R-CNN,Fast R-CNN,Faster R-CNN演化过程与原理详解
文章来源于视频https://www.bilibili.com/video/BV1af4y1m7iL
目录
-
- 1 、R-CNN
-
- 1.1 算法流程(可分为四个步骤)
- 1.2 R-CNN算法详解
-
- 1.2.1 候选区域的生成
- 1.2.2 对每个候选区域,使用深度网络提取特征
- 1.2.3 特征送入每一类的SVM分类器,判定类别
- 1.2.4 使用回归器精细修正候选框位置
- 1.2.5 R-CNN整体框架
- 1.3 R-CNN存在的问题
- 2 Fast R-CNN
-
- 2.1算法流程(可分为3个步骤)
- 2.2 实现过程
-
- 2.2.1 一次性计算整张图像特征
- 2.2.2 正、负样本采集
- 2.2.3 ROI Pooling Layer
- 2.2.4 分类器
- 2.2.5 边界框回归器
- 2.2.6 计算损失
- 2.2.7 Fast R-CNN整体框架
- 2.3 Fast R-CNN存在的问题
- 3 Faster R-CNN
-
- 3.1 Faster R-CNN算法流程(可分为3个步骤)
- 3.2 Faster R-CNN各部分实现
-
- 3.2.1 RPN结构
- 3.2.2 RPN计算特征图的点对应原图的位置
- 3.2.3 RPN中的分类器和回归器
- 3.2.4 RPN 中的anchor box 和sliding window
- 3.2.5 RPN正负样本的判定
- 3.2.6 RPN损失函数
- 3.3 Faster R-CNN训练
- 3.4 Faster R-CNN整体框架
- 结语
1 、R-CNN
1.1 算法流程(可分为四个步骤)
- 一张图像生成1K~2K个候选区域(使用Selective Search方法,以下简称SS方法)
- 对每个候选区域,使用深度网络提取特征
- 特征送入每一类的SVM(支持向量机)分类器,判断是否属于该类
- 使用回归器精细修正候选框位置

R-CNN的流程图如上图所示,输入原图像后,先使用SS方法在图像选中一千到两千个候选框,将这么多个候选框分别送入卷积神经网络提取图像特征,最后再经过SVM分类器判断是否属于该类(有多少类就设置多少个SVM,如图分三类就设置三个SVM分类器,每个SVM识别一类)。
1.2 R-CNN算法详解
1.2.1 候选区域的生成
前面提到SS方法生成候选框,通过图像分割的方法得到候选框选中的图像区域。然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,这些结构中就包含着可能需要的物体。

1.2.2 对每个候选区域,使用深度网络提取特征
将2000个候选区域统一缩放到227*227大小,接着将候选区域输入预训练好的AlexNet CNN网络获取4096维的特征得到2000*4096维矩阵。

1.2.3 特征送入每一类的SVM分类器,判定类别

将2000 * 4096维特征与20个SVM组成的权值矩阵4096*20相乘,获得2000 * 20维矩阵表示每个建议框是某个目标类别的得分。分别对上述2000 * 20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。

如图,左边2000 * 4096矩阵是两千个候选框通过卷积神经网络得到的两千个特征向量,再输入到20个SVM分类器中,每个SVM对应有一个4096维的权值矩阵,通过矩阵相乘后,最终得到了2000个候选框中每一个候选框对应20个类别的概率。
再经非极大值抑制剔除重叠建议框,文章引入 I o U IoU IoU方法,表示 ( A ⋂ B ) / ( A ⋃ B ) (A\bigcap B)/(A\bigcup B) (A⋂B)/(A⋃B)
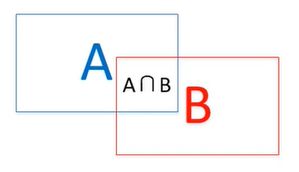
剔除候选框步骤如下:

剔除后效果如下:

1.2.4 使用回归器精细修正候选框位置
通过前面操作后,剔除了大量的候选框,这一步接着对候选框进一步筛选。分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。

如图,黄色框P表示建议框Region Proposal(即是我们前面通过非极大值抑制后得到的候选框),绿色窗口G表示真实框Ground Truth(真实框是人工先标注好的),红色窗口 G ^ \hat{G} G^表示Region Proposal进行回归后的预测窗口,可以用最小二乘法解决线性回归问题。
1.2.5 R-CNN整体框架

1.3 R-CNN存在的问题
-
测试速度慢:
测试一张图片约53秒(cpu)。用SS算法提取候选框用时2秒,一张图像内候选框之间存在大量重叠,提取特征操作冗余。 -
训练速度慢:
过程极其繁琐 -
训练所需空间大:
对于 SVM和bbox(bounding box)回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络,如VGG16,从VOCO7训练集上的5K图像上提取特征需要数百GB的存储空间。
2 Fast R-CNN
Fast R-CNN是作者Ross Girshick继R-CNN后的又一力作。同样使用VGG16作为网络的backbone,与R-CNN相比训练时间快9倍,测试推理时间快213倍,准确率从62%提升至66%(在Pascal VOC数据集上)。

2.1算法流程(可分为3个步骤)
- 一张图像生成1K~2K个候选区域(使用SS方法)
- 将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵(注意:这里与R-CNN不同的是,R-CNN分别将每个候选框放入CNN提取特征向量,而Fast R-CNN将整张图片放入CNN提取特征,再利用SS提取候选框的位置映射到特征图上,得到对应位置上的特征图,不需要对重叠区域进行重复计算,这一步改进大大节省了训练时间)
- 将每个特征矩阵通过ROI pooling层缩放到7*7大小的特征图,接着将特征图展平通过一系列全连接层,最终得到预测结果

2.2 实现过程
2.2.1 一次性计算整张图像特征
R-CNN依次将候选区域输入卷积神经网络得到特征。

Fast R-CNN将整张图像送入网络,紧接着从特征图像上提取相应的候选区域。这些候选区域的特征不需要再重复计算。

2.2.2 正、负样本采集
正样本:候选框与真实框 I o U IoU IoU值大于0.5,认定为正样本
负样本:候选框与真实框 I o U IoU IoU值在[0.1 , 0.5]之间,认定为负样本
【所以并不是使用SS算法提供的所有候选区域,而是随机采样了一部分进行训练】
为何要选取正负样本?
以猫狗分类器为例,如果训练数据中只有猫的图片,那显然是有问题的,因为它没有负样例,可能你放一只狗进去分类器也会识别为猫。在fate R-CNN中,如果没有负样例,网络可能会把一些图片的背景同样识别为物品,这显然不是我们想要的效果。
2.2.3 ROI Pooling Layer

单通道ROI Pooling Layer效果如上图,它将每幅特征图划分为77个区域,对每个区域进行max pooling操作,最后无论特征图多大,都统一缩到了77大小。
2.2.4 分类器
概率预测:输出N+1个类别的概率(N为检测目标的种类,1为背景)共N+1个节点
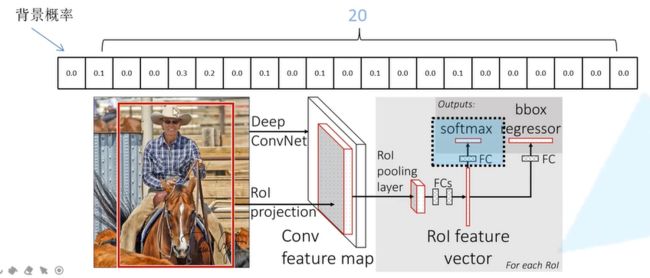
如图,在全局特征图中取得建议框选中的特征图,将特征图传入池化层(ROI Pooling)得到7*7缩放的特征图,再经过两个全连接层,将这个两个全连接层并联起来得到ROI feature vector,再分别经过一个全连接层,得到分类的概率预测和回归参数预测。

每个边界框回归参数对应四个参数,分别为中点坐标(X,Y)和长度、宽度。
2.2.5 边界框回归器
输出对应N+1个类别的候选框回归参数 ( d x , d y , d w , d h ) (d_x,d_y,d_w,d_h) (dx,dy,dw,dh),共 ( N + 1 ) × 4 (N+1)\times 4 (N+1)×4个节点。
P x , P y , P w , P h P_x,P_y,P_w,P_h Px,Py,Pw,Ph分别为候选框的中心x,y坐标以及宽高
G x ^ , G y ^ , G w ^ , G h ^ \hat{G_x},\hat{G_y},\hat{G_w},\hat{G_h} Gx^,Gy^,Gw^,Gh^分别为最终预测的边界框中心x,y坐标,以及宽高。
d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) d_x(P),d_y(P),d_w(P),d_h(P) dx(P),dy(P),dw(P),dh(P)表示基于候选框P的预测回归参数,也即是需要训练的参数。最终通过这个参数来调整候选框的位置,也就是从P调整到 G ^ \hat{G} G^的参数。


2.2.6 计算损失
模型的总损失由分类损失和边界框回归损失两部分加权求和,如下:

p是分类器预测的softmax概率分布 p = ( p 0 , . . . , p k ) p=(p_0,...,p_k) p=(p0,...,pk),分别代表背景和K个类别的概率
u对应目标真实类别标签
t u t^u tu对应边界框回归器预测的对应类别u的回归参数 ( t x u , t y u , t w u , t h u ) (t^u_x,t^u_y,t^u_w,t^u_h) (txu,tyu,twu,thu)
v对应真实目标的边界框回归参数 ( v x , v y , v w , v h ) (v_x,v_y,v_w,v_h) (vx,vy,vw,vh)

P u P_u Pu表示候选区域P预测为类别u的概率,此处损失函数为多分类损失的损失函数
边界框回归损失:

[ u ≥ 1 ] [u\geq 1] [u≥1]是艾弗森括号,当u大于等于1时等于1;u小于1时等于0,此时特征图代表负样本,无需考虑边界框损失
λ \lambda λ是平衡系数,用于平衡两个损失

t u t^u tu对应边界框回归器预测的对应类别u的回归参数 ( t x u , t y u , t w u , t h u ) (t^u_x,t^u_y,t^u_w,t^u_h) (txu,tyu,twu,thu)
v对应真实目标的边界框回归参数 ( v x , v y , v w , v h ) (v_x,v_y,v_w,v_h) (vx,vy,vw,vh)
( t u − v ) (t^u-v) (tu−v)计算预测回归参数和真实回归参数的差值,以训练预测的回归参数接近真实值
2.2.7 Fast R-CNN整体框架

2.3 Fast R-CNN存在的问题
Fast R-CNN相较于R-CNN而言,减少了很多候选区域的重叠计算,大大提升了训练速度,但是由于SS算法在一张图片生成1K~2K候选框还是需要耗时2秒左右,大大拖慢了目标检测速度,为了解决这一问题,作者又提出了Faster R-CNN
3 Faster R-CNN
3.1 Faster R-CNN算法流程(可分为3个步骤)
- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI pooling层缩放到7*7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
总的来说,Faster R-CNN = RPN + Fast R-CNN

Faster R-CNN的结构图如上,红线圈中区域其实与前面的Fast R-CNN一样,先提取特征图然后进行分类预测和回归参数预测。而Faster R-CNN加入了RPN来提取候选框,替换了SS算法,克服了提取候选框时间久的问题。
3.2 Faster R-CNN各部分实现
3.2.1 RPN结构
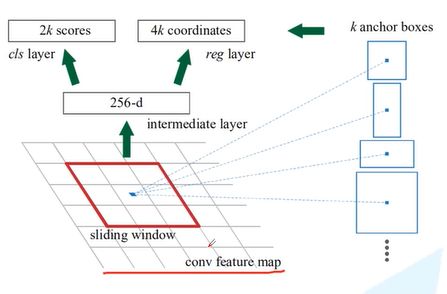
在全局特征图上有一个滑动窗,每一个sliding window会选中K个候选框,效果如下图所示。之后把特征图经过两个全连接层进行展平,得到intermediate layer,这里利用的是ZF网络也就是前面提到的backbone,深度为256,如果用VGG16网络,则这里深度为512。再分别送入分类器和回归器,得到分类概率和边界框回归参数。

3.2.2 RPN计算特征图的点对应原图的位置
如上图,红线相连的特征图要找到原图中对应点的位置,主要通过以下两条公式计算点的横纵坐标:
原 图 横 坐 标 = 原 图 宽 度 特 征 图 宽 度 × 特 征 图 离 左 侧 边 缘 的 格 数 原图横坐标=\frac{原图宽度}{特征图宽度}\times 特征图离左侧边缘的格数 原图横坐标=特征图宽度原图宽度×特征图离左侧边缘的格数
原 图 纵 坐 标 = 原 图 高 度 特 征 图 高 度 × 特 征 图 离 上 侧 边 缘 的 格 数 原图纵坐标=\frac{原图高度}{特征图高度}\times 特征图离上侧边缘的格数 原图纵坐标=特征图高度原图高度×特征图离上侧边缘的格数
3.2.3 RPN中的分类器和回归器
分类器针对每个anchor box生成两个概率,一个是前景概率,另一个是背景概率。(注意:这里概率只分为前景和背景两类,与前面20类不同)这里K个anchor box对应就会生成2K个概率。
回归器针对每个anchor box生成四个回归参数,分别是坐标和宽高。这里K个anchor box对应生成4K个回归参数。

3.2.4 RPN 中的anchor box 和sliding window
anchor box有三种尺度(面积) { 12 8 2 , 25 6 2 , 51 2 2 } \{128^2,256^2,512^2\} {1282,2562,5122}和三种比例 { 1 : 1 , 1 : 2 , 2 : 1 } \{1:1,1:2,2:1\} {1:1,1:2,2:1},不同的尺度和比例决定了anchor box的大小和形状,如下9个anchor box大小和形状各不相同。在faster R-CNN中,每一个sliding window在原图中对应有着这九个anchor box。

滑动窗口采用的是33的卷积,步长和填充为1,这样滑动窗口可以遍历图像的每一个点,其所得的shape与feature map一模一样。对于一张1000 * 600 * 3的图像,大约有6040*9(20K)个anchor,忽略跨越边界的anchor后,剩下约6K个anchor。对于RPN生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,IoU设为0.7,这样每张图片只剩下2K个候选框。

3.2.5 RPN正负样本的判定
作者的论文中从所有anchor中采样出256个样本,由正样本和负样本组成,比例为1:1。如果正样本个数不足128个,则用负样本进行填充。
正样本:只要anchor与真实的边界框IoU大于0.7,则选中这个anchor为正样本。或者anchor与真实边框有最大IoU,则也把这个anchor标为正样本(适用于所有IoU都小于0.7的情况)。
负样本:与所有真实框的IoU都小于0.3。
3.2.6 RPN损失函数

p i p_i pi表示第i个anchor预测为真实标签的概率
p i ∗ p_i^* pi∗当为正样本时为1,当为负样本时为0
t i t_i ti表示预测第i个anchor的边界框回归参数
t i ∗ t_i^* ti∗表示第i个anchor对应的真实边界框
N c l s N_{cls} Ncls表示一个mini-batch中的所有样本数量256
N r e g N_{reg} Nreg表示anchor位置的个数(不是anchor的个数)约2400,在实际的操作中通常用 1 N c l s \frac{1}{N_{cls}} Ncls1来代替后面的 λ 1 N r e g \lambda \frac{1}{N_{reg}} λNreg1
分类损失的计算:


虽然在RPN中,分类器只需要分类前景和背景两类,但原论文中使用的是多分类损失, p i p_i pi表示第i个anchor预测为真实标签的概率。

而在pytorch提供的faster R-CNN代码中使用的是二分类损失。

边界框回归损失的计算:



![]()


其中 t i , t i ∗ t_i,t_i^* ti,ti∗的求得方法,其实是前面介绍的求预测框公式反向推导而得,这里 t x t_x tx对应的就是下图中的 d x ( P ) d_x(P) dx(P)。
3.3 Faster R-CNN训练
直接采用【RPN Loss+Fast R-CNN Loss】的联合训练方法,Fast R-CNN Loss前面已经有介绍,这里就不重复介绍了。

3.4 Faster R-CNN整体框架

结语
到这里就把faster R-CNN介绍完了,建议视频和博客结合一起看,博客中有对视频进一步补充的内容,如果有不同想法,欢迎交流。