实现需求:
从网上(随便一个网址,我爬的网址会在评论区告诉大家,dddd)获取某一年的历史天气信息,包括每天最高气温、最低气温、天气状况、风向等,完成以下功能:
(1)将获取的数据信息存储到csv格式的文件中,文件命名为”城市名称.csv”,其中每行数据格式为“日期,最高温,最低温,天气,风向”;
(2)在数据中增加“平均温度”一列,其中:平均温度=(最高温+最低温)/2,在同一张图中绘制两个城市一年平均气温走势折线图;
(3)统计两个城市各类天气的天数,并绘制条形图进行对比,假设适合旅游的城市指数由多云天气占比0.3,晴天占比0.4,阴天数占比0.3,试比较两个城市中哪个城市更适合旅游;
(4)统计这两个城市每个月的平均气温,绘制折线图,并通过折线图分析该城市的哪个月最适合旅游;
(5)统计出这两个城市一年中,平均气温在18~25度,风力小于5级的天数,并假设该类天气数越多,城市就越适宜居住,判断哪个城市更适合居住;
爬虫代码:
import random
import time
from spider.data_storage import DataStorage
from spider.html_downloader import HtmlDownloader
from spider.html_parser import HtmlParser
class SpiderMain:
def __init__(self):
self.html_downloader=HtmlDownloader()
self.html_parser=HtmlParser()
self.data_storage=DataStorage()
def start(self):
"""
爬虫启动方法
将获取的url使用下载器进行下载
将html进行解析
数据存取
:return:
"""
for i in range(1,13): # 采用循环的方式进行依次爬取
time.sleep(random.randint(0, 10)) # 随机睡眠0到40s防止ip被封
url="XXXX"
if i<10:
url =url+"20210"+str(i)+".html" # 拼接url
else:
url=url+"2021"+str(i)+".html"
html=self.html_downloader.download(url)
resultWeather=self.html_parser.parser(html)
if i==1:
t = ["日期", "最高气温", "最低气温", "天气", "风向"]
resultWeather.insert(0,t)
self.data_storage.storage(resultWeather)
if __name__=="__main__":
main=SpiderMain()
main.start()
import requests as requests
class HtmlDownloader:
def download(self,url):
"""
根据给定的url下载网页
:param url:
:return: 下载好的文本
"""
headers = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0"}
result = requests.get(url,headers=headers)
return result.content.decode('utf-8')
此处大家需要注意,将User-Agent换成自己浏览器访问该网址的,具体如何查看呢,其实很简单,只需大家进入网站后,右键网页,然后点击检查将出现这样的界面:
然后只需再点击网络,再随便点击一个请求,如下图:

就可以进入如下图,然后再复制,图中User-Agent的内容就好了!
继续:
from bs4 import BeautifulSoup
class HtmlParser:
def parser(self,html):
"""
解析给定的html
:param html:
:return: area set
"""
weather = []
bs = BeautifulSoup(html, "html.parser")
body = bs.body # 获取html中的body部分
div = body.find('div', {'class:', 'tian_three'}) # 获取class为tian_three的
ul = div.find('ul') # 获取div中的import pandas as pd
class DataStorage:
def storage(self,weather):
"""
数据存储
:param weather list
:return:
"""
data = pd.DataFrame(columns=weather[0], data=weather[1:]) # 格式化数据
data.to_csv("C:\\Users\\86183\\Desktop\\成都.csv", index=False, sep=",",mode="a") # 保存到csv文件当中
注意,文件保存路径该成你们自己的哦!
ok,爬取代码就到这,接下来是图形化效果大致如下:
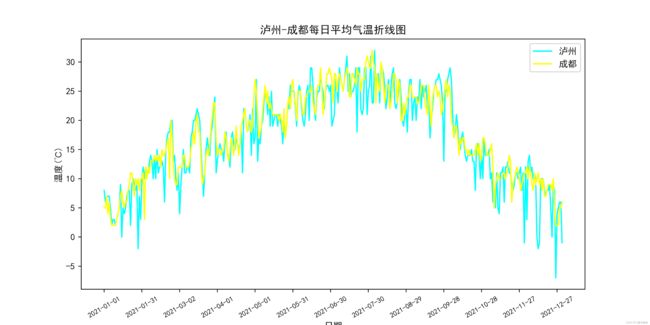


代码如下:
import pandas as pd
import matplotlib as mpl
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 该语句解决图像中的“-”负号的乱码问题
def broken_line_chart(x, y1, y2): # 折线图绘制函数
plt.figure(dpi=500, figsize=(10, 5))
plt.title("泸州-成都每日平均气温折线图")
plt.plot(x, y1, color='cyan', label='泸州')
plt.plot(x, y2, color='yellow', label='成都')
# 获取图的坐标信息
coordinates = plt.gca()
# 设置x轴每个刻度的间隔天数
xLocator = mpl.ticker.MultipleLocator(30)
coordinates.xaxis.set_major_locator(xLocator)
# 将日期旋转30°
plt.xticks(rotation=30)
plt.xticks(fontsize=8)
plt.ylabel("温度(℃)")
plt.xlabel("日期")
plt.legend()
plt.savefig("平均气温走势折线图.png") # 平均气温折线图
plt.show()
plt.close()
data_luZhou = pd.read_csv('C:\\Users\\86183\\Desktop\\泸州.csv')
data_chengdu = pd.read_csv('C:\\Users\\86183\\Desktop\\成都.csv')
# 将列的名称转为列表类型方便添加
columS = data_luZhou.columns.tolist()
columY = data_chengdu.columns.tolist()
# 将数据转换为列表
data_luZhou=np.array(data_luZhou).tolist()
data_chengdu=np.array(data_chengdu).tolist()
# 在最开始的位置上添加列的名字
data_luZhou.insert(0, columS)
data_chengdu.insert(0, columY)
# 添加平均气温列
data_luZhou[0].append("平均气温")
data_chengdu[0].append("平均气温")
weather_dict_luZhou = {}
weather_dict_chengdu = {}
for i in range(1, len(data_luZhou)):
# 去除日期中的星期
data_luZhou[i][0] = data_luZhou[i][0][0:10]
data_chengdu[i][0] = data_chengdu[i][0][0:10]
# 获取平均气温
average_luZhou = int((int(data_luZhou[i][1]) + int(data_luZhou[i][2])) / 2)
average_chengdu = int((int(data_chengdu[i][1]) + int(data_chengdu[i][2])) / 2)
# 将平均气温添加进入列表中
data_luZhou[i].append(average_luZhou)
data_chengdu[i].append(average_chengdu)
# 将新的数据存入新的csv中
new_data_luZhou = pd.DataFrame(columns=data_luZhou[0], data=data_luZhou[1:])
new_data_chengdu = pd.DataFrame(columns=data_chengdu[0], data=data_chengdu[1:])
new_data_luZhou.to_csv("D:/PythonProject/spider/泸州.csv", index=False, sep=",")
new_data_chengdu.to_csv("D:/PythonProject/spider/成都.csv", index=False, sep=",")
# 折线图的绘制
y1 = np.array(new_data_luZhou.get("平均气温")).tolist()
y2 = np.array(new_data_chengdu.get("平均气温")).tolist()
x = np.array(new_data_luZhou.get("日期")).tolist()
broken_line_chart(x, y1, y2)
# 进行每个月的平均气温求解
new_data_luZhou["日期"] = pd.to_datetime(new_data_luZhou["日期"])
new_data_chengdu["日期"] = pd.to_datetime(new_data_chengdu["日期"])
new_data_luZhou.set_index("日期", inplace=True)
new_data_chengdu.set_index("日期", inplace=True)
# 按月进行平均气温的求取
month_l = new_data_luZhou.resample('m').mean()
month_l = np.array(month_l).tolist()
month_c = new_data_chengdu.resample('m').mean()
month_c = np.array(month_c).tolist()
length = len(month_c)
month_average_l = []
month_average_c = []
for i in range(length):
month_average_l.append(month_l[i][2])
month_average_c.append(month_c[i][2])
month_list = [str(i) + "月" for i in range(1, 13)]
plt.figure(dpi=500, figsize=(10, 5))
plt.title("泸州-成都每月平均折线气温图")
plt.plot(month_list, month_average_l, color="cyan",label="泸州", marker='o')
plt.plot(month_list, month_average_c, color="blue",label='成都', marker='v')
for a, b in zip(month_list, month_average_l):
plt.text(a, b + 0.5, '%.2f' % b, horizontalalignment='center', verticalalignment='bottom', fontsize=6)
for a, b in zip(month_list, month_average_c):
plt.text(a, b - 0.5, '%.2f' % b, horizontalalignment='center', verticalalignment='bottom', fontsize=6)
plt.legend()
plt.xlabel("月份")
plt.ylabel("温度(℃)")
plt.savefig("月平均气温折线图.png") # 月平均气温折线图
plt.show()
#
# 只获取两列的数据
data_l = pd.read_csv("泸州.csv", usecols=['风向', '平均气温'])
data_c = pd.read_csv("成都.csv", usecols=['风向', '平均气温'])
data_l = np.array(data_l).tolist()
data_c = np.array(data_c).tolist()
day_c = 0
day_l = 0
for i in range(len(data_l)):
if len(data_l[i][0]) == 5:
if int(data_l[i][0][3]) < 5 and 18 <= int(data_l[i][1]) <= 25:
day_l += 1
else:
if int(data_l[i][0][2]) < 5 and 18 <= int(data_l[i][1]) <= 25:
day_l += 1
if len(data_c[i][0]) == 5:
if int(data_c[i][0][3]) < 5 and 10 <= int(data_c[i][1]) <= 25:
day_c += 1
else:
if int(data_c[i][0][2]) < 5 and 18 <= int(data_c[i][1]) <= 25:
day_c += 1
plt.figure(dpi=500, figsize=(8, 4))
plt.title("泸州-成都平均气温在18-25且风力<5级的天数")
list_name = ['泸州', '成都']
list_days = [day_l, day_c]
plt.bar(list_name, list_days, width=0.5)
plt.text(0, day_l, '%.0f' % day_l, horizontalalignment='center', verticalalignment='bottom', fontsize=7)
plt.text(1, day_c, '%.0f' % day_c, horizontalalignment='center', verticalalignment='bottom', fontsize=7)
plt.xlabel("城市")
plt.ylabel("天数(d)")
plt.savefig("适宜居住柱形图.png")
plt.show()
data_l=pd.read_csv("泸州.csv")
data_c=pd.read_csv("成都.csv")
# 将数据转换为列表
data_l=np.array(data_l).tolist()
data_c=np.array(data_c).tolist()
# 获取每种天气的天数,采用字典类型进行存储
for i in range(1,365):
weather_l = data_l[i][3]
weather_c = data_c[i][3]
if weather_l in weather_dict_luZhou:
weather_dict_luZhou[weather_l] = weather_dict_luZhou.get(weather_l) + 1
else:
weather_dict_luZhou[weather_l]=1
if weather_c in weather_dict_chengdu:
weather_dict_chengdu[weather_c]=weather_dict_chengdu.get(weather_c)+1
else:
weather_dict_chengdu[weather_c]=1
weather_list_luZhou = list(weather_dict_luZhou)
weather_list_chengdu = list(weather_dict_chengdu)
value_l = []
value_c = []
# 获取所有的天气种类
weather_list = sorted(set(weather_list_luZhou + weather_list_chengdu))
# 获取每种天气的天数,并将其对应的放入列表中,没有的则用0进行替代,方便条形图的绘制。
for i in weather_list:
if i in weather_dict_luZhou:
value_l.append(weather_dict_luZhou[i])
else:
value_l.append(0)
if i in weather_dict_chengdu:
value_c.append(weather_dict_chengdu[i])
else:
value_c.append(0)
# 绘制条形图进行对比
plt.figure(dpi=500, figsize=(10, 5))
plt.title("泸州-成都各种天气情况对比")
x1 = list(range(len(weather_list)))
x = [i + 0.4 for i in x1]
plt.bar(x1, value_l, width=0.4, color='red', label='泸州')
plt.bar(x, value_c, width=0.4, color='orange', label='成都')
for a, b in zip(x1, value_l):
plt.text(a, b + 0.4, '%.0f' % b, ha='center', va='bottom', fontsize=7)
for a, b in zip(x, value_c):
plt.text(a, b + 0.4, '%.0f' % b, ha='center', va='bottom', fontsize=7)
plt.xticks(x1, weather_list)
plt.ylabel("天数")
plt.xlabel("天气")
plt.xticks(rotation=270)
plt.legend()
plt.savefig("泸州成都天气情况对比.png")
plt.show()
plt.close()
好的这次就到这儿吧,我们下次见哦!!!
到此这篇关于Python实战实现爬取天气数据并完成可视化分析详解的文章就介绍到这了,更多相关Python爬取天气数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!