Spark SQL: Relational Data Processing in Spark(SparkSQL原理解密,希望对大家有所帮助)
Spark SQL: Relational Data Processing in Spark
Michael Armbrusty, Reynold S. Xiny, Cheng Liany, Yin Huaiy, Davies Liuy, Joseph K. Bradleyy,Xiangrui Mengy, Tomer Kaftanz, Michael J. Franklinyz, Ali Ghodsiy, Matei Zahariay_y
Databricks Inc. _MIT CSAIL zAMPLab, UC Berkeley
Philipse Guo(郭飞 翻译整理)
欢迎转载,请标明文档出处:https://mp.csdn.net/postedit/85331857
摘要:
Spark SQL是Apache Spark下一个新模块,它集成了关系型操作和函数编程API于一体,基于我们的Shark经验,Spark SQL不仅可以让Spark开发者利用关系型(数据)处理的优势(比如声明式的查询和最优化的存储等),还可以让SQL开发者调用Spark里面的复杂库类(比如机器学习等),与之前的系统相比,Spark SQL新增了两个主要功能,其一,关系型操作和程序性操作结合更加紧密了,通过声明式的DataFrame API可以很好的和Spark代码结合起来,其二,他提供了可高度拓展的优化器Catalyst,Catalyst利用Scala编程语言的特色,让新增规则,代码生成控制和自定义拓展功能操作更加容易了。有了Catalyst我们就多了很多新特性(比如JSON格式数据的结构推测,机器学习的类型和结合外部数据库组合查询等),即使是很复杂的数据分析需求也变得很得心应手。SparkSQL在保证Spark编程模型不被破坏的前提下提供更丰富的API和各种优化,这不仅仅是SQL-On-Spark的一次革命,同时也是Spark自身的一次升华。
目录和主题描述
H.2数据库管理系统:系统
关键字:
数据库;数据仓库;机器学习;Spark;Hadoop
一:简介
大数据的应用系统需要面对多种数据处理技术,各种数据源和五花八门的数据格式,最早期的系统为此提供一个功能强大的,但是低级的过程程序设计接口,比如MapReduce。像这样的程序略显笨重,需要用户手动调优才能达到一个比较好的性能。因此,各种新系统通过提供大数据下的关系型操作的接口争相给用户一种更好的体验,这些系统利用声明式的查询来提供更丰富的自动优化方案,比如Pig,Hive,Dremel和Shark。
尽管关系型系统的流行昭示着用户更喜欢写声明式的查询,但关系型系统的一些解决方案在面对大数据应用场景下也经常捉襟见肘,首先,用户想要通过自定义代码来ETL处理来自各种数据源的半结构化或非结构化的数据,其次,用户想要进行一些高级分析,比如机器学习和图计算,这些在关系型系统中想要实现非常困难,实际上,我们观察到大多数数据更适合在关系型查询和复杂的程序算法中一起处理,不幸的是,这两种系统目前结合的并不好,一般都是让用户去选择其一。
本篇论文描述了我们在SparkSQL中结合两种模型的努力,一个Apache Spark的一个子模块,SparkSQL是基于最早起的SQL-on-Spark,俗称Shark,为了不让用户选择使用关系型或者过程程序设计API,SparkSQL把二者组合了一起,真正做到的无缝衔接。
SparkSQL通过两个特征把这两种模型结合起来,首先是DataFrame API,它可以对外部的数据源和Spark程序中的数据进行关系型的操作,这和使用广泛的R语言的dataFrame概念类似,不过SparkSQL是延迟运算的模式,在运算之前会进行关系型操作的优化;其次,为了支持更多的数据源和大数据应用的各种场景的算法,SparkSQL引进的一种新型可拓展的优化器Catalyst.使得新增数据源、优化规则和不同领域的数据类型(比如机器学习)更加便利。
DataFrame API在Spark程序中集成了丰富的关系型操作和过程程序操作,DataFrame是一种结构化记录的数据集,这可以通过Spark程序API来操作,也可以通过支持更丰富的优化器的关系型API来使用。DataFrame可以通过Spark程序内的JAVA/Python对象直接创建,这使得在Spark程序中进行关系型操作成为可能。还有其他的Spark相关的组件,比如机器学习库,也可以正常创建和使用DataFrame。一般应用场景下,DataFrame比Spark程序API在易操作性和使用效率上都更胜一筹。例如,DataFrame使用SQL语句可以很轻松对数据进行多种聚合操作,过程中仅仅需要读取数据一次,传统的函数式API要实现这一功能要相对困难些。DataFrame可以自动把数据进行存储列式,而不是松散的JAVA/Python对象。最后DataFrame与已有的R和Python的设计API不同, Spark sql在DataFrame操作中拥有关系型优化器,Catalyst.
为了在SparkSQL中支持更多的数据源和分析场景,我们设计了一种可拓展的查询优化器Catalyst,Catalyst利用Scala编程语言的特色(例如如规则匹配)通过使用Turingcomplete language(见注解1)来构建各种组合规则,同时提供一套通用的框架来对树节点进行操作,比如语法分析,生成执行计划和运行时的代码,有了这个架构我们可以很轻松的新增数据源,包括类似JSON一样的半结构化的数据集,同时把优化的数据(前文有提过列式存储)推到下游,比如hbase;通过自定义函数和自定义特定领域的一些数据类型(如机器学习等)。众所周知,函数式编程语言比较适合开发编译器,因此,基于Scala的优化器开发也相对比较容易,有了Catalyst的SparkSQL如虎添翼,自发布之后,我们看到好多外部的贡献者也把Catalyst加到他们的项目中。
SparkSQL发布于2014年5月,目前也是Spark家族中较成熟和活跃的成员,日前,Apache Spark是大数据处理领域里最活跃的开源项目,仅去年就有400个contributors做过贡献,SparkSQL在超大数据规模环境中也已有应用场景,比如,一家大量互联网公司使用SparkSQL来处理数据流,在8000个节点的集群上进行查询,数据量超过100PB,正常每次操作有数十TB的数据,不仅如此,很多用户采用SparkSQL不仅仅是由于它的SQL查询,更是看中它可以在Spark程序中集成程序设计语言的特性,比如,2/3的Databricks Cloud客户使用Spark的同时也在程序中集成SparkSQL一起使用。在性能方面,我们发现SparkSQL在使用SQL on hadoop的关系型查询中有着不俗的表现,同样的功能用SparkSQL的速度比用Spark代码快10倍,而且内存使用更少。
一般情况我们认为SparkSQL是SparkCore API的一次重大革命,原始的Spark函数式编程API比较普通,程序自动优化的空间很小,Spark SQL在拓宽Spark受众的同时也在提升Spark在优化方面的短板,Spark社区内目前正在把SparkSQL集成到更多的SPARK API中,在机器学习领域,DataFrames利用一种创新的“ML pipeline” API已经成为标准的数据表达方式,我们希望把次推广到更多的领域中去,比如图计算和流。
本篇论文起于Spark的背景和SparkSQL的目标,第二章会对DataFrame API对进一步的讲解,第三章主要介绍Catalyst优化器,第四章,聊聊我们在Catalyst中新增的高级特性,第五章讲SparkSQL的应用,第六章重点会在Catalyst上我们做的一些外部探索,第七章,总结,第八章,涉及到相关工作
二、背景和目标
2.1 Spark概述
Spark是2010年发布的一个通用的集群计算引擎,它包括Scala, Java and Python的API,流处理的库类,图计算和机器学习功能,据我所知,它是目前使用最广泛的多语言集成API系统之一,与DryadLINQ比较相似,同时它也是大数据处理领域中最活跃的开源项目,截止2014年,我们总共有400名贡献者,被多家公司使用。
Spark和最近流行的其他系统比较类似,也是提供一种函数式的编程API,用户可以在Resilient Distributed Datasets (RDDs)中操作他们的数据集,每一个RDD都含有分布在不同集群节点上的JAVA和Python对象,RDDs可以通过算子(如map,filter,reduce等)来操作,编程语言中使用这些算子可以将RDD在节点之间进行传递,例如,下面的Scala代码可以计算一个文本文件中的行数,每行数据都是以“ERRIR”打头。
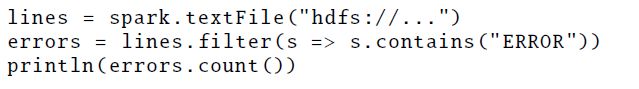
上面的代码创建了RDD,逐行读取Hdfs文件,然后使用filter算子得到新的RDD errors,然后在此基础上再进行计数
RDDs是容错的,通过RDDs的线性图可以恢复丢失的数据(通过重新运行算子的方式进行重建丢失的数据,如上就是filter算子),RDDs也可以缓存到内存中或写到磁盘里,为下一步的迭代操作做准备。
值得注意的是RDDs是一种懒运算模式,每个RDD代表一个操作数据集的逻辑计划,但是Spark只有等到特定的输出算子才会真正的开始计算,比如count算子,在此之前执行引擎可以进行一些简单的优化,比如管道流优化,以上面的代码为例,Spark会以管道的方式逐行读取HDFS的数据,然后应用到filter算子,最后计算行数,所以过程中没有必要对中间的Lines和errors进行物化存储,这其实很关键,因为引擎可能不知道RDDs中数据的结构(可以是任意的JAVA或者Python对象)或用户自定义函数的专有名词(可以是任意的代码语言)
2.2 Spark之前的关系型操作系统
Shark是我们在Spark上首次尝试使用关系型操作接口,Shark让Hive可以以Spark引擎进行计算,同时进行了一些关系型数据库操作系统的优化,比如列式存储,尽管Shark和Spark程序结合的也很好,但是还有三个主要的挑战,第一,Shark只能查询存储在Hive catalog中的数据,不能对Spark程序中的数据进行关系型查询(比如上面创建的errors)。第二,Spark程序调用Shark的唯一方式就是拼成一个SQL字符串,这在模块化程序中会带来了极大的不便,同时也更易出错。最后,Hive的优化器专用于MapReduce,不易拓展,如果想要新增一些机器学习的数据类型或支持更多的数据源就会变得很困难。
2.3 SparkSQL的设计目标
根据Shark的经验,我们想在spark程序中的RDDs和更多的数据源都使用到关系型操作,我们来看下SparkSQL的设计目标:
- 不仅支持Spark程序中(原生的RDDs)的关系型处理,也支持外部的一些编程性良好的API的关系型处理
- 可以利用已有的关系型数据库管理系统的操作技巧优化程序的性能
- 易于新增数据源,包括半结构化和外部数据源,支持联合查询
- 可以拓展一些高级分析算法,比如图计算和机器学习
三、编程接口
Spark sql作为Spark中的一个库来使用(见下图Figure1),它暴露的SQL接口,可以通过JDBC/ODBC或者命令行提供给外界去访问,也可以通过集成到Spark程序中的DataFrame API来访问,我们从DataFrame API开始支持,这样用户可以把程序代码和关系型代码放在一起使用,不过,高级函数本身也可以通过自定义函数的方式对外以SQL暴露出去,用户可以通过BI工具来使用,3.7节我们会讨论自定义函数

3.1 DataFrame API
SparkSQL API最抽象的部分就是DataFrame(见注解)了,这是一种带有相同schema的分布式数据行集合,DataFrame可以理解为关系型数据库中的表概念,它的操作也类似于操作Spark原生的分布式数据集合(RDDs),与RDDs不同的是,DataFrame可以记录数据的schema信息,并且还支持多种关系型操作,后期可以做更多的优化。
DataFrames可以通过数据库中表(如外部的数据库)来创建,也可以通过JAVA/Python代码中原生的RDDs来创建(见3.5),DataFrames被创建好后就可以通过多种关系型操作算子进行操作,比如where,groupby,这些都是用DSL(domain-specific language)进行表达的,与R,python里面的data frames比较像,每个DataFrames可以当成是行对象RDD,DataFrames允许用户来调用程序设计Spark APIs,比如map
下面我们来聊聊DataFrame API.的细节部分。
3.2 数据模型
SparkSQL的Tables和DataFrames缘于一种基于hive的嵌套模型,SparkSQL支持目前主流的数据类型,包括boolean, integer, double, decimal, string, date, and timestamp和一些复杂数据类型,如structs, arrays, maps and unions.复杂数据类型之间可以再进行嵌套组合成更强大的数据类型,与很多传统的关系型数据库管理系统不同,SparkSQL在关系型查询语句和API操作复杂数据类型时表现非常卓越,SparkSQL还支持用户自定义数据类型,章节4.4.2会提及到。
通过DataFrames,我们可以从多种数据源和各种数据格式中生成精确的目标模型,包括Hive,关系型数据库,JSON和原生的Java/python/Scala产生的原生对象。
3.3 DataFrame算子
用户可以使用DSL在DataFrames上进行关系型操作,DataFrames支持所有一般关系型操作的算子,包括projection(select),filter(where),join和aggregations (groupBy).这些算子在DSL都相应的表达式,从而使得Spark可以捕获到这些表达式的结构,例如下面代码计算每个部门女性的人数

在这里,employees就是一个DataFrames,employees("deptId")就是一个描述deptid列的一个表达式,表达式对象通过不同的算子产生新的表达式,包括常见的比较算子(===表示相等,)表示大于,还有一些算术运行符+,-等),同时DataFrames还支持聚合,比如(count("name")),所有这些算子都会生成一个抽象语法树(AST)表达式,然后表达式会传给Catalyst做下一步的优化,这和Spark API生成的原生代码不同,原生代码在运行的时候是不可见的,希望了解API详情的同学可以参考Spark官方文档。
除了可以使用关系型DSL外,DataFrames可以通过关系型数据库中的表注册为临时表,然后用户可以通过SQL进行查询,下面就是一个例子。

SQL有时候在单纯的多聚合计算场景下是比较方面的,并且还可以通过JDBC/ODBC对外提供这些数据,注册好的DataFrames没有做物化存储,所以从SQL到原始的DataFrame表达式可以进行很多优化,值得一提的是,DataFrame也可以做物化存储,3.6节会提到这个
3.4 DataFrames对比关系型查询语言
从表面上看,DataFrames提供了和关系型查询(hive,pig)语句一样的操作,但是经过社区的集成后,DataFrames变得更友好易用,比如,用户可以把他们的代码转化为Scala, Java 或Python函数,然后传递DataFrames,生成一个逻辑执行计划,在执行输出操作时,整个执行计划都可以进行优化,同样道理,开发者可以使用程序控制语言,比如if语句和循环语句来完成他们的工作,有个用户曾经说过,DataFrame API的简单易用和声明式的操作和SQL很像,就是不能给中间生成的结果数据进行命名(郭飞解:反讽的说法),意思是这种整体计算和debug操作是有多么的透明和易掌握
DataFrames,为了简化编程,前置了API分析逻辑计划(可以提前知道这个表达式中使用的列是不是在已有的表中,数据类型是否合适),尽管查询结果是延迟计算的,Spark SQL还是可以当用户输入无效的代码立刻把错误报出来,而不需要等到代码执行的时候才发现,与大的关系型SQL语句查询对比,效果会更好。
3.5 查询本地数据集
真实世界中的管道流数据来自四面八方,算法也不尽相同,为了更好的和Spark程序代码进行集成,Spark SQL允许用户可以直接使用各种编程语言写的RDD直接进行构建DataFrames,它可以通过反射拿到这些对应的schema信息,在Scala和Java语言中,相关的反射类信息是从语言的类库中获得(从JavaBeans and Scala的类库),Python,语言由于动态类的特性,Spark SQL只需抽样部分反射schema信息的数据集就可以了
例如,下面的Scala代码就是利用一个USER对象的RDD定义了一个DataFrame。

一般来说,Spark SQL创建了一个指向RDD的逻辑数据扫描算子,这个算子进一步转化为物理操作算子,然后就可以直接访问代码中的原生对象了,值得注意的是这和传统的ORM(object-relational mapping)有很大的不同,ORMs在把整个对象转换为另外一个格式时需要付出很大的代价,相反,Spark SQL可以直接访问原生的对象,而且每次查询的时候仅仅需要抽取指定的字段就可以了。
Spark SQL能够直接访问原生的数据集,这使得用户可以在Spark代码中进行关系型算子的优化,不仅如此,它还可以把轻易地集成RDDs和外部的数据集,例如,我们可以把Hive中的一个表和USER对象的RDD进行Join操作

3.6 内存缓存
和之前的Shark一样,Spark SQL可以在内存中列式物化(也可以叫缓存)热数据,与Spark原生的缓存相比,Spark SQL物化就像把数据存在JVM对象里一样简单,列式存储使用列式压缩编码比如字典编码和运行时长编码,这大大减少了内存的占用。缓存在在交互式的查询和机器学习里面的迭代算法运行时显得尤为重要,可以通过调用DataFrame.的cache()
3.7 自定义函数
自定义函数(UDFS)对于数据库系统来说一直以来都是一种重要的拓展,例如,Mysql以来UDFs来处理JSON数据,Postgres and other database systems也有通过MADLib的UDFs来实现机器学习算法,不过数据库系统经常需要再单独的程序环中去定义这些UDFs,和主要的查询接口是分离开的,Spark SQL的DataFrame API支持行内定义UDFs,不需要额外的打包或注册到外部的数据库系统中,这也是我们采用它的重要因素。
Spark SQL中, UDFs可以通过Scala,Java 或者Python的函数进行注册,也可以使用Spark自带的一些API来注册,比方说,给定一个机器学习的模型,我们可以这样注册为UDF

一旦注册成功,这个UDF就可以用BI工具的JDBC/ODBC接口来进行访问,除了上面这个操作数值的UDF外,我们还可以通过一个名称来操作整张表,像MADLib一样,同时还可以集成Spark API一起使用,这样SQL开发者就可以使用到高级分析函数了,最后,由于UDF的定义和查询执行都是使用一种主要语言(Scala或者Python),用户可以使用标准工具来debug整个或设计整个程序。
上面的例子演示了多个管道流下的一种通用使用场景,比如,用户既可以使用关系型算子,也可以使用高级分析方法来满足各种的需求,这些如果通过SQL实现都比较困难,DataFrame API可以让用户使用SparkSql时做到无缝衔接
四、 Catalyst优化器
为了实现SparkSQL,我们设计了基于Scala函数编程架构一种新型可拓展的优化器Catalyst, Catalyst的拓展设计主要基于两种考虑,其一,我们想要快速的为SparkSQL新增优化技术和新的特性,这样我们可以处理大数据下的各种大场景(比如半结构化的数据和高级分析场景),其次,我们想要外部的开发者们也一起参与到开发优化器的过程中来,例如,通过新增数据源的特殊规则可以把算子运算好的数据落到外部存储介质中去,或者可以生成新的数据类型供后续使用,Catalyst支持基于规则的优化和基于代价的优化
尽管在过去拓展优化器经常被提到,不过这些一般情况下倾向于使用复杂的DSL去实现这个规则,然后编译优化器把规则解释为可执行的代码,这无疑延长的学习曲线,也增加了维护的压力,与此不同的是,Catalyst使用Scala编程语言的标准特性,比如规则匹配,这使得开发者全程可以使用编程语言,同事实现规则也变得比较容易,函数式编程语言适合做编译器,因此我们发现Scala就是这个工作的不二人选,不仅如此,据我所知,Catalyst是第一个被广泛用于生产环境基于Scala语言的优化器。
Catalyst的核心包含一系列用于描述树结构并且操作这些树的库,除了这个架构外,我们还创建特殊的库来处理关系型查询(比如,表达式,逻辑查询计划等),与此同时我们也新增了一系列规则集合,主要用于处理查询执行的不同的阶段:分析阶段,逻辑计划优化阶段,物理计划生成阶段和编译查询代码为Java字节码阶段,对于生成代码这个阶段,我们使用Scala的另外一个特性,关键字识别(quasiquotes),这可以使各种组合表达式中生成运行时代码这一阶段就变得很容易了,最后,Catalyst还提供几个公共拓展的功能点,包括拓展外部数据源和自定义对象等。
4.1 树

Catalyst的主要数据类型是由节点对象组成的树,每个节点都有一个节点类型和任意个children.Scala中定义的新节点类型是TreeNode的子类,这些对象都是不可改变的,并且可以通过前文提到的函数式转换来进行操作。
下面是一个简单的例子,假设我们使用下面的表达式来定义三个节点类型
_ Literal(value: Int): 常量
_ Attribute(name: String): 输入数据行的一个属性,比如“x”
_ Add(left: TreeNode, right: TreeNode): 对两个表达式进行求和
这三个节点都可以用于构建树,例如figure2中的x+(1+2)的表达式,用Scala代码就表示如下:
![]()
4.2 规则
规则可以操作这些树,把他们从一个树变到另外一个树,尽管规则可以操作任意语言构建的数(上面仅仅是Scala语言的例子),但是最常用的方式却是使用一系列规则匹配函数查找并用特别的数据结构去替换子树。
规则匹配是很多函数式变成的一个特征,因为其可以从嵌套的算术运算表达式中抽取到需要的数值,在Catalyst,里面树结构有一种转换函数,可以通过规则匹配在树的各个节点上进行递归匹配,抽取到需要的值到结果集中,我们也可以实现对两个常量进行相加处理的包装:

把这个规则用于x+(1+2)这个数上就会产生一个新的数x+3,上面例子的关键字就是Scala标准的语法,它不仅可以匹配到任务对象的类型,还可以给他们起名字(c1和c2)。
规则匹配表达式的转换是一个局部函数,这意味着它仅仅需要匹配到所有输入树的子集,Catalyst会探到一个规则适用哪些树,自动跳过不符合条件的,保留需要的一些子树,这使得规则只负责查找既定的优化点,而不是其他无关痛痒的部分,因此,新操作算子加入到程序中来的时候规则也不需要做任何修改
规则(一般是Scala的规则匹配)在同一个转换函数被调用时可以做多种匹配,一次调用多个转换的是也很简单

实际上,规则在操作树的时候可能需要被调用多次,Catalyst把规则分成多组,达到阈值的时候就执行一组,这需要规则间相互独立,同时达到这个阈值时树会有很大的变化,在上面的例子中,重复的应用数据会产生一个由常数组成的大树,比如(x+0)+(3+3),还有一个例子,第一批规则通过分析表达式决定各个属性的数据类型,第二个规则可以做常量合并,每批规则处理后,开发者会重新检查整个树,以保证每个属性的数据类型都可以确定,这个在递归匹配的时候用的比较多。
最后,规则条件和规则本身都是使用Scala代码完成,在保持规则简单清晰的基础上,Catalyst比其他特定语言(DSL)的优化器表现更好。
按照我们的经验来看,对固定树的函数式转换,可以让优化器执行更流畅,而且可以很好的进行debug。
优化器还可以支持并发优化,不过暂时还没有更多的实践。
4.3 SparkSQL中使用Catalyst
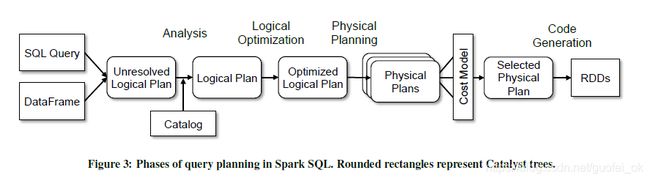
我们使用Catalyst的通用树结构主要集中在下面四个方面(Figure 3也提到了):
(1)分析逻辑计划
(2)逻辑计划优化
(3)生成物理执行计划
(4) 编译查询代码为Java字节码阶段
在生成物理计划的时候,Catalyst通常会生成多个计划,让后对计划的性能进行比较,其他阶段都是基于规则的,每个阶段都会用到树节点的数据类型,Catalyst不仅表达式节点库,还有数据类型,逻辑和物理计划操作算子,下面我们来具体聊聊这四个方面。
4.3.1 分析阶段
Spark SQL刚开始会确定需要计算的关系,或是通过SQL解析器返回的AST,又或是API构建的DataFrame对象,无论哪种情况,树节点的属性目前都是未知的,例如下面的查询中“SELECT col FROM sales”,在查看这个表的表结构之前我们不能确定这个col是什么数据类型,甚至col是不是sales表的一个列我们都不知道,如果一个属性我们不知道数据类型,也映射不到输入的数据(或别名的数据),这个属性就一直是不确定的。Spark SQL利用Catalyst规则和Catalog对象对所有数据源的表进行分析来确定这个属性的数据类型,分析起于未确定的逻辑计划树,树节点的属性和数据类型是无界的,然后可以对此进行规则匹配。
- 在catalog.中按照名字查找相关的关系
- 和已有操作符的children节点匹配名称属性,比如col
- 决定哪个属性对应哪个值,并提供一个唯一标识(后来又新增了表示优化如col=col)
- 通过表达式把数据类型传播下去,比如直到我们直到col是什么类型的时候才知道1 + col的数据类型,过程中可能还会涉及到类型强制转换
analyzer这块总共有1000行代码。
4.3.2 逻辑计划优化
逻辑计划优化主要是对逻辑计划进行规则优化,这其中包括常量合并,谓词下推,projection pruning,,空值处理,布尔表达式简化,还有其他规则等,一般情况下,新增规则比较容易,当我们在SparkSQL中新增固定精度的浮点型数据类型时,我们希望在聚合函数在操作这些浮点数的时候可以按照较小的精度来进行,比如求和和求平均数,我们用12行代码写了规则来处理此类运算,然后把他们强转为无符号64位的Long类型数字,然后再做聚合,最后返回结果,这个规则的简化版只有sum,如下:

还有一个例子,我们用了12行代码优化了LIKE表达式,通过简单的正则表达式来替换掉String.startsWith或String.contains的调用,规则中可以使用任意的Scala代码进行优化,这比正则匹配的子树要好,逻辑优化规则共计800行代码。
4.3.3 物理执行计划
物理执行计划阶段,Spark SQL拿到一个逻辑计划后会生成1个或多个物理计划,物理计划会使用Spark执行引擎能识别的物理操作算子,然后使用Cost-based模型进行筛选,这个时候cost-based的优化仅仅用来选择Join的算法,其实选择性也不是很多,Spark
SQL使用一种broadcast join,Spark自身也是支持这个的,这套框架支持多个节点上同时使用基于代价的评估,不过由于代价评估需要使用规则递归遍历整个树,我们将来会支持更丰富的基于代价评估的优化。
物理执行计划也是使用的基于代价评估的优化方式,比如管道流数据推算或是把数据filter到Spark的map中,不仅如此,从逻辑计划中拿到的算子推到数据源中后还可以支持谓词下推或推测下推,在4.4.1中我们会讲到这些数据源的API
物理执行计划大约500行代码
4.3.4 生成字节码
查询优化的最后一章我们来说说生成Java字节码,这些字节码后面会在各个节点上执行,我们直到Spark SQL经常处理一些存放在内存中的计算密集型的数据集,我们想要通过生成字节码的方式加快Spark的执行速度,不仅如此,字节码生成器很难编译,和一个编译器差不多,Catalyst利用Scala语言的的关键字识别的特点可以让生成字节码的工作大大简化,关键字识别可以结合Scala语言的AST架构一起使用,然后运行的时候编译器就可以开始生成字节码了,我们使用Catalyst去转换一个用SQL表达的树为AST,然后Scala代码可以识别这些表达式,然后编译和执行生成字节码的工作。
举一个简单的例子,就拿4.2章节提到的Add, Attribute and Literal树节点来看,我们可以使用(x+y)+1,在不生成字节码之前,这样的表达式需要对每一行进行解析,遍历整个Add, Attribute and Literal 节点,这大大增多了函数的调用,降低了执行效率,有了生成字节码的功能后,我们可以写一个函数把表达式翻译为一个Scala AST,比如下面的:

这个类注册好了之后,points就会被认为是Spark的原生对象,SparkSQL会把它转化为DataFrames,UDF在使用的时候就可以访问到了,此外,Spark SQL在缓存数据的时候用列式存储(比如x,y是单独的列),Points会注册到SparkSQL的所有数据源,可以看成是DOUBLE的一个双胞胎,机器学习库中有不少这样的udf,5.2节会讲到。

- 高级分析特性
本节我们聊聊SparkSQL里面的三个特性,这些也是为了处理大数据的特别场景而设计的,首先,在这些环境里,数据一般是非结构化或者半结构化的,尽管我们平时也可以解析这些数据,不过代码效率很低,为了可以让用户快速高效查询数据,SparkSQL引入了针对JSON和其他半结构化数据的结构推测算法,其次,机器学习中经常设计到大规模数据的聚合和join操作,我们来讲讲SparkSQL如何在机器学习库中引入高级API的,最后,数据应该来自四面八方,基于4.4.1中提到的API,SparkSQL支持联合查询多种不用的数据源,这些特性都是建立在Catalyst框架的基础之上。
5.1 半结构化数据的结构推测
半结构化数据在大数据中很常见,因为它生成比较简单,也很容易随时追加字段,在很多Spark的用户中,很多的数据来源都是json格式的,不过像MR和Spark这样的程序其实处理JSON数据并不高效,大多数用户会使用ORM库(如Jackson)把json对象映射到Java对象,还有的会用一些简单库逐条对数据进行解析。
SparkSQL中,我们引入了JSON数据源格式,它可以自动推测出数据集的结构, 例如,针对figure5给出的json对象,figure6会给出预测的数据的结构类型。用户可以轻松地把一些json文件映射为一张表,然后像下面这样通过路径去访问它:
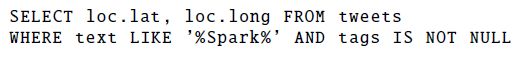
我们的结构推测算法不仅在全量数据集有效,在抽象数据中一样可以发挥作用,这得益于XML数据格式和对象数据的结构推测技术,算法在SparkSQL中相对简单些,因为它只需要简单的推测树结构,不需要递归遍历所有目录的元素。
值得一提的是算法还可以推测出STRUCT类型的树,STRUCT结构中可能还含所有原子型,数组型和其他STRUCT类型的数据,每个字段都有一个独立的路径(比如tweet.loc.latitude),算法会找到最匹配Spark SQL数据类型的字段。比如,如果字段的所有内容都是32位以内的数字,那么SparkSQL会推测出INT类型,如果数字更大点,会推测出LONG(64位)或者DECIMAL(任意精度),再比如数据是小数,它会用Float类型,如果推测出多个类型,SparkSQL最后会用String类型,同时保留原先的json内容,如果字段中含有数组,它也会根据“最公共的父类”逻辑去决定最后每个元素的数据类型,我们是这么实现这个算法的,先对数据执行reduce操作,得到每个元素的推测结构,然后使用最公共的父类为每个元素生成他们的类型,所以算法可以单点执行,也可以跨节点执行,因为reduce操作是最先在各个节点本地进行的。
举个简单的例子,figure5和figure6如何推测出lat和long的数据类型的,遍历每个字段的时候发现单条记录中既有整型数据也有浮点型数据,所以最后返回FLOAT类型,同样道理,tags的数据都是字符串数组的,而且也是非空的,所以最后返回数组非空类型。
实际上,我们发现这套算法在处理真实json格式的数据的时候效果很好,比如它可以精确地识别Twitter每条数据流中的tag,这其中含有上百个字段,而且还有多层嵌套,很多databricks的客户都在使用这种算法处理json格式的数据。
Spark SQL中我们使用同样的算法来推测python对象的RDD的数据类型(见第三节),由于json不是静态类,所有一个RDD会有对象类型,将来我们准备新增一些类似的接口来处理CSV和XML格式的数据,开发者在生成环境中可以把这些数据集当成表,然后立刻去查询或者与其他数据进行Join操作。
5.2 集成机器学习库
下面讲讲SparkSQL在其他Spark模块中的用途,机器学习酷(ML-lib),它使用DataFrames引入了高级API,这个API基于机器学习数据流的概念,这个流是更高级别的ML库(比如SciKit-Learn)的一种抽象化,管道流是一系列数据转换的图,比如特征提取,标准化,降维和模型训练,每个环节都在交换数据,因为ML有很多步数据转换,所有管道流很重要,这些组合操作会让管道流数据转换更加容易了,也方面全流程参数调优。
为了在管道流阶段进行数据交换,MLlib开发者需要一种既灵便又可压缩(数据集可能很大)的数据格式,同时还需要允许不同字段不同类型可以存储,比如,一个用户输入的数据中既含有文本数据,又含有浮点型数据, 然后对记录进行特征提取的算法比如TF-IDF,进行矩阵化操作,同时标准化一些字段,然后对整个特征多降维等等,为了解决这种数据,这个API使用DataFrames(每列都代表数据的一种特征),在管道流中所有的算法根据名称拿到要处理的输入数据列和输出数据列,同时还可以处理数据集合的子集并产生新的数据集,开发者们在保留原始数据不变的情况下轻松地进行复杂的管道流处理,为了进一步描述这个API,见figure7图示:

MLlib要使用SparkSQL还有一个工作要做,那就是为矩阵创建一个自定义类型,UDT矩阵可以包含稀疏矩阵和稠密矩阵,矩阵有四个属性,布尔类型(决定稠密或稀疏)、矩阵大小、坐标数组(稀疏矩阵)、双位数组(可以是稀疏矩阵的非零数据的坐标值或稠密矩阵的所有坐标),DataFrames不仅仅在查询和操作数据列比较有优势,它还让MLlib的新API暴露给所有Spark支持的编程语言,之前每个算法只拿到特定领域的对象(标签分类,个性推荐),这些类都需要用多种语言来实现(比如从Scala到Python),现在DataFrames到处都可以使用,所有语言都可以访问它,你只需要在SparkSQL中做数据转换就好了,Spark能快速融入到一个新的编程语言,这确实是很重要的特性。
最后,在MLlib中使用DataFrames存储也让所有算法都可以通过SQL访问到,我们可以简单地顶一个MADlib风格的UDF,就像3.7节提到的,内部以表的方式被调用,外部接口可以通过访问SQL进行数据流管理。
5.3 联合查询外部数据源
数据管道流的数据经常来自四面八方,比如一个推荐的管道流可能需要流量日志、用户信息数据库和用户社交的实时流数据,这些数据源可能在不同的机器上,甚至可能是异地存储,此时原生查询代价颇高,SparkSql通过Catalyst可以随时把谓词下推各个数据源。
下面的例子就是利用JDBC数据源和JSON格式的数据源进行Join操作来找到最新注册用户的流量日志,无须定义数据类型,两个数据源都可以自动拿到推测的数据类型,JDBC数据源直接把filter谓词推到Mysql,减少了中间的数据传输


执行引擎中JDBC数据源使用4.4.1中使用的PrunedFilteredScan接口,这个接口可以给列名起名并做简单判断(是否相等,大小比较,In等),这个例子中,JDBC数据源将会在mysql中执行下面一段语句:

未来的SparkSQL版本,我们希望对键值对存储的数据源做谓词下推(如Hbase或Cassandra),进一步支持filter操作。
六、性能评估
我们主要从两个方面对SparkSQL进行性能评估:SQL查询性能和Spark程序性能,值得一提的是,我们发现SparkSQL的可拓展的架构不仅丰富了自身的功能,还对原先的基于Spark的SQL查询引擎带来了大大的性能提升。不仅如此,对于Spark应用开发者来说,尽管Spark程序简洁易懂,但是DataFrame API比原生的SparkAPI快很多,最后,应用可以在集成的SparkSQL引擎上进行关系型和程序查询联合查询,这比起并行Job单独处理SQL查询和程序代码要快得多。
6.1 SQL性能
我们使用AMPLab的大数据benchmark和Pavlo开发的web压测工具对Shark和Impala进行了比较,benchmark包含了4种不同参数的查询,分别是:扫描操作、聚合操作、Join操作和基于UDF的MR job,我们使用6台EC2 i2.xlarge组成的集群(1主,5从)跑在2.4版本的的hdfs上,每台机器配置为:CPU4核,内存30GB,磁盘是800GB的SSD,比较版本为:Spark1.3、Shark0.9.1、Impala2.1.1,数据集是110GB,经过压缩过后的Parquet格式的数据。
Figure 8是按照查询类型分组的比较结果,查询1-3参数不同,数据量以此递增,查询4是基于Python的Hive UDF,这个Impala暂时不支持,但是很受CPU限制。
从结果上看,SparkSQL大大领先于Shark,一般情况和impala不分伯仲,比Shark快最主要的原因是SparkSQL使用了Catalyst的生成代码这个特性,这个减少了不少的CPU负载,这也使得SparkSQL在大多数查询中胜于基于C++和LLVM开发的Impala引擎,SparkSQL和Impala最大的差异是3a,由于有个小表,impala选择了更优的关联方式。

6.2 DataFrames对比原生的Spark代码
SparkSQL不仅让开发者可以运行SQL查询,还可以通过DataFrame API让开发者写出更简单高效的Spark代码,Catalyst会对Spark代码写死的部分做DataFrames优化,比如谓词下推、管道流数据处理、自动关联等,即使没有这个优化,DataFrame API的代码生成机制也会让引擎执行的更高效,特别是对Python的应用来说,因为Python比JVM要慢
为了进一步做性能评估,我们要两个Spark程序实现分布式聚合,数据集包含10亿的整数对(a,b),其中a是唯一的,还是在前面提到的5个节点上,我们要计算按照每个a分组后的对应b的平均值,首先我们看看Spark中使用PythonAPI 利用map和reduce函数实现的版本
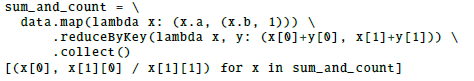
对比之下,如下通过DataFrame API可以写的更简洁。
![]()
Figure 9 中可以看到DataFrame 版本的代码要比python不仅更简洁,速度也快了12倍,这是因为在DataFrame API里,仅仅逻辑计划是python的,所有的物理执行都编译原生Spark代码,如JVM字节码,所以才会更快。实际上DataFrame比原生的SparkAPI也快了2倍,这个主要是代码生成这个环节,DataFrame不需要再额外处理键值对了,但是SparkAPI却必不可少。
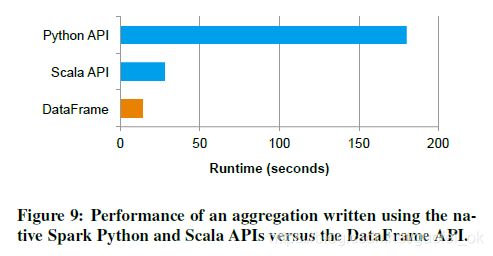
6.3 管道流
DataFrame API可以让开发者在一个程序里的管道流中进行关系型和程序型运算,大大提升应用的性能,举个简单的例子,我们有一个2阶段的管道流去文库中去选择一些文本子集,然后计算出现频率最高的单词,尽管比较简单,这个却可以模拟出真实的场景,比如统计出Tweet中的最受欢迎的词。
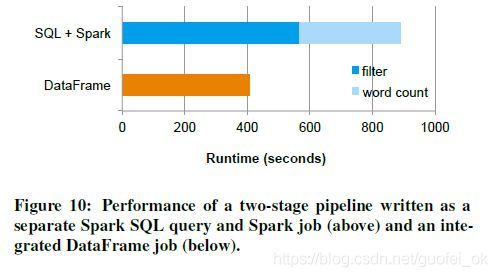
在这个实验中,我们准备了100亿合成数据放在hdfs上,每条消息包含10个字典词汇,第一个阶段用关系型操作筛选90%的消息,第二阶段进行计数统计。
首先,我们是同单独的SQL查询,然后使用Spark Job,这两个步骤可能在不同的关系型或程序型引擎执行(比如Hive和Spark),然后我们再用一个DataFrame API去操作,比如使用DataFrame的关系型算子去filter,然后用RDD API进行计数,与第一个管道流相比,第二个管道流避免了从HDFS查询数据的时间消耗,这些中间数据然后会被送到Spark执行,第二个管道可以一个管道中去map和filter这些数据,Figure10是这两个方法的性能比较,除了操作容易和易理解之外,DataFrame的管道流性能也提升了2倍。
七、应用研究
我们看到很多开发者们在生成环境上大量使用Spark SQL,不仅如此,还有好多开发者对于SparkSQL也有更深的研究兴趣,我们列了两个利用Catalyst可拓展性的研究项目:一个是快速近似查询,一个是基因学领域的。
7.1一般在线聚合
Zeng曾经利用Catalyst做在线聚合功能的提升,提升后系统支持任意嵌套的聚合查询,允许用户实时看到已处理的数据和总体进度,当部分精确的结果出现的时候,如果用户感觉已经满足需求了,此时可以取消查询,为了在Spark SQL中实现这个功能,作者新增一个算子来表示关系型操作已做抽样batch,在查询计划阶段调用一个函数把查询替换为多个查询,每个算子都操作一个完整的样本。
可以单纯的用抽样代替整体不能得到一个准确的结果,算子,就拿聚合来说吧,需要考虑到当前样本和之前样本的结果,然后做有状态的一一处理,还有,算子可能过滤了基于近似结果的元组,这些算子还需要考虑到预估错误之后怎么处理。
上面的这些转换都是Catalyst的规则,算子会不断变更直到最后算到准确的结果,不过这个规则会过滤掉那些不是基于样本的零散树节点,这些会被正常的处理,以SparkSQL为基础,新增一个协议只用了2000行代码。
7.2 基因计算
基因计算的一个常见算法是基于偏移量的重复检查,这个可以理解为非等值Join,假设我们有两个数据集,a和b,结构分别为(start Long.end Long),下面是一个简单的join
如果不做优化的话,上面这个查询会执行的非常低效,可能还有嵌套join操作,相对而下,系统可以使用区间树的方式进行处理,ADAM项目的研发人员研发了一种可以提高计算性能的规则,并把它加在SparkSQL的版本中了,这个规则在处理标准数据的旁边新增了特殊处理代码,大约1000行代码。
八、相关工作
编程模型
目前好多系统都在集成关系型数据处理引擎和程序型数据处理引擎以便在大规模的集群上使用,Shark是最接近SparkSQL的,他们都是运行在Spark引擎上,都提供关系型查询和高级分析,SparkSQL在Shark基础之上改进了更丰富和友好的DataFrames API,从此查新可以在一个模块内进行(3.4中提到),SparkSQL还可以查询原生的RDDs,除了Hive之后支持更多的数据源
SparkSQL的改进受到了DryadLINQ的启发,DryadLINQ把集成的语言查询用C++重新编译,然后放在一个DAG执行引擎上去,LINQ上面的查询也是关系型的,不过只能是C#对象,而Spark SQL提供了类似公共数据科学库的DataFrame接口,这是一个可以使用多种数据源和结构推测并支持在Spark上执行迭代算法的API。
其他也有系统使用关系型数据模型,同时提供可代码编程的UDF,比如,Hive和Pig都提供关系型查询和UDF,ASTERIX是一种半结构化的数据模型,Stratosphere也是一种半结构化的数据模型,不过它还提供了API,这样用户可以通过Java或者Python很轻松地调用UDF,PIQL也是这样,提供了Scala DSL,相比这些系统,Spark SQL与原生的Spark程序集成更加紧密,它可以查询用户自定义的类(原生的Java或Python),开发者在一个变成语言里可以同时使用关系型和程序型API,不仅如此,通过Catalyst这个优化器,Spark SQL实现了大多数计算框架不曾有的优化(代码生成技术等)和功能点(JSON和机器学习的结构推测等),我们相信这些特征也是集成易用的大数据系统应该具备的。
最后DataFrame框架可以单机、集群使用,和之前的API优化不同,SparkSQL使用关系型优化对DataFrame进行的优化。
拓展的优化点
Catalyst优化器和其他可拓展的优化框架(EXODUS和Cascades)有着相似的目标,一般情况,优化框架需要有个特定语言来写规则,然后需要优化编译器去把它们变成可执行的代码,我们主要的改进是我们的优化器基于Scala语言的编程特色,提供较低的学习成本和维护代价。Catalyst还借助了高级语言的一些特性,比如我们的代码使用的是关键字识别(4.3.4),这也是它的最佳使命,尽管易拓展的这个特色不好量化,我们惊喜地发现SparkSQL在首次发布之后的8个月就有了50多为外部的贡献者。
对于代码生成的这一功能点,LegoBase最近建议使用Scala的编程解决,替换掉之前的Catalyst里面的关键字识别。
高级分析
SparkSQL目前聚焦在大规模集群的高级算法的应用,包括迭代算法和图计算的平台支持,和MADlib一样,我们也想暴露一些分析算法到外部,尽管方式不太相同,MADlib不得不使用Postgres的几个UDF接口,而Spark SQL的UDF可以是任意的Spark程序,最后,相关技术比如Sinew and Invisible Loading目前正致力于提供和优化对半结构化数据的查询。比如,JSON,我们希望在JSON数据源这里使用到这些技术。
九、总结
SparkSQL丰富地集成了关系型查询,SparkSQL把Spark从声明式的DataFrame API到拓展到允许关系型数据的处理,同时还提供了自动优化,让用户可以把关系型的查询和程序型处理结合在一起,它还有很多的特色,比如大规模数据处理的容错、查询半结构话数据,联合查询和机器学习的自定义数据类型,为了让这一切变成可能,SparkSQL使用了可拓展的优化器Catalyst,有了它之后,新增规则、数据源、数据类型都可以直接在Scala代码中处理,通过上面的实验测试案例和结果,Spark SQL在集成关系型查询和程序型数据流处理上更加简单和高效,同时还比之前的SQL-on-Spark引擎还要快。
SparkSQL开源地址请访问:http://spark.apache.org.
十、鸣谢
We would like to thank Cheng Hao, Tayuka Ueshin, Tor Myklebust,
Daoyuan Wang, and the rest of the Spark SQL contributors so far.
We would also like to thank John Cieslewicz and the other members
of the F1 team at Google for early discussions on the Catalyst
optimizer. The work of authors Franklin and Kaftan was supported
in part by: NSF CISE Expeditions Award CCF-1139158, LBNL
Award 7076018, and DARPA XData Award FA8750-12-2-0331,
and gifts from Amazon Web Services, Google, SAP, The Thomas
and Stacey Siebel Foundation, Adatao, Adobe, Apple, Inc., Blue
Goji, Bosch, C3Energy, Cisco, Cray, Cloudera, EMC2, Ericsson,
Facebook, Guavus, Huawei, Informatica, Intel, Microsoft, NetApp,
Pivotal, Samsung, Schlumberger, Splunk, Virdata and VMware.
十一、相关参考
- A. Abouzied, D. J. Abadi, and A. Silberschatz. Invisible
loading: Access-driven data transfer from raw files into
database systems. In EDBT, 2013.
[2] A. Alexandrov et al. The Stratosphere platform for big data
analytics. The VLDB Journal, 23(6):939–964, Dec. 2014.
[3] AMPLab big data benchmark.
https://amplab.cs.berkeley.edu/benchmark.
[4] Apache Avro project. http://avro.apache.org.
[5] Apache Parquet project. http://parquet.incubator.apache.org.
[6] Apache Spark project. http://spark.apache.org.
[7] M. Armbrust, N. Lanham, S. Tu, A. Fox, M. J. Franklin, and
D. A. Patterson. The case for PIQL: a performance insightful
query language. In SOCC, 2010.
[8] A. Behm et al. Asterix: towards a scalable, semistructured
data platform for evolving-world models. Distributed and
Parallel Databases, 29(3):185–216, 2011.
[9] G. J. Bex, F. Neven, and S. Vansummeren. Inferring XML
schema definitions from XML data. In VLDB, 2007.
[10] BigDF project. https://github.com/AyasdiOpenSource/bigdf.
[11] C. Chambers, A. Raniwala, F. Perry, S. Adams, R. R. Henry,
R. Bradshaw, and N. Weizenbaum. FlumeJava: Easy, efficient
data-parallel pipelines. In PLDI, 2010.
[12] J. Cohen, B. Dolan, M. Dunlap, J. Hellerstein, and C. Welton.
MAD skills: new analysis practices for big data. VLDB, 2009.
[13] DDF project. http://ddf.io.
[14] B. Emir, M. Odersky, and J. Williams. Matching objects with
patterns. In ECOOP 2007 – Object-Oriented Programming,
volume 4609 of LNCS, pages 273–298. Springer, 2007.
[15] J. E. Gonzalez, R. S. Xin, A. Dave, D. Crankshaw, M. J.
Franklin, and I. Stoica. GraphX: Graph processing in a
distributed dataflow framework. In OSDI, 2014.
[16] G. Graefe. The Cascades framework for query optimization.
IEEE Data Engineering Bulletin, 18(3), 1995.
[17] G. Graefe and D. DeWitt. The EXODUS optimizer generator.
In SIGMOD, 1987.
[18] J. Hegewald, F. Naumann, and M. Weis. XStruct: efficient
schema extraction from multiple and large XML documents.
In ICDE Workshops, 2006.
[19] Hive data definition language.
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL.
[20] M. Isard and Y. Yu. Distributed data-parallel computing using
a high-level programming language. In SIGMOD, 2009.
[21] Jackson JSON processor. http://jackson.codehaus.org.
[22] Y. Klonatos, C. Koch, T. Rompf, and H. Chafi. Building
efficient query engines in a high-level language. PVLDB,
7(10):853–864, 2014.
[23] M. Kornacker et al. Impala: A modern, open-source SQL
engine for Hadoop. In CIDR, 2015.
[24] Y. Low et al. Distributed GraphLab: a framework for machine
learning and data mining in the cloud. VLDB, 2012.
[25] S. Melnik et al. Dremel: interactive analysis of web-scale
datasets. Proc. VLDB Endow., 3:330–339, Sept 2010.
[26] X. Meng, J. Bradley, E. Sparks, and S. Venkataraman. ML
pipelines: a new high-level API for MLlib.
https://databricks.com/blog/2015/01/07/ml-pipelines-a-newhigh-level-api-for-mllib.html.
[27] S. Nestorov, S. Abiteboul, and R. Motwani. Extracting
schema from semistructured data. In ICDM, 1998.
[28] F. A. Nothaft, M. Massie, T. Danford, Z. Zhang, U. Laserson,
C. Yeksigian, J. Kottalam, A. Ahuja, J. Hammerbacher,
M. Linderman, M. J. Franklin, A. D. Joseph, and D. A.
Patterson. Rethinking data-intensive science using scalable
analytics systems. In SIGMOD, 2015.
[29] C. Olston, B. Reed, U. Srivastava, R. Kumar, and A. Tomkins.
Pig Latin: a not-so-foreign language for data processing. In
SIGMOD, 2008.
[30] pandas Python data analysis library. http://pandas.pydata.org.
[31] A. Pavlo et al. A comparison of approaches to large-scale data
analysis. In SIGMOD, 2009.
[32] R project for statistical computing. http://www.r-project.org.
[33] scikit-learn: machine learning in Python.
http://scikit-learn.org.
[34] D. Shabalin, E. Burmako, and M. Odersky. Quasiquotes for
Scala, a technical report. Technical Report 185242, École
Polytechnique Fédérale de Lausanne, 2013.
[35] D. Tahara, T. Diamond, and D. J. Abadi. Sinew: A SQL
system for multi-structured data. In SIGMOD, 2014.
[36] A. Thusoo et al. Hive–a petabyte scale data warehouse using
Hadoop. In ICDE, 2010.
[37] P. Wadler. Monads for functional programming. In Advanced
Functional Programming, pages 24–52. Springer, 1995.
[38] R. S. Xin, J. Rosen, M. Zaharia, M. J. Franklin, S. Shenker,
and I. Stoica. Shark: SQL and rich analytics at scale. In
SIGMOD, 2013.
[39] M. Zaharia et al. Resilient distributed datasets: a fault-tolerant
abstraction for in-memory cluster computing. In NSDI, 2012.
[40] K. Zeng et al. G-OLA: Generalized online aggregation for
interactive analysis on big data. In SIGMOD, 2015.
小郭飞飞刀注解1:Turingcomplete language
a programing language is called "Turing complete", if that it can run any program(irrespective of the language) that a Turing machine can run given enough time and memory.