数据分析实战-酒店价格因素分析-Python
数据集和源代码放在资源里了
数据集和源代码
导入所需要的包
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LinearRegression as LR
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] #显示中文标签
读取数据,并显示前五行
df = pd.read_csv('hoteldata.csv')
df.head()
- 看特征数据类型以及是否包含缺失值
df.info()
- 查看数值型变量数据情况
df.describe()
描述性分析
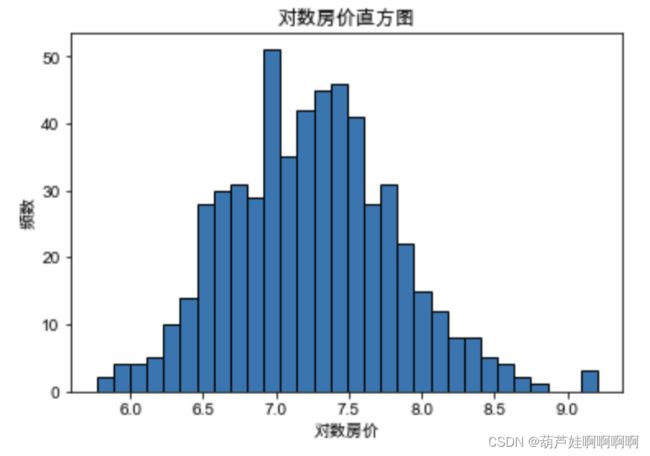
- 绘制对数房价
df["对数房价"] = np.log(df["房价"])
plt.figsize = (8, 8)
plt.hist(df['对数房价'], bins = 30, edgecolor = 'k')
plt.xlabel('对数房价')
plt.ylabel('频数')
plt.title('对数房价直方图')
plt.show()
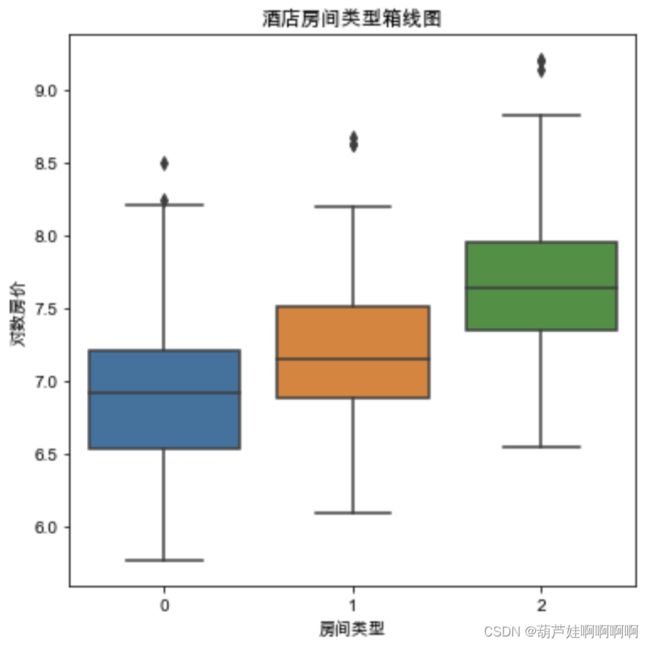
- 绘制酒店房间类型箱线图
#酒店房间类型
plt.figure(figsize=(6,6))
sns.boxplot(x='房间类型',y='对数房价',data=df)
plt.title("酒店房间类型箱线图")
plt.show()
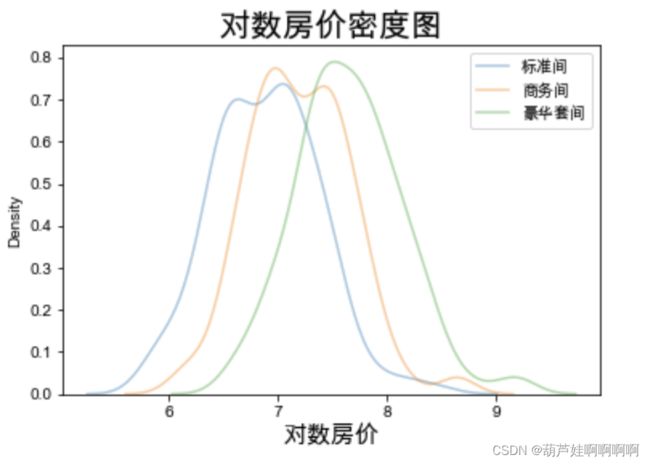
- 绘制对数房价密度图
types = set(df["房间类型"])
figsize = (15, 10)
for i in types:
subset = df[df["房间类型"] == i]
sns.kdeplot(subset['对数房价'],label = i , shade = False, alpha = 0.4)
plt.xlabel('对数房价', size = 15)
plt.legend()
plt.title('对数房价密度图', size = 20)
plt.show()
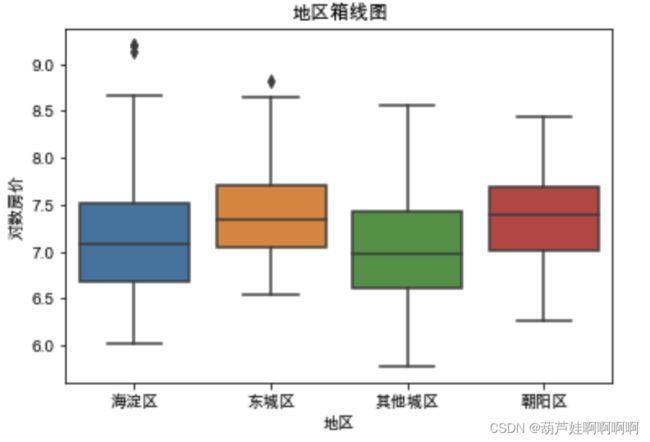
#酒店区域因素分析
plt.figsize = (8, 8)
sns.boxplot(x='地区',y='对数房价',data=df)
plt.title("地区箱线图")
plt.show()
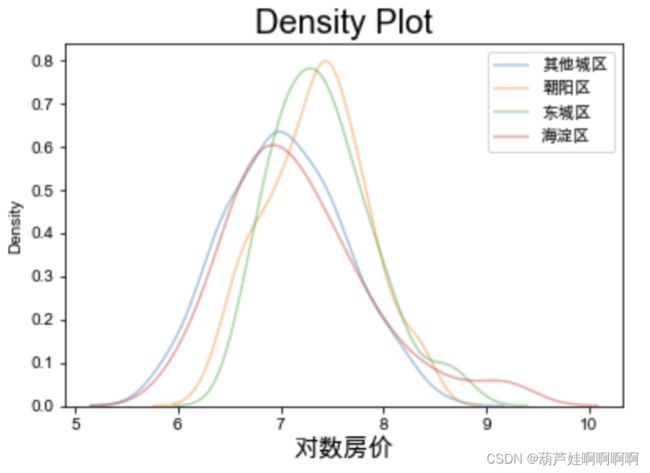
types = set(df["地区"])
figsize = (15, 10)
for i in types:
subset = df[df["地区"] == i]
sns.kdeplot(subset['对数房价'],label = i , shade = False, alpha = 0.4)
plt.xlabel('对数房价', size = 15)
plt.legend()
plt.title('Density Plot', size = 20)
plt.show()
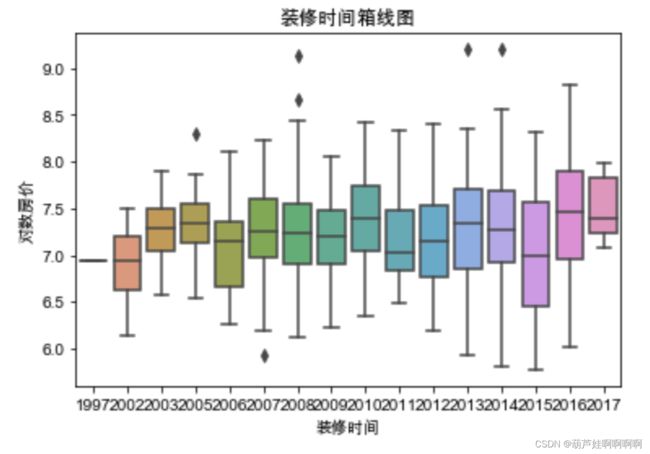
#酒店装修时间因素分析
plt.figsize = (20, 8)
sns.boxplot(x='装修时间',y='对数房价',data=df)
plt.title("装修时间箱线图")
plt.show()
plt.figsize = (8, 8)
plt.hist(df['经度'], bins = 30, edgecolor = 'k')
plt.xlabel('经度')
plt.ylabel('频数')
plt.title('经度直方图')
plt.show()
plt.figsize = (8, 8)
plt.hist(df['纬度'], bins = 30, edgecolor = 'k')
plt.xlabel('纬度')
plt.ylabel('频数')
plt.title('纬度直方图')
plt.show()
plt.figsize = (8, 8)
plt.hist(df['评价数'], bins = 30, edgecolor = 'k')
plt.xlabel('评价数')
plt.ylabel('频数')
plt.title('评价数直方图')
plt.show()
plt.scatter(df['对数房价'],df["评价数"],color="green",alpha=0.5)
plt.xlabel('评价数')
plt.ylabel('对数房价')
plt.title("对数房价与评价数散点图")
plt.show()
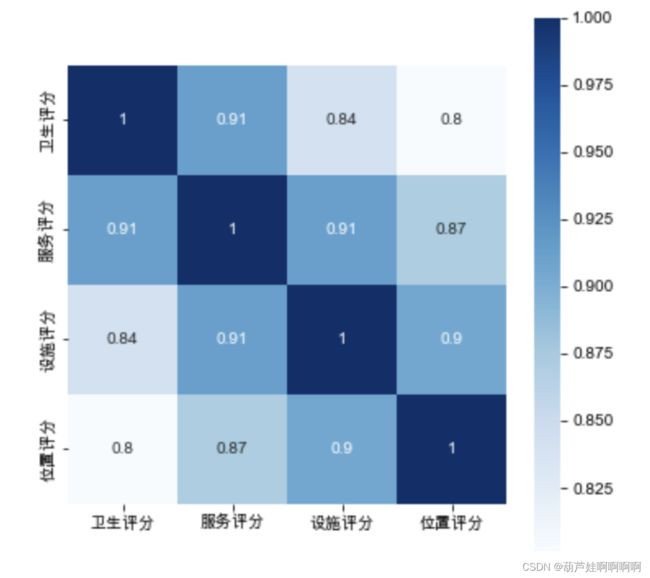
grade=pd.DataFrame([df['卫生评分'],df['服务评分'],df['设施评分'],df['位置评分']]).T
correlation=grade.corr()
plt.subplots(figsize=(6, 6))
sns.heatmap(correlation, annot=True, square=True, cmap="Blues")
plt.show()
df["评分"] = (df["卫生评分"] + df["服务评分"] +df["设施评分"] +df["位置评分"])/4
plt.scatter(df['对数房价'],df["评分"],color="black",alpha=0.5)
plt.xlabel('对数房价')
plt.ylabel('评分')
plt.show()
plt.scatter(df['对数房价'],df["公司"],color="green",alpha=0.5)
plt.xlabel('公司')
plt.ylabel('对数房价')
plt.title("对数房价与公司散点图")
plt.show()
plt.scatter(df['对数房价'],df["出行住宿"],color="red",alpha=0.5)
plt.xlabel('出行住宿')
plt.ylabel('对数房价')
plt.title("对数房价与出行住宿散点图")
plt.show()
plt.scatter(df['对数房价'],df["校园生活"],color="purple",alpha=0.5)
plt.xlabel('校园生活')
plt.ylabel('对数房价')
plt.title("对数房价与校园生活散点图")
plt.show()
- 数据分组和哑变量处理
df["装修时间"] = pd.cut(df["装修时间"],[0,2015,2020],labels = ["旧装修","新装修"])
df[["房间类型"]] = df[["房间类型"]].replace({'标准间': 0, '商务间': 1, '豪华套间': 2})
le = LabelEncoder()
df['地区'] = le.fit_transform(df['地区'])
df["装修时间"] = le.fit_transform(df["装修时间"])
df["评分"] = le.fit_transform(df["评分"])
- 数据标准化
from sklearn import preprocessing
df['评分']=preprocessing.scale(df['评分'])
df['校园生活']=preprocessing.scale(df['校园生活'])
df['公司']=preprocessing.scale(df['公司'])
df['出行住宿']=preprocessing.scale(df['出行住宿'])
df['评价数']=preprocessing.scale(df['评价数'])
对数线性回归模型
features=['地区','房间类型','装修时间','评分','校园生活','公司','出行住宿',"评价数"]
X = df[features]
y = df[["对数房价"]]
import statsmodels.api as sm
# 模型训练
model = sm.OLS(y, X).fit()
# 查看模型结果
model.summary()

# 提取回归系数
sm.OLS(y, X).fit().params
#R2
sm.OLS(y, X).fit().rsquared
# P值
sm.OLS(y, X).fit().pvalues
# 为了检验上述回归中是否存在严重的多重共线性,使用Python的VIF检验模块来验证:
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif = [variance_inflation_factor(X.values, X.columns.get_loc(i)) for i in X.columns]
vif