Python数据分析案例:对全国大学综合数据分析,本可视化展示(附加2021全国大学排名爬虫源码)
前言
软科中国大学排名以专业、客观、透明的优势赢得了高等教育领域和社会的广泛关注和认可,本次将利用Python对我国大学排名和分布情况进行一番研究。
先展示下爬虫的源码
import requests
import parsel
import csv
f = open('排名.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['名次', '学校名称', '综合得分', '星级排名', '办学层次'])
url = 'http://m.gaosan.com/gaokao/265440.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
response.encoding = response.apparent_encoding
selector = parsel.Selector(response.text)
trs = selector.css('#page tr')
for tr in trs:
dit = {}
ranking = tr.css('td:nth-child(1)::text').get()
dit['名次'] = ranking
school = tr.css('td:nth-child(2)::text').get()
dit['学校名称'] = school
score = tr.css('td:nth-child(3)::text').get()
dit['综合得分'] = score
star = tr.css('td:nth-child(4)::text').get()
dit['星级排名'] = star
level = tr.css('td:nth-child(5)::text').get()
dit['办学层次'] = level
csv_writer.writerow(dit)
print(dit)
f.close()
Python从零基础入门到实战系统教程、源码、视频,想要数据集的同学也可以点这里
数据分析涉及到的内容
- Pandas — 数据处理
- Pyecharts — 数据可视化
导入模块
from pyecharts.charts import Map,Bar,Pie
from pyecharts import options as opts
import pandas as pd
Pandas数据处理
读取数据
df = pd.read_csv('中国大学综合排名.csv',index_col=0)
df.head()

查看表格数据类型
df.dtypes

统计各省市大学数量
# 各省份大学数量
df_counts = df.groupby('省市').count()['排名']
df0 = df_counts.copy()
# 进行降序排列 并在当前df0上进行修改
df0.sort_values(ascending=False, inplace=True)
df0

各省市大学平均分排序
# 统计每个省份大学的数量以及平均分
# 算出平均分
df_means0 = df.groupby('省市').mean()['总分']
# 取两位小数
df_means = df_means0.round(2)
# 合并上面的大学数量跟平均分
df1 = pd.concat([df_counts, df_means], axis=1)
# 改变列名
df1.columns = ['数量', '平均分']
# 通过 平均分 进行降序排列 并在当前df1上进行修改
df1.sort_values(by=['平均分'], ascending=False, inplace=True)
df1

Pyecharts数据可视化
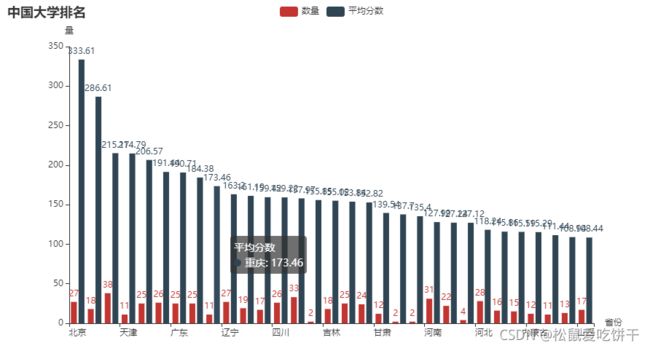
各省市大学数量和平均分柱状图(横向)
d1 = df1.index.tolist()
d2 = df1['数量'].values.tolist()
d3 = df1['平均分'].values.tolist()
bar0 = (
Bar()
.add_xaxis(d1)
.add_yaxis('数量', d2)
.add_yaxis('平均分数', d3)
.set_global_opts(
title_opts=opts.TitleOpts(title='中国大学排名'),
yaxis_opts=opts.AxisOpts(name='量'),
xaxis_opts=opts.AxisOpts(name='省份'),
)
)
bar0.render_notebook()
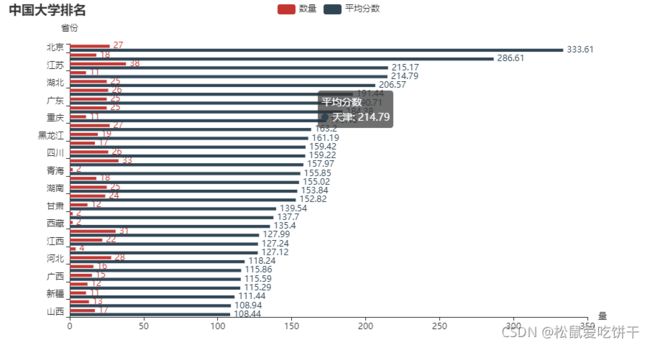
各省市大学数量和平均分柱状图(纵向)
df1.sort_values(by=['平均分'], inplace=True)
d1 = df1.index.tolist()
d2 = df1['数量'].values.tolist()
d3 = df1['平均分'].values.tolist()
bar1 = (
Bar()
.add_xaxis(d1)
.add_yaxis('数量', d2)
.add_yaxis('平均分数', d3)
# 坐标轴翻转
.reversal_axis()
# 数值显示靠右
.set_series_opts(label_opts=opts.LabelOpts(position='right'))
.set_global_opts(
title_opts=opts.TitleOpts(title='中国大学排名'),
yaxis_opts=opts.AxisOpts(name='省份'),
xaxis_opts=opts.AxisOpts(name='量'),
)
)
bar1.render_notebook()
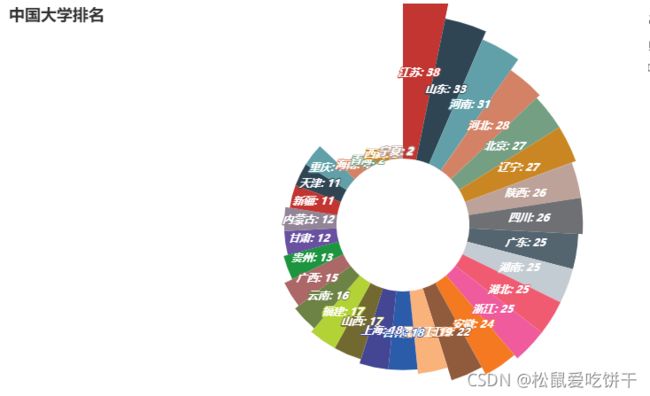
各省市大学数量玫瑰图
弗罗伦斯·南丁格尔(Florence Nightingale),一位著名的英国护士,同时她也是一位统计学家,很多人没有想到吧?
她被号称为数据可视化的鼻祖,就是数据可视化的祖师爷,你可能也没有想到吧?
她是英国皇家统计学会的第一个女成员,也是美国统计协会的名誉会员。
克里米亚战争时期,南丁格尔发现大多数士兵不是阵亡,而是因为饥饿、营养不良、卫生条件差和野战医院的条件差才死于其战伤。
于是她向上级报告了克里米亚战争的医疗条件,同时申请一批医疗物质来改变医疗条件。由于国会议员不会阅读统计报告,所以她的申请一直得不到批准。于是她改用了极座标饼图的形式来展示战地医院的病人死亡率在不同季节的变化,重新提交这个申请报告,没想到马上就得到了批准。这是这批物质改善了战地医院的卫生条件,仅此一项改革就大大地提高了受伤战士的生存率。
后被这个图就被称为南丁格尔玫瑰图,南丁格尔也被尊称为数据可视化鼻祖
name = df_counts.index.tolist()
count = df_counts.values.tolist()
c0 = (
Pie()
.add(
'',
[list(z) for z in zip(name, count)],
# 饼图的半径,数组的第一项是内半径,第二项是外半径
# 默认设置成百分比,相对于容器高宽中较小的一项的一半
radius=['20%', '60%'],
# 让图在这个位置显示
center=['50%', '65%'],
# 是否展示成南丁格尔图,通过半径区分数据大小,有'radius'和'area'两种模式。
# radius:扇区圆心角展现数据的百分比,半径展现数据的大小
# area:所有扇区圆心角相同,仅通过半径展现数据大小
rosetype="radius",
# 显示标签
label_opts=opts.LabelOpts(is_show=False),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter='{b}: {c}'))
)
c0.render_notebook()

各省市大学数量南丁格尔玫瑰图
provinces = df0.index.tolist()
num = df0.values.tolist()
c1 = (
Pie()
.add('',
[list(z) for z in zip(provinces, num)],
radius=['30%', '105%'],
rosetype='area'
)
.set_global_opts(
title_opts=opts.TitleOpts(title='中国大学排名'),
legend_opts=opts.LegendOpts(is_show=False),
toolbox_opts=opts.ToolboxOpts()
)
.set_series_opts(
label_opts=opts.LabelOpts(
# 是否显示标签
is_show=True,
# 设置标签位置
position="inside",
font_size=12,
formatter='{b}: {c}',
# 斜体
font_style='italic',
# 加粗
font_weight='bold',
# 微软的雅黑字体
font_family='Microsoft YaHei'
)
)
)
c1.render_notebook()
总结
大学数量较多的省市:江苏、山东、河南、河北、北京、辽宁 、陕西、四川 、广东 、湖南 、湖北、浙江等地(只看学校数量),后期探索可根据学校排名
排名前20的大学较前一年的波动较小(这也符合常理,毕竟前几的学校都是多年沉淀下来的)
西部地区大学数量较少
本数据集不包含港、澳、台大学(网站未统计)