
Pencil
网易游戏数据与平台的离线平台组高级开发工程师,目前负责 Trino(Presto)/Doris 等组件的开发和业务支持工作。离线平台小组目前为广州互娱的大数据离线计算提供了接近 EB 级别的大数据存储集群服务,以及 Hive/Spark/Presto/Doris/ClickHouse 等计算框架的开发与业务支持。
一、背景
随着公司游戏业务的高速发展,越来越多的分析需求涌现,例如:各类游戏用户行为分析、商业智能分析、数仓报表等。这些场景的数据体量都较大,对数据分析平台提出了很高的要求。为了解决实时分析的时效性,同时又能保证数据快速写入和查询,需要一个合适的数据查询引擎来补充我们原有的架构体系。
经过大量调研,Apache Doris 比较契合网易互娱游戏数据中心的整体要求,Apache Doris 具备以下优秀特性:
-
MPP架构 + 高效列式存储引擎
-
高性能、高可用、高弹性
-
标准ANSI SQL支持
-
支持多表Join
-
支持MySQL协议
-
-
支持预聚合
-
支持物化视图
-
支持预聚合结果自动更新
-
-
支持数据高效的批量导入、实时导入
-
支持数据的实时更新
-
支持高并发查询
-
周边生态完善
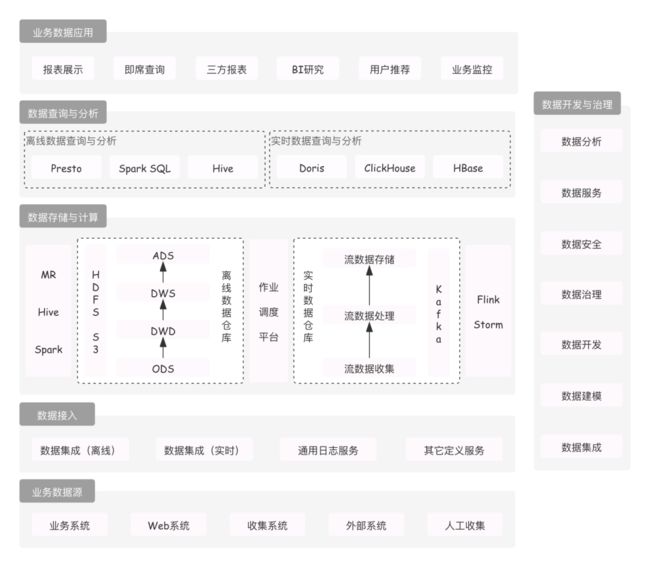
网易互娱于 2021 年 4 月引入了 Apache Doris 产品,目前已经发展为多个集群,服务数十个业务,如游戏舆情分析,实时日活看板、用户事件分析、留存分析、漏斗分析、分布分析等。当前 OLAP 平台与数仓体系融合的架构如下图所示:
二、Apache Doris 简介
Apache Doris 是百度开源的 MPP 分析型数据库产品,不仅能够在亚秒级响应时间即可获得查询结果,有效的支持实时数据分析,而且支持 PB 级别的超大数据集。相较于其他业界比较火的 OLAP 数据库系统,Doris 的分布式架构非常简洁,只有 FE、BE 两个服务,整体运行不依赖任何第三方系统,支持弹性伸缩,对于业务线部署运维到使用都非常友好。目前国内社区火热,也有腾讯、字节跳动、美团、小米等大厂在使用。
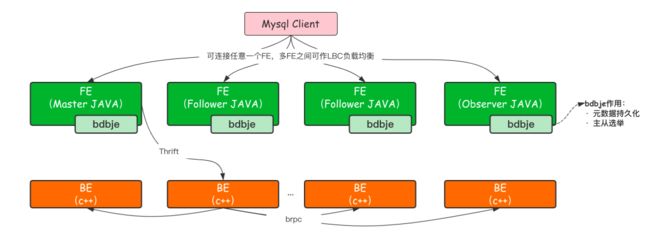
2.1 FE
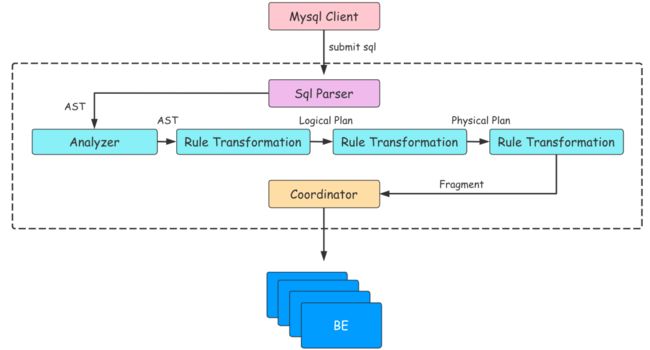
FE 的主要作用将 SQL 语句转换成 BE 能够认识的 Fragment,如果把 BE 集群当成一个分布式的线程池的话,那么 Fragment 就是线程池中的 Task。从 SQL 文本到分布式物理执行计划,FE 的主要工作需要经过以下几个步骤:
-
SQL Parse:将 SQL 文本转换成一个 AST(抽象语法树)
-
SQL Analyze:基于 AST 进行语法和语义分析
-
SQL Logical Plan:将 AST 转换成逻辑计划
-
SQL Optimize:基于关系代数,统计信息,Cost 模型对逻辑计划进行重写,转换,基于 Cost 选出成本最低的物理执行计划
-
生成 Plan Fragment:将 Optimizer 选择的物理执行计划转换为 BE 可以直接执行的 Plan Fragment
-
执行计划的调度
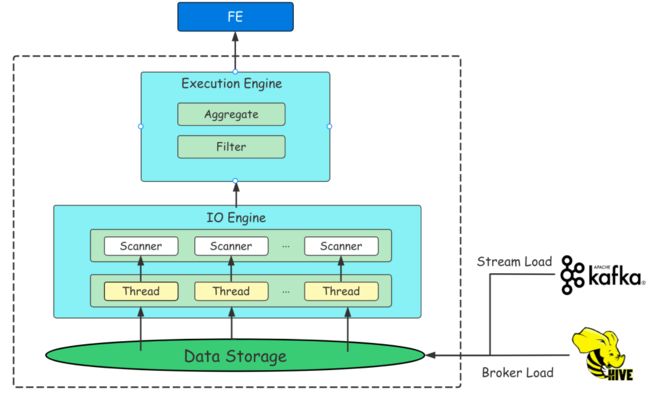
2.2 BE
BE 是 Doris 的后端节点,负责数据存储以及 SQL 计算执行等工作。
BE 节点都是完全对等的,FE 按照一定策略将数据分配到对应的 BE 节点。在数据导入时,数据会直接写入到 BE 节点,不会通过 FE 中转,BE 负责将导入数据写成对应的格式以及生成相关索引。在执行 SQL 计算时,一条 SQL 语句首先会按照具体的语义规划成逻辑执行单元,然后再按照数据的分布情况拆分成具体的物理执行单元。物理执行单元会在数据存储的节点上进行执行,这样可以避免数据的传输与拷贝,从而能够得到极致的查询性能。
三、 集群治理
3.1 Compaction 调优 - Tablet 治理
在网易互娱引入 Apache Doris 初期,业务用户在测试过程中发现建表时指定 bucket 数越大,查询速度越快,导致了用户在新建表和分区时统一将 bucket 数指定为 64。随着导入的数据越来越多,问题也开始暴露了出来:业务陆续反馈 alter 分区失败、修改字段长度失败等问题。经过 SA 排查发现这些失败都是超时导致,同时发现业务操作的表数据量仅 2G,replica 数却达到了 68736:

更进一步地,为了将问题彻底暴露出来,对该集群进行全量统计发现 60T 的数据量达到了接近 2000 万的 tablet 数,tablet 数过多会导致以下几个问题:
-
用户建分区,建表,修改字段等元数据操作耗时长,甚至会超时失败;
-
元数据都放在 FE 内存中,GC 压力较大,同时 FE 在进行 Checkpoint 操作时由于元数据占用内存翻倍,极易出现 OOM 的风险;
bucket 数是查询吞吐和查询并发的一种权衡,为了集群的健康发展,旧数据必须进行 tablet 治理,新的建表规范需建立起来。
3.1.1 治理目标
从上面的计算公式可知,在用户的场景下,前两者都是固定不变的,决定 tablet 数大小的只有 bucket 数。
鉴于该集群目前数据量大小为 60T 左右,结合对 bucket 的更进一步理解以及当前集群实际情况,治理的目标和长期控制的目标定为:
1. tablet 数:2000w -> 100w
2. tablet 增长量:15000/TB
3.1.2 实施计划
(1)对于现存的表
-
扫描集群内所有的表,以分区粒度输出一份完整的数据统计给业务方,并根据每张表的实际情况附上修改建议;
-
制定治理计划按照由高收益到低收益,优先处理最不合理的库,将元数据管理压力降下来,再逐步按照计划治理所有的库。
因为 Doris 目前不支持按分区级别展示整个库下的数据情况,因此单独开发一个程序进行扫描,伪代码如下所示:
con = DriverManager.getConnection()
for db in db_list:
con.execute("use %s".format(db)))
for table in table_list:
con.execute("show create table %s".format(table)) #获取第一个分区的bukcet数
result.append(regrex_extract_bucket(con.next()))
con.execute("show partitions from %s".format(table))
result.append(regrex_extract_bucket(con.next())) #获取除第一个分区的bukcet数
write_result_to_excel(result)
截取部分写入 Excel 的数据,统计格式如下:
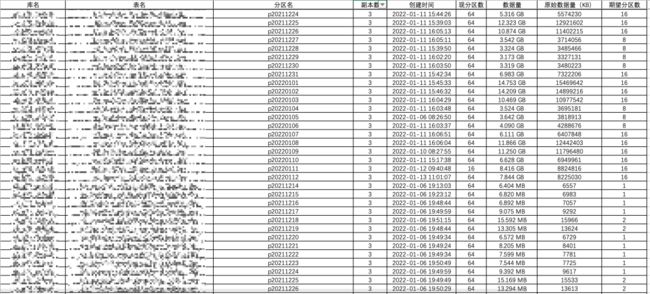
结合 Excel 优秀的透视表功能,即可轻松获取表粒度、以及库粒度下的治理建议统计表,最终治理目标也是依据计算出来的总期望分区数得到。以库粒度做统计截取部分数据如下所示:
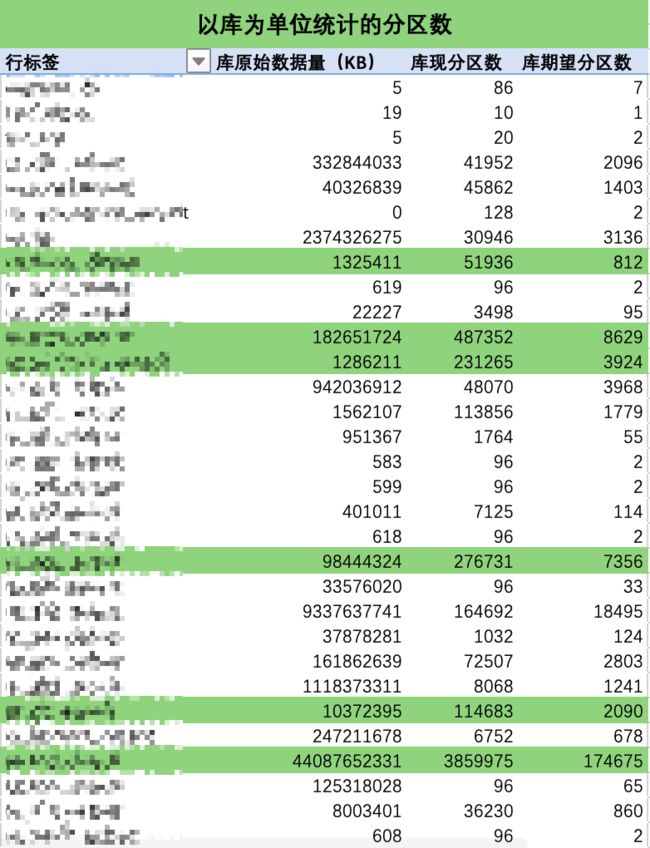
根据统计表得到的信息,优先选择高收益率的库进行治理(上图中已标绿),对表的治理方式有以下两种方式:
第一种方式:数据重插
# 鉴于Doris对所有已存在分区的bucket数无法修改的情况,使用新建表重插的方式进行,步骤为:
1. create table xxx_bak
for partition in partition_range:
if(partition.data != null)
2. alter table xxx_bak add partition if not exists date bucket[动态值]; //动态值根据每一个分区实际的数据量计算传入
3. insert into xxx_bak select * from xxx where dt=date
4. 检查新的xxx数据量,分区数是否正确;//重点!!
5. ALTER TABLE xxx RENAME xxx_old;
6. ALTER TABLE xxx_bak RENAME xxx;
7. drop xxx_old。
-----
方案说明:根据优先顺序对一张待治理的表进行步骤1和步骤2,第3步使用串行的方式提交执行(减少资源占用和出错的可能性)。执行完后根据数据验证方案对数据进行验证,确保无误后进行5,6操作。
特别说明:因为迁移过程中仍然会有数据写入旧表,因此迁移过程中有两个内容要确保:
1、在重插最新的分区过程中,业务控制确保该时间段内没有数据流入;
2、一张表的1-6步骤在下一次写入数据前完成。
3、如未完成则单独标记,在当天结束写入数据和下次写入数据前完成该分区的重插。根据业务反馈大部分load分区操作都能在1分钟完成,所以重插的时间窗口是很大的。
使用该种方式对三种类型的表进行测试,结果如下:
-
小表测试 21.5M 6806tablet 650s
-
中表测试 19G 4191tablet 330s
-
大表测试 188G 10624tablet 1930s
第二种方式:数据重 Load
# 对于表数据在Hive数据还存在的,该方式更为简单
1. drop partition
2. create partition
3. load data from Hive
(2)对于未来新增表
对于业务方,业务在导入数据时增加判断逻辑,根据 Hive 表数据情况指定 bucket 数,建分区规范如下:
-
0-10M 的数据量:1
-
10-50M 的数据量:2
-
50M-2G 的数据量:4
-
2-5G 的数据量:8
-
5-25G 的数据量:16
-
25-50G 的数据量:32
-
超过 50G 的数据量:64
对于服务方,新增以下措施:
-
监控页面新增 tablet_per_TB_data 指标,及时检测到异常建表建分区的情况。
-
定期(如每月)统计哪些表还存在 tablet 优化的空间,提供给业务,并敦促改进。
3.1.3 治理收益
经过一段时间的治理,tablet 数显著下降:由接近 2000 万下降到 300 多万,业务反馈的元数据操作相关问题明显减少:
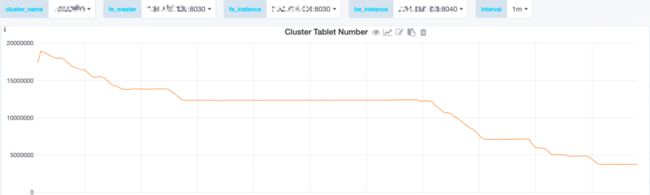
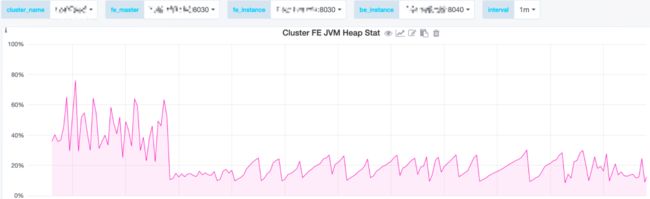
FE 的堆内存占用明显下降,执行 Checkpoint 时,元数据会在内存中复制一份,表现在监控图上是一段尖峰,治理后尖峰变得更缓和,大大提升了 FE 的稳定性:
3.1.4 治理说明
由于 Hive 中数据存储格式与 Doris 数据存储格式不同,因此在数据量判定方面存在差别,会导致 SA 在扫描分区 tablet 数时得到部分治理错误的结论,总体来说实际值会比预期值高,以某库为例:

3.2 Compaction 调优 - Stream Load 治理
3.2.1 问题描述
业务使用的某个 Doris 集群经常出现 BE 异常退出的情况,影响实时数据导入到 Doris 集群,查看监控显示 Compaction Cumulative Score 值波动十分异常:
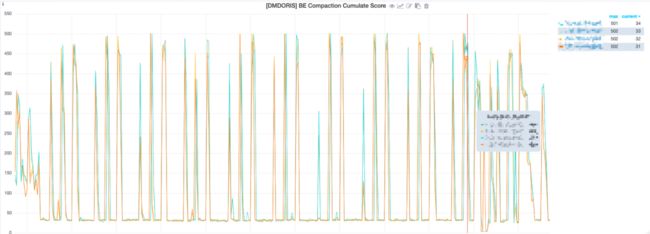
Doris 的数据写入模型使用了 LSM-Tree 类似的数据结构。数据都是以追加(Append)的方式写入磁盘的。这种数据结构可以将随机写变为顺序写。这是一种面向写优化的数据结构,他能增强系统的写入吞吐,但是在读逻辑中,需要通过 Merge-on-Read 的方式,在读取时合并多次写入的数据,从而处理写入时的数据变更。
Merge-on-Read 会影响读取的效率,为了降低读取时需要合并的数据量,基于 LSM-Tree 的系统都会引入后台数据合并的逻辑,以一定策略定期的对数据进行合并。Doris 中这种机制被称为 Compaction。
该值可以反映当前版本堆积的情况,这个值在 100 以内算正常,如果持续逼近 100,说明集群可能存在风险,而从图 11 中可以看到,该集群的 Compaction Score 周期性的逼近 500。
3.2.2 Compaction 参数调节
通过监控图找到一个版本数量最高的 BE 节点。然后执行以下命令分析日志:
grep "succeed to do cumulative compaction" logs/be.INFO |tail -n 100
以上命令可以查看最近 100 个执行完成的 compaction 任务:
I0401 12:59:18.284560 237214 compaction.cpp:141] succeed to do cumulative compaction. tablet=2566873.1945397493.0d4a2195f6f6424d-65b75eda8ddfb0b7, output_version=[2-35622], current_max_version=35646, disk=/disk3/doris-storage, segments=5. elapsed time=0.028255s. cumulative_compaction_policy=SIZE_BASED.
I0401 12:59:18.368721 237212 compaction.cpp:141] succeed to do cumulative compaction. tablet=2566783.1058891652.1640cd0ad79af581-ed2dab3265ffc484, output_version=[2-158658], current_max_version=158682, disk=/disk4/doris-storage, segments=1. elapsed time=0.112345s. cumulative_compaction_policy=SIZE_BASED.
通过日志时间可以判断 Compaction 是否在持续正确的执行,通过 elapsed time 可以观察每个任务的执行时间。
还可以执行以下命令展示最近 100 个 compaction 任务的配额(permits):
grep "permits" logs/doris/be.INFO |tail -n 100
配额和版本数量成正比。
场景一:基线数据量大,Base Compaction 任务执行时间长。
BC 任务执行时间长,意味着一个任务会长时间占用 Compaction 工作线程,从而导致其他 tablet 的 compaction 任务时间被挤占。如果是因为 0 号版本的基线数据量较大导致,则可以考虑尽量推迟增量 rowset 晋升到 BC 任务区的时间。以下两个参数将影响这个逻辑:
cumulative_size_based_promotion_ratio:默认 0.05,基线数据量乘以这个系数,即晋升阈值。可以调大这个系数来提高晋升阈值。
cumulative_size_based_promotion_size_mbytes:默认 1024MB。如果增量 rowset 的数据量大于这个值,则会忽略第一个参数的阈值直接晋升。因此需要同时调整这个参数来提升晋升阈值。
场景二:增量数据版本数量增长较快,Cumulative Compaction 处理过多版本,耗时较长。
max_cumulative_compaction_num_singleton_deltas 参数控制一个 CC 任务最多合并多少个数据版本,默认值为 1000。考虑这样一种场景:针对某一个 tablet,其数据版本的增长速度为 1 个 / 秒。而其 CC 任务的执行时间 + 调度时间是 1000 秒(即单个 CC 任务的执行时间加上 Compaction 再一次调度到这个 tablet 的时间总和)。那么可能会看到这个 tablet 的版本数量在 1-1000 之间浮动。因为在下一次 CC 任务执行前的 1000 秒内,又会累积 1000 个版本。
这种情况可能导致这个 tablet 的读取效率很不稳定。这时可以尝试调小
max_cumulative_compaction_num_singleton_deltas 这个参数,这样一个 CC 所要合并的版本数更少,执行时间更短,执行频率会更高。还是刚才这个场景,假设参数调整到 500,而对应的 CC 任务的执行时间 + 调度时间也降低到 500,则理论上这个 tablet 的版本数量将会在 1-500 之间浮动,相比于之前,版本数量更稳定。
3.2.3 解决方案
(1)临时解决方案
将 max_tablet_version_num 由默认的 500 设置为 1000。
参数描述:限制单个 tablet 最大 version 的数量。用于防止导入过于频繁,或 compaction 不及时导致的大量 version 堆积问题。当超过限制后,导入任务将被拒绝。
这也解释了为什么有 be 宕机后业务的 load 作业也会停止的原因。
(2)最终解决方案
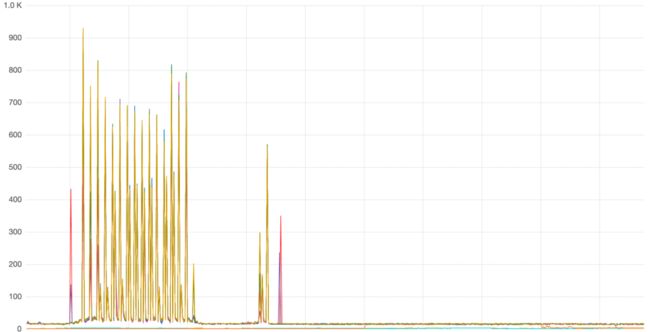
通过审计日志发现,版本数的变化曲线与 Doris Stream Load 导入频率变化曲线一致,所以 Cumulate Compaction Score 过高是 Stream Load 导入频次过高引起。经过和业务的沟通,确定了 Load 参数如下:
1. sink.batch.size 设置为 10000
2. sink.batch.interval 设置为 10s
参数修改后,问题得到了解决:
3.3 集群扩缩容经验分享
3.2.1 背景描述
扩缩容操作简单一直是 Doris 广为人知的优势之一。随着业务的不断迁入,网易互娱内部的 Doris 集群经常会遇到扩容的需求,也遇到了一些问题,现在对扩容经验作总结分享。
3.2.2 扩容后 be 数据不均衡
对某 Doris 集群扩容后,出现了这样一种情况,所有旧的 be 的 tablet 全部迁移到了新的机器中去,如下图所示:
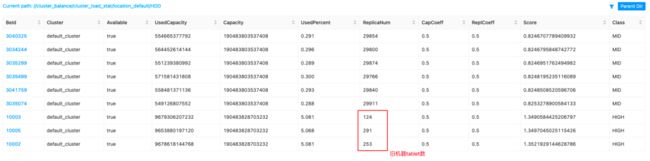
上图中可以看到新增的节点 tablet 数经过自动负载均衡后都到达了 29800 左右,而旧的机器 tablet 数变成了三位数。在最后一列可以看到旧机器的 Class 被打上了 HIGH 标签,而新机器的标签为 MID,从这里开始分析,根据标签定位到以下源码:
public enum Classification {
INIT,
LOW, // load score is Config.balance_load_score_threshold lower than average load score of cluster
MID, // between LOW and HIGH
HIGH // load score is Config.balance_load_score_threshold higher than average load score of cluster
}
从注释中可以看到有一个参数 balance_load_score_threshold 可以界定该节点是负载还是低负载,这个值系统默认是 0.1,在官网中又有如下一段解释:
Class:根据负载情况分类,LOW/MID/HIGH。均衡调度会将高负载节点上的副本迁往低负载节点
被打上 HIGH 标签的 BE 的数据就会往 MID 标签的 BE 中迁移,导致出现了图 13 中下方 3 个 BE tablet 数很少的情况,就是因为他们的 UsedPercent 比其他节点高,所以 score 高出了平均值 0.1。
问题:那么如果我把 balance_load_score_threshold 的数值调大,使得旧机器的标签也变成 MID,是否可以触发新的负载均衡?
结论是不行,当我将 balance_load_score_threshold 调到 0.4 之后,旧机器的标签都变成了 MID,但是新旧机器的 tablet 仍然保持着悬殊的差距。这是因为迁移策略只会从 mid -> low 或者 high -> mid,mid -> mid 不会触发负载均衡,相关源码见:BeLoadRebalancer.java 的 selectAlternativeTabletsForCluster( ) 方法。
当前均衡策略存在的问题:一个 BE 因为其他应用多占用了一些磁盘空间,比其他 BE 高,导致被打了 HIGH 标签后就不存储数据,而实际上他的空间利用率仍然很低?
负载分数计算的源码如下:
// 计算的公式
loadScore.score = capacityProportion * loadScore.capacityCoefficient
+ replicaNumProportion * loadScore.replicaNumCoefficient;
负载因素系数和磁盘使用率系数一般都是 0.5,所以决定 load score 的是 磁盘使用率 和 副本数量 。
double capacityProportion = avgClusterUsedCapacityPercent <= 0 ? 0.0
: usedCapacityPercent / avgClusterUsedCapacityPercent;
从这一行源码中可以看到,无论你的负载多低,只要机器负载之间占比悬殊,最后的 capacityProportion 值都会很大,导致该节点极有可能被打上 HIGH 标签。
3.2.3 解决方法
方法一:
调整 BE 存储数据的磁盘其他因素占用的磁盘空间(如系统预留空间,其他应用程序占用等),使得所有 BE 磁盘除去 BE 存储数据后的磁盘使用率基本一致。
this.totalCapacityB = in.readLong();
...
long availableCapacityB = in.readLong();
this.dataUsedCapacityB = this.totalCapacityB - availableCapacityB;
this.diskAvailableCapacityB = availableCapacityB;
从上述源码可以看到 Doris 通过底层命令拿到了 totalCapacityB 和 availableCapacityB,dataUsedCapacityB 通过两者相减计算了出来。因此要想 BE 存储的数据在各机器之间均衡,就要尽量消除其他因素导致的 BE 之间磁盘初始使用率不均衡。
本案例中是因为旧机器的磁盘 ext4 存在默认 5% 的保留空间,而新机器的保留空间为 1%,通过命令 tune2fs -m 1 /dev/sdXY 将旧机器的预留空间修改为 1% 后,所有 BE 存储的 tablet 数达到了相对均衡的状态。
方法二:
修改 HIGH 标签的判定方式,该补丁已经提交社区,原理是:如果 BE 的磁盘使用率小于 50%,那么无论 BE 之间磁盘使用率多么悬殊,它都不会被打上 HIGH 标签,进而会正常的存储 BE 数据。补丁链接:#9496。
3.2.4 其他经验
-
如果集群只有三台机器,三副本机制下不能 DECOMMISSION 机器;
-
DECOMMISSION 机器后会有部分 Replica 未被迁移,可以先通过 show proc "/statistic" 查看集群是否还有 unhealthy 的分片,如果为 0,则可以直接通过 drop backend 语句删除这个 BE(三副本机制下);
-
DECOMMISSION 机器后 tablet 未做任何迁移,查看当前版本是否打了该补丁:#7563;
四、监控与报警
4.1 监控系统
网易互娱内部自研的 Monitor 智能监控系统提供多种方式上报数据,轻松实现可视化与报警。借助它的基础监控能力,只需安装 agent 即可享受覆盖硬件、操作、进程系统层面的基础监控,覆盖物理机、虚拟机、公有云、私有公、容器等。对于暴露有 Prometheus Exporter 的组件采集,此部份系统已提供了标准插件,只要机器在 Galaxy 上绑定了相应的服务,就会安装相应的插件,自动采集 Metrics 数据并上报 Monitor。Doris 的监控数据通过 Frontend 和 Backend 的 http 接口向外暴露,满足上述快速接入的条件。Monitor 的可视化模块提供仪表盘(集成开源的可视化组件 grafana)、自定义视图等多种灵活配置看板,适用于多种监控场景的跨实例汇聚数据、实时 / 历史数据展示、相似指标对比展示、图表联动等灵活的个性化视图功能,让 SA 快速轻松实现 Doris FE、BE、Broker 的监控面板建设。
4.2 Blackhole 告警
Blackhole 是网易互娱内部广泛使用的监控和报警系统,提供了丰富的报警场景:支持指标、变化、集群、聚合、端口探测、消息、alert.py 事件报警、异常检测动态阈值、预测报警、硬件报警等。目前对 Doris 集群配置的报警规则来自两个方面:
-
借助 Monitor 采集的 Doris 上报的 Metrics 数据,进行关键指标的监控;
-
内部 Doris 的所有服务日志已通过 Loghub 采集并写入 elk 中,对 warn 级别的日志类型进行百分比阈值监控。
经过不断的迭代,目前监控的主要指标包括如下:
-
FE 端口、BE 端口异常告警
-
查询错误率告警
-
查询时间 P90、P95 告警
-
BE 存储使用率告警
-
BE 内存使用告警
-
BE Cumulate Compaction Score 报警
-
Broker Load 并发数报警
-
Broker Load 异常数报警
Blackhole 的通知策略提供了多种模式,简单通知、重复通知、升级通知、触发式通知,故障自愈通知等,确保针对不同级别的故障能得到相应的响应速度。同时我们为 Doris 所有的 FE、BE、Broker 均配置了 Supervisor 守护进程,可以实现服务异常退出后快速自动拉起,结合 Doris 的 FE 高可用机制,基本保证了线上服务的稳定运行。
五、故障处理恢复
当线上集群节点发生故障时,Supervisor 解决了大部分服务异常退出后的恢复,但是仍有少部分的故障需要人为干预。例如以下场景:用户提交的 SQL 触发了 Doris 的某个 BUG,如果不及时解决和干预就会导致集群中不断有节点宕机、拉起,影响其他用户的正常使用。针对该场景下的问题排查,可总结为以下几个步骤:
-
对于 BE 异常退出:
-
首先查看服务宕机节点的 be.out 日志文件,该日志记录了简要的 be 进程退出的堆栈,未得到问题结论则下一步;
-
利用 gdb 及 coredump 文件定位问题(需提前配置让 Linux 服务器产生 coredump 文件)
-
gdb 命令打开文件:gdb DORIS_PATH/be/lib/palo_be coredump_file_name
-
bt 命令展开堆栈,得到展开之后详细的堆栈信息
-
使用 gdb 的调试命令查看堆栈中与查询信息相关的成员变量
-
打印成员变量的 _query_id,并转换为 16 进制
-
在 fe_audit.log 中查找该 16 进制值关键字,即可定位到对应的 sql
-
-
对于 FE 节点异常:
-
如果进程退出,组件层面通过 fe.log 和 fe.warn.log 查看是否有相关报错日志,结合 Monitor 监控面板进行问题定位;
-
如果进程未退出,但服务异常,采用以下几个步骤定位问题:
-
jps 命令参看进程 id
-
top -Hp pid 命令参看高负载线程
-
将线程号转换为 16 进制
-
jstack -l pid | grep 16 进制线程 id
-
jmap -histo:live pid > jmap.log
-
整个问题排查的流程如下图所示:
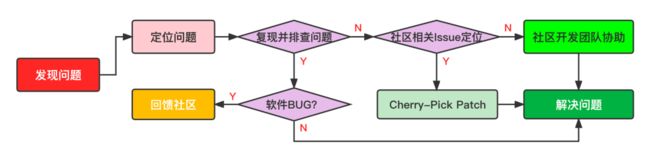
网易互娱内部 Doris 的问题主要来自业务反馈和 SA 对组件巡检两个渠道。在发现问题之后,SA 会利用上面提到的排查方法来定位问题:如果是 Doris 自身存在的 BUG,SA 会积极将问题反馈给社区,同时回馈社区提交修复 PR;对于较为复杂的问题暂时无法解决的,SA 会请求社区开发团队协助排查问题,这里特别感谢 Doris 社区张家锋与陈明雨两位大佬,在很多问题的处理上提供了积极的帮助。
六、结束语
自从 2021 年 4 月网易互娱引入 Apache Doris 以来,Apache Doris 已经在互娱内部得到了广泛地使用,在查询速度及易用性方面也得到了业务的认可,目前有更多的业务正在往 Doris 集群上迁移。结合网易互娱丰富的大数据生态系统以及 Doris 组件易运维的特性,SA 也可以快速满足业务增长需求,交付新集群和完成旧集群扩容的工作。当然 Doris 目前也存在一些问题,比如社区对发行版本存在的高危问题没有做及时的公告、发行版本没有做分支对齐以及小版本发布内容不透明,这让 SA 同学在运维和打补丁的过程中遭遇了不少麻烦。最后,非常期待社区的向量化引擎、新版查询优化器、Lateral View 等几大新特性成熟稳定,让网易互娱的业务用户体验更上一个台阶。
Apache Doris 开源社区链接参考
Apache Doris 官方网站:
http://doris.apache.org
Apache Doris Github :
https://github.com/apache/incubator-doris
Apache Doris 开发者邮件组:
本文分享自微信公众号 - ApacheDoris(gh_80d448709a68)。
如有侵权,请联系 [email protected] 删除。
本文参与“ OSC源创计划 ”,欢迎正在阅读的你也加入,一起分享。