Spark15:Spark SQL:DataFrame常见算子操作、DataFrame的sql操作、RDD转换为DataFrame、load和save操作、SaveMode、内置函数
前面我们学习了Spark中的Spark core,离线数据计算,下面我们来学习一下Spark中的Spark SQL。
一、Spark SQL
Spark SQL和我们之前讲Hive的时候说的hive on spark是不一样的。
hive on spark是表示把底层的mapreduce引擎替换为spark引擎。
而Spark SQL是Spark自己实现的一套SQL处理引擎。
Spark SQL是Spark中的一个模块,主要用于进行结构化数据的处理。它提供的最核心的编程抽象,就是DataFrame。
DataFrame=RDD+Schema。
它其实和关系型数据库中的表非常类似,RDD可以认为是表中的数据,Schema是表结构信息。DataFrame可以通过很多来源进行构建,包括:结构化的数据文件,Hive中的表,外部的关系型数据库,以及RDD
Spark1.3出现的DataFrame,Spark1.6出现了DataSet,在Spark2.0中两者统一,DataFrame等于DataSet[Row]
二、SparkSession
要使用Spark SQL,首先需要创建一个SpakSession对象。
SparkSession中包含了SparkContext和SqlContext。
所以说想通过SparkSession来操作RDD的话需要先通过它来获取SparkContext。
这个SqlContext是使用sparkSQL操作hive的时候会用到的。
三、创建DataFrame
使用SparkSession,可以从RDD、HIve表或者其它数据源创建DataFrame
那下面我们来使用JSON文件来创建一个DataFrame
想要使用spark-sql需要先添加spark-sql的依赖
org.apache.spark
spark-sql_2.11
2.4.3
在项目中添加sql这个包名
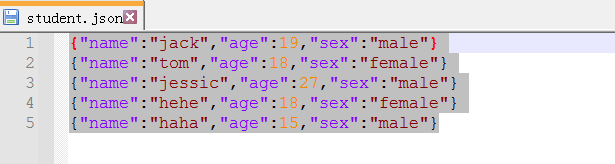
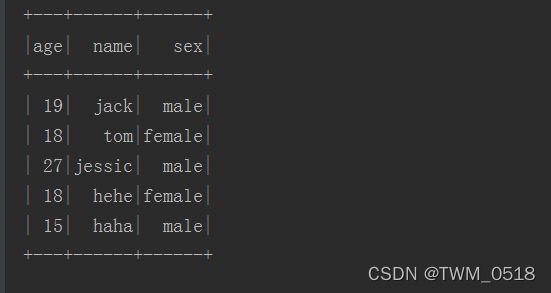
student.json文件内容如下:
{"name":"jack","age":19,"sex":"male"}
{"name":"tom","age":18,"sex":"female"}
{"name":"jessic","age":27,"sex":"male"}
{"name":"hehe","age":18,"sex":"female"}
{"name":"haha","age":15,"sex":"male"}
1、scala代码如下:
创建object:SqlDemoScala
package com.imooc.scala.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 需求:使用json文件创建DataFrame
*/
object SqlDemoScala {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "E:\\hadoop-3.2.0\\hadoop-3.2.0")
val conf = new SparkConf().setMaster("local")
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("SqlDemoScala").config(conf)
.getOrCreate()
//读取json文件,获取DataFrame
val stuDf = sparkSession.read.json("D:\\student.json")
//将DataFrame转换为DataSet[Row]
//val stuDf = sparkSession.read.json("D:\\student.json").as("stu")
//查看DataFrame中的数据
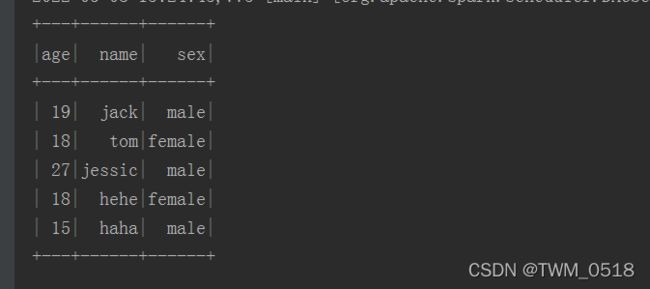
stuDf.show()
sparkSession.stop()
}
}
运行结果如下:
2、java代码如下:
package com.imooc.java.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* 需求:使用json文件创建DataFrame
*/
public class SqlDemoJava {
public static void main(String[] args) {
System.setProperty("hadoop.home.dir", "E:\\hadoop-3.2.0\\hadoop-3.2.0");
SparkConf conf = new SparkConf();
conf.setMaster("local");
//创建SparkSession对象,里面包含SparkContext和SqlContext
SparkSession sparkSession = SparkSession.builder()
.appName("SqlDemoJava")
.config(conf)
.getOrCreate();
//读取json文件,获取Dataset
Dataset stuDf = sparkSession.read().json("D:\\student.json");
//将Dataset转换为DataFrame
//Dataset stuDf = sparkSession.read().json("D:\\student.json").toDF();
stuDf.show();
sparkSession.stop();
}
}
运行结果如下:
注:
由于DataFrame等于DataSet[Row],它们两个可以互相转换,所以创建哪个都是一样的
咱们前面的scala代码默认创建的是DataFrame,java代码默认创建的是DataSet
尝试对他们进行转换
在Scala代码中将DataFrame转换为DataSet[Row],对后面的操作没有影响
//将DataFrame转换为DataSet[Row]
val stuDf = sparkSession.read.json("D:\\student.json").as("stu")
在Java代码中将DataSet[Row]转换为DataFrame
//将Dataset转换为DataFrame
Dataset stuDf = sparkSession.read().json("D:\\student.json").toDF();
四、DataFrame常见算子操作
下面来看一下Spark sql中针对DataFrame常见的算子操作
先看一下官方文档
printSchema()
show()
select()
filter()、where()
groupBy()
count()
下面来使用一下这些操作
1、scala代码如下:
package com.imooc.scala.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 需求:DataFrame常见操作
*/
object DataFrameOpScala {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "E:\\hadoop-3.2.0\\hadoop-3.2.0")
val conf = new SparkConf().setMaster("local")
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("DataFrameOpScala")
.config(conf)
.getOrCreate()
val stuDf = sparkSession.read.json("D:\\student.json")
//打印schema信息
stuDf.printSchema()
//默认显示所有数据,可以通过参数控制显示多少条
stuDf.show(2)
stuDf.select("name","age").show()
//在使用select的时候可以对数据做一些操作,需要添加隐式转换函数,否则语法报错
import sparkSession.implicits._
stuDf.select($"name",$"age" + 1).show()
//对数据进行过滤,需要添加隐式转换函数,否则语法报错
stuDf.filter($"age" > 18).show()
//where底层调用的就是filter
stuDf.where($"age" > 18).show()
//对数据进行分组求和
stuDf.groupBy("age").count().show()
sparkSession.stop()
}
}
输出如下:
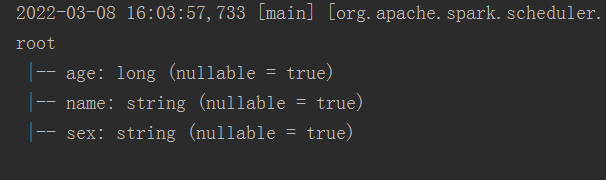
//打印schema信息
stuDf.printSchema()
//默认显示所有数据,可以通过参数控制显示多少条
stuDf.show(2)
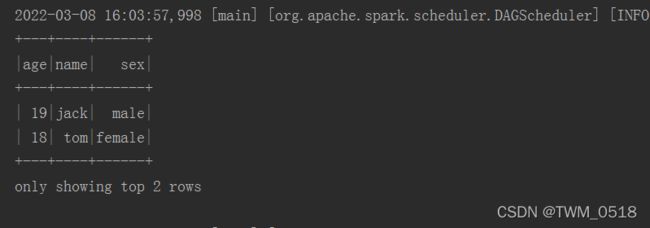
stuDf.select("name","age").show()
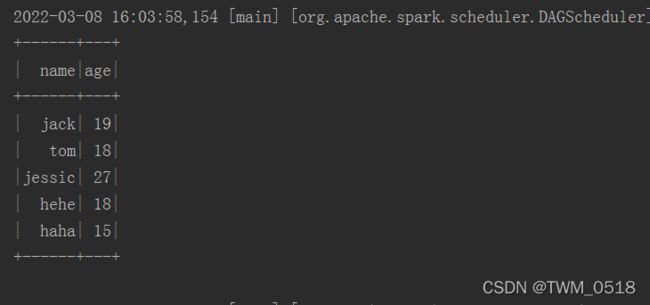
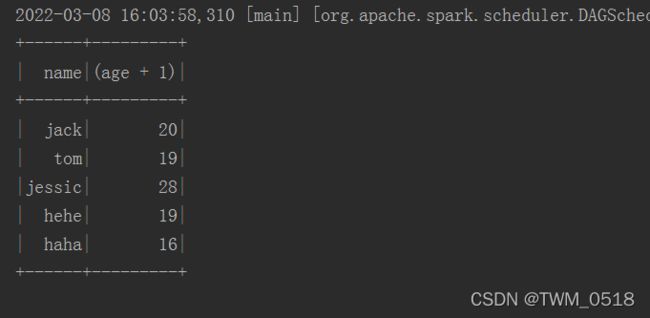
//在使用select的时候可以对数据做一些操作,需要添加隐式转换函数,否则语法报错
import sparkSession.implicits._
stuDf.select($"name",$"age" + 1).show()
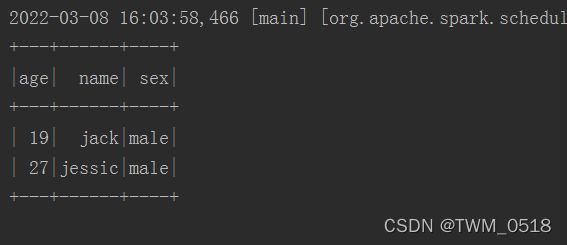
//对数据进行过滤,需要添加隐式转换函数,否则语法报错
stuDf.filter($"age" > 18).show()
//where底层调用的就是filter
stuDf.where($"age" > 18).show()
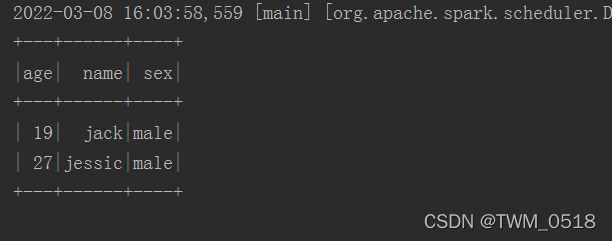
//对数据进行分组求和
stuDf.groupBy("age").count().show()
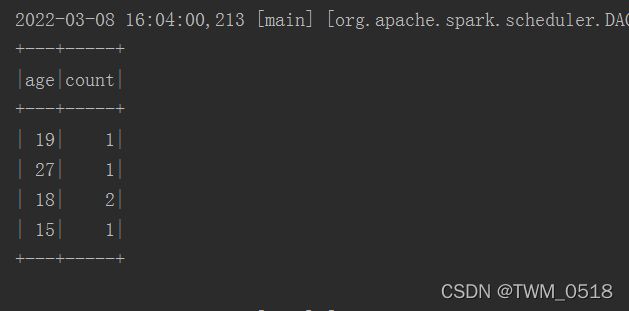
2、java代码如下:
package com.imooc.java.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import static org.apache.spark.sql.functions.col;
/**
* 需求:DataFrame常见操作
*/
public class DataFrameOpJava {
public static void main(String[] args) {
System.setProperty("hadoop.home.dir", "E:\\hadoop-3.2.0\\hadoop-3.2.0");
SparkConf conf = new SparkConf();
conf.setMaster("local");
//创建SparkSession对象,里面包含SparkContext和SqlContext
SparkSession sparkSession = SparkSession.builder()
.appName("DataFrameOpJava")
.config(conf)
.getOrCreate();
Dataset stuDf = sparkSession.read().json("D:\\student.json");
//打印schema信息
stuDf.printSchema();
//默认显示所有数据,可以通过参数控制显示多少条
stuDf.show(2);
//查询数据中的指定字段信息
stuDf.select("name","age").show();
//在select的时候可以对数据做一些操作,需要引入import static org.apache.spark.sql.functions.col;
stuDf.select(col("name"),col("age").plus(1)).show();
//对数据进行过滤
stuDf.filter(col("age").gt(18)).show();
//where底层调用的就是filter
stuDf.where(col("age").gt(18)).show();
stuDf.groupBy("age").count().show();
sparkSession.stop();
}
}
输出如下:
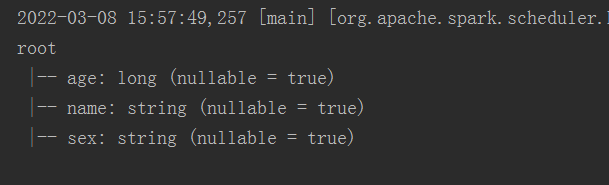
//打印schema信息
stuDf.printSchema();
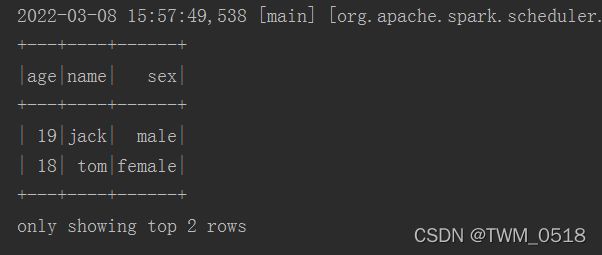
//默认显示所有数据,可以通过参数控制显示多少条
stuDf.show(2);
//查询数据中的指定字段信息
stuDf.select("name","age").show();
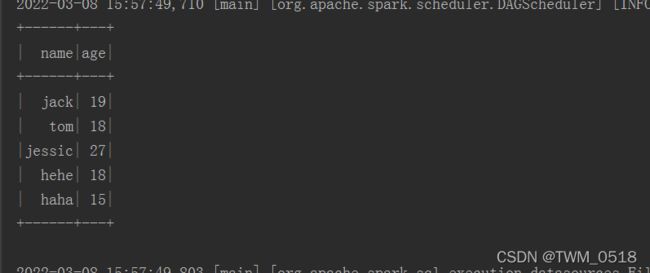
//在select的时候可以对数据做一些操作,需要引入import static org.apache.spark.sql.functions.col;
stuDf.select(col("name"),col("age").plus(1)).show();
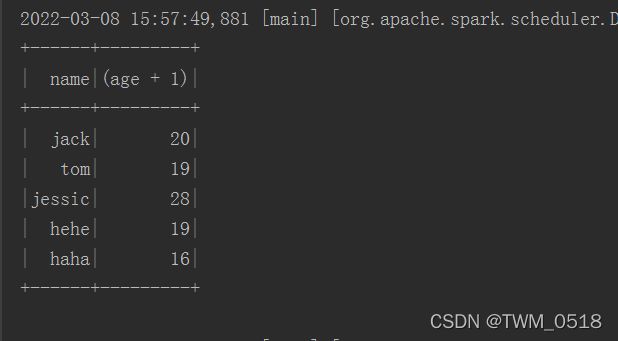
//对数据进行过滤
stuDf.filter(col("age").gt(18)).show();
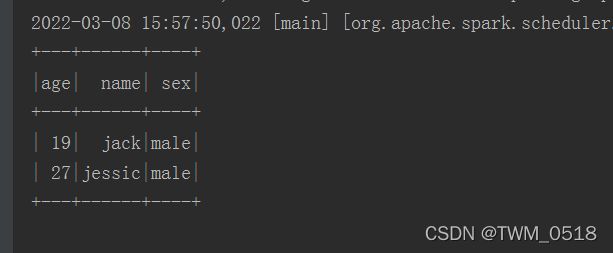
//where底层调用的就是filter
stuDf.where(col("age").gt(18)).show();
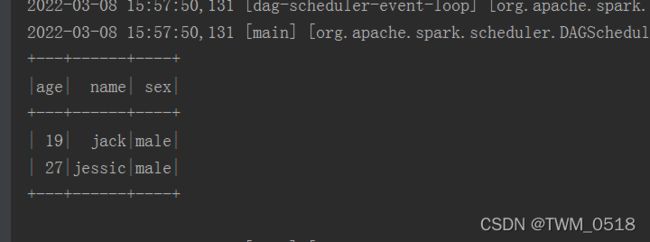
stuDf.groupBy("age").count().show();
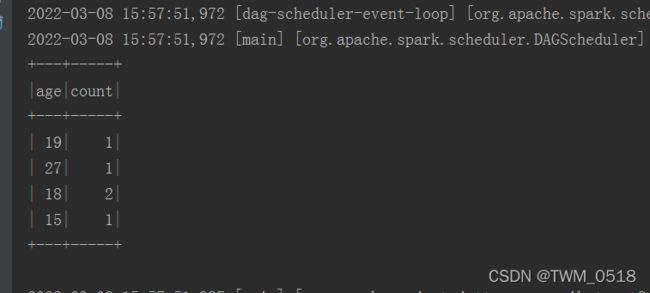
这些就是针对DataFrame的一些常见的操作。
但是现在这种方式其实用起来还是不方便,只是提供了一些类似于可以操作表的算子,很对一些简单的查询还是可以的,但是针对一些复杂的操作,使用算子写起来就很麻烦了,所以我们希望能够直接支持用sql的方式执行,Spark SQL也是支持的。
五、DataFrame的sql操作
想要实现直接支持sql语句查询DataFrame中的数据
需要两步操作
1、先将DataFrame注册为一个临时表
2、使用sparkSession中的sql函数执行sql语句
下面来看一个案例
1、scala代码如下:
package com.imooc.scala.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 需求:使用sql操作DataFrame
*/
object DataFrameSqlScala {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "E:\\hadoop-3.2.0\\hadoop-3.2.0")
val conf = new SparkConf().setMaster("local")
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("DataFrameSqlScala")
.config(conf)
.getOrCreate()
val stuDf = sparkSession.read.json("D:\\student.json")
//将DataFrame注册为一个临时表
stuDf.createOrReplaceTempView("student")
//使用sql查询临时表中的数据
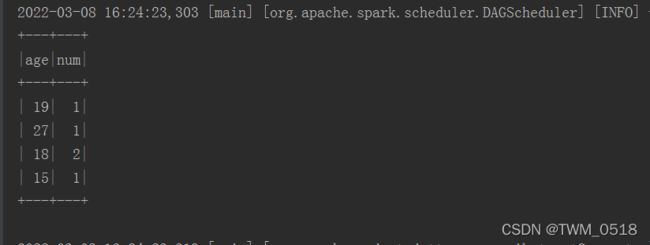
sparkSession.sql("select age,count(*) as num from student group by age")
.show()
sparkSession.stop()
}
}
结果输出如下:
2、java代码如下:
package com.imooc.java.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* 需求:使用sql操作DataFrame
*/
public class DataFrameSqlJava {
public static void main(String[] args) {
System.setProperty("hadoop.home.dir", "E:\\hadoop-3.2.0\\hadoop-3.2.0");
SparkConf conf = new SparkConf();
conf.setMaster("local");
//创建SparkSession对象,里面包含SparkContext和SqlContext
SparkSession sparkSession = SparkSession.builder()
.appName("DataFrameSqlJava")
.config(conf)
.getOrCreate();
Dataset stuDf = sparkSession.read().json("D:\\student.json");
//将Dataset注册为一个临时表
stuDf.createOrReplaceTempView("student");
//使用sql查询临时表中的数据
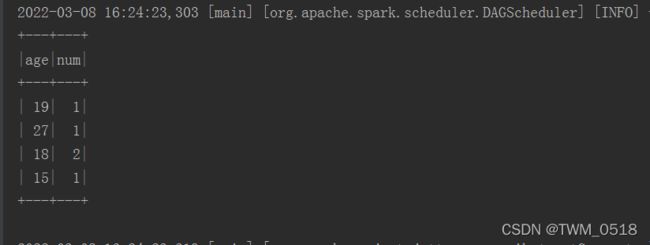
sparkSession.sql("select age,count(*) as num from student group by age")
.show();
sparkSession.stop();
}
}
结果输出如下:
六、RDD转换为DataFrame
为什么要将RDD转换为DataFrame?
在实际工作中我们可能会先把hdfs上的一些日志数据加载进来,然后进行一些处理,最终变成结构化的数据,希望对这些数据做一些统计分析,当然了我们可以使用spark中提供的transformation算子来实现,只不过会有一些麻烦,毕竟是需要写代码的,如果能够使用sql实现,其实是更加方便的。
所以可以针对我们前面创建的RDD,将它转换为DataFrame,这样就可以使用dataFrame中的一些算子或者直接写sql来操作数据了。
Spark SQL支持这两种方式将RDD转换为DataFrame
1、反射方式
2、编程方式
1、反射方式
下面来看一下反射方式:
这种方式是使用反射来推断RDD中的元数据。
基于反射的方式,代码比较简洁,也就是说当你在写代码的时候,已经知道了RDD中的元数据,这样的话使用反射这种方式是一种非常不错的选择。
Scala具有隐式转换的特性,所以spark sql的scala接口是支持自动将包含了case class的RDD转换为DataFrame的
下面来举一个例子
(1)scala代码如下:
package com.imooc.scala.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 需求:使用反射方式实现RDD转换为DataFrame
*/
object RddToDataFrameByReflectScala {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "E:\\hadoop-3.2.0\\hadoop-3.2.0")
val conf = new SparkConf().setMaster("local")
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("RddToDataFrameByReflectScala")
.config(conf)
.getOrCreate()
//获取SparkContext
val sc = sparkSession.sparkContext
val dataRDD = sc.parallelize(Array(("jack",18),("tom",20),("jessic",30)))
//基于反射直接将包含Student对象的dataRDD转换为DataFrame
//需要导入隐式转换
import sparkSession.implicits._
val stuDf = dataRDD.map(tup=>Student(tup._1,tup._2)).toDF()
//下面就可以通过DataFrame的方式操作dataRDD中的数据了
stuDf.createOrReplaceTempView("student")
//执行sql查询
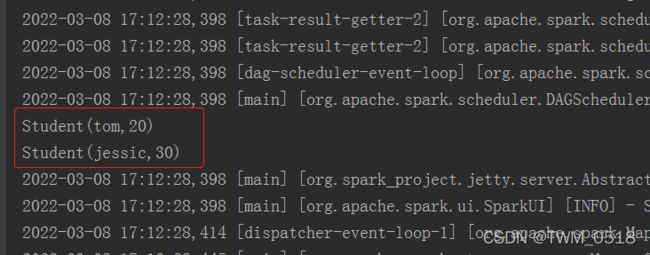
val resDf = sparkSession.sql("select name,age from student where age > 18")
sparkSession.sql("select name,age from student where age > 18").show()
//将DataFrame转化为RDD
val resRDD = resDf.rdd
//从row中取数据,封装成student,打印到控制台
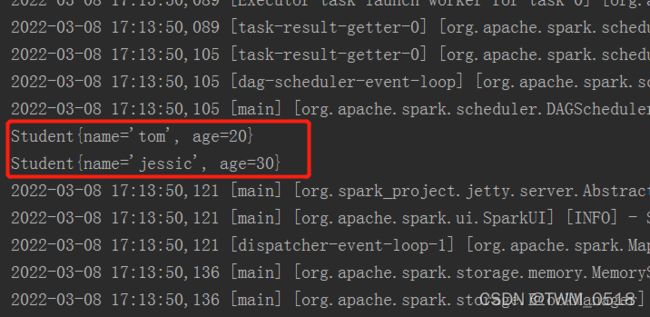
resRDD.map(row=>Student(row(0).toString,row(1).toString.toInt))
.collect()
.foreach(println(_))
//使用row的getAs()方法,获取指定列名的值
resRDD.map(row=>Student(row.getAs[String]("name"),row.getAs[Int]("age")))
.collect()
.foreach(println(_))
sparkSession.stop()
}
}
//定义一个Student
case class Student(name:String,age:Int)
输出如下:
(2)java代码如下:
package com.imooc.java.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.rdd.RDD;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
import java.io.Serializable;
import java.util.Arrays;
import java.util.List;
/**
* 需求:使用反射方式实现RDD转换为DataFrame
*/
public class RddToDataFrameByReflectJava {
public static void main(String[] args) {
System.setProperty("hadoop.home.dir", "E:\\hadoop-3.2.0\\hadoop-3.2.0");
SparkConf conf = new SparkConf();
conf.setMaster("local");
//创建SparkSession对象,里面包含SparkContext和SqlContext
SparkSession sparkSession = SparkSession.builder()
.appName("RddToDataFrameByReflectJava")
.config(conf)
.getOrCreate();
//获取SparkContext
//从sparkSession中获取的是scala中的sparkContext,所以需要转换成java中的sparkContext
JavaSparkContext sc = JavaSparkContext.fromSparkContext(sparkSession.sparkContext());
Tuple2 t1 = new Tuple2("jack", 18);
Tuple2 t2 = new Tuple2("tom", 20);
Tuple2 t3 = new Tuple2("jessic", 30);
JavaRDD> dataRDD = sc.parallelize(Arrays.asList(t1,t2,t3));
JavaRDD stuRDD = dataRDD.map(new Function, Student>() {
@Override
public Student call(Tuple2 tup) throws Exception {
return new Student(tup._1, tup._2);
}
});
//注意:Student这个类必须声明为public,并且必须实现序列化
Dataset stuDf = sparkSession.createDataFrame(stuRDD,Student.class);
stuDf.createOrReplaceTempView("student");
//执行sql查询
Dataset resDf = sparkSession.sql("select name,age from student where age > 18");
//将DataFrame转化为RDD,注意:这里需要转为JavaRDD
JavaRDD resRDD = resDf.javaRDD();
//从row中取数据,封装成student,打印到控制台
List resList = resRDD.map(new Function() {
@Override
public Student call(Row row) throws Exception {
//return new Student(row.getString(0), row.getInt(1));
//通过getAs获取数据
return new Student(row.getAs("name").toString(), Integer.parseInt(row.getAs("age").toString()));
}
}).collect();
for(Student stu : resList){
System.out.println(stu);
}
sparkSession.stop();
}
}
Student类:
package com.imooc.java.sql;
import java.io.Serializable;
/**
*
*/
public class Student implements Serializable {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
输出如下:
2、编程方式
接下来是编程的方式
这种方式是通过编程接口来创建DataFrame,你可以在程序运行时动态构建一份元数据,就是Schema,然后将其应用到已经存在的RDD上。这种方式的代码比较冗长,但是如果在编写程序时,还不知道RDD的元数据,只有在程序运行时,才能动态得知其元数据,那么只能通过这种动态构建元数据的方式。
也就是说当case calss中的字段无法预先定义的时候,就只能用编程方式动态指定元数据了
下面看一个案例
(1)scala代码如下:
package com.imooc.scala.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
/**
* 需求:使用编程方式实现RDD转换为DataFrame
*
*/
object RddToDataFrameByProgramScala {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "E:\\hadoop-3.2.0\\hadoop-3.2.0")
val conf = new SparkConf()
.setMaster("local")
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("RddToDataFrameByProgramScala")
.config(conf)
.getOrCreate()
//获取SparkContext
val sc = sparkSession.sparkContext
val dataRDD = sc.parallelize(Array(("jack",18),("tom",20),("jessic",30)))
//组装rowRDD
val rowRDD = dataRDD.map(tup=>Row(tup._1,tup._2))
//指定元数据信息【这个元数据信息就可以动态从外部获取了,比较灵活】
val schema = StructType(Array(
StructField("name",StringType,true),
StructField("age",IntegerType,true)
))
//组装DataFrame
val stuDf = sparkSession.createDataFrame(rowRDD,schema)
//下面就可以通过DataFrame的方式操作dataRDD中的数据了
stuDf.createOrReplaceTempView("student")
//执行sql查询
val resDf = sparkSession.sql("select name,age from student where age > 18")
//将DataFrame转化为RDD
val resRDD = resDf.rdd
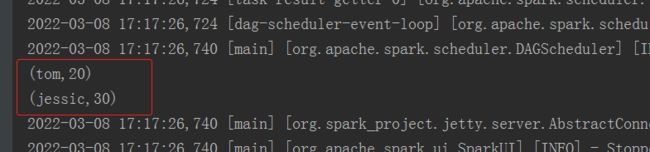
resRDD.map(row=>(row(0).toString,row(1).toString.toInt))
.collect()
.foreach(println(_))
sparkSession.stop()
}
}
输出如下:
(2)java代码如下:
package com.imooc.java.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* 需求:使用编程方式实现RDD转换为DataFrame
*
*/
public class RddToDataFrameByProgramJava {
public static void main(String[] args) {
System.setProperty("hadoop.home.dir", "E:\\hadoop-3.2.0\\hadoop-3.2.0");
SparkConf conf = new SparkConf();
conf.setMaster("local");
//创建SparkSession对象,里面包含SparkContext和SqlContext
SparkSession sparkSession = SparkSession.builder()
.appName("RddToDataFrameByProgramJava")
.config(conf)
.getOrCreate();
//获取SparkContext
//从sparkSession中获取的是scala中的sparkContext,所以需要转换成java中的sparkContext
JavaSparkContext sc = JavaSparkContext.fromSparkContext(sparkSession.sparkContext());
Tuple2 t1 = new Tuple2("jack", 18);
Tuple2 t2 = new Tuple2("tom", 20);
Tuple2 t3 = new Tuple2("jessic", 30);
JavaRDD> dataRDD = sc.parallelize(Arrays.asList(t1, t2, t3));
//组装rowRDD
JavaRDD rowRDD = dataRDD.map(new Function, Row>() {
@Override
public Row call(Tuple2 tup) throws Exception {
return RowFactory.create(tup._1, tup._2);
}
});
//指定元数据信息
ArrayList structFieldList = new ArrayList();
structFieldList.add(DataTypes.createStructField("name", DataTypes.StringType, true));
structFieldList.add(DataTypes.createStructField("age", DataTypes.IntegerType, true));
StructType schema = DataTypes.createStructType(structFieldList);
//构建DataFrame
Dataset stuDf = sparkSession.createDataFrame(rowRDD, schema);
stuDf.createOrReplaceTempView("student");
//执行sql查询
Dataset resDf = sparkSession.sql("select name,age from student where age > 18");
//将DataFrame转化为RDD,注意:这里需要转为JavaRDD
JavaRDD resRDD = resDf.javaRDD();
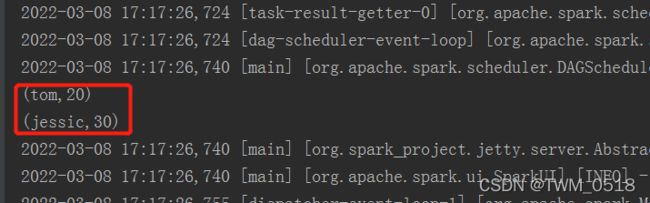
List> resList = resRDD.map(new Function>() {
@Override
public Tuple2 call(Row row) throws Exception {
return new Tuple2(row.getString(0), row.getInt(1));
}
}).collect();
for(Tuple2 tup : resList){
System.out.println(tup);
}
sparkSession.stop();
}
}
输出如下:
七、load和save操作
对于Spark SQL的DataFrame来说,无论是从什么数据源创建出来的DataFrame,都有一些共同的load和save操作。
load操作主要用于加载数据,创建出DataFrame;
save操作,主要用于将DataFrame中的数据保存到文件中。
我们前面操作json格式的数据的时候好像没有使用load方法,而是直接使用的json方法,这是什么特殊用法吗?
查看json方法的源码会发现,它底层调用的是format和load方法。
def json(paths: String*): DataFrame = format("json").load(paths : _*)
注意:如果看不到源码,需要点击idea右上角的download source提示信息下载依赖的源码。
我们如果使用原始的format和load方法加载数据,
此时如果不指定format,则默认读取的数据源格式是parquet,也可以手动指定数据源格式。Spark SQL内置了一些常见的数据源类型,比如json, parquet, jdbc, orc, csv, text
通过这个功能,就可以在不同类型的数据源之间进行转换了。
来看一个案例:
1、scala代码如下:
package com.imooc.scala.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 需求:load和save的使用
*
*/
object LoadAndSaveOpScala {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "E:\\hadoop-3.2.0\\hadoop-3.2.0")
val conf = new SparkConf()
.setMaster("local")
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("LoadAndSaveOpScala")
.config(conf)
.getOrCreate()
//读取数据
val stuDf = sparkSession.read
.format("json")
.load("D:\\student.json")
//保存数据
stuDf.select("name","age")
.write
.format("csv")
.save("hdfs://bigdata01:9000/out-save001")
sparkSession.stop()
}
}
执行代码,查看结果,csv文件是使用逗号分隔的:
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /out-save001
Found 2 items
-rw-r--r-- 3 yehua supergroup 0 2020-05-29 17:53 /out-save001/_SUCCESS
-rw-r--r-- 3 yehua supergroup 46 2020-05-29 17:53 /out-save001/part-00000-9bf82de6-b23e-4118-bc05-34e0466aa295-c000.csv
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -cat /out-save001/part-00000-9bf82de6-b23e-4118-bc05-34e0466aa295-c000.csv
jack,19
tom,18
jessic,27
hehe,18
haha,15
2、java代码如下:
package com.imooc.java.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* 需求:load和save的使用
*/
public class LoadAndSaveOpJava {
public static void main(String[] args) {
System.setProperty("hadoop.home.dir", "E:\\hadoop-3.2.0\\hadoop-3.2.0");
SparkConf conf = new SparkConf();
conf.setMaster("local");
//创建SparkSession对象,里面包含SparkContext和SqlContext
SparkSession sparkSession = SparkSession.builder()
.appName("LoadAndSaveOpJava")
.config(conf)
.getOrCreate();
//读取数据
Dataset stuDf = sparkSession.read()
.format("json")
.load("D:\\student.json");
//保存数据
stuDf.select("name","age")
.write()
.format("csv")
.save("hdfs://bigdata01:9000/out-save002");
sparkSession.stop();
}
}
八、SaveMode
Spark SQL对于save操作,提供了不同的save mode。
主要用来处理,当目标位置已经有数据时应该如何处理。save操作不会执行锁操作,并且也不是原子的,因此是有一定风险出现脏数据的。
SaveMode 解释
SaveMode.ErrorIfExists (默认) 如果目标位置已经存在数据,那么抛出一个异常
SaveMode.Append 如果目标位置已经存在数据,那么将数据追加进去
SaveMode.Overwrite 如果目标位置已经存在数据,那么就将已经存在的数据删除,用新数据进行覆盖
SaveMode.Ignore 如果目标位置已经存在数据,那么就忽略,不做任何操作
在LoadAndSaveOpScala中增加SaveMode的设置,重新执行,验证结果
将SaveMode设置为Append,如果目标已存在,则追加
stuDf.select("name","age")
.write
.format("csv")
.mode(SaveMode.Append)//追加
.save("hdfs://bigdata01:9000/out-save001")
执行之后的结果确实是追加到之前的结果目录中了
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /out-save001 Found 3 items
-rw-r--r-- 3 yehua supergroup 0 2020-05-29 17:59 /out-save001/_SUCCESS
-rw-r--r-- 3 yehua supergroup 46 2020-05-29 17:59 /out-save001/part-00000-94a0141a-49f1-45a5-b2a4-0bdd89647ab1-c000.csv
-rw-r--r-- 3 yehua supergroup 46 2020-05-29 17:53 /out-save001/part-00000-9bf82de6-b23e-4118-bc05-34e0466aa295-c000.csv
九、内置函数
Spark中提供了很多内置的函数,
种类 函数
聚合函数 avg, count, countDistinct, first, last, max, mean, min, sum, sumDistinct
集合函数 array_contains, explode, size
日期/时间函数 datediff, date_add, date_sub, add_months, last_day, next_day, months_between, current_date, current_timestamp, date_format
数学函数 abs, ceil, floor, round
混合函数 if, isnull, md5, not, rand, when
字符串函数 concat, get_json_object, length, reverse, split, upper
窗口函数 denseRank, rank, rowNumber
其实这里面的函数和hive中的函数是类似的
注意:SparkSQL中的SQL函数文档不全,其实在使用这些函数的时候,大家完全可以去查看hive中sql的文档,使用的时候都是一样的。