kubernetes安全:RBAC,Security Context,PSP,准入控制器
文章目录
- RBAC 权限控制前言
-
- API 对象
- RBAC
-
- 只能访问某个 namespace 的普通用户
-
- 创建用户凭证
- 创建角色
- 创建角色权限绑定
- 测试
- 只能访问某个 namespace 的 ServiceAccount
- 可以全局访问的 ServiceAccount
- Security Context
-
- 为 Pod 设置 Security Context
- 为容器设置 Security Context
- 设置 Linux Capabilities
-
- 什么是 Capabilities
- 如何使用 Capabilities
- Docker Container Capabilities
- Kubernetes 配置 Capabilities
- 为容器设置 SELinux 标签
- pod安全策略(官网已经弃用,推荐使用PodSeurityAdmission)
-
- Admission Controller
- ServiceAccount Controller Manager
- 策略
- RBAC
- group解释
- 特定应用的 ServiceAccount
- 静态 Pod
- 准入控制器
-
- admission webhook 是什么?
- 创建配置一个 Admission Webhook
- 编写 webhook
- 构建
- 部署
- 测试
- 部署 mutating webhook
RBAC 权限控制前言
前面我们已经学习一些常用的资源对象的使用,我们知道对于资源对象的操作都是通过 APIServer 进行的,那么集群是怎样知道我们的请求就是合法的请求呢?(请求一般是http,包含说明发出请求的身份想要干什么,如果是pod发出的请求,首先是用token认证了pod在集群中的身份,然后就是判断这个pod身份想要进行的操作是否有这个权限)这个就需要了解 Kubernetes 中另外一个非常重要的知识点了:RBAC(基于角色的权限控制)。
管理员可以通过 Kubernetes API 动态配置策略来启用RBAC,需要在 kube-apiserver 中添加参数**–authorization-mode=RBAC**,如果使用的 kubeadm 安装的集群那么是默认开启了 RBAC 的,可以通过查看 Master 节点上 apiserver 的静态 Pod 定义文件:
$ cat /etc/kubernetes/manifests/kube-apiserver.yaml
...
- --authorization-mode=Node,RBAC
...
如果是二进制的方式搭建的集群,添加这个参数过后,记得要重启 kube-apiserver 服务
API 对象
在学习 RBAC 之前,我们还需要再去理解下 Kubernetes 集群中的对象,我们知道,在 Kubernetes 集群中,Kubernetes 对象是我们持久化的实体,就是最终存入 etcd 中的数据,集群中通过这些实体来表示整个集群的状态。前面我们都直接编写的 YAML 文件,通过 kubectl 来提交的资源清单文件,然后创建的对应的资源对象,那么它究竟是如何将我们的 YAML 文件转换成集群中的一个 API 对象的呢?
这个就需要去了解下声明式 API的设计,Kubernetes API 是一个以 JSON 为主要序列化方式的 HTTP 服务,除此之外也支持 Protocol Buffers 序列化方式,主要用于集群内部组件间的通信。为了可扩展性,Kubernetes 在不同的 API 路径(比如/api/v1 或者 /apis/batch)下面支持了多个 API 版本,不同的 API 版本意味着不同级别的稳定性和支持:
Alpha 级别,例如 v1alpha1 默认情况下是被禁用的,可以随时删除对功能的支持,所以要慎用
Beta 级别,例如 v2beta1 默认情况下是启用的,表示代码已经经过了很好的测试,但是对象的语义可能会在随后的版本中以不兼容的方式更改
稳定级别,比如 v1 表示已经是稳定版本了,也会出现在后续的很多版本中。
在 Kubernetes 集群中,一个 API 对象在 Etcd 里的完整资源路径,是由:**Group(API 组)、Version(API 版本)和 Resource(API 资源类型)**三个部分组成的。通过这样的结构,整个 Kubernetes 里的所有 API 对象,实际上就可以用如下的树形结构表示出来:
变成里边也有声明式这个概念,常规的编程比如你让一个人去超市帮你干烧牛筋,你告诉他要出门,然后走那条路,坐电梯到负一楼,到哪块区买干烧牛筋,声明式就是告诉他去超市买干烧牛筋,至于怎么去就不管了,也就是不注重过程

从上图中我们也可以看出 Kubernetes 的 API 对象的组织方式,在顶层,我们可以看到有一个核心组(由于历史原因,是 /api/v1 下的所有内容而不是在 /apis/core/v1 下面)和命名组(路径 /apis/$NAME/$VERSION)和系统范围内的实体,比如 /metrics
查看集群中的 API 组织形式
raw未加工的,真实的
[root@master docker]# kubectl get --raw /
{
"paths": [
"/.well-known/openid-configuration",
"/api",
"/api/v1",
"/apis",
"/apis/",
"/apis/admissionregistration.k8s.io",
"/apis/admissionregistration.k8s.io/v1",
"/apis/admissionregistration.k8s.io/v1beta1",
"/apis/apiextensions.k8s.io",
"/apis/apiextensions.k8s.io/v1",
"/apis/apiextensions.k8s.io/v1beta1",
"/apis/apiregistration.k8s.io",
"/apis/apiregistration.k8s.io/v1",
"/apis/apiregistration.k8s.io/v1beta1",
"/apis/apps",
"/apis/apps/v1",
"/apis/authentication.k8s.io",
"/apis/authentication.k8s.io/v1",
"/apis/authentication.k8s.io/v1beta1",
"/apis/authorization.k8s.io",
"/apis/authorization.k8s.io/v1",
"/apis/authorization.k8s.io/v1beta1",
"/apis/autoscaling",
"/apis/autoscaling/v1",
"/apis/autoscaling/v2beta1",
"/apis/autoscaling/v2beta2",
"/apis/batch",
"/apis/batch/v1",
"/apis/batch/v1beta1",
"/apis/certificates.k8s.io",
"/apis/certificates.k8s.io/v1",
"/apis/certificates.k8s.io/v1beta1",
"/apis/coordination.k8s.io",
"/apis/coordination.k8s.io/v1",
"/apis/coordination.k8s.io/v1beta1",
"/apis/discovery.k8s.io",
"/apis/discovery.k8s.io/v1beta1",
"/apis/events.k8s.io",
"/apis/events.k8s.io/v1",
"/apis/events.k8s.io/v1beta1",
"/apis/extensions",
"/apis/extensions/v1beta1",
"/apis/flowcontrol.apiserver.k8s.io",
"/apis/flowcontrol.apiserver.k8s.io/v1beta1",
"/apis/networking.k8s.io",
"/apis/networking.k8s.io/v1",
"/apis/networking.k8s.io/v1beta1",
"/apis/node.k8s.io",
"/apis/node.k8s.io/v1",
"/apis/node.k8s.io/v1beta1",
"/apis/policy",
"/apis/policy/v1beta1",
"/apis/rbac.authorization.k8s.io",
"/apis/rbac.authorization.k8s.io/v1",
"/apis/rbac.authorization.k8s.io/v1beta1",
"/apis/scheduling.k8s.io",
"/apis/scheduling.k8s.io/v1",
"/apis/scheduling.k8s.io/v1beta1",
"/apis/storage.k8s.io",
"/apis/storage.k8s.io/v1",
"/apis/storage.k8s.io/v1beta1",
"/healthz",
"/healthz/autoregister-completion",
"/healthz/etcd",
"/healthz/log",
"/healthz/ping",
"/healthz/poststarthook/aggregator-reload-proxy-client-cert",
"/healthz/poststarthook/apiservice-openapi-controller",
"/healthz/poststarthook/apiservice-registration-controller",
"/healthz/poststarthook/apiservice-status-available-controller",
"/healthz/poststarthook/bootstrap-controller",
"/healthz/poststarthook/crd-informer-synced",
"/healthz/poststarthook/generic-apiserver-start-informers",
"/healthz/poststarthook/kube-apiserver-autoregistration",
"/healthz/poststarthook/priority-and-fairness-config-consumer",
"/healthz/poststarthook/priority-and-fairness-config-producer",
"/healthz/poststarthook/priority-and-fairness-filter",
"/healthz/poststarthook/rbac/bootstrap-roles",
"/healthz/poststarthook/scheduling/bootstrap-system-priority-classes",
"/healthz/poststarthook/start-apiextensions-controllers",
"/healthz/poststarthook/start-apiextensions-informers",
"/healthz/poststarthook/start-cluster-authentication-info-controller",
"/healthz/poststarthook/start-kube-aggregator-informers",
"/healthz/poststarthook/start-kube-apiserver-admission-initializer",
"/livez",
"/livez/autoregister-completion",
"/livez/etcd",
"/livez/log",
"/livez/ping",
"/livez/poststarthook/aggregator-reload-proxy-client-cert",
"/livez/poststarthook/apiservice-openapi-controller",
"/livez/poststarthook/apiservice-registration-controller",
"/livez/poststarthook/apiservice-status-available-controller",
"/livez/poststarthook/bootstrap-controller",
"/livez/poststarthook/crd-informer-synced",
"/livez/poststarthook/generic-apiserver-start-informers",
"/livez/poststarthook/kube-apiserver-autoregistration",
"/livez/poststarthook/priority-and-fairness-config-consumer",
"/livez/poststarthook/priority-and-fairness-config-producer",
"/livez/poststarthook/priority-and-fairness-filter",
"/livez/poststarthook/rbac/bootstrap-roles",
"/livez/poststarthook/scheduling/bootstrap-system-priority-classes",
"/livez/poststarthook/start-apiextensions-controllers",
"/livez/poststarthook/start-apiextensions-informers",
"/livez/poststarthook/start-cluster-authentication-info-controller",
"/livez/poststarthook/start-kube-aggregator-informers",
"/livez/poststarthook/start-kube-apiserver-admission-initializer",
"/logs",
"/metrics",
"/openapi/v2",
"/openid/v1/jwks",
"/readyz",
"/readyz/autoregister-completion",
"/readyz/etcd",
"/readyz/informer-sync",
"/readyz/log",
"/readyz/ping",
"/readyz/poststarthook/aggregator-reload-proxy-client-cert",
"/readyz/poststarthook/apiservice-openapi-controller",
"/readyz/poststarthook/apiservice-registration-controller",
"/readyz/poststarthook/apiservice-status-available-controller",
"/readyz/poststarthook/bootstrap-controller",
"/readyz/poststarthook/crd-informer-synced",
"/readyz/poststarthook/generic-apiserver-start-informers",
"/readyz/poststarthook/kube-apiserver-autoregistration",
"/readyz/poststarthook/priority-and-fairness-config-consumer",
"/readyz/poststarthook/priority-and-fairness-config-producer",
"/readyz/poststarthook/priority-and-fairness-filter",
"/readyz/poststarthook/rbac/bootstrap-roles",
"/readyz/poststarthook/scheduling/bootstrap-system-priority-classes",
"/readyz/poststarthook/start-apiextensions-controllers",
"/readyz/poststarthook/start-apiextensions-informers",
"/readyz/poststarthook/start-cluster-authentication-info-controller",
"/readyz/poststarthook/start-kube-aggregator-informers",
"/readyz/poststarthook/start-kube-apiserver-admission-initializer",
"/readyz/shutdown",
"/version"
]
}
比如我们来查看批处理这个操作,在我们当前这个版本中存在两个版本的操作:/apis/batch/v1 和 /apis/batch/v1beta1,分别暴露了可以查询和操作的不同实体集合,同样我们还是可以通过 kubectl 来查询对应对象下面的数据:
$ kubectl get --raw /apis/batch/v1 | python -m json.tool
{
"apiVersion": "v1",
"groupVersion": "batch/v1",
"kind": "APIResourceList",
"resources": [
{
"categories": [
"all"
],
"kind": "Job",
"name": "jobs",
"namespaced": true,
"singularName": "",
"storageVersionHash": "mudhfqk/qZY=",
"verbs": [
"create",
"delete",
"deletecollection",
"get",
"list",
"patch",
"update",
"watch"
]
},
{
"kind": "Job",
"name": "jobs/status",
"namespaced": true,
"singularName": "",
"verbs": [
"get",
"patch",
"update"
]
}
]
}
python -m json.tool格式化json文件
但是这个操作和我们平时操作 HTTP 服务的方式不太一样,这里我们可以通过 kubectl proxy 命令来开启对 apiserver 的访问:
$ kubectl proxy
Starting to serve on 127.0.0.1:8001
可以--port=端口号来指定端口
访问批处理的 API 服务:
$ curl http://127.0.0.1:8001/apis/batch/v1
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "batch/v1",
"resources": [
{
"name": "jobs",
"singularName": "",
"namespaced": true,
"kind": "Job",
"verbs": [
"create",
"delete",
"deletecollection",
"get",
"list",
"patch",
"update",
"watch"
],
"categories": [
"all"
],
"storageVersionHash": "mudhfqk/qZY="
},
{
"name": "jobs/status",
"singularName": "",
"namespaced": true,
"kind": "Job",
"verbs": [
"get",
"patch",
"update"
]
}
]
}
通常,Kubernetes API 支持通过标准 HTTP POST、PUT、DELETE 和 GET 在指定 PATH 路径上创建、更新、删除和检索操作,并使用 JSON 作为默认的数据交互格式。
比如现在我们要创建一个 Deployment 对象,那么我们的 YAML 文件的声明就需要怎么写:
apiVersion: apps/v1
kind: Deployment
其中 Deployment 就是这个 API 对象的资源类型(Resource),apps 就是它的组(Group),v1 就是它的版本(Version)。API Group、Version 和 资源就唯一定义了一个 HTTP 路径,然后在 kube-apiserver 端对这个 url 进行了监听,然后把对应的请求传递给了对应的控制器进行处理而已,当然在 Kuberentes 中的实现过程是非常复杂的。
RBAC
role base access control
基于角色的访问控制,角色其实就是一系列的权限
Kubernetes 所有资源对象都是模型化的 API 对象,允许执行 CRUD(Create、Read、Update、Delete) 操作(也就是我们常说的增、删、改、查操作),比如下面的这些资源:
Pods
ConfigMaps
Deployments
Nodes
Secrets
Namespaces
…
对于上面这些资源对象的可能存在的操作有:
create
get
delete
list
update
edit
watch
exec
patch
在更上层,这些资源和 API Group 进行关联,比如 Pods 属于 Core API Group,而 Deployements 属于 apps API Group,现在我们要在 Kubernetes 中通过 RBAC 来对资源进行权限管理,除了上面的这些资源和操作以外,我们还需要了解另外几个概念:
Rule:规则,规则是一组属于不同 API Group 资源上的一组操作的集合
Role 和ClusterRole:角色和集群角色,这两个对象都包含上面的 Rules 元素,二者的区别在于,在 Role中,定义的规则只适用于单个命名空间,也就是和 namespace 关联的,而 ClusterRole是集群范围内的,因此定义的规则不受命名空间的约束。另外 Role 和 ClusterRole 在Kubernetes 中都被定义为集群内部的API 资源,和我们前面学习过的 Pod、Deployment 这些对象类似,都是我们集群的资源对象,所以同样的可以使用 YAML文件来描述,用 kubectl 工具来管理
Subject:主题,对应集群中尝试操作的对象
集群中定义了3种类型的主题资源:
User Account:用户,这是有外部独立服务进行管理的,管理员进行私钥的分配,用户可以使用 KeyStone 或者 Goolge帐号,甚至一个用户名和密码的文件列表也可以。对于用户的管理集群内部没有一个关联的资源对象,所以用户不能通过集群内部的 API 来进行管理
Group:组,这是用来关联多个账户的,集群中有一些默认创建的组,比如 cluster-admin
Service Account:服务帐号,通过 Kubernetes API 来管理的一些用户帐号,和 namespace进行关联的,适用于集群内部运行的应用程序,需要通过 API 来完成权限认证,所以在集群内部进行权限操作,我们都需要使用到ServiceAccount,这也是我们这节课的重点
RoleBinding 和 ClusterRoleBinding:角色绑定和集群角色绑定,简单来说就是把声明的 Subject 和我们的 Role进行绑定的过程(给某个用户绑定上操作的权限),二者的区别也是作用范围的区别:RoleBinding 只会影响到当前 namespace下面的资源操作权限,而 ClusterRoleBinding 会影响到所有的 namespace。
api-server是一切集群操作的入口,集群内部的应用程序一般用service account,想要操作集群内的资源,会发送http请求到(请求头有各种的)api-server,api-server会判断该service account是否有对应的操作权限
只能访问某个 namespace 的普通用户
我们想要创建一个 User Account,只能访问 kube-system 这个命名空间,对应的用户信息如下所示:
username: cnych
group: youdianzhishi
创建用户凭证
我们前面已经提到过,Kubernetes 没有 User Account 的 API 对象,不过要创建一个用户帐号的话也是挺简单的,利用管理员分配给你的一个私钥就可以创建了,使用 OpenSSL 证书来给用户 cnych 创建一个私钥,命名成 cnych.key:
$ openssl genrsa -out cnych.key 2048
Generating RSA private key, 2048 bit long modulus
..............................................................................+++
..............................................................................................................................................+++
e is 65537 (0x10001)
使用我们刚刚创建的私钥创建一个证书签名请求文件(证书请求文件csr中要有公钥,公钥由私钥可以推出):cnych.csr,要注意需要确保在-subj参数中指定用户名和组(CN表示用户名,O表示组):
$ openssl req -new -key cnych.key -out cnych.csr -subj "/CN=cnych/O=youdianzhishi"
然后找到我们的 Kubernetes 集群的 CA 证书,我们使用的是 kubeadm 安装的集群,CA 相关证书位于 /etc/kubernetes/pki/ 目录下面,如果你是二进制方式搭建的,你应该在最开始搭建集群的时候就已经指定好了 CA 的目录,我们会利用该目录下面的 ca.crt 和 ca.key两个文件来批准上面的证书请求
$ openssl x509 -req -in cnych.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out cnych.crt -days 500
Signature ok
subject=/CN=cnych/O=youdianzhishi
Getting CA Private Key
serial序列号
使用刚刚创建的证书文件和私钥文件在集群中创建新的凭证和上下文(Context)
$ kubectl config set-credentials cnych --client-certificate=cnych.crt --client-key=cnych.key
User "cnych" set.
credential凭证
我们可以看到一个用户 cnych 创建了,然后为这个用户设置新的 Context,我们这里指定特定的一个 namespace
$ kubectl config set-context cnych-context --cluster=kubernetes --namespace=kube-system --user=cnych
Context "cnych-context" created.
到这里,我们的用户 cnych 就已经创建成功了,现在我们使用当前的这个配置文件来操作 kubectl 命令的时候,即这个用这个用户凭证和用户上下文来操作集群资源,应该会出现错误,因为我们还没有为该用户定义任何操作的权限
$ kubectl get pods --context=cnych-context
Error from server (Forbidden): pods is forbidden: User "cnych" cannot list resource "pods" in API group "" in the namespace "kube-system"
user account不是kubernetes自带的api资源,要创建个用于kubernetes的用户凭证,需要先用openssl生成用户的私钥,再将包含用户的公钥和用户的用户名和组信息的证书请求文件给kubernetes的CA证书签名得到证书文件,再用kubectl config set-credentials生成用于集群的用户凭证即用户,然后用kubectl config set-context为这个用户创建用户上下文,其中指定clusters和user和namespace
clusters指定的是集群
[root@master ~]# kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.23.178:6443
name: kubernetes #集群名称
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
[root@master ~]# cat ~/.kube/config
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUM1ekNDQWMrZ0F3SUJBZ0lCQURBTkJna3Foa2lHOXcwQkFRc0ZBREFWTVJNd0VRWURWUVFERXdwcmRXSmwKY201bGRHVnpNQjRYRFRJeU1EUXhNekUxTURReU5sb1hEVE15TURReE1ERTFNRFF5Tmxvd0ZURVRNQkVHQTFVRQpBeE1LYTNWaVpYSnVaWFJsY3pDQ0FTSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnRVBBRENDQVFvQ2dnRUJBTmg1ClNHVHRHV051VlRNQ05BV2pudE5XUC9NTS90RG1LTnNtL08zYjFlK3U3YmJkbG03WjFQQ3RDQmdILzdSSDZGS0QKQ24rOFVzNHp6d0VXRVhWUnF3cmJZaURxaG5tUnN3N2IycWpVVENtUzRsK0grdEdLd0pSenhxMjVyNVM4UFFJNwpIcWRYaWZKUHoyU3JIM0RLc1VqL2lXNHROY01kSktqdXpzcXkxdWlWYU40blovd1pmWUF1Vms0bmY5R1ZEMDAxCkRpYlU5bTByYzhaWVpMQUZZQnhNVTBNV05Vc1kwUnhGamFMK0NtSXl6QXMySnRaUC9ubjNTT25ZRndlaDdhekQKcmlKaEJpTXhlTmNUUzRWbGtzTGsyaTN0S29zM1VzL2pWTVFIUExaeGNEVWVGeUs2bXRpWTczK05mTVNTNHFlVQpVcjhFdXd3VHpMdXo3NFdlU1hFQ0F3RUFBYU5DTUVBd0RnWURWUjBQQVFIL0JBUURBZ0trTUE4R0ExVWRFd0VCCi93UUZNQU1CQWY4d0hRWURWUjBPQkJZRUZLWkRaOHJNZDZtS3JaVmVMRnFXY3lhWEdxRTBNQTBHQ1NxR1NJYjMKRFFFQkN3VUFBNElCQVFBaVZ4RmJqaGQvL1JaTVpPTnlYcWVDT2t0c09uNHNjZW4wR0M1aWdXZzNsOENleGNNZQpEMHptZEpMYWlvblVqOFFIUUVTV0YzWW9BZmErNzdaVklRVUdZT3hCb0trTTdtOFFSUVlKbXF0ZWdHb0E3VVBxCnBOUEc5SHU0Q3pRTWF0VHl0NTNhTklJM3MyVktta1p2eEpoUTVOZi9DSzZlL0gyK2pkT2YzT05RRE0wUEFjdkQKZVpQRVlySGcrbGozVUpWc2xGbUFrbWtFMnRzV2RIcVhreFhNQ0tOMFFueGJaME45Tk0zSTdnbmF5Nk5JSThncgpGdlRwUUg4OTVia1NQOTdUUVJ1enE2NFBVQTRhNGpKZEhqbW95bWRYdnB6T01TVWNpYUFadElzSEJFUGxhYUVZCkZnTTV4VUZqVFkyUWswQldwY0pWcTd0czdjSXVwcUxvMjNPZQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==
server: https://192.168.23.178:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURFekNDQWZ1Z0F3SUJBZ0lJYytoN0g5Ky9BcEl3RFFZSktvWklodmNOQVFFTEJRQXdGVEVUTUJFR0ExVUUKQXhNS2EzVmlaWEp1WlhSbGN6QWVGdzB5TWpBME1UTXhOVEEwTWpaYUZ3MHlNekEwTVRNeE5UQTBNamRhTURReApGekFWQmdOVkJBb1REbk41YzNSbGJUcHRZWE4wWlhKek1Sa3dGd1lEVlFRREV4QnJkV0psY201bGRHVnpMV0ZrCmJXbHVNSUlCSWpBTkJna3Foa2lHOXcwQkFRRUZBQU9DQVE4QU1JSUJDZ0tDQVFFQW5GK2c2WjB4Y2hnS2NGTlcKNDhFaWF4N3Y0akJQL1kyVmtxRVhDREVjVUpGUUZPMWh0Yk4rbkxkR2swdEtob2M4WWx1S05MbkFnL01uUk9DZQpsZVVnaXE3bmI3dEgwWUZhT3BnRmdKYmRDVFRWMkF4dDZFRjFlT2ZsTDh2SXZuSktHbnVUZGxOamZaV0Q1Ynh6ClpkZzFjVTh4Y2NTV1lNUXg0dVVOQ3hsWlZaaGtXaStvQ05GWS9nRzZpWGhEZTRkMUQySmRkY3J4UTVhZnFicWgKblFjMVF0dWpwQVViZFFhMXZYbEI0VFJtRlJqRjVVZVJobzh1QXV6Y2d4QlpPVkQ1MGlZd1BmZmRPaDZCTzRmQwppT1AzUFlIV0ZlTzdKNGF5SVFjNTA0K0tsbS9sYUIvcmVzc3crZlMvVXlreUJRT1RhU3c3Z3pnYkdlSkYrVlhZCmpQM1FWd0lEQVFBQm8wZ3dSakFPQmdOVkhROEJBZjhFQkFNQ0JhQXdFd1lEVlIwbEJBd3dDZ1lJS3dZQkJRVUgKQXdJd0h3WURWUjBqQkJnd0ZvQVVwa05ueXN4M3FZcXRsVjRzV3BaekpwY2FvVFF3RFFZSktvWklodmNOQVFFTApCUUFEZ2dFQkFMdVZINSsyczFTM3ZyMnV2U3BDa1lNYU9hYXl4am9IdVI5cHVIV2F0cThsQk90dXgyb3hiM1dICm9yQkJuLzNQTmh6ajJrSGZxanIyYzdxV0tvS1ZtMnRsWFViK0Q0SWYyWm5zMENQdjlEZTd3ZEI2UEVxUElNNUUKNWxmVkthU3Bld3UzdmRTZWJ0WlhGS0MxNnVWY0NvNk8wQ1RhaXZ2RGpNalZaNDN0bEtvSGxwWm8vVVl1WS84eQp6eStPbFJraEtRVHpCVW1kOU5yNm9TYUNzdURGUk1kdytvR1YreEFxcFdrZ3Yyb3pxOVU3RlJ1a3hHb21uelBGCjVOREFHMGhSNlFRY2RHR2Q3K3lYaWJ1VkM4NzV6TFJrcTRHNXBnRFFndlVuMW1MbU1WeFhlbXMxcVhrdUxxWnEKK2kwL1BkOGdPU1BQVkxLdll1cHBPWGx1U1NvZWpDdz0KLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo=
client-key-data: LS0tLS1CRUdJTiBSU0EgUFJJVkFURSBLRVktLS0tLQpNSUlFcEFJQkFBS0NBUUVBbkYrZzZaMHhjaGdLY0ZOVzQ4RWlheDd2NGpCUC9ZMlZrcUVYQ0RFY1VKRlFGTzFoCnRiTituTGRHazB0S2hvYzhZbHVLTkxuQWcvTW5ST0NlbGVVZ2lxN25iN3RIMFlGYU9wZ0ZnSmJkQ1RUVjJBeHQKNkVGMWVPZmxMOHZJdm5KS0dudVRkbE5qZlpXRDVieHpaZGcxY1U4eGNjU1dZTVF4NHVVTkN4bFpWWmhrV2krbwpDTkZZL2dHNmlYaERlNGQxRDJKZGRjcnhRNWFmcWJxaG5RYzFRdHVqcEFVYmRRYTF2WGxCNFRSbUZSakY1VWVSCmhvOHVBdXpjZ3hCWk9WRDUwaVl3UGZmZE9oNkJPNGZDaU9QM1BZSFdGZU83SjRheUlRYzUwNCtLbG0vbGFCL3IKZXNzdytmUy9VeWt5QlFPVGFTdzdnemdiR2VKRitWWFlqUDNRVndJREFRQUJBb0lCQVFDSGhhRlJsZmhxWjBkMAp2ZVdLRWJJZ29IbEowSkVpci9nM1VnRkNDajM5M1ZKSU1Nc0R6SUlvay9aSVpYSTdVUzBXR1R1WUlud2tYekZqClVrQmVyR3NkaGlQeUE1OWtoUFNMMzRDMVJ3cGRsanJXdVQ3dmtQdWNRMjJ2bEs5dnptRkd2bDY0cCtDTDBHNjEKUmpQRXlqTFc5c2xsVGZqOStFczcxME1Nb1hWNDVmVGl4R3JnbmJpUWtOeGk2SnA0L3VHbUlESUFWRnpEQ0w1KwpBWjVoOS9nL3RNL3NWU3BWRW1jQTF4YTAwVEJpT2dQOUx2RXp1MnB3N0dTVGZtTTlEVjlKa0l0d2FEYVU5U2xNCkJsb29GZ09QalNxM1FrWE9EUHo0WUdCa1RxSDJ4OFZpYlBYdFlMSG1GYkJDdXR0T2x2aUpwQUNPZ0U0d0ZMa0EKMjVBU2RrSWhBb0dCQU1GMmV4azJsYW01a24yajZ3TUw1Tk1rRCtzczBTOE5oaFd6U2s1cC9BV3VyOVpBTGlwSApNckNuVVpza1lFdEJCMjduamgvbkNuU3JEUHIwajJORDV1ano3aWh2SWVsYUlReGVBQStqdUVqcytwZGQ3akJWCnVKcVoxSmhDdlNLQ3hsYk5zMWYxandEM2xuV2lGaFBkUFF2TmVIY2xxRmYyVDhJWEx6anc1WnpmQW9HQkFNN3IKNjZvZkJpM0lmVFMyY0NOU1JPOFQ5YTI3a0tlaFpHM1g1Y0Q4MXFodnMvd0xHeC9CWDJRbGxrNGVFVDU3cE1kRQo0NDZ4QjlqQnhaL1htT0cyL3UvczJabWhNRG8zMDlxWXR6alBxVmZnbnNmSDJOcUlUcHNLeG1INW5CV2tpd0dwCmd6N3lJRlBJclpGbVBiZzl0TSt6NEZ4RDBBT0pQZDF6eitINVFjT0pBb0dCQUxKbUlXbkVyZ3BPOThrb0tRVXMKS0p5VGVxSnhONHplT2JFMUhlWmxVV09rREwzVGZUNjdYUUVOcWZFWWdEdWxBY2ZCZTR2cnIvYVo3V1JWdFF2aQpoOEoxZmo2SERJeDA4bGpITGVNK0pDZ0xiNkc1bW5XejlvR0tMVU1pOStvbEVlVGwxdVhicVQxSkV0UHkzY3ovCmpOV2ZhZURsTnZHMlR5STU0dS90SksrZEFvR0FQc096QlRSSjVJTkc3MEZUZkhOTTg1UURWb0pwVzErS0hnTjUKN25NRERhNXNVc3h2bXM5R0J4T2JwdkJaM0xFV2gxY3ZDeTVKcWdjRTBmcE1wbEtpdTlZRkh5T1VoR1JBdjdMSgpDTk44azJwUDMxdVFQS0ZSN3BkekcyN2lXSEpEcytwZUpDNi9mWXFHazI4RzA2YnIvSUNjVW9CRFRYOUlvNjZvClpPdjlkYmtDZ1lBcHhTQnBPLzk1cVRHeno5Z3lnanNNZ2pwY09XVE1nbWVCZldnM3dBNlNScjNKdGpJYzlNWG0Kclc0dVQxbGYvTGNKdDd5UW9RcGkyWHpMQ2xCWkxJb21mZ0dkSjR4dUdTRjMyYURLQmd2WU1OSlNIUjkvZ1N1SAptSnRnMGJZNEF1TDFwUDBrMU1PM3JzazNCdHY0NEROZzZPYmZ3OGtIQklRZHdVWGl4UGdxekE9PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=
都能查看到集群名称
创建角色
用户创建完成后,接下来就需要给该用户添加操作权限,我们来定义一个 YAML 文件,创建一个允许用户操作 Deployment、Pod、ReplicaSets 的角色,如下定义:(cnych-role.yaml)
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: cnych-role
namespace: kube-system #注意名称控件
rules:
- apiGroups: ["", "apps"]
resources: ["deployments", "replicasets", "pods"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"] # 也可以使用['*']
建议写上core
其中 Pod 属于 core 这个 API Group,在 YAML 中用空字符就可以,而 Deployment 和 ReplicaSet 现在都属于 apps 这个 API Group(如果不知道则可以用 kubectl explain 命令查看),所以 rules 下面的 apiGroups 就综合了这几个资源的 API Group:[“”, “apps”],其中 verbs 就是我们上面提到的可以对这些资源对象执行的操作,我们这里需要所有的操作方法,所以我们也可以使用[‘*’]来代替,然后直接创建这个 Role:
$ kubectl create -f cnych-role.yaml
role.rbac.authorization.k8s.io/cnych-role created
注意这里我们没有使用上面的 cnych-context 这个上下文,因为暂时还没有设置权限。
创建角色权限绑定
Role 创建完成了,但是很明显现在我们这个 Role 和我们的用户 cnych 还没有任何关系,对吧?这里就需要创建一个 RoleBinding 对象,在 kube-system 这个命名空间下面将上面的 cnych-role 角色和用户 cnych 进行绑定:(cnych-rolebinding.yaml)
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: cnych-rolebinding
namespace: kube-system #某个特定的名称空间,上面的role也指定了名称空间
subjects:
- kind: User
name: cnych
apiGroup: "" #表示当前apiGroup,集群角色绑定时,如果是User,那么就要注明apiGroup
roleRef:
kind: Role
name: cnych-role
apiGroup: rbac.authorization.k8s.io # 留空字符串也可以,则使用当前的apiGroup
[root@master ~]# kubectl explain role
KIND: Role
VERSION: rbac.authorization.k8s.io/v1
建议写上rbac.authorization.k8s.io
上面的 YAML 文件中我们看到了 subjects 字段,这里就是我们上面提到的用来尝试操作集群的对象,这里对应上面的 User 帐号 cnych,使用kubectl 创建上面的资源对象:
$ kubectl create -f cnych-rolebinding.yaml
rolebinding.rbac.authorization.k8s.io/cnych-rolebinding created
测试
$ kubectl --context=cnych-context get rs,deploy
NAME DESIRED CURRENT READY AGE
replicaset.apps/coredns-667f964f9b 2 2 2 13d
replicaset.apps/metrics-server-5d4dbb78bb 1 1 1 2d21h
replicaset.apps/metrics-server-6886856d7c 0 0 0 2d21h
replicaset.apps/metrics-server-6dcfdf89b5 0 0 0 2d21h
replicaset.apps/traefik-ingress-controller-54f665bb97 0 0 0 47h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/coredns 2/2 2 2 13d
deployment.apps/metrics-server 1/1 1 1 2d21h
deployment.apps/traefik-ingress-controller 1/1 1 1 2d6h
使用 kubectl 的使用并没有指定 namespace,这是因为我们我们上面创建这个 Context 的时候就绑定在了 kube-system 这个命名空间下面
可以加上个-n default测试,发现权限不符合
get svc测试,发现也没有这个权限,所以不能访问
这样我们就创建了一个只有单个命名空间访问权限的普通 User,可以不指定名称空间,就是说这个user account可以用于任意名称空间,但实际对某个名称空间的操作权限还是取决于确切的role和binding
只能访问某个 namespace 的 ServiceAccount
上面我们创建了一个只能访问某个命名空间下面的普通用户,我们前面也提到过 subjects 下面还有一种类型的主题资源:ServiceAccount
$ kubectl create sa cnych-sa -n kube-system
当然我们也可以定义成 YAML 文件的形式来创建:
apiVersion: v1
kind: ServiceAccount
metadata:
name: cnych-sa
namespace: kube-system
然后新建一个 Role 对象:(cnych-sa-role.yaml)
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: cnych-sa-role
namespace: kube-system
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
这里定义的角色没有创建、删除、更新 Pod 的权限
然后创建一个 RoleBinding 对象,将上面的 cnych-sa 和角色 haimaxy-sa-role 进行绑定:
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cnych-sa-rolebinding
namespace: kube-system
subjects:
- kind: ServiceAccount
name: cnych-sa
namespace: kube-system
roleRef:
kind: Role
name: cnych-sa-role
apiGroup: rbac.authorization.k8s.io
ServiceAccount 会生成一个 Secret 对象和它进行映射,这个 Secret 里面包含一个 token(用来证明pod在集群中的身份),我们可以利用这个 token 去登录 Dashboard
service account一般是用于集群内部的应用程序访问操作集群内部资源
sevice account会自动生成个自带的secret。imagepull的secret可以在设置sa时设置,那么使用这个sa的pod就可以拉取对应的私有仓库的镜像
pod.spec.imagePullSecrets或serviceaccout.imagePullSecrets
[root@master ~]# kubectl describe sa cnych-sa -n kube-system
Name: cnych-sa
Namespace: kube-system
Labels: <none>
Annotations: <none>
Image pull secrets: <none>
Mountable secrets: cnych-sa-token-xgnzr
Tokens: cnych-sa-token-xgnzr
Events: <none>
[root@master ~]# kubectl get secret cnych-sa-token-xgnzr -o yaml -n kube-system
apiVersion: v1
data:
ca.crt: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUM1ekNDQWMrZ0F3SUJBZ0lCQURBTkJna3Foa2lHOXcwQkFRc0ZBREFWTVJNd0VRWURWUVFERXdwcmRXSmwKY201bGRHVnpNQjRYRFRJeU1EUXhNekUxTURReU5sb1hEVE15TURReE1ERTFNRFF5Tmxvd0ZURVRNQkVHQTFVRQpBeE1LYTNWaVpYSnVaWFJsY3pDQ0FTSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnRVBBRENDQVFvQ2dnRUJBTmg1ClNHVHRHV051VlRNQ05BV2pudE5XUC9NTS90RG1LTnNtL08zYjFlK3U3YmJkbG03WjFQQ3RDQmdILzdSSDZGS0QKQ24rOFVzNHp6d0VXRVhWUnF3cmJZaURxaG5tUnN3N2IycWpVVENtUzRsK0grdEdLd0pSenhxMjVyNVM4UFFJNwpIcWRYaWZKUHoyU3JIM0RLc1VqL2lXNHROY01kSktqdXpzcXkxdWlWYU40blovd1pmWUF1Vms0bmY5R1ZEMDAxCkRpYlU5bTByYzhaWVpMQUZZQnhNVTBNV05Vc1kwUnhGamFMK0NtSXl6QXMySnRaUC9ubjNTT25ZRndlaDdhekQKcmlKaEJpTXhlTmNUUzRWbGtzTGsyaTN0S29zM1VzL2pWTVFIUExaeGNEVWVGeUs2bXRpWTczK05mTVNTNHFlVQpVcjhFdXd3VHpMdXo3NFdlU1hFQ0F3RUFBYU5DTUVBd0RnWURWUjBQQVFIL0JBUURBZ0trTUE4R0ExVWRFd0VCCi93UUZNQU1CQWY4d0hRWURWUjBPQkJZRUZLWkRaOHJNZDZtS3JaVmVMRnFXY3lhWEdxRTBNQTBHQ1NxR1NJYjMKRFFFQkN3VUFBNElCQVFBaVZ4RmJqaGQvL1JaTVpPTnlYcWVDT2t0c09uNHNjZW4wR0M1aWdXZzNsOENleGNNZQpEMHptZEpMYWlvblVqOFFIUUVTV0YzWW9BZmErNzdaVklRVUdZT3hCb0trTTdtOFFSUVlKbXF0ZWdHb0E3VVBxCnBOUEc5SHU0Q3pRTWF0VHl0NTNhTklJM3MyVktta1p2eEpoUTVOZi9DSzZlL0gyK2pkT2YzT05RRE0wUEFjdkQKZVpQRVlySGcrbGozVUpWc2xGbUFrbWtFMnRzV2RIcVhreFhNQ0tOMFFueGJaME45Tk0zSTdnbmF5Nk5JSThncgpGdlRwUUg4OTVia1NQOTdUUVJ1enE2NFBVQTRhNGpKZEhqbW95bWRYdnB6T01TVWNpYUFadElzSEJFUGxhYUVZCkZnTTV4VUZqVFkyUWswQldwY0pWcTd0czdjSXVwcUxvMjNPZQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==
namespace: a3ViZS1zeXN0ZW0=
token: ZXlKaGJHY2lPaUpTVXpJMU5pSXNJbXRwWkNJNklqRnlUMFoxWm14d1dsRmFlR1ZPWlZsME1ubHBYMTl5Y25OUFdHaFNiekJqWWt0dU5UaEdORXBzWWxFaWZRLmV5SnBjM01pT2lKcmRXSmxjbTVsZEdWekwzTmxjblpwWTJWaFkyTnZkVzUwSWl3aWEzVmlaWEp1WlhSbGN5NXBieTl6WlhKMmFXTmxZV05qYjNWdWRDOXVZVzFsYzNCaFkyVWlPaUpyZFdKbExYTjVjM1JsYlNJc0ltdDFZbVZ5Ym1WMFpYTXVhVzh2YzJWeWRtbGpaV0ZqWTI5MWJuUXZjMlZqY21WMExtNWhiV1VpT2lKamJubGphQzF6WVMxMGIydGxiaTE0WjI1NmNpSXNJbXQxWW1WeWJtVjBaWE11YVc4dmMyVnlkbWxqWldGalkyOTFiblF2YzJWeWRtbGpaUzFoWTJOdmRXNTBMbTVoYldVaU9pSmpibmxqYUMxellTSXNJbXQxWW1WeWJtVjBaWE11YVc4dmMyVnlkbWxqWldGalkyOTFiblF2YzJWeWRtbGpaUzFoWTJOdmRXNTBMblZwWkNJNkltWTFOREJqTmpsbExUZzJObVF0TkRObVlTMWlZVEl5TFRRek56Y3laalF3TldNNU1DSXNJbk4xWWlJNkluTjVjM1JsYlRwelpYSjJhV05sWVdOamIzVnVkRHByZFdKbExYTjVjM1JsYlRwamJubGphQzF6WVNKOS5CQjhRaG8wdXBqZVRVdHdBcmgwN21OYk5td2tWUFYtbXN1LWdNX2dBVVIyb2NrNDhDa2FtbjdzdFpSeEdfdk8zSGhaQ0VkUVdyeEdBUW1PSWdJYlVVbGt3UHl5ZndtSEZDSU5hbXlRTmhMQ2xRUW9vdnVFdUlqeDVnR1BIcWN2Z0Fwb0QxTkM0cTVYMnB4djdaUW81bk1HUGFJSkNjdW5RRXB2eTBwZUhGX25nTXZyZzZZSGFnSUtMazhZcHlhUzE3VjhiRC1SUGMwb1BkS29icjVXTHJ0d3lRMzg5angtOFc2QTkxaUhNOXFQZ0d0NF9sM2ZUc0RQTmd1Z1NDcV9YeW1leW05ek9nenlUejVGNFNJc2NScld6LXMwUnRvdjNidHY3TV9DelRwWHkta19PTzNQMGZtTWRuMDJUOF9pQ0FvQ0I5WmFmT2paWlZYUGN6dERuYlE=
kind: Secret
metadata:
annotations:
kubernetes.io/service-account.name: cnych-sa
kubernetes.io/service-account.uid: f540c69e-866d-43fa-ba22-43772f405c90
creationTimestamp: "2022-04-26T05:40:36Z"
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:data:
.: {}
f:ca.crt: {}
f:namespace: {}
f:token: {}
f:metadata:
f:annotations:
.: {}
f:kubernetes.io/service-account.name: {}
f:kubernetes.io/service-account.uid: {}
f:type: {}
manager: kube-controller-manager
operation: Update
time: "2022-04-26T05:40:36Z"
name: cnych-sa-token-xgnzr
namespace: kube-system
resourceVersion: "562270"
uid: 68077226-2617-4086-96c4-1faaec2e5072
type: kubernetes.io/service-account-token
$ kubectl get secret -n kube-system |grep cnych-sa
cnych-sa-token-nxgqx kubernetes.io/service-account-token 3 47m
$ kubectl get secret cnych-sa-token-nxgqx -o jsonpath={.data.token} -n kube-system |base64 -d
# 会生成一串很长的base64后的字符串
使用这里的 token 去 Dashboard 页面进行登录(也就是用sa这个身份去登录集群内部的服务,sa主要就是用于集群身份验证,就是判断你这个操作的发起方对集群来说是否合法的)
我们可以看到上面的提示信息说我们现在使用的这个 ServiceAccount 没有权限获取当前命名空间下面的资源对象,这是因为我们登录进来后默认跳转到 default 命名空间,我们切换到 kube-system 命名空间下面就可以了
我们可以看到可以访问 pod 列表了,但是也会有一些其他额外的提示:events is forbidden: User “system:serviceaccount:kube-system:cnych-sa” cannot list events in the namespace “kube-system”,这是因为当前登录用只被授权了访问 pod 和 deployment 的权限,同样的,访问下deployment看看可以了吗?
同样的,你可以根据自己的需求来对访问用户的权限进行限制,可以自己通过 Role 定义更加细粒度的权限,也可以使用系统内置的一些权限……
可以全局访问的 ServiceAccount
刚刚我们创建的 cnych-sa 这个 ServiceAccount 和一个 Role 角色进行绑定的,如果我们现在创建一个新的 ServiceAccount,需要他操作的权限作用于所有的 namespace,这个时候我们就需要使用到 ClusterRole 和 ClusterRoleBinding 这两种资源对象了。同样,首先新建一个 ServiceAcount 对象:(cnych-sa2.yaml)
apiVersion: v1
kind: ServiceAccount
metadata:
name: cnych-sa2
namespace: kube-system #sa和secret都是有名称空间的,默认default
创建:
$ kubectl create -f cnych-sa2.yaml
然后创建一个 ClusterRoleBinding 对象(cnych-clusterolebinding.yaml):
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: cnych-sa2-clusterrolebinding
subjects:
- kind: ServiceAccount
name: cnych-sa2
namespace: kube-system
roleRef:
kind: ClusterRole
name: cluster-admin #这里直接用cluster-admin这个cluster-role
apiGroup: rbac.authorization.k8s.io
从上面我们可以看到我们没有为这个资源对象声明 namespace,因为这是一个 ClusterRoleBinding 资源对象,是作用于整个集群的,我们也没有单独新建一个 ClusterRole 对象,而是使用的 cluster-admin 这个对象,这是 Kubernetes 集群内置的 ClusterRole 对象,我们可以使用 kubectl get clusterrole 和 kubectl get clusterrolebinding 查看系统内置的一些集群角色和集群角色绑定,这里我们使用的 cluster-admin 这个集群角色是拥有最高权限的集群角色,所以一般需要谨慎使用该集群角色。
创建上面集群角色绑定资源对象,创建完成后同样使用 ServiceAccount 对应的 token 去登录 Dashboard 验证下:
$ kubectl create -f cnych-clusterolebinding.yaml
$ kubectl get secret -n kube-system |grep cnych-sa2
cnych-sa2-token-nxgqx kubernetes.io/service-account-token 3 47m
$ kubectl get secret cnych-sa2-token-nxgqx -o jsonpath={.data.token} -n kube-system |base64 -d
会生成一串很长的base64后的字符串
发现是有全局权限的,也就是各个名称空间都有权限,但是有哪些权限,就要看role的rule的配置了
[root@master ~]# kubectl get clusterrole | grep cluster-admin
cluster-admin 2022-04-13T15:04:44Z
[root@master ~]# kubectl get clusterrole cluster-admin -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
creationTimestamp: "2022-04-13T15:04:44Z"
labels:
kubernetes.io/bootstrapping: rbac-defaults
managedFields:
- apiVersion: rbac.authorization.k8s.io/v1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
.: {}
f:rbac.authorization.kubernetes.io/autoupdate: {}
f:labels:
.: {}
f:kubernetes.io/bootstrapping: {}
f:rules: {}
manager: kube-apiserver
operation: Update
time: "2022-04-13T15:04:44Z"
name: cluster-admin
resourceVersion: "85"
uid: ca9eb13e-2cc9-4319-ac8b-ca9619f16aff
rules: #权限设置非常高,直接全不权限
- apiGroups:
- '*'
resources:
- '*'
verbs:
- '*'
- nonResourceURLs: #这个是对于非api资源的类型的控制,就是不是pod这些,比如metrics
- '*'
verbs:
- '*'
Security Context
Kubernetes Pod/容器的安全管控
我们有时候在运行一个容器的时候,可能需要使用 sysctl 命令来修改内核参数,比如 net、vm、kernel 等参数,但是 sysctl 需要容器拥有超级权限,才可以使用,在 Docker 容器启动的时候我们可以加上 --privileged 参数来使用特权模式。那么在 Kubernetes 中应该如何来使用呢?(记得容器是共享一个内核的)
这个时候我们就需要使用到 Kubernetes 中的 Security Context,也就是常说的安全上下文,主要是来限制容器非法操作宿主节点的系统级别的内容,使得节点的系统或者节点上其他容器组受到影响。Kubernetes 提供了三种配置安全上下文级别的方法:
(安全上下文类型)
Container-level Security Context:仅应用到指定的容器
Pod-level Security Context:应用到 Pod 内所有容器以及 Volume
Pod Security Policies(PSP):应用到集群内部所有
Pod 以及 Volume
我们可以用如下几种方式来设置 Security Context:
访问权限控制:根据用户 ID(UID)和组 ID(GID)来限制对资源(比如:文件)的访问权限
Security Enhanced Linux (SELinux):为对象分配 SELinux 标签
以privileged(特权)模式运行
Linux Capabilities:给某个特定的进程超级权限,而不用给 root 用户所有的privileged 权限
AppArmor:使用程序文件来限制单个程序的权限
Seccomp:过滤容器中进程的系统调用(system call)
AllowPrivilegeEscalation(允许特权扩大):此项配置是一个布尔值,定义了一个进程是否可以比其父进程获得更多的特权,直接效果是,容器的进程上是否被设置no_new_privs 标记。当出现如下情况时,AllowPrivilegeEscalation 的值始终为 true:容器以 privileged 模式运行
容器拥有 CAP_SYS_ADMIN 的 Linux Capability
有些配置是属于unbuntu的,这里主要用centos
为 Pod 设置 Security Context
pod级别的security context
我们只需要在 Pod 定义的资源清单文件中添加 securityContext 字段,就可以为 Pod 指定安全上下文相关的设定,通过该字段指定的内容将会对当前 Pod 中的所有容器以及volume生效。
apiVersion: v1
kind: Pod
metadata:
name: security-context-pod-demo
spec:
volumes:
- name: sec-ctx-vol
emptyDir: {}
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: sec-ctx-demo
image: busybox
command: ["sh", "-c", "sleep 60m"]
volumeMounts:
- name: sec-ctx-vol
mountPath: /pod/demo
securityContext:
allowPrivilegeEscalation: false #这里不允许特权扩大,就是说子进程的权限不能超过父进程
runAsUser: 1000
fsGroup: 2000
在当前资源清单文件中我们在 Pod 下面添加了 securityContext 字段,其中:
runAsUser 字段指定了该 Pod 中所有容器的进程都以 UID 1000 的身份运行,runAsGroup 字段指定了该 Pod
中所有容器的进程都以 GID 3000 的身份运行
如果省略该字段,容器进程的 GID 为 root(0)
容器中创建的文件,其所有者为userID 1000,groupID 3000
fsGroup 字段指定了该 Pod 的 fsGroup 为 2000
数据卷 (对应挂载点 /pod/demo 的数据卷为 sec-ctx-demo) 的所有者以及在该数据卷下创建的任何文件,其 GID 都为2000

apply上面的文件
我们可以验证下容器中的进程运行的 ownership:
$ kubectl exec security-context-pod-demo top
Mem: 7586020K used, 422948K free, 298660K shrd, 1247656K buff, 3867660K cached
CPU: 2.1% usr 1.0% sys 0.0% nic 96.3% idle 0.2% io 0.0% irq 0.0% sirq
Load average: 0.30 0.35 0.35 1/956 50
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
46 0 1000 R 1292 0.0 0 0.0 top
1 0 1000 S 1280 0.0 0 0.0 sleep 60m
我们直接运行一个 top 进程,查看容器中的所有正在执行的进程,我们可以看到 USER ID 都为 1000(runAsUser 指定的),然后查看下挂载的数据卷的 ownership:
$ kubectl exec security-context-pod-demo -- ls -la /pod
total 8
drwxr-xr-x 3 root root 4096 Nov 26 15:44 .
drwxr-xr-x 1 root root 4096 Nov 26 15:44 ..
drwxrwsrwx 2 root 2000 6 Nov 26 15:43 demo
因为上面我们指定了 fsGroup=2000,所以声明挂载的数据卷 /pod/demo 的 GID 也变成了 2000。直接调用容器中的 id 命令:
$ kubectl exec security-context-pod-demo id
uid=1000 gid=3000 groups=2000
我们可以看到 gid 为 3000,与 runAsGroup 字段所指定的一致,如果 runAsGroup 字段被省略,则 gid 取值为 0(即 root),此时容器中的进程将可以操作 root Group 的文件。
比如我们现在想要去删除容器中的 /tmp 目录就没有权限了,因为该目录的用户和组都是 root,而我们当前要去删除使用的进程的 ID 号就变成了 1000:3000,所以没有权限操作:
$ kubectl exec security-context-pod-demo -- ls -la /tmp
total 8
drwxrwxrwt 2 root root 4096 Oct 29 02:40 .
drwxr-xr-x 1 root root 4096 Nov 26 15:44 ..
$ kubectl exec security-context-pod-demo -- rm -rf /tmp
rm: can't remove '/tmp': Permission denied
为容器设置 Security Context
除了在 Pod 中可以设置安全上下文之外,我们还可以单独为某个容器设置安全上下文,同样也是通过 securityContext 字段设置,当该字段的配置与 Pod 级别的 securityContext 配置相冲突时,容器级别的配置将覆盖 Pod 级别的配置。容器级别的 securityContext 不影响 Pod 中的数据卷(volume是在pod的spec下定义的)。如下资源清单所示:
apiVersion: v1
kind: Pod
metadata:
name: security-context-container-demo
spec:
securityContext:
runAsUser: 1000
containers:
- name: sec-ctx-demo
image: busybox
command: [ "sh", "-c", "sleep 60m" ]
securityContext:
runAsUser: 2000
allowPrivilegeEscalation: false
同样可以用上面的方法来验证
容器的进程以 UID 2000 的身份运行,该取值由 spec.containers[*].securityContext.runAsUser 容器组中的字段定义。Pod 中定义的 spec.securityContext.runAsUser 取值 1000 被覆盖。
设置 Linux Capabilities
我们使用 docker run 的时候可以通过 --cap-add 和 --cap-drop 命令来给容器添加 Linux Capabilities。那么在 Kubernetes 下面如何来设置呢?要了解如何设置,首先我们还是需要了解下 Linux Capabilities 是什么?
Linux Capabilities
要了解 Linux Capabilities,这就得从 Linux 的权限控制发展来说明。在 Linux 2.2 版本之前,当内核对进程进行权限验证的时候,Linux 将进程划分为两类:特权进程(UID=0,也就是超级用户)和非特权进程(UID!=0),特权进程拥有所有的内核权限,而非特权进程则根据进程凭证(effective UID, effective GID,supplementary group 等)进行权限检查。
比如我们以常用的 passwd 命令为例,修改用户密码需要具有 root 权限,而普通用户是没有这个权限的。但是实际上普通用户又可以修改自己的密码,这是怎么回事呢?在 Linux 的权限控制机制中,有一类比较特殊的权限设置,比如 SUID(Set User ID on execution),允许用户以可执行文件的 owner 的权限来运行可执行文件。因为程序文件 /bin/passwd 被设置了 SUID 标识,所以普通用户在执行 passwd 命令时,进程是以 passwd 的所有者,也就是 root 用户的身份运行,从而就可以修改密码了。
但是使用 SUID 却带来了新的安全隐患,当我们运行设置了 SUID 的命令时,通常只是需要很小一部分的特权,但是 SUID 却给了它 root 具有的全部权限,一旦 被设置了 SUID 的命令出现漏洞,是不是就很容易被利用了。
为此 Linux 引入了 Capabilities 机制来对 root 权限进行了更加细粒度的控制,实现按需进行授权,这样就大大减小了系统的安全隐患。
什么是 Capabilities
从内核 2.2 开始,Linux 将传统上与超级用户 root 关联的特权划分为不同的单元,称为 capabilites。Capabilites 每个单元都可以独立启用和禁用。这样当系统在作权限检查的时候就变成了:在执行特权操作时,如果进程的有效身份不是 root,就去检查是否具有该特权操作所对应的 capabilites,并以此决定是否可以进行该特权操作。比如如果我们要设置系统时间,就得具有 CAP_SYS_TIME 这个 capabilites

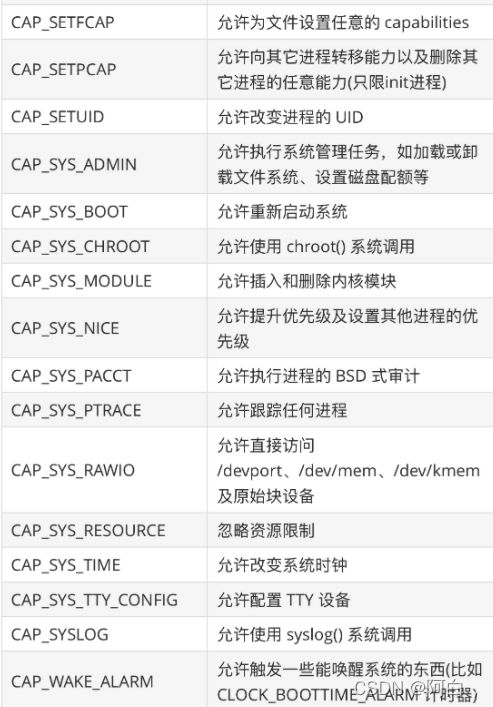
如何使用 Capabilities
我们可以通过 getcap 和 setcap 两条命令来分别查看和设置程序文件的 capabilities 属性。比如当前我们是zuiapp 这个用户,使用 getcap 命令查看 ping 命令目前具有的 capabilities:
$ ll /bin/ping
-rwxr-xr-x. 1 root root 62088 Nov 7 2016 /bin/ping
$ getcap /bin/ping
/bin/ping = cap_net_admin,cap_net_raw+p
我们可以看到具有 cap_net_admin 这个属性,所以我们现在可以执行 ping 命令:
```bash
$ ping www.qikqiak.com
PING www.qikqiak.com.w.kunlungr.com (115.223.14.186) 56(84) bytes of data.
64 bytes from 115.223.14.186 (115.223.14.186): icmp_seq=1 ttl=54 time=7.87 ms
64 bytes from 115.223.14.186 (115.223.14.186): icmp_seq=2 ttl=54 time=7.85 ms
但是如果我们把命令的 capabilities 属性移除掉:
$ sudo setcap cap_net_admin,cap_net_raw-p /bin/ping
$ getcap /bin/ping
/bin/ping =
这个时候我们执行 ping 命令可以发现已经没有权限了:
$ ping www.qikqiak.com
ping: socket: Operation not permitted
因为 ping 命令在执行时需要访问网络,所需的 capabilities 为 cap_net_admin 和 cap_net_raw,所以我们可以通过 setcap 命令可来添加它们:
$ sudo setcap cap_net_admin,cap_net_raw+p /bin/ping
$ getcap /bin/ping
/bin/ping = cap_net_admin,cap_net_raw+p
$ ping www.qikqiak.com
PING www.qikqiak.com.w.kunlungr.com (115.223.14.188) 56(84) bytes of data.
64 bytes from 115.223.14.188 (115.223.14.188): icmp_seq=1 ttl=54 time=7.39 ms
命令中的 p 表示 Permitted 集合(接下来会介绍),+ 号表示把指定的capabilities 添加到这些集合中,- 号表示从集合中移除。
对于可执行文件的属性中有三个集合来保存三类 capabilities,它们分别是:
Permitted:在进程执行时,Permitted 集合中的 capabilites 自动被加入到进程的 Permitted 集合中。
Inheritable:Inheritable 集合中的 capabilites 会与进程的 Inheritable 集合执行与操作,以确定进程在执行 execve 函数后哪些 capabilites 被继承。
Effective:Effective 只是一个 bit。如果设置为开启,那么在执行 execve 函数后,Permitted 集合中新增的 capabilities 会自动出现在进程的 Effective 集合中。
对于进程中有五种 capabilities 集合类型,相比文件的 capabilites,进程的 capabilities 多了两个集合,分别是 Bounding 和 Ambient。
我们可以通过下面的命名来查看当前进程的 capabilities 信息:
$ cat /proc/7029/status | grep 'Cap' #7029为PID
CapInh: 0000000000000000
CapPrm: 0000000000000000
CapEff: 0000000000000000
CapBnd: 0000001fffffffff
CapAmb: 0000000000000000
然后我们可以使用 capsh 命令把它们转义为可读的格式,这样基本可以看出进程具有的 capabilities 了:
$ capsh --decode=0000001fffffffff
0x0000001fffffffff=cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable,cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock,cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace,cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource,cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write,cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog,35,36
Docker Container Capabilities
我们说 Docker 容器本质上就是一个进程,所以理论上容器就会和进程一样会有一些默认的开放权限,默认情况下 Docker 会删除必须的 capabilities 之外的所有 capabilities,因为在容器中我们经常会以 root 用户来运行,使用 capabilities 现在后,容器中的使用的 root (不指定用户身份即不是runAsUser,默认是root,但官方的dockerfile或镜像一般都是用了USER命令来指定用户)用户权限就比我们平时在宿主机上使用的 root 用户权限要少很多了,这样即使出现了安全漏洞,也很难破坏或者获取宿主机的 root 权限,所以 Docker 支持 Capabilities 对于容器的安全性来说是非常有必要的。
不过我们在运行容器的时候可以通过指定 --privileded 参数来开启容器的超级权限,这个参数一定要慎用,因为他会获取系统 root 用户所有能力赋值给容器,并且会扫描宿主机的所有设备文件挂载到容器内部(并且还可以特权拓展也就是它的子进程权限可以具备超过了父进程的权限),所以是非常危险的操作。
但是如果你确实需要一些特殊的权限,我们可以通过 --cap-add 和 --cap-drop 这两个参数来动态调整,可以最大限度地保证容器的使用安全。下面表格中列出的 Capabilities 是 Docker 默认给容器添加的,我们可以通过 --cap-drop 去除其中一个或者多个:
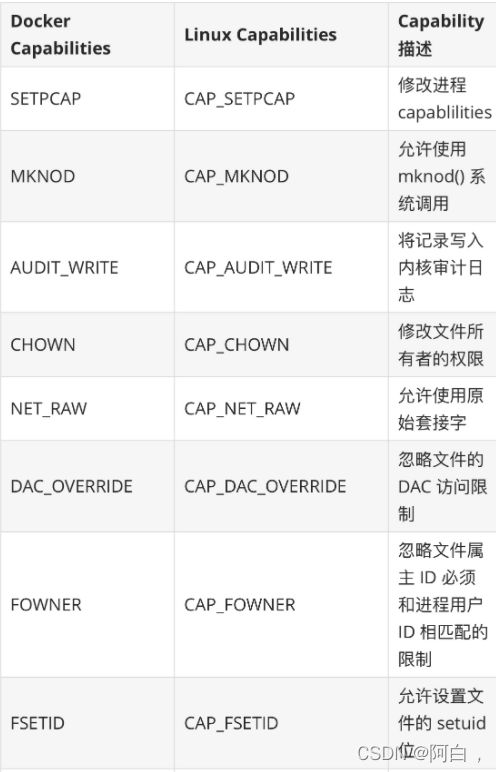
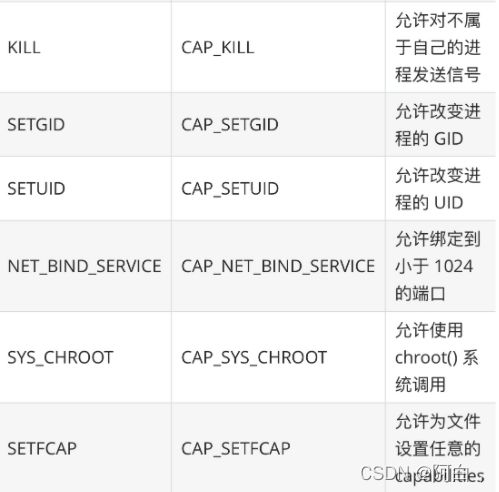
下面表格中列出的 Capabilities 是 Docker 默认删除的,我们可以通过–cap-add添加其中一个或者多个:

–cap-add和–cap-drop 这两参数都支持ALL值,比如如果你想让某个容器拥有除了MKNOD之外的所有内核权限,那么可以执行下面的命令: $ sudo docker run --cap-add=ALL --cap-drop=MKNOD …
比如现在我们需要修改网络接口数据,默认情况下是没有权限的,因为需要的 NET_ADMIN 这个 Capabilities 默认被移除了:
$ docker run -it --rm busybox /bin/sh
/ # ip link add dummy0 type dummy
ip: RTNETLINK answers: Operation not permitted
所以在不使用 --privileged 的情况下(不建议)我们可以使用 --cap-add=NET_ADMIN 将这个 Capabilities 添加回来:
$ docker run -it --rm --cap-add=NET_ADMIN busybox /bin/sh
/ # ip link add dummy0 type dummy
可以看到已经 OK 了。
Kubernetes 配置 Capabilities
就是在kubernetes中对容器配置capabilities
上面我介绍了在 Docker 容器下如何来配Capabilities,在 Kubernetes 中也可以很方便的来定义,我们只需要添加到 Pod 定义的 spec.containers.securityContext.capabilities中即可,也可以进行 add 和 drop 配置,同样上面的示例,我们要给 busybox 容器添加 NET_ADMIN 这个 Capabilities,对应的 YAML 文件可以这样定义:(cpb-demo.yaml)
apiVersion: v1
kind: Pod
metadata:
name: cpb-demo
spec:
containers:
- name: cpb
image: busybox
args:
- sleep
- "3600"
securityContext:
capabilities:
add: # 添加
- NET_ADMIN
drop: # 删除
- KILL
我们在 securityContext 下面添加了 capabilities 字段,其中添加了 NET_ADMIN 并且删除了 KILL 这个默认的容器 Capabilities,这样我们就可以在 Pod 中修改网络接口数据了:
$ kubectl apply -f cpb-demo.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
cpb-demo 1/1 Running 0 2m9s
$ kubectl exec -it cpb-demo /bin/sh
/ # ip link add dummy0 type dummy
/ #
在 Kubernetes 中通过 sercurityContext.capabilities 进行配置容器的 Capabilities,当然最终还是通过 Docker 的 libcontainer 去借助 Linux kernel capabilities 实现的权限管理。
为容器设置 SELinux 标签
SELinux (Security-Enhanced Linux) 是一种强制访问控制(mandatory access control)的实现。它的作法是以最小权限原则(principle of least privilege)为基础,在 Linux 核心中使用 Linux 安全模块(Linux Security Modules)。Pod 或容器定义的 securityContext 中 seLinuxOptions 字段是一个 SELinuxOptions 对象,该字段可用于为容器指定 SELinux 标签。
securityContext:
seLinuxOptions:
level: "s0:c123,c456"
pod安全策略(官网已经弃用,推荐使用PodSeurityAdmission)
Pod 安全策略使得对 Pod 创建和更新进行细粒度的权限控制成为可能。默认情况下,Kubernetes 允许创建一个有特权容器的 Pod,这些容器很可能会危机系统安全,而 Pod 安全策略(PSP)则通过确保请求者有权限按配置来创建 Pod,从而来保护集群免受特权 Pod 的影响。
PodSecurityPolicy 是 Kubernetes API 对象,它能够控制 Pod 规范中与安全性相关的各个方面,PodSecurityPolicy 对象定义了一组 Pod 运行时必须遵循的条件及相关字段的默认值,只有 Pod 满足这些条件才会被系统接受,Pod 安全策略允许管理员控制如下方面

Pod 安全策略由设置和策略组成,它们能够控制 Pod 访问的安全特征,这些设置分为如下三类:
基于布尔值控制:这种类型的字段默认为最严格限制的值 基于被允许的值集合控制:这种类型的字段会与这组值进行对比,以确认值被允许
基于策略控制:设置项通过一种策略提供的机制来生成该值,这种机制能够确保指定的值落在被允许的这组值中
Pod 安全策略实现为一种可选(但是建议启用)的准入控制器,启用了准入控制器即可强制实施 Pod 安全策略,不过如果没有授权认可策略之前即启用准入控制器将导致集群中无法创建任何 Pod。
Admission Controller
Admission Controller(准入控制器)拦截对 kube-apiserver 的请求,拦截发生在请求的对象被持久化之前(也就是写进etcd前),但是在请求被验证和授权之后。这样我们就可以查看请求对象的来源,并验证需要的内容是否正确。通过将它们添加到 kube-apiserver 的 –enable-admission-plugins 参数中来启用准入控制器。另外需要注意准入控制器的顺序很重要。
将 PodSecurityPolicy 添加到 kube-apiserver 上的 --enabled-admission-plugins 参数中,然后重启 kube-apiserver(kube-apiserver是静态pod):
--enable-admission-plugins=NodeRestriction,PodPreset,PodSecurityPolicy
restriction限制
我们这里使用的是 kubeadm 搭建的集群,当我们开启 PodSecurityPolicy 后你会发现一个奇怪的现象,就是我们在 kube-system 命名空间下面看不到 apiserver 的 Pod 了
大家看到这里可能觉得很奇怪,其实这是因为我们开启了 Pod 的安全策略了,而 apiserver 这个 Pod 是一个静态 Pod,他需要 kubelet 创建一个镜像的 Pod 我们才能看到,但是现在我们并没有针对 kubelet 的任何安全策略声明,所以这个镜像 Pod 是创建不成功的,所以我们也就看不到了。同样我们去创建新的 Pod 也会失败。
这时候你去创建deploy会发现deploy和rs可以创建成功,但是没有生成pod,kubectl describe rs会发现报错forbidden: PodSecurityPolicy: unable to admit pod: []
forbidden禁止
ServiceAccount Controller Manager
一般来说用户很少会直接创建 Pod,通常是通过 Deployment、StatefulSet、Job 或者 DasemonSet 这些控制器来创建 Pod 的,我们这里需要配置 kube-controller-manager 来为其包含的每个控制器使用单独的 ServiceAccount,我们可以通过在其命令启动参数中添加如下标志来实现:
--use-service-account-credentials=true
credential凭证
一般情况下上面这个标志在大多数安装工具(如 kubeadm)中都是默认开启的,所以不需要单独配置了。
当 kube-controller-manager 开启上面的标志后,它将使用由 Kubernetes 自动生成的以下 ServiceAccount:
$ kubectl get serviceaccount -n kube-system | egrep -o '[A-Za-z0-9-]+-controller'
attachdetach-controller
calico-kube-controller
certificate-controller
clusterrole-aggregation-controller
cronjob-controller
daemon-set-controller
deployment-controller
disruption-controller
endpoint-controller
expand-controller
job-controller
namespace-controller
node-controller
pv-protection-controller
pvc-protection-controller
replicaset-controller
replication-controller
resourcequota-controller
service-account-controller
service-controller
statefulset-controller
ttl-controller
就是各类的控制器的serviceaccount,每个控制器都有自己的serviceaccount现在
这些 ServiceAccount 可以用来指定哪个控制器可以解析哪些策略的配置。
策略
PodSecurityPolicy 对象提供了一种声明式的方式,用于表达我们运行用户和 ServiceAccount 在我们的集群中创建的内容。我们可以查看策略文档来了解如何设置。在我们当前示例中,我们将创建2个策略,第一个是提供限制访问的“默认”策略,保证使用一些特权设置(例如使用 hostNetwork)无法创建 Pod。第二种是一个“提升”的许可策略,允许将特权设置用于某些 Pod,例如在 kube-system 命名空间下面创建的 Pod 有权限。
首先,创建一个限制性策略,作为默认策略
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: restrictive
spec:
privileged: false
hostNetwork: false
allowPrivilegeEscalation: false
defaultAllowPrivilegeEscalation: false
hostPID: false
hostIPC: false
runAsUser:
rule: RunAsAny
fsGroup:
rule: RunAsAny
seLinux:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
volumes: # TODO?为什么普通 Pod 会使用到 hostPath 的权限策略
- '*'
allowedCapabilities:
- '*'
虽然限制性的访问对于大多数 Pod 创建是足够的了,但是对于需要提升访问权限的 Pod 来说,就需要一些允许策略了,例如,kube-proxy 就需要启用 hostNetwork:
kubectl get pod -n kube-system pod_name -o yaml | grep hostNetwork
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: permissive
spec:
privileged: true
hostNetwork: true
hostIPC: true #ipc,进程间通信,pid,进程的id,这两个一般一块使用
hostPID: true
seLinux:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
runAsUser:
rule: RunAsAny
fsGroup:
rule: RunAsAny
hostPorts:
- min: 0
max: 65535
volumes: #允许使用各种volume
- '*'
现在配置都已经就绪了,但是我们需要引入到 Kubernetes 授权,这样才可以确定请求 Pod 创建的用户或者 ServiceAccount 是否解决了限制性或许可性策略,这就需要用到 RBAC 了。
策略已经配置好,就需要指定谁去用策略了
RBAC
在我们启用 Pod 安全策略的时候,可能会对 RBAC 引起混淆。它确定了一个账户(普通的用户或者serviceaccount)可以使用的策略,使用集群范围的 ClusterRoleBinding 可以为 ServiceAccount(例如 replicaset-controller)提供对限制性策略的访问权限。使用命名空间范围的 RoleBinding,可以启用对许可策略的访问,这样可以在特定的命名空间(如 kube-system)中进行操作。
首先创建允许使用 restrictive 策略的 ClusterRole。然后创建一个 ClusterRoleBinding,将 restrictive 策略和系统中所有的控制器 ServiceAccount 进行绑定:
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: psp-restrictive
rules:
- apiGroups:
- policy #psp的组,也可以写成个列表
resources:
- podsecuritypolicies #api资源名称
resourceNames:
- restrictive #psp的名称
verbs:
- use #操作名称
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: psp-default
subjects:
- kind: Group # 授权给 kube-system 下面的 serviceaccount,group表示一组用户,可以是普通用户也可以是serviceaccount
name: system:serviceaccounts #该group的名称
namespace: kube-system
roleRef:
kind: ClusterRole
name: psp-restrictive
apiGroup: rbac.authorization.k8s.io
kube-system下的serviceaccount有很多是控制器的serviceaccount,还有kube-proxy这个sa等等
直接apply创建上面RBAC相关的资源对象
这里要理解清楚,sa是有自身的归属的namespace的,但是它的操作权限可以是指定名称空间或者全局的,这取决于rolebinding和clusterrolebinding
这时候你在defalut名称空间下创建个deployment,其中的pod末班开启hostNetwork: true,会发现deploy和rs都能创建,但就是没有pod。
我们创建一个允许执行的 ClusterRole,然后为特定的命名空间创建一个 RoleBinding,将这里的 ClusterRole 和相关的控制器 ServiceAccount 进行绑定:
```bash
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: psp-permissive
rules:
- apiGroups:
- policy
resources:
- podsecuritypolicies
resourceNames:
- permissive
verbs:
- use
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: psp-permissive
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: psp-permissive
subjects:
- kind: ServiceAccount
name: replicaset-controller
namespace: kube-system
这时候在kube-system下创建的要求hostNetwork: true的pod是可以成功的
group解释
group表示用户组
serviceaccount,在kubernetes内对应的用户名称是
system:serviceaccount:namespace_name:serviceaccount_name
对应的内置用户组的名字是,系统的内置用户组即内置的serviceaccount用户组
system:serviceaccounts:namespace_name
特定应用的 ServiceAccount
如果我们现在有这样的一个需求,在某个命名空间下面要强制执行我们创建的 restrictive(限制性)策略,但是这个命名空间下面的某个应用需要使用 permissive(许可)策略,那么应该怎么办呢?在当前模型中,我们只有集群级别和命名空间级别的解析。为了给某个应用提供单独的许可策略,我们可以为应用的 ServiceAccount 提供使用 permissive 这个 ClusterRole 的能力。
比如,还是在默认的命名空间下面创建一个名为 specialsa 的 ServiceAccount:
(理解清楚一定,不管是role还是clusterrole,都只是对资源操作权限的定义,真正的效果还是binding)
$ kubectl create serviceaccount specialsa
serviceaccount/specialsa created
然后创建一个 RoleBinding 将 specialsa 绑定到上面的 psp-permissive 这个 CluterRole 上
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: specialsa-psp-permissive
namespace: default
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: psp-permissive
subjects:
- kind: ServiceAccount
name: specialsa
namespace: default
创建上面的 RoleBinding 对象:
$ kubectl apply -f specialsa-psp.yaml
rolebinding.rbac.authorization.k8s.io/specialsa-psp-permissive created
然后为我们上面的 Deployment 添加上 serviceAccount 属性
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-hostnetwork-deploy
namespace: default
labels:
app: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
hostNetwork: true
serviceAccount: specialsa # 注意这里使用的sa的权限绑定
然后直接创建即可:
$ kubectl apply -f nginx-hostnetwork-sa.yaml
deployment.apps/nginx-hostnetwork-deploy configured
这个时候我们查看 default 这个命名空间下面带有 hostNetwork 的 Pod 也创建成功了:
$ kubectl get po,rs,deploy -l app=nginx
NAME READY STATUS RESTARTS AGE
pod/nginx-hostnetwork-deploy-6c85dfbf95-hqt8j 1/1 Running 0 65s
NAME DESIRED CURRENT READY AGE
replicaset.extensions/nginx-hostnetwork-deploy-6c85dfbf95 1 1 1 65s
replicaset.extensions/nginx-hostnetwork-deploy-74c8fbd687 0 0 0 31m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.extensions/nginx-hostnetwork-deploy 1/1 1 1 31m
上面我们描述了 Pod 安全策略是一种通过使用 PSP 授权策略来保护 k8s 集群中的 Pod 的创建过程的方法。
静态 Pod
同样要解决上面静态 Pod 不出现的问题,我们也只需要给 kubelet 的用户添加一些策略即可:
# psp-node.yaml
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: node-psp
spec:
allowPrivilegeEscalation: true
allowedCapabilities:
- '*'
fsGroup:
rule: RunAsAny
hostIPC: true
hostNetwork: true
hostPID: true
hostPorts:
- max: 65535
min: 0
privileged: true
runAsUser:
rule: RunAsAny
seLinux:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
volumes:
- '*'
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: node:psp:privileged
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: node:psp:privileged
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:nodes
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kubelet
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: node:psp:privileged
rules:
- apiGroups:
- policy
resourceNames:
- node-psp
resources:
- podsecuritypolicies
verbs:
- use
我们声明一个 psp-node 的 PSP 对象,然后绑定到 system:nodes 这个 Group 和 kubelet 这个 User 上,创建完成后,就可以正常显示静态 Pod 了:
$ kubectl apply -f psp-node.yaml
$ kubectl get pods -n kube-system
准入控制器
Kubernetes 提供了需要扩展其内置功能的方法,最常用的可能是自定义资源类型和自定义控制器了,除此之外,Kubernetes 还有一些其他非常有趣的功能,比如 admission webhooks 就可以用于扩展 API,用于修改某些 Kubernetes 资源的基本行为。
准入控制器是在对象持久化之前用于对 Kubernetes API Server 的请求进行拦截的代码段,在请求经过身份验证和授权之后放行通过。准入控制器可能正在 validating、mutating 或者都在执行,Mutating 控制器可以修改他们处理的资源对象,Validating 控制器不会,如果任何一个阶段中的任何控制器拒绝了请求,则会立即拒绝整个请求,并将错误返回给最终的用户。
这意味着有一些特殊的控制器可以拦截 Kubernetes API 请求,并根据自定义的逻辑修改或者拒绝它们。Kubernetes 有自己实现的一个控制器列表:https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#what-does-each-admission-controller-do,当然你也可以编写自己的控制器,虽然这些控制器听起来功能比较强大,但是这些控制器需要被编译进 kube-apiserver,并且只能在 apiserver 启动时启动。
由于上面的控制器的限制,我们就需要用到动态的概念了,而不是和 apiserver 耦合在一起,Admission webhooks 就通过一种动态配置方法解决了这个限制问题。
admission webhook 是什么?
在 Kubernetes apiserver 中包含两个特殊的准入控制器:MutatingAdmissionWebhook 和ValidatingAdmissionWebhook,这两个控制器将发送准入请求到外部的 HTTP 回调服务并接收一个准入响应。如果启用了这两个准入控制器,Kubernetes 管理员可以在集群中创建和配置一个 admission webhook。

authentication阶段:主要是对发出请求到api-server的发起者身份进行验证,比如pod的token,sa和secret这些也行,都能用来证明自己在集群中的合法身份
整体的步骤如下所示:
检查集群中是否启用了 admission webhook 控制器,并根据需要进行配置。
编写处理准入请求的 HTTP回调,回调可以是一个部署在集群中的简单 HTTP 服务,甚至也可以是一个 serverless 函数,例如https://github.com/kelseyhightower/denyenv-validating-admission-webhook这个项目。
通过 MutatingWebhookConfiguration 和 ValidatingWebhookConfiguration资源配置 admission webhook。
这两种类型的 admission webhook 之间的区别是非常明显的:validating webhooks 可以拒绝请求,但是它们却不能修改准入请求中获取的对象,而 mutating webhooks 可以在返回准入响应之前通过创建补丁来修改对象,如果 webhook 拒绝了一个请求,则会向最终用户返回错误。
任意一个控制器错误都会给最终用户返回错误
创建配置一个 Admission Webhook
上面我们介绍了 Admission Webhook 的理论知识,接下来我们在一个真实的 Kubernetes 集群中来实际测试使用下,我们将创建一个 webhook 的 webserver,将其部署到集群中,然后创建 webhook 配置查看是否生效。
首先确保在 apiserver 中启用了 MutatingAdmissionWebhook 和 ValidatingAdmissionWebhook 这两个控制器,由于我这里集群使用的是 kubeadm 搭建的,可以通过查看 apiserver Pod 的配置:
(MutatingAdmissionWebhook可以用来修改过来的api请求,ValidatingAdmissionWebhook用来验证请求,这两个控制器各自在自己的阶段生效,注意有的控制器修改和验证同时进行)
$ kubectl get pods kube-apiserver-ydzs-master -n kube-system -o yaml
apiVersion: v1
kind: Pod
metadata:
labels:
component: kube-apiserver
tier: control-plane
name: kube-apiserver-ydzs-master
namespace: kube-system
......
spec:
containers:
- command:
- kube-apiserver
- --advertise-address=10.151.30.11
- --allow-privileged=true
- --authorization-mode=Node,RBAC
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --enable-admission-plugins=NodeRestriction,MutatingAdmissionWebhook,ValidatingAdmissionWebhook
......
上面的 enable-admission-plugins 参数中带上了 MutatingAdmissionWebhook 和ValidatingAdmissionWebhook 两个准入控制插件,如果没有的(当前 v1.19.x 版本是默认开启的),需要添加上这两个参数,然后重启 apiserver。
然后通过运行下面的命令检查集群中是否启用了准入注册 API:
$ kubectl api-versions |grep admission
admissionregistration.k8s.io/v1
admissionregistration.k8s.io/v1beta1
编写 webhook
满足了前面的先决条件后,接下来我们就来实现一个 webhook 示例,通过监听两个不同的 HTTP 端点(validate 和 mutate)来进行 validating 和 mutating webhook 验证。
这个 webhook 的完整代码可以在 Github 上获取:https://github.com/cnych/admission-webhook-example,该仓库 Fork 自项目 https://github.com/banzaicloud/admission-webhook-example。这个 webhook 是一个简单的带 TLS 认证的 HTTP 服务,用 Deployment 方式部署在我们的集群中。
代码中主要的逻辑在两个文件中:main.go 和 webhook.go,main.go 文件包含创建 HTTP 服务的代码,而webhook.go 包含 validates 和 mutates 两个 webhook 的逻辑,大部分代码都比较简单,首先查看 main.go 文件,查看如何使用标准 golang 包来启动 HTTP 服务,以及如何从命令行标志中读取 TLS 配置的证书:
flag.StringVar(¶meters.certFile, "tlsCertFile", "/etc/webhook/certs/cert.pem", "File containing the x509 Certificate for HTTPS.")
flag.StringVar(¶meters.keyFile, "tlsKeyFile", "/etc/webhook/certs/key.pem", "File containing the x509 private key to --tlsCertFile.")
然后一个比较重要的是 serve 函数,用来处理传入的 mutate 和 validating 函数 的 HTTP 请求。该函数从请求中反序列化 AdmissionReview 对象,执行一些基本的内容校验,根据 URL 路径调用相应的 mutate 和 validate 函数,然后序列化 AdmissionReview 对象:
func (whsvr *WebhookServer) serve(w http.ResponseWriter, r *http.Request) {
var body []byte
if r.Body != nil {
if data, err := ioutil.ReadAll(r.Body); err == nil {
body = data
}
}
if len(body) == 0 {
glog.Error("empty body")
http.Error(w, "empty body", http.StatusBadRequest)
return
}
// 校验 Content-Type
contentType := r.Header.Get("Content-Type")
if contentType != "application/json" {
glog.Errorf("Content-Type=%s, expect application/json", contentType)
http.Error(w, "invalid Content-Type, expect `application/json`", http.StatusUnsupportedMediaType)
return
}
var admissionResponse *v1beta1.AdmissionResponse
ar := v1beta1.AdmissionReview{}
if _, _, err := deserializer.Decode(body, nil, &ar); err != nil {
glog.Errorf("Can't decode body: %v", err)
admissionResponse = &v1beta1.AdmissionResponse{
Result: &metav1.Status{
Message: err.Error(),
},
}
} else {
if r.URL.Path == "/mutate" {
admissionResponse = whsvr.mutate(&ar)
} else if r.URL.Path == "/validate" {
admissionResponse = whsvr.validate(&ar)
}
}
admissionReview := v1beta1.AdmissionReview{}
if admissionResponse != nil {
admissionReview.Response = admissionResponse
if ar.Request != nil {
admissionReview.Response.UID = ar.Request.UID
}
}
resp, err := json.Marshal(admissionReview)
if err != nil {
glog.Errorf("Can't encode response: %v", err)
http.Error(w, fmt.Sprintf("could not encode response: %v", err), http.StatusInternalServerError)
}
glog.Infof("Ready to write reponse ...")
if _, err := w.Write(resp); err != nil {
glog.Errorf("Can't write response: %v", err)
http.Error(w, fmt.Sprintf("could not write response: %v", err), http.StatusInternalServerError)
}
}
主要的准入逻辑是 validate 和 mutate 两个函数。validate 函数检查资源对象是否需要校验:不验证 kube-system 和 kube-public 两个命名空间中的资源,如果想要显示的声明不验证某个资源,可以通过在资源对象中添加一个 admission-webhook-example.qikqiak.com/validate=false 的 annotation 进行声明。如果需要验证,则根据资源类型的 kind,和标签与其对应项进行比较,将 service 或者 deployment 资源从请求中反序列化出来。如果缺少某些 label 标签,则响应中的 Allowed 会被设置为 false。如果验证失败,则会在响应中写入失败原因,最终用户在尝试创建资源时会收到失败的信息。validate 函数实现如下所示:
// validate deployments and services
func (whsvr *WebhookServer) validate(ar *v1beta1.AdmissionReview) *v1beta1.AdmissionResponse {
req := ar.Request
var (
availableLabels map[string]string
objectMeta *metav1.ObjectMeta
resourceNamespace, resourceName string
)
glog.Infof("AdmissionReview for Kind=%v, Namespace=%v Name=%v (%v) UID=%v patchOperation=%v UserInfo=%v",
req.Kind, req.Namespace, req.Name, resourceName, req.UID, req.Operation, req.UserInfo)
switch req.Kind.Kind {
case "Deployment":
var deployment appsv1.Deployment
if err := json.Unmarshal(req.Object.Raw, &deployment); err != nil {
glog.Errorf("Could not unmarshal raw object: %v", err)
return &v1beta1.AdmissionResponse{
Result: &metav1.Status{
Message: err.Error(),
},
}
}
resourceName, resourceNamespace, objectMeta = deployment.Name, deployment.Namespace, &deployment.ObjectMeta
availableLabels = deployment.Labels
case "Service":
var service corev1.Service
if err := json.Unmarshal(req.Object.Raw, &service); err != nil {
glog.Errorf("Could not unmarshal raw object: %v", err)
return &v1beta1.AdmissionResponse{
Result: &metav1.Status{
Message: err.Error(),
},
}
}
resourceName, resourceNamespace, objectMeta = service.Name, service.Namespace, &service.ObjectMeta
availableLabels = service.Labels
}
if !validationRequired(ignoredNamespaces, objectMeta) {
glog.Infof("Skipping validation for %s/%s due to policy check", resourceNamespace, resourceName)
return &v1beta1.AdmissionResponse{
Allowed: true,
}
}
allowed := true
var result *metav1.Status
glog.Info("available labels:", availableLabels)
glog.Info("required labels", requiredLabels)
for _, rl := range requiredLabels {
if _, ok := availableLabels[rl]; !ok {
allowed = false
result = &metav1.Status{
Reason: "required labels are not set",
}
break
}
}
return &v1beta1.AdmissionResponse{
Allowed: allowed,
Result: result,
}
}
判断是否需要进行校验的方法如下,可以通过 namespace 进行忽略,也可以通过 annotations 设置进行配置:
func validationRequired(ignoredList []string, metadata *metav1.ObjectMeta) bool {
required := admissionRequired(ignoredList, admissionWebhookAnnotationValidateKey, metadata)
glog.Infof("Validation policy for %v/%v: required:%v", metadata.Namespace, metadata.Name, required)
return required
}
func admissionRequired(ignoredList []string, admissionAnnotationKey string, metadata *metav1.ObjectMeta) bool {
// skip special kubernetes system namespaces
for _, namespace := range ignoredList {
if metadata.Namespace == namespace {
glog.Infof("Skip validation for %v for it's in special namespace:%v", metadata.Name, metadata.Namespace)
return false
}
}
annotations := metadata.GetAnnotations()
if annotations == nil {
annotations = map[string]string{}
}
var required bool
switch strings.ToLower(annotations[admissionAnnotationKey]) {
default:
required = true
case "n", "no", "false", "off":
required = false
}
return required
}
mutate 函数的代码是非常类似的,但不是仅仅比较标签并在响应中设置 Allowed,而是创建一个补丁,将缺失的标签添加到资源中,并将 not_available 设置为标签的值。
// main mutation process
func (whsvr *WebhookServer) mutate(ar *v1beta1.AdmissionReview) *v1beta1.AdmissionResponse {
req := ar.Request
var (
availableLabels, availableAnnotations map[string]string
objectMeta *metav1.ObjectMeta
resourceNamespace, resourceName string
)
glog.Infof("AdmissionReview for Kind=%v, Namespace=%v Name=%v (%v) UID=%v patchOperation=%v UserInfo=%v",
req.Kind, req.Namespace, req.Name, resourceName, req.UID, req.Operation, req.UserInfo)
switch req.Kind.Kind {
case "Deployment":
var deployment appsv1.Deployment
if err := json.Unmarshal(req.Object.Raw, &deployment); err != nil {
glog.Errorf("Could not unmarshal raw object: %v", err)
return &v1beta1.AdmissionResponse{
Result: &metav1.Status{
Message: err.Error(),
},
}
}
resourceName, resourceNamespace, objectMeta = deployment.Name, deployment.Namespace, &deployment.ObjectMeta
availableLabels = deployment.Labels
case "Service":
var service corev1.Service
if err := json.Unmarshal(req.Object.Raw, &service); err != nil {
glog.Errorf("Could not unmarshal raw object: %v", err)
return &v1beta1.AdmissionResponse{
Result: &metav1.Status{
Message: err.Error(),
},
}
}
resourceName, resourceNamespace, objectMeta = service.Name, service.Namespace, &service.ObjectMeta
availableLabels = service.Labels
}
if !mutationRequired(ignoredNamespaces, objectMeta) {
glog.Infof("Skipping validation for %s/%s due to policy check", resourceNamespace, resourceName)
return &v1beta1.AdmissionResponse{
Allowed: true,
}
}
annotations := map[string]string{admissionWebhookAnnotationStatusKey: "mutated"}
patchBytes, err := createPatch(availableAnnotations, annotations, availableLabels, addLabels)
if err != nil {
return &v1beta1.AdmissionResponse{
Result: &metav1.Status{
Message: err.Error(),
},
}
}
glog.Infof("AdmissionResponse: patch=%v\n", string(patchBytes))
return &v1beta1.AdmissionResponse{
Allowed: true,
Patch: patchBytes,
PatchType: func() *v1beta1.PatchType {
pt := v1beta1.PatchTypeJSONPatch
return &pt
}(),
}
}
以上这些是实现部分准入控制器的go代码,建议学了go再看,没学可以先跳过
构建
其实我们已经将代码打包成一个 docker 镜像了,你可以直接使用,镜像仓库地址为:cnych/admission-webhook-example:v1。当然如果你希望更改部分代码,那就需要重新构建项目了,由于这个项目采用 go 语言开发,包管理工具更改为了 go mod,所以我们需要确保构建环境提前安装好 go 环境,当然 docker 也是必不可少的,因为我们需要的是打包成一个 docker 镜像。
获取项目:
$ mkdir admission-webhook && cd admission-webhook
$ git clone https://github.com/cnych/admission-webhook-example.git
我们可以看到代码根目录下面有一个 build 的脚本,只需要提供我们自己的 docker 镜像用户名然后直接构建即可:
$ export DOCKER_USER=cnych
$ ./build
部署
为了部署 webhook server,我们需要在我们的 Kubernetes 集群中创建一个 service 和 deployment 资源对象,部署是非常简单的,只是需要配置服务的 TLS 配置。我们可以在代码根目录下面的 deployment 文件夹下面查看deployment.yaml 文件中关于证书的配置声明,会发现从命令行参数中读取的证书和私钥文件是通过一个 secret 对象挂载进来的:
args:
- -tlsCertFile=/etc/webhook/certs/cert.pem
- -tlsKeyFile=/etc/webhook/certs/key.pem
[...]
volumeMounts:
- name: webhook-certs
mountPath: /etc/webhook/certs
readOnly: true
volumes:
- name: webhook-certs
secret:
secretName: admission-webhook-example-certs
在生产环境中,对于 TLS 证书(特别是私钥)的处理是非常重要的,我们可以使用类似于 cert-manager 之类的工具来自动处理 TLS 证书,或者将私钥密钥存储在 Vault 中,而不是直接存在 secret 资源对象中。
我们可以使用任何类型的证书,但是需要注意的是我们这里设置的 CA 证书是需要让 apiserver 能够验证的,我们这里可以重用 Istio 项目中的生成的证书签名请求脚本。通过发送请求到 apiserver,获取认证信息,然后使用获得的结果来创建需要的 secret 对象。
首先,运行该脚本检查 secret 对象中是否有证书和私钥信息:
$ ./deployment/webhook-create-signed-cert.sh
creating certs in tmpdir /var/folders/x3/wjy_1z155pdf8jg_jgpmf6kc0000gn/T/tmp.IboFfX97
Generating RSA private key, 2048 bit long modulus (2 primes)
..................+++++
........+++++
e is 65537 (0x010001)
certificatesigningrequest.certificates.k8s.io/admission-webhook-example-svc.default created
NAME AGE REQUESTOR CONDITION
admission-webhook-example-svc.default 1s kubernetes-admin Pending
certificatesigningrequest.certificates.k8s.io/admission-webhook-example-svc.default approved
secret/admission-webhook-example-certs created
$ kubectl get secret admission-webhook-example-certs
NAME TYPE DATA AGE
admission-webhook-example-certs Opaque 2 28s
一旦 secret 对象创建成功,我们就可以直接创建 deployment 和 service 对象。
$ kubectl apply -f deployment/rbac.yaml
$ kubectl apply -f deployment/deployment.yaml
deployment.apps "admission-webhook-example-deployment" created
$ kubectl apply -f deployment/service.yaml
service "admission-webhook-example-svc" created
配置 webhook¶
现在我们的 webhook 服务运行起来了,它可以接收来自 apiserver 的请求。但是我们还需要在 kubernetes 上创建一些配置资源。首先来配置 validating 这个 webhook,查看 webhook 配置,我们会注意到它里面包含一个 CA_BUNDLE 的占位符:
clientConfig:
service:
name: admission-webhook-example-svc
namespace: default
path: "/validate"
caBundle: ${CA_BUNDLE}
CA 证书应提供给 admission webhook 配置,这样 apiserver 才可以信任 webhook server 提供的 TLS 证书。因为我们上面已经使用 Kubernetes API 签署了证书,所以我们可以使用我们的 kubeconfig 中的 CA 证书来简化操作。代码仓库中也提供了一个小脚本用来替换 CA_BUNDLE 这个占位符,创建 validating webhook 之前运行该命令即可:
$ cat ./deployment/validatingwebhook.yaml | ./deployment/webhook-patch-ca-bundle.sh > ./deployment/validatingwebhook-ca-bundle.yaml
执行完成后可以查看 validatingwebhook-ca-bundle.yaml 文件中的 CA_BUNDLE 占位符的值是否已经被替换掉了。需要注意的是 clientConfig 里面的 path 路径是 /validate,因为我们代码在是将 validate 和 mutate 集成在一个服务中的。
然后就是需要配置一些 RBAC 规则,我们想在 deployment 或 service 创建时拦截 API 请求,所以 apiGroups 和apiVersions 对应的值分别为 apps/v1 对应 deployment,v1 对应 service。
webhook 的最后一部分是配置一个 namespaceSelector,我们可以为 webhook 工作的命名空间定义一个 selector,这个配置不是必须的,比如我们这里添加了下面的配置:
namespaceSelector:
matchLabels:
admission-webhook-example: enabled
则我们的 webhook 会只适用于设置了 admission-webhook-example=enabled 标签的 namespaces。
所以,首先需要在 default 这个 namespace 中添加该标签:
$ kubectl label namespace default admission-webhook-example=enabled
namespace "default" labeled
最后,创建这个 validating webhook 配置对象,这会动态地将 webhook 添加到 webhook 链上,所以一旦创建资源,就会拦截请求然后调用我们的 webhook 服务:
$ kubectl apply -f deployment/validatingwebhook-ca-bundle.yaml
validatingwebhookconfiguration.admissionregistration.k8s.io "validation-webhook-example-cfg" created
测试
现在让我们创建一个 deployment 资源来验证下是否有效,代码仓库下有一个 sleep.yaml 的资源清单文件,直接创建即可:
$ kubectl apply -f deployment/sleep.yaml
Error from server (required labels are not set): error when creating "deployment/sleep.yaml": admission webhook "required-labels.qikqiak.com" denied the request: required labels are not set
正常情况下创建的时候会出现上面的错误信息,然后部署另外一个 sleep-with-labels.yaml 的资源清单:
$ kubectl apply -f deployment/sleep-with-labels.yaml
deployment.apps "sleep" created
可以看到可以正常部署,然后我们将上面的 deployment 删除,然后部署另外一个 sleep-no-validation.yaml 资源清单,该清单中不存在所需的标签,但是配置了 admission-webhook-example.qikqiak.com/validate=false 这样的 annotation,所以正常也是可以正常创建的:
$ kubectl delete deployment sleep
$ kubectl apply -f deployment/sleep-no-validation.yaml
deployment.apps "sleep" created
部署 mutating webhook
首先,我们将上面的 validating webhook 删除,防止对 mutating 产生干扰,然后部署新的配置。 mutating webhook 与 validating webhook 配置基本相同,但是 webook server 的路径是 /mutate,同样的我们也需要先填充上 CA_BUNDLE 这个占位符。
$ kubectl delete validatingwebhookconfiguration validation-webhook-example-cfg
validatingwebhookconfiguration.admissionregistration.k8s.io "validation-webhook-example-cfg" deleted
$ cat ./deployment/mutatingwebhook.yaml | ./deployment/webhook-patch-ca-bundle.sh > ./deployment/mutatingwebhook-ca-bundle.yaml
$ kubectl apply -f deployment/mutatingwebhook-ca-bundle.yaml
mutatingwebhookconfiguration.admissionregistration.k8s.io "mutating-webhook-example-cfg" created
现在我们可以再次部署上面的 sleep 应用程序,然后查看是否正确添加 label 标签:
$ kubectl apply -f deployment/sleep.yaml
deployment.apps "sleep" created
$ kubectl get deploy sleep -o yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
admission-webhook-example.qikqiak.com/status: mutated
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2020-06-01T08:10:04Z"
generation: 1
labels:
app.kubernetes.io/component: not_available
app.kubernetes.io/instance: not_available
app.kubernetes.io/managed-by: not_available
app.kubernetes.io/name: not_available
app.kubernetes.io/part-of: not_available
app.kubernetes.io/version: not_available
name: sleep
namespace: default
...
最后,我们重新创建 validating webhook,来一起测试。现在,尝试再次创建 sleep 应用。正常是可以创建成功的,我们可以查看下 admission-controllers 的文档。
准入控制分两个阶段进行,第一阶段,运行 mutating admission 控制器,第二阶段运行 validating admission 控制器。
所以 mutating webhook 在第一阶段添加上缺失的 labels 标签,然后 validating webhook 在第二阶段就不会拒绝这个 deployment 了,因为标签已经存在了,用 not_available 设置他们的值。
$ kubectl apply -f deployment/validatingwebhook-ca-bundle.yaml
validatingwebhookconfiguration.admissionregistration.k8s.io "validation-webhook-example-cfg" created
$ kubectl apply -f deployment/sleep.yaml
deployment.apps "sleep" created
MutatingAdmissionWebkook和ValidatingAdmissionWebhook主要使用场景是istio