泰坦尼克号分析
利用泰坦尼克数据集训练一个 SVM 模型,对泰坦尼克号上的乘客是否遇难进行建模,
评估模型的效果并对结果进行适当的分析。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
import warnings
%matplotlib inline
sns.set(style='darkgrid') #使用画图风格
warnings.filterwarnings('ignore') #忽略警告
# 读取数据集,并显示前五行
data = pd.read_csv("titanic.csv")
data.head()
特征解读:
Pclass:乘客所持票类,有三种值(1,2,3)
SibSp:乘客兄弟姐妹/配偶的个数(整数值)
Parch:乘客父母/孩子的个数(整数值)
Ticket:票号(字符串)
Fare:乘客所持票的价格(浮点数,0-500不等)
Cabin:乘客所在船舱(有缺失)
Embark:乘客登船港口:S、C、Q(有缺失)
data.info()#查看特征数据类型以及是否包含缺失值
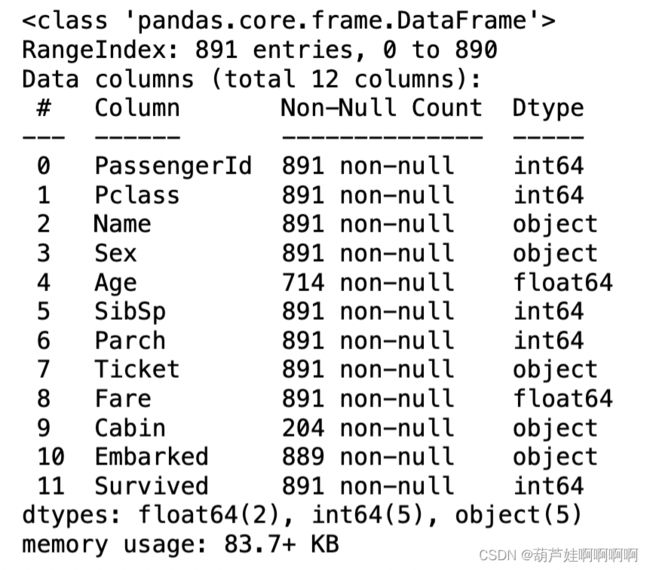
一共有891组数据,其中’Age’这一特征存在一百多个缺失值,缺失数量不算太多,可以使用’Age’这个特征的均值进行填充,‘Cabin’这一特征缺失值太多,故舍去这个特征,‘Embarked’这一特征有两组缺失值,考虑到‘Embarked’缺失值数量很少,可以舍去这两行。
# 各数值型特征的统计性描述结果
data.describe()
# 存活率的饼图和条形图
fig,ax=plt.subplots(1,2,figsize=(10,5))
data.Survived.value_counts().plot.pie(explode=[0,0.15]# 饼之间间隔
,autopct='%1.1f%%',ax=ax[0]
,shadow=True #
,fontsize=13)
ax[0].set_title('Survived',fontsize=13)
ax[0].set_ylabel('')
sns.countplot('Survived',data=data,ax=ax[1])
ax[1].set_title('Survived',fontsize=13)
for y, x in enumerate(data.Survived.value_counts()):
plt.text(y, x , x,fontsize=13)
plt.xticks(fontsize=13)
plt.yticks(fontsize=13)
plt.show()
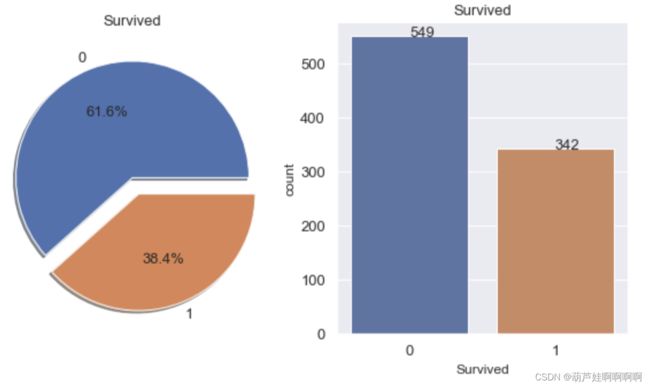
# Sex中male和female的存活人数分别为233,109。
pd.crosstab(data['Sex'],data['Survived'],margins=True).style.background_gradient(cmap='Blues')
# Sex中male和female的存活率分别为0.742038,0.188908,可以看出female存活率远高于male。
pd.crosstab(data['Sex'],data['Survived'],normalize=0,margins=True).style.background_gradient(cmap='Greens')
# 性别 Sex 存活率直方图,以及 Sex 中male和female存活与未存活对比条形图。
fig,ax = plt.subplots(1,2,figsize=(10,5))
data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survived vs Sex',fontsize=13)
sns.countplot('Sex',hue='Survived',data=data,ax=ax[1])
ax[1].set_title('Sex:Survived vs Dead',fontsize=13)
plt.show()

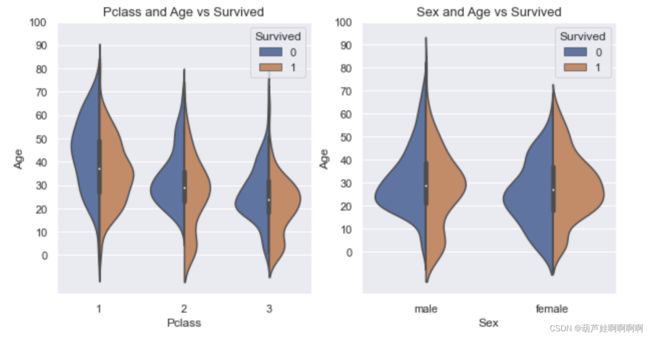
# ‘PClass’和‘Age’的小提琴图以及‘Sex’和‘Age’的小提琴图
fig,ax=plt.subplots(1,2,figsize=(10,5))
sns.violinplot('Pclass','Age',hue='Survived',data=data,split=True,ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived',fontsize=13)
ax[0].set_yticks(range(0,110,10))
sns.violinplot('Sex','Age',hue='Survived',data=data,split=True,ax=ax[1])
ax[1].set_title('Sex and Age vs Survived',fontsize=13)
ax[1].set_yticks(range(0,110,10))
plt.show()
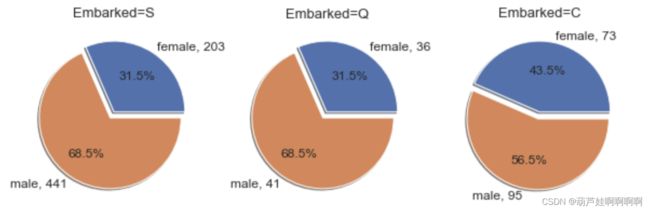
# 乘客登船港口Embarked分别为S、C、Q时female和male数量分布的饼图
# 从图中可以看出不论哪个登船港口,上船的male数量都高于female。
fig,ax = plt.subplots(1,3,figsize=(10,5))
data[data.Embarked=='S'].groupby(['Sex'])['Embarked'].count().plot.pie(explode=[0,0.1],labels=['female, 203','male, 441'],
autopct='%1.1f%%',shadow=True,fontsize=12,ax=ax[0])
ax[0].set_title('Embarked=S',fontsize=13)
ax[0].set_ylabel('')
data[data.Embarked=='S'].groupby(['Sex'])['Embarked'].count().plot.pie(explode=[0,0.1],labels=['female, 36','male, 41'],
autopct='%1.1f%%',shadow=True,fontsize=12,ax=ax[1])
ax[1].set_title('Embarked=Q',fontsize=13)
ax[1].set_ylabel('')
data[data.Embarked=='C'].groupby(['Sex'])['Embarked'].count().plot.pie(explode=[0,0.1],labels=['female, 73','male, 95'],
autopct='%1.1f%%',shadow=True,fontsize=12,ax=ax[2])
ax[2].set_title('Embarked=C',fontsize=13)
ax[2].set_ylabel('')
plt.show()
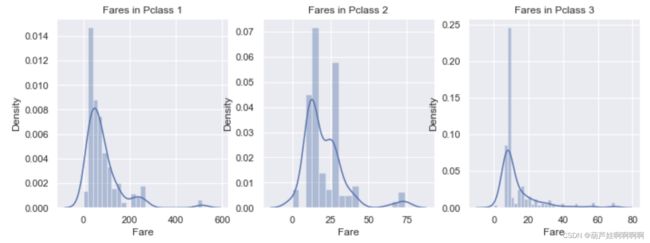
# ‘Pclass’为1,2,3时的‘Fare’密度图
f,ax=plt.subplots(1,3,figsize=(12,4))
sns.distplot(data[data['Pclass']==1].Fare,ax=ax[0])
ax[0].set_title('Fares in Pclass 1')
sns.distplot(data[data['Pclass']==2].Fare,ax=ax[1])
ax[1].set_title('Fares in Pclass 2')
sns.distplot(data[data['Pclass']==3].Fare,ax=ax[2])
ax[2].set_title('Fares in Pclass 3')
plt.show()
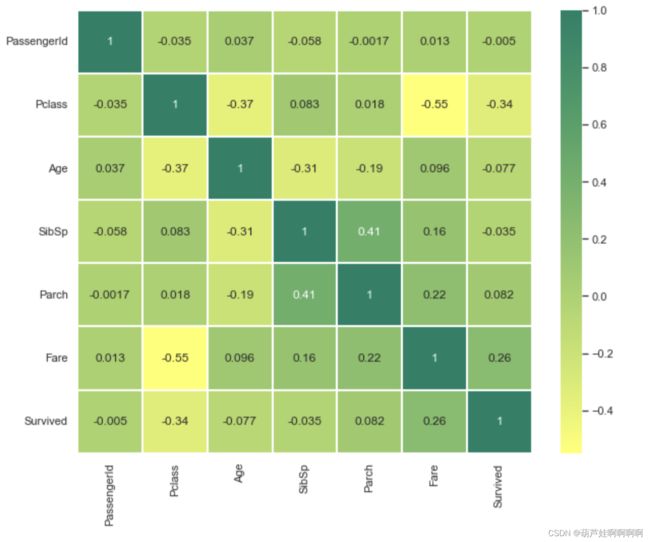
# 各变量之间的相关系数和相关性热图
data.corr()
sns.heatmap(data.corr(),annot=True,cmap='summer_r',linewidths=0.2)
fig=plt.gcf()
fig.set_size_inches(10,8)
plt.show()
- 删除"Cabin"这一列,删除’Embarked’有缺失值的两行,'Age’那列用均值填充缺失值
data = data.drop(columns = "Cabin")
data = data[data['Embarked'].notnull()]
data['Age'] = data['Age'].fillna(round(data['Age'].mean()))
y = data["Survived"]
X = data.loc[:,["Pclass","Sex","Age",'SibSp','Parch','Fare','Embarked']]
X.index = np.arange(X.shape[0])# 处理索引
- 哑变量处理
# 处理后‘S’=2,’Q’=1,’C’=0,’male’=0,’female’=1
X["Sex"] = pd.get_dummies(X['Sex'])['female']
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
X['Embarked'] = le.fit_transform(data['Embarked'])
- 建模
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.2,random_state=5)
from sklearn.svm import LinearSVC
np.random.seed(1)
model = LinearSVC(random_state=28, tol=1e-4,max_iter=1000)
model.fit(Xtrain, Ytrain)
y_pred =model.predict(Xtest)
model.score(Xtest, Ytest)
a = pd.DataFrame()
a['真实值']=Ytest
a['预测值']=y_pred
a.index = range(len(Ytest))
a
print('预测值与真实值一样的样本量:',a[a['真实值']==a['预测值']].shape[0])
# 预测值与真实值一样的样本量: 151
- 混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(Ytest,y_pred)
'''
array([[107, 12],
[ 15, 44]])
'''
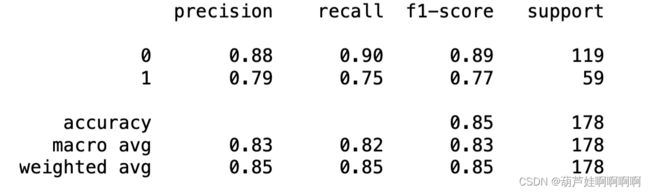
from sklearn.metrics import classification_report
print(classification_report(Ytest,y_pred))
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred,Ytest)
score #0.848314606741573