ E t y t + j − 1.96 var ( e t ( j ) ) , E t y t + j + 1.96 var ( e t ( j ) ) ] . \left[E_{t} y_{t+j}-1.96 \sqrt{\operatorname{var}\left(e_{t}(j)\right)}, E_{t} y_{t+j}+1.96 \sqrt{\operatorname{var}\left(e_{t}(j)\right)}\right] \text {. } [Etyt+j−1.96var(et(j)),Etyt+j+1.96var(et(j))].
test whether a forecast is accurate or not
We want the forecast errors to be small!
If there are H \mathrm{H} H observations in the holdback periods, and { e j } j = 1 H \left\{e_{j}\right\}_{j=1}^{H} {ej}j=1H are the forecast errors from the candidate model :
- Mean squared prediction error: MSPE = 1 H ∑ j = 1 H e j 2 =\frac{1}{H} \sum_{j=1}^{H} e_{j}^{2} =H1∑j=1Hej2. It is also called mean squared error (MSE).
- Mean absolute error: M A E = 1 H ∑ j = 1 H ∣ e j ∣ \mathrm{MAE}=\frac{1}{H} \sum_{j=1}^{H}\left|e_{j}\right| MAE=H1∑j=1H∣ej∣.
- Mean absolute percentage error: MAPE = 1 H ∑ j = 1 H ∣ e j y T + j ∣ ⋅ 100 =\frac{1}{H} \sum_{j=1}^{H}\left|\frac{e_{j}}{y_{T+j}}\right| \cdot 100 =H1∑j=1H∣∣∣yT+jej∣∣∣⋅100.
Many researchers would select the model with the smallest MSPE (or MAE, MAPE).
Diebold-Mariano Test
- Let the loss from a forecast error in period j j j be denoted by g ( e j ) g\left(e_{j}\right) g(ej). In the typical case of mean squared errors, the loss is e j 2 e_{j}^{2} ej2
- We can write the differential loss in period j j j from using model 1 versus model 2 as d j = g ( e 1 j ) − g ( e 2 j ) d_{j}=g\left(e_{1 j}\right)-g\left(e_{2 j}\right) dj=g(e1j)−g(e2j). The mean loss can be obtained as
d ˉ = 1 H ∑ j = 1 H [ g ( e 1 j ) − g ( e 2 j ) ] \bar{d}=\frac{1}{H} \sum_{j=1}^{H}\left[g\left(e_{1 j}\right)-g\left(e_{2 j}\right)\right] dˉ=H1j=1∑H[g(e1j)−g(e2j)] - Under the null hypothesis of equal forecast accuracy,
- H 0 : E ( d ˉ ) = E ( d j ) = 0 H_0:\quad E(\bar{d})=E\left(d_{j}\right)=0 H0:E(dˉ)=E(dj)=0
- H 1 : E ( d ˉ ) > 0 ? E ( d ˉ ) < 0 ? H_1: \quad E(\bar{d})>0 ? E(\bar{d})<0 ? H1:E(dˉ)>0?E(dˉ)<0? (模型2更好,模型1更好)
Under fairly weak conditions, the central limit theorem implies that d ˉ ⟶ D N ( 0 , var ( d ˉ ) ) \bar{d} \stackrel{\mathcal{D}}{\longrightarrow} \mathcal{N}(0, \operatorname{var}(\bar{d})) dˉ⟶DN(0,var(dˉ)), as H → ∞ H \rightarrow \infty H→∞, under the null hypothesis.
-
If the { d j } \left\{d_{j}\right\} {dj} series is serially uncorrelated with a sample variance of γ ^ \hat{\gamma} γ^, 若序列无关the estimator of var ( d ˉ ) \operatorname{var}(\bar{d}) var(dˉ) is simply γ ^ H − 1 \frac{\widehat{\gamma}}{H-1} H−1γ . The expression
d ˉ γ ^ / ( H − 1 ) ⟶ D N ( 0 , 1 ) , as H → ∞ , \frac{\bar{d}}{\sqrt{\hat{\gamma} /(H-1)}} \stackrel{\mathcal{D}}{\longrightarrow} \mathcal{N}(0,1), \quad \text { as } \quad H \rightarrow \infty, γ^/(H−1)dˉ⟶DN(0,1), as H→∞,
under the null hypothesis. -
If the { d j } \left\{d_{j}\right\} {dj} series is serially correlated,若序列相关 there is a very large literature on the best way to estimate var ( d ˉ ) \operatorname{var}(\bar{d}) var(dˉ) in the presence of serial correlation (e.g., the Newey-West estimator of the variance proposed in Newey and West ( 1987 ) ) (1987)) (1987)).
d ˉ var ( d ˉ ) ^ ⟶ D N ( 0 , 1 ) , as H → ∞ \frac{\bar{d}}{\sqrt{\hat{\operatorname{var}(\bar{d})}}} \stackrel{\mathcal{D}}{\longrightarrow} \mathcal{N}(0,1), \quad \text { as } \quad H \rightarrow \infty var(dˉ)^dˉ⟶DN(0,1), as H→∞
under the null hypothesis, where var ( d ˉ ) ^ \hat{\operatorname{var}(\bar{d})} var(dˉ)^ is an appropriate estimator of var ( d ˉ ) \operatorname{var}(\bar{d}) var(dˉ).
双边检验:1.96
单边检验:1.645
$H_1: \quad E(\bar{d})>0 ? $ 模型二更好1.645
E ( d ˉ ) < 0 ? E(\bar{d})<0 ? E(dˉ)<0? 模型一更好-1.645
time series with trend
- 做差分去趋势化(log difference)
- 直接回归方程
周期性或季节性ARMA model
拟合模型应同时考虑数据中的季节模式和非季节模式。
Chapter 4 Modeling Volatility
the volatility equation:
σ t 2 = var ( y t ∣ F t − 1 ) = var ( ϵ t ∣ F t − 1 ) \sigma_{t}^{2}=\operatorname{var}\left(y_{t} \mid \mathcal{F}_{t-1}\right)=\operatorname{var}\left(\epsilon_{t} \mid \mathcal{F}_{t-1}\right) σt2=var(yt∣Ft−1)=var(ϵt∣Ft−1)
- Volatility σ t \sigma_{t} σt : the conditional standard deviation of y t y_{t} yt based on a past information set F t − 1 \mathcal{F}_{t-1} Ft−1.
ARCH(q) 自回归条件异方差
A natural idea is to model ϵ t 2 \epsilon_{t}^{2} ϵt2 using an A R ( q ) A R(q) AR(q) process:
ϵ t 2 = α 0 + α 1 ϵ t − 1 2 + ⋯ + α q ϵ t − q 2 + η t ⇒ σ t 2 = α 0 + α 1 ϵ t − 1 2 + ⋯ + α q ϵ t − q 2 \begin{aligned} \epsilon_{t}^{2} &=\alpha_{0}+\alpha_{1} \epsilon_{t-1}^{2}+\cdots+\alpha_{q} \epsilon_{t-q}^{2}+\eta_{t} \\ \Rightarrow \sigma_{t}^{2} &=\alpha_{0}+\alpha_{1} \epsilon_{t-1}^{2}+\cdots+\alpha_{q} \epsilon_{t-q}^{2} \end{aligned} ϵt2⇒σt2=α0+α1ϵt−12+⋯+αqϵt−q2+ηt=α0+α1ϵt−12+⋯+αqϵt−q2
Eq. is called an autoregressive conditional heteroskedasticity ( A R C H ) (\mathbf{A R C H}) (ARCH) model of order q q q.
ARCH (q) model
y t = E ( y t ∣ F t − 1 ) + ϵ t , ϵ t = σ t v t σ t 2 = α 0 + α 1 ϵ t − 1 2 + ⋯ + α q ϵ t − q 2 \begin{aligned} y_{t} &=E\left(y_{t} \mid \mathcal{F}_{t-1}\right)+\epsilon_{t}, \quad \epsilon_{t}=\sigma_{t} v_{t} \\ \sigma_{t}^{2} &=\alpha_{0}+\alpha_{1} \epsilon_{t-1}^{2}+\cdots+\alpha_{q} \epsilon_{t-q}^{2} \end{aligned} ytσt2=E(yt∣Ft−1)+ϵt,ϵt=σtvt=α0+α1ϵt−12+⋯+αqϵt−q2
- This is an ARCH (q) model.
- α 0 > 0 \alpha_{0}>0 α0>0, and α i ≥ 0 \alpha_{i} \geq 0 αi≥0 for i > 0 i>0 i>0 for positiveness.
- ∑ i = 1 q α i < 1 \sum_{i=1}^{q} \alpha_{i}<1 ∑i=1qαi<1 for stationarity.
- { v t } \left\{v_{t}\right\} {vt} is a sequence of i.i.d.r.v. with mean 0 and variance 1 .
协方差Cov( , )反映的是线性相关关系
Corr( , )表示是否相关 独立是p(xy)=p(x)p(y)
善用全期望公式
E ( ϵ t ) = E [ E ( ϵ t ∣ F t − 1 ) ] = 0 E ( ϵ t ϵ t − j ) = E [ E ( ϵ t ϵ t − j ∣ F t − 1 ) ] = E [ ϵ t − j E ( ϵ t ∣ F t − 1 ) ] = 0 j ≥ 1 \begin{aligned} E\left(\epsilon_{t}\right) &=E\left[E\left(\epsilon_{t} \mid \mathcal{F}_{t-1}\right)\right]=0 \\ E\left(\epsilon_{t} \epsilon_{t-j}\right) &=E\left[E\left(\epsilon_{t} \epsilon_{t-j} \mid \mathcal{F}_{t-1}\right)\right]=E\left[\epsilon_{t-j} E\left(\epsilon_{t} \mid \mathcal{F}_{t-1}\right)\right]=0 \quad j \geq 1 \end{aligned} E(ϵt)E(ϵtϵt−j)=E[E(ϵt∣Ft−1)]=0=E[E(ϵtϵt−j∣Ft−1)]=E[ϵt−jE(ϵt∣Ft−1)]=0j≥1
ϵ t 2 \epsilon_t^2 ϵt2
Assuming stationarity ( α 1 + ⋯ + α q < 1 ) \left(\alpha_{1}+\cdots+\alpha_{q}<1\right) (α1+⋯+αq<1)
var ( ϵ t ) = E ( ϵ t 2 ) = E [ E ( ϵ t 2 ∣ F t − 1 ) ] = E ( σ t 2 ) = α 0 + α 1 E ( ϵ t − 1 2 ) + ⋯ + α q E ( ϵ t − q 2 ) \begin{aligned} \operatorname{var}\left(\epsilon_{t}\right) &=E\left(\epsilon_{t}^{2}\right)=E\left[E\left(\epsilon_{t}^{2} \mid \mathcal{F}_{t-1}\right)\right]=E\left(\sigma_{t}^{2}\right) \\ &=\alpha_{0}+\alpha_{1} E\left(\epsilon_{t-1}^{2}\right)+\cdots+\alpha_{q} E\left(\epsilon_{t-q}^{2}\right) \end{aligned} var(ϵt)=E(ϵt2)=E[E(ϵt2∣Ft−1)]=E(σt2)=α0+α1E(ϵt−12)+⋯+αqE(ϵt−q2)
which implies that
var ( ϵ t ) = E ( σ t 2 ) = α 0 1 − α 1 − ⋯ − α q \operatorname{var}\left(\epsilon_{t}\right)=E\left(\sigma_{t}^{2}\right)=\frac{\alpha_{0}}{1-\alpha_{1}-\cdots-\alpha_{q}} var(ϵt)=E(σt2)=1−α1−⋯−αqα0
The error { ϵ t } \left\{\epsilon_{t}\right\} {ϵt} is uncorrelated and stationary with mean zero and constant unconditional variance (with constraints to A R C H \mathrm{ARCH} ARCH parameters).
ϵ t 2 \epsilon_t^2 ϵt2 是一个白噪音,uncorrelated, but dependent. 非线性相关关系
ARCH Model 可以描述序列的平稳性和波动性
Heavy tails
long tail / fat tail/ heavy tail
- Kurtosis of a random variable y y y is defined to be E [ ( y − E ( y ) ) 4 ] [ var ( y ) ] 2 \frac{E\left[(y-E(y))^{4}\right]}{[\operatorname{var}(y)]^{2}} [var(y)]2E[(y−E(y))4]. For example,
- the kurtosis of a normal distribution is 3. 3 . 3.
- the kurtosis of a student’s t \mathrm{t} t distribution with ν \nu ν degrees of freedom is 6 ν − 4 + 3 \frac{6}{\nu-4}+3 ν−46+3, for ν > 4 \nu>4 ν>4.
- Kurtosis identifies whether the tails of a given distribution contain extreme values.
- Excess kurtosis=kurtosis-3 defines how heavily the tails of a distribution differ from the tails of a normal distribution.
ARCH heavy tail
Advantages
- Simplicity
- A R C H \mathrm{ARCH} ARCH can model the volatility clustering effect since the conditional variance is autoregressive. Such models can be used to forecast volatility.
- Heavy tails (high kurtosis)
Weaknesses
- Symmetric between positive & negative prior shocks
- Restrictive on parameter space
Idea : A R C H \mathrm{ARCH} ARCH is like an A R \mathrm{AR} AR model for volatility. G A R C H \mathrm{GARCH} GARCH is like an ARMA model for volatility.
G A R C H ( p , q ) G A R C H(p, q) GARCH(p,q) model :
y t = E ( y t ∣ F t − 1 ) + ϵ t ϵ t = σ t v t σ t 2 = α 0 + ∑ i = 1 q α i ϵ t − i 2 + ∑ j = 1 p β j σ t − j 2 \begin{aligned} y_{t} &=E\left(y_{t} \mid \mathcal{F}_{t-1}\right)+\epsilon_{t} \quad \epsilon_{t}=\sigma_{t} v_{t} \\ \sigma_{t}^{2} &=\alpha_{0}+\sum_{i=1}^{q} \alpha_{i} \epsilon_{t-i}^{2}+\sum_{j=1}^{p} \beta_{j} \sigma_{t-j}^{2} \end{aligned} ytσt2=E(yt∣Ft−1)+ϵtϵt=σtvt=α0+i=1∑qαiϵt−i2+j=1∑pβjσt−j2
- α 0 > 0 \alpha_{0}>0 α0>0, and α i ≥ 0 , β j ≥ 0 \alpha_{i} \geq 0, \beta_{j} \geq 0 αi≥0,βj≥0 for i , j > 0 i, j>0 i,j>0 ensure positiveness.
- ∑ i = 1 max ( p , q ) ( α i + β i ) < 1 \sum_{i=1}^{\max (p, q)}\left(\alpha_{i}+\beta_{i}\right)<1 ∑i=1max(p,q)(αi+βi)<1 ensures stationarity.(证明如下)
- { v t } \left\{v_{t}\right\} {vt} is a sequence of i.i.d. r.v. with mean 0 and variance 1 .
Re-parameterization :
Let η t = ϵ t 2 − σ t 2 . { η t } \eta_{t}=\epsilon_{t}^{2}-\sigma_{t}^{2} .\left\{\eta_{t}\right\} ηt=ϵt2−σt2.{ηt} are uncorrelated series. The G A R C H \mathrm{GARCH} GARCH model becomes
ϵ t 2 = α 0 + ∑ i = 1 max ( p , q ) ( α i + β i ) ϵ t − i 2 + η t − ∑ j = 1 p β j η t − j \epsilon_{t}^{2}=\alpha_{0}+\sum_{i=1}^{\max (p, q)}\left(\alpha_{i}+\beta_{i}\right) \epsilon_{t-i}^{2}+\eta_{t}-\sum_{j=1}^{p} \beta_{j} \eta_{t-j} ϵt2=α0+i=1∑max(p,q)(αi+βi)ϵt−i2+ηt−j=1∑pβjηt−j
This is an ARMA form for the squared series ϵ t 2 \epsilon_{t}^{2} ϵt2.
The error { ϵ t } \left\{\epsilon_{t}\right\} {ϵt} is uncorrelated and stationary with mean zero and finite unconditional variance,
E ( ϵ t ∣ F t − 1 ) = 0 , E ( ϵ t ) = 0 , E ( ϵ t ϵ t − j ) = 0 j ≥ 1 var ( ϵ t ) = E ( ϵ t 2 ) = α 0 1 − ( ∑ i = 1 m α i ) − ( ∑ j = 1 s β j ) \begin{aligned} E\left(\epsilon_{t} \mid \mathcal{F}_{t-1}\right) &=0, \quad E\left(\epsilon_{t}\right)=0, \quad E\left(\epsilon_{t} \epsilon_{t-j}\right)=0 \quad j \geq 1 \\ \operatorname{var}\left(\epsilon_{t}\right) &=E\left(\epsilon_{t}^{2}\right)=\frac{\alpha_{0}}{1-\left(\sum_{i=1}^{m} \alpha_{i}\right)-\left(\sum_{j=1}^{s} \beta_{j}\right)} \end{aligned} E(ϵt∣Ft−1)var(ϵt)=0,E(ϵt)=0,E(ϵtϵt−j)=0j≥1=E(ϵt2)=1−(∑i=1mαi)−(∑j=1sβj)α0
provided that ∑ i = 1 max ( m , s ) ( α i + β i ) < 1 \sum_{i=1}^{\max (m, s)}\left(\alpha_{i}+\beta_{i}\right)<1 ∑i=1max(m,s)(αi+βi)<1
GARCH heavy tails
一般来说,一个GARCH(1,1)模型将足以捕获数据中的波动性聚类。
除了ARCH,GARCH,还有其他的包含过去信息的形式的模型
Identification of A R C H \mathrm{ARCH} ARCH and GARCH Models
- Modeling the mean equation and testing for A R C H \mathrm{ARCH} ARCH effects.
- H 0 H_{0} H0 : no A R C H \mathrm{ARCH} ARCH effects versus H 1 : A R C H H_{1}: \mathrm{ARCH} H1:ARCH effects.
- Use Q-statistics of squared residuals { ϵ ^ t 2 } \left\{\hat{\epsilon}_{t}^{2}\right\} {ϵ^t2} or LM test.
- Order determination :
- PACF of the squared residuals ϵ ^ t 2 \widehat{\epsilon}_{t}^{2} ϵ t2 gives useful information about the ARCH order q q q (see Eq.(2)); 、
- to identify GARCH models, we use information criteria.
Testing for ARCH Effects
类似于AR model的检验
Ljung-Box statistics
Consider testing H 0 : ( H_{0}:( H0:( No A R C H ) α 1 = α 2 = ⋯ = α q = 0 \mathrm{ARCH}) \alpha_{1}=\alpha_{2}=\cdots=\alpha_{q}=0 ARCH)α1=α2=⋯=αq=0 against H 1 : ( A R C H ) H_{1}:(\mathrm{ARCH}) H1:(ARCH) at least one α i ≠ 0 \alpha_{i} \neq 0 αi=0
- Step 1 : Compute residuals { ϵ t ^ } \left\{\hat{\epsilon_{t}}\right\} {ϵt^} from mean equation regression.
- Step 2 : Apply the usual Ljung-Box statistics Q ( m ) Q(m) Q(m) to { ϵ ^ t 2 } \left\{\hat{\epsilon}_{t}^{2}\right\} {ϵ^t2} series.
- View/Residual Diagnostics : Correlogram Squared Residuals
Engle derived a simple LM test :
-
Step 1: Compute residuals { ϵ t ^ } \left\{\hat{\epsilon_{t}}\right\} {ϵt^} from mean equation regression.
-
Step 2 : Estimate auxiliary regression
ϵ ^ t 2 = α 0 + α 1 ϵ ^ t − 1 2 + ⋯ + α q ϵ ^ t − q 2 + error t \hat{\epsilon}_{t}^{2}=\alpha_{0}+\alpha_{1} \hat{\epsilon}_{t-1}^{2}+\cdots+\alpha_{q} \hat{\epsilon}_{t-q}^{2}+\text { error }_{t} ϵ^t2=α0+α1ϵ^t−12+⋯+αqϵ^t−q2+ error t
Obtain R 2 ≡ R A U X 2 R^{2} \equiv R_{A U X}^{2} R2≡RAUX2 from this regression. -
Step 3 : Form the LM test statistic
L M A R C H = T ⋅ R A U X 2 L M_{A R C H}=T \cdot R_{A U X}^{2} LMARCH=T⋅RAUX2
where T = T= T= sample size from auxiliary regression.
Under H 0 H_{0} H0 : (No A R C H ) , L M A R C H \mathrm{ARCH}), L M_{A R C H} ARCH),LMARCH is asymptotically distributed as χ 2 ( q ) \chi^{2}(q) χ2(q).
Estimation of ARCH/GARCH Models
由于非线性,所以只能使用极大似然估计
The steps involved in actually estimating an A R C H \mathrm{ARCH} ARCH or GARCH model are as follows :
(1) Specify the appropriate equations for the mean and the variance - e.g. an A R ( 1 ) − G A R C H ( 1 , 1 ) \mathrm{AR}(1)-\mathrm{GARCH}(1,1) AR(1)−GARCH(1,1) model:
y t = ϕ 0 + ϕ 1 y t − 1 + ϵ t , ϵ t = σ t v t , v t ∼ i . i . d N ( 0 , 1 ) , σ t 2 = α 0 + α 1 ϵ t − 1 2 + β 1 σ t − 1 2 . \begin{aligned} &y_{t}=\phi_{0}+\phi_{1} y_{t-1}+\epsilon_{t}, \epsilon_{t}=\sigma_{t} v_{t}, v_{t} \stackrel{i . i . d}{\sim} \mathcal{N}(0,1), \\ &\sigma_{t}^{2}=\alpha_{0}+\alpha_{1} \epsilon_{t-1}^{2}+\beta_{1} \sigma_{t-1}^{2} . \end{aligned} yt=ϕ0+ϕ1yt−1+ϵt,ϵt=σtvt,vt∼i.i.dN(0,1),σt2=α0+α1ϵt−12+β1σt−12.
(2) Specify the log-likelihood function to maximize:
L = − T 2 log ( 2 π ) − 1 2 ∑ t = 1 T log ( σ t 2 ) − 1 2 ∑ t = 1 T ( y t − ϕ 0 − ϕ 1 y t − 1 ) 2 σ t 2 . L=-\frac{T}{2} \log (2 \pi)-\frac{1}{2} \sum_{t=1}^{T} \log \left(\sigma_{t}^{2}\right)-\frac{1}{2} \sum_{t=1}^{T} \frac{\left(y_{t}-\phi_{0}-\phi_{1} y_{t-1}\right)^{2}}{\sigma_{t}^{2}} . L=−2Tlog(2π)−21t=1∑Tlog(σt2)−