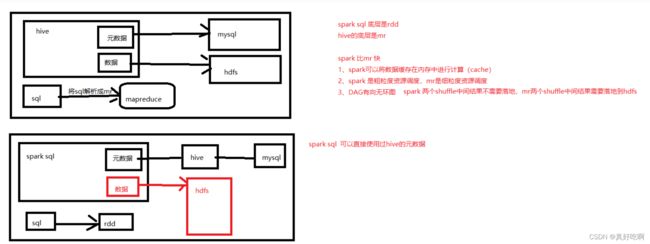
Spark SQL整合hive
Spark SQL
- Spark SQL整合Hive
-
-
-
- 1. 修改Hive配置文件hive-site.xml
- 2. 将hive-site.xml 复制到spark conf目录下
- 3. 启动hive元数据服务
- 4.将mysql 驱动包复制到saprk jars目录下
- 5. 启动Spark SQL
-
-
- 案例
-
- 6. sparkSql在代码中使用hive中的表
-
-
Spark SQL整合Hive
1. 修改Hive配置文件hive-site.xml
在Hive的conf目录下
在hive-site.xml中添加以下内容
<property>
<name>hive.metastore.urisname>
<value>thrift://master:9083value>
property>
2. 将hive-site.xml 复制到spark conf目录下
cp hive-site.xml /usr/local/soft/spark-2.4.5/conf/
3. 启动hive元数据服务
nohup hive --service metastore >> metastore.log 2>&1 &
4.将mysql 驱动包复制到saprk jars目录下
在Hive的lib目录下找到mysql驱动包
cp mysql-connector-java-5.1.17.jar /usr/local/soft/spark-2.4.5/jars/
5. 启动Spark SQL
文件小可以将并行度改小一点,默认并行度为200。
并行度的计算:10G的文件 / 128MB = 80
10G的文件需要80个Task
spark-sql
spark-sql --master yarn-client
--master yarn-client这个参数不写的话默认是local模式的
--不可以使用yarn-cluster,因为Driver端必须要在本地启动
spark-sql --master yarn-client --conf spark.sql.shuffle.partitions=2
--conf spark.sql.shuffle.partitions=2 可以在启动spark-sql时就指定,如果启动时不指定的话,后面可以在spark-sql中通过:set spark.sql.shuffle.partitions=2 指定
案例
创建student表
create table student
(
id string,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS textfile
location '/data/student/';
创建score表
create table score
(
student_id string,
cource_id string,
sco int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS textfile
location '/data/score/';
select clazz,count(1) from student group by clazz;
1、统计每个科目排名前十的学生 分组取topN
6. sparkSql在代码中使用hive中的表
执行软件IDEA
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SaveMode, SparkSession}
object Demo9OnHive {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.appName("Demo9OnHive")
.enableHiveSupport()//在代码中开启hive元数据支持,后面写代码可以直接使用hive中的表
.config("spark.sql.shuffle.partitions", 2)
.getOrCreate()
// 导入隐式转换
import spark.implicits._
// 导入Spark SQL所有的函数
import org.apache.spark.sql.functions._
/**
* 通过表名得到DF
* 可以直接写DSL
*/
val stuDF: DataFrame = spark.table("student")
val sqlDF: DataFrame = stuDF.groupBy($"clazz")
.agg(count($"id"))
/**
* 直接编写sql,使用hive中的表
*/
/*
val sqlDF: DataFrame = spark.sql(
"""
select clazz,count(1) from student group by clazz
""".stripMargin)
*/
sqlDF
.write
.format("csv")
.option("sep",",")
.mode(SaveMode.Overwrite)
.save("/data/On_hive")
/**
* 将DF转换成RDD
*/
val rdd: RDD[Row] = stuDF.rdd
/**
* 1. 通过列名和类型 获取数据
*/
val rdd2: RDD[String] = rdd.map(row => {
//通过列名和类型获取字段
val clazz: String = row.getAs[String]("clazz")
clazz
})
/**
* 2. 使用模式匹配的方式
*/
val rdd3: RDD[(String, String, Int, String, String)] = rdd.map {
case Row(id: String, name: String, age: Int, gender: String, clazz: String) => {
(id, name, age, gender, clazz)
}
}
rdd3.saveAsTextFile("/data/rdd3")
}
}
代码写好后,进行打包
上传至虚拟机,运行
spark-submit --master yarn-client --class sparksql.Demo9OnHive SparkLearning-1.0-SNAPSHOT.jar

DF也可以cache
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo10Cache {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.appName("Demo10Cache")
.master("local")
.config("spark.sql.shuffle.partitions", 2)
.getOrCreate()
// 导入隐式转换
import spark.implicits._
// 导入Spark SQL所有的函数
import org.apache.spark.sql.functions._
val stuDF: DataFrame = spark
.read
.format("json")
.load("SparkLearning/src/main/data/wordCount/syudents.json")
//对多次使用的DF进行缓存
stuDF.cache()
stuDF.groupBy($"clazz")
.agg(count($"id"))
.show()
stuDF.groupBy($"gender")
.agg(count($"id"))
.show()
}
}