机器翻译——基于注意力机制的seq2seq结构
目录
- 前言
- 0、seq2seq结构介绍以及机器翻译整体流程介绍
-
- 0-1、seq2seq结构介绍
- 0-2、机器翻译整体流程介绍
- 一、导入所有需要的库
- 二、数据预处理
- 三、读取数据,创建Dataset。
- 四、文本向量化
- 五、创建训练集和验证集
- 六、相关参数设置
- 七、Encoder部分
- 八、BahdanauAttention部分
- 九、Decoder部分
- 总结
前言
该项目是一个基于注意力机制的seq2seq结构的由英语和西班牙语互译的项目,一共有11万对句子,文章中训练使用到的数据对为3万,可以根据个人机器配置灵活调整。
0、seq2seq结构介绍以及机器翻译整体流程介绍
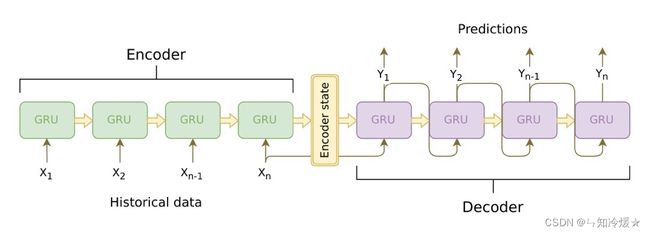
0-1、seq2seq结构介绍
seq2seq结构介绍:seq2seq模型是以编码(Encode)和解码(Decode)为代表的架构方式,seq2seq模型是根据输入序列X来生成输出序列Y,在翻译,文本自动摘要和机器人自动问答以及一些回归预测任务上有着广泛的运用。以encode和decode为代表的seq2seq模型,encode意思是将输入序列转化成一个固定长度的向量,decode意思是将输入的固定长度向量解码成输出序列。其中编码解码的方式可以是RNN,CNN、LSTM、GRU等。
缺点是:
1、定长编码是信息瓶颈
2、长度越长,前面输入RNN的信息就被越稀释。
0-2、机器翻译整体流程介绍
机器翻译整体流程介绍:
一、准备数据、数据预处理
1、加载数据
2、分割数据:因为数据集里西班牙语和英语在同一行里,需要切割开,一共有11万条数据。
3、数据处理:全部转化为小写、去掉首尾多余的空格、删除特殊字符、标点符号前后都要添加空格、给每个句子添加一个开始标记和结束标记。
4、数据id化:单词级别的数据id化,把一条句子转化为数字序列,并且后续做一个padding处理。
二、模型构建:
1、encoder构建:通过学习输入,将其编码成一个固定大小的中间状态向量,再将中间状态向量传递给decoder。这个过程称其为编码。
2、decoder构建:decoder通过对中间状态向量的学习来进行输出,得到输出序列,这个过程称其为解码。需要注意的是:中间状态向量只是作为初始状态参与decoder的构建,后面的运算都和中间状态向量无关。
3、attention机制的构建:
3-1、如果不引入attention机制的话,Encoder-Decoder结构在编码和解码阶段始终由一个中间状态向量来联系,这就造成了在编码阶段由于信息压缩到中间状态向量中而导致的部分信息丢失,在解码阶段时,在后边的序列容易丢失细节信息。
3-2、在编码阶段加入Attention模型,它不再要求编码器将所有输入信息都编码进一个固定长度的向量之中。此时编码器对源数据序列进行数据加权变换编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。
3-3、Bahdanau注意力公式:
EO: (Encoder_Output) encoder各个位置的输出。
H: (Hidden_State) decoder某一步的隐含状态。
FC: 全连接层
X: decoder的一个输入
score = FC(tanh(FC(EO)+FC(H)))
4、总结:加入了Attention机制以后,encoder不仅仅是把encoder最后一个节点的hidden state提供给decoder,而是提供了更多的数据给到了decoder,它采取了一种选择机制,把最符合的hidden state选出来,这就是注意力公式要干的事情。
三、损失、优化器:
四、train
五、评估
一、导入所有需要的库
sys.version_info: 用于返回你使用的python版本号,例子中表示输出的python版本是3.9.12
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import sklearn
import sys
import tensorflow as tf
import time
import unicodedata
import re
from sklearn.model_selection import train_test_split
from tensorflow import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
输出:
2.9.1
sys.version_info(major=3, minor=9, micro=12, releaselevel='final', serial=0)
matplotlib 3.5.1
numpy 1.21.2
pandas 1.1.5
sklearn 1.0.2
tensorflow 2.9.1
keras.api._v2.keras 2.9.0
二、数据预处理
unicodedata.category(unichr): 以字符串形式返回分配给Unicode字符unichr的常规类别。‘Mn’代表的是语气词类别,与数据处理无关,所以去掉。
unicodedata.normalize: 返回Unicode字符串unistr的常规表单形式。表单的有效值为’NFC’,‘NFKC’,‘NFD’和’NFKD’, 理解为标准化。
notice : 经过unicodedata.normalize返回的一个格式才可以被unicodedata.category所判断。
有关于正则表达式:正则表达式——re库的一些常用函数.
def unicode_to_ascii(s):
return ''.join(c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn')
en_sentence = u"May I borrow this book?"
sp_sentence = u"¿Puedo tomar prestado este libro?"
print(unicode_to_ascii(en_sentence))
print(unicode_to_ascii(sp_sentence))
def preprocess_sentence(w):
# 转换为小写,把字符串的头尾空格去掉
w = unicode_to_ascii(w.lower().strip())
# creating a space between a word and the punctuation following it
# eg: "he is a boy." => "he is a boy ."
# Reference:- https://stackoverflow.com/questions/3645931/python-padding-punctuation-with-white-spaces-keeping-punctuation
# 标点符号前后加空格
w = re.sub(r"([?.!,¿])", r" \1 ", w)
# 多余空格变成一个
w = re.sub(r'[" "]+', " ", w)
# 除了标点符号和字母外都变为空格
# replacing everything with space except (a-z, A-Z, ".", "?", "!", ",")
w = re.sub(r"[^a-zA-Z?.!,¿]+", " ", w)
# 去掉前后空格
w = w.rstrip().strip()
# adding a start and an end token to the sentence
# so that the model know when to start and stop predicting.
# 为句子加上开始和结束符号。
w = ' ' + w + ' '
return w
print(preprocess_sentence(en_sentence))
print(preprocess_sentence(sp_sentence).encode('utf-8'))
输出:
May I borrow this book?
¿Puedo tomar prestado este libro?
may i borrow this book ?
b' \xc2\xbf puedo tomar prestado este libro ? '
三、读取数据,创建Dataset。
数据集:数据集为英语转化为西班牙语,如下所示。(左边英语,右边西班牙语)
Grab Tom. Sujeta a Tom.
Grab him. Agárralo.
Have fun. Diviértanse.
Have fun. Pásala bien.
Have fun. Pásenla bien.
data_path = './data_spa_en/spa.txt'
# 1. Remove the accents
# 2. Clean the sentences
# 3. Return word pairs in the format: [ENGLISH, SPANISH]
def create_dataset(path, num_examples):
"""
path: 数据源的路径。
num_examples: 样本例子数量,如果没有指定
"""
# 打开数据源,编码方式必须为UTF-8.去除前后空格,以换行符划分。
# 返回值是列表,英语和西班牙语之间以制表符划分
lines = open(path, encoding='UTF-8').read().strip().split('\n')
# 遍历,按照\t,即tab键代表的字符来进行划分,之后进行数据的预处理。
word_pairs = [[preprocess_sentence(w) for w in l.split('\t')] for l in lines[:num_examples]]
# 返回值是一个二维列表每一个元素是[' go . ' , ' ve . ' ]这种格式
# 解包,将数据预处理之后的英语和西班牙语分割成为两个列表
return zip(*word_pairs)
en, sp = create_dataset(data_path, None)
print(en[-1])
print(sp[-1])
输出:
if you want to sound like a native speaker , you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo .
si quieres sonar como un hablante nativo , debes estar dispuesto a practicar diciendo la misma frase una y otra vez de la misma manera en que un musico de banjo practica el mismo fraseo una y otra vez hasta que lo puedan tocar correctamente y en el tiempo esperado .
四、文本向量化
tf.keras.preprocessing.text.Tokenizer: 将文本向量化,或将文本转换为序列(即单个字词以及对应下标构成的列表,从1开始)的类。调用即实例化Tokenizer类。
fit_on_texts:使用分词器(Tokenizer类)来训练文本。训练之后就可以用分词器把对应文本转化为张量。
texts_to_sequences:返回文本对应的序列列表。将对应文本转化为张量。
tf.keras.preprocessing.sequence.pad_sequences:将序列转化为经过填充以后得到的一个长度相同新的序列。
参数:padding,为pre或post,确定当需要补0时,在序列的起始还是结尾补。
def max_length(tensor):
return max(len(t) for t in tensor)
def tokenize(lang):
lang_tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='')
lang_tokenizer.fit_on_texts(lang)
tensor = lang_tokenizer.texts_to_sequences(lang)
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor, padding='post')
return tensor, lang_tokenizer
def load_dataset(path, num_examples=None):
# creating cleaned input, output pairs
# 创建Dataset,返回数据预处理之后的英语和西班牙语的两个列表
targ_lang, inp_lang = create_dataset(path, num_examples)
input_tensor, inp_lang_tokenizer = tokenize(inp_lang)
target_tensor, targ_lang_tokenizer = tokenize(targ_lang)
return input_tensor, target_tensor, inp_lang_tokenizer, targ_lang_tokenizer
# Try experimenting with the size of that dataset
num_examples = 30000
# 这里取30000条数据来进行训练
input_tensor, target_tensor, inp_lang, targ_lang = load_dataset(data_path, num_examples)
# Calculate max_length of the target tensors
max_length_targ, max_length_inp = max_length(target_tensor), max_length(input_tensor)
# 11、16
print('input_tensor: ', input_tensor[:5])
print('target_tensor: ', target_tensor[:5])
print('inp_lang_dictionary: ', inp_lang.word_index)
输出:
input_tensor:
[[ 1 135 3 2 0 0 0 0 0 0 0 0 0 0
0 0]
[ 1 293 3 2 0 0 0 0 0 0 0 0 0 0
0 0]
[ 1 595 3 2 0 0 0 0 0 0 0 0 0 0
0 0]
[ 1 1428 3 2 0 0 0 0 0 0 0 0 0 0
0 0]
[ 1 766 3 2 0 0 0 0 0 0 0 0 0 0
0 0]]
target_tensor:
[[ 1 36 3 2 0 0 0 0 0 0 0]
[ 1 36 3 2 0 0 0 0 0 0 0]
[ 1 36 3 2 0 0 0 0 0 0 0]
[ 1 36 3 2 0 0 0 0 0 0 0]
[ 1 679 3 2 0 0 0 0 0 0 0]]
inp_lang_dictionary:
{'': 1, '': 2, '.': 3, 'tom': 4, '?': 5, '¿': 6, 'es': 7, 'no': 8, 'el': 9, 'a': 10, 'que': 11, 'me': 12, 'la': 13, 'de': 14, 'un': 15, 'esta': 16, 'se': 17, 'lo': 18, 'mi': 19, 'en': 20, 'una': 21, 'por': 22, 'te': 23, 'estoy': 24, 'ella': 25, 'yo': 26, '!': 27, 'eso': 28, 'le': 29, 'esto': 30, 'tu': 31, ',': 32, 'los': 33, 'aqui': 34, 'soy': 35, 'muy': 36, 'tengo': 37, 'puedo': 38, 'las': 39, 'gusta': 40, 'mary': 41, 'tiene': 42, 'son': 43.......................................}
五、创建训练集和验证集
# ex: 分割训练集和验证集,验证集比例占0.2
input_tensor_train, input_tensor_val, target_tensor_train, target_tensor_val = train_test_split(input_tensor, target_tensor, test_size=0.2)
def convert(lang, tensor):
"""
将tensor转化为对应的英文单词,0除外。
"""
for t in tensor:
if t != 0:
print ("%d ----> %s" % (t, lang.index_word[t]))
print("Input Language; index to word mapping")
convert(inp_lang, input_tensor_train[0])
print()
print("Target Language; index to word mapping")
convert(targ_lang, target_tensor_train[0])
输出:
Input Language; index to word mapping
1 ---->
287 ----> sigue
603 ----> corriendo
3 ----> .
2 ---->
Target Language; index to word mapping
1 ---->
111 ----> keep
378 ----> running
3 ----> .
2 ---->
六、相关参数设置
tf.data.Dataset.from_tensor_slices:将输入张量和目标张量混合为一个TensorSliceDataset对象,把输入和目标对应,即切片操作。
shuffle: 对from_tensor_slices处理的数据,进行混合,混合就是打乱原数组之间的顺序,数组的数据大小和内容并没有改变;
混合的数据越大,混合程度越高。
dataset.batch: 对shuffle处理后的数据进行打包,如果为1,则数据内容和格式跟shuffle的数据相同,相当于没有处理,即对数据打包,便于后续批量处理。
iter(): 函数用来生成迭代器。
next(): 返回迭代器的下一个项目。
# 24000条训练数据
BUFFER_SIZE = len(input_tensor_train)
BATCH_SIZE = 64
# 每一批次训练375条数据
steps_per_epoch = len(input_tensor_train)//BATCH_SIZE
# embedding维度设置为256
embedding_dim = 256
# 神经网络单元设置为1024
units = 1024
# 词典长度为9413
vocab_inp_size = len(inp_lang.word_index)+1
# 词典长度为4934
vocab_tar_size = len(targ_lang.word_index)+1
# 切片打包
dataset = tf.data.Dataset.from_tensor_slices((input_tensor_train, target_tensor_train)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
# 展示一个样例批次。
example_input_batch, example_target_batch = next(iter(dataset))
example_input_batch, example_target_batch
输出:
(,
)
七、Encoder部分
python特殊函数__call__(self): 可以使用,类对象(参数)来直接调用call函数。当然也可以使用普通调用,类对象.call(参数)来调用call方法。
tf.keras.layers.Embedding
(input_dim,
output_dim,
embeddings_initializer=‘uniform’,
embeddings_regularizer=None,
activity_regularizer=None,
embeddings_constraint=None,
mask_zero=False,
input_length=None,
**kwargs)
tf.keras.layers.Embedding: 嵌入层主要负责将一个特征转换成一个向量。将单词序列转化成一个向量,便于数据的处理。例子中Embedding层的作用就是把向量中每一个标签值映射为一个256维向量,这样就可以用一个256维向量来表示一个单词。input_dim表示词汇量的大小,即之前的变量vocab_inp_size,还有一个常用的参数input_length,这个参数用来规定输入的单词序列的长度,如果单词序列长度为30个,那么这个参数的值就应该设置为30。如果没有设置参数input_length,那么输入序列的长度可以改变。
注意:Embedding层输入是一个二维张量,形状为(batch_size, input_length),输出形状为(batch_size, input_length, output_dim),是一个三维张量。
tf.keras.layers.GRU(
units, activation=‘tanh’, recurrent_activation=‘sigmoid’,
use_bias=True, kernel_initializer=‘glorot_uniform’,
recurrent_initializer=‘orthogonal’,
bias_initializer=‘zeros’, kernel_regularizer=None,
recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, recurrent_constraint=None, bias_constraint=None,
dropout=0.0, recurrent_dropout=0.0, return_sequences=False, return_state=False,
go_backwards=False, stateful=False, unroll=False, time_major=False,
reset_after=True, **kwargs
)
tf.keras.layers.GRU:
常用参数介绍:
units 正整数,输出空间的维度。
return_sequences 布尔值。是返回输出序列中的最后一个输出还是完整序列。默认值: False 。return_sequences默认为False,即只返回最后一个单元的output。
return_state 布尔值。除输出外,是否返回最后一个状态。默认值: False 。
recurrent_initializer recurrent_kernel 权重矩阵的初始化程序,用于递归状态的线性转换。
class Encoder(tf.keras.Model):
"""
定义Encoder类。
初始化隐藏状态, 隐层初始化为(64,1024)的0矩阵
"""
def __init__(self, vocab_size, embedding_dim, encoding_units, batch_size):
super(Encoder, self).__init__()
# 64、1024、
self.batch_size = batch_size
self.encoding_units = encoding_units
# 实例化embedding。
self.embedding = keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = keras.layers.GRU(self.encoding_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, x, hidden):
x = self.embedding(x)
output, state = self.gru(x, initial_state = hidden)
return output, state
def initialize_hidden_state(self):
#
return tf.zeros((self.batch_size, self.encoding_units))
# vocab_size,词典长度为9413,embedding维度设置为256,神经网络单元设置为1024,
encoder = Encoder(vocab_inp_size, embedding_dim, units, BATCH_SIZE)
sample_hidden = encoder.initialize_hidden_state()
sample_output, sample_hidden = encoder(example_input_batch, sample_hidden)
print('Encoder output shape: (batch size, sequence length, units) {}'.format(sample_output.shape))
print('Encoder Hidden state shape: (batch size, units) {}'.format(sample_hidden.shape))
print('sample_hidden: ', sample_hidden)
输出:
Encoder output shape: (batch size, sequence length, units) (64, 16, 1024)
Encoder Hidden state shape: (batch size, units) (64, 1024)
sample_hidden: tf.Tensor(
[[ 0.00788676 -0.01040656 0.01343848 ... -0.01719056 -0.00481622
0.00266501]
[ 0.00808515 -0.01035669 0.01346539 ... -0.01728923 -0.00475897
0.00262072]
[ 0.00797403 -0.01035444 0.01340555 ... -0.01723078 -0.00478959
0.00261864]
...
[ 0.00789879 -0.01038888 0.01343339 ... -0.017216 -0.00482771
0.00266448]
[ 0.0081946 -0.0103415 0.01352166 ... -0.01729597 -0.00472772
0.00260748]
[ 0.00801533 -0.01033554 0.01345733 ... -0.01728254 -0.00472484
0.00259217]], shape=(64, 1024), dtype=float32)
八、BahdanauAttention部分
输出:
九、Decoder部分
输出:
参考文章:
Seq2Seq系列(一):基于神经网络的高维时间序列预测.
Seq2Seq原理详解 .
Seq2Seq模型介绍 .
Seq2Seq 模型详解 .