云计算复习
云计算三道大题
分值分别是40+40+20分
有什么疑问尽管评论区提问.若有错误,请谅解并且指出,会及时纠正.
一、Hbase与JAVA结合应用
前置知识:
JSON是表示数据的一种格式的文件,XML是在联网状态下的‘JSON’,也可以传递数据.JSON通过read操作,可以进行数据库的建立.
举例:emplouees表
{
"employees": {
{ "firstName":"Bill" , "lastName":"Gates" },
{ "firstName":"George" , "lastName":"Bush" },
{ "firstName":"Thomas" , "lastName":"Carter" }
}
}
/*可能添加base 和 extra 额外信息的补充,区别不大
extra主要是多出了与base不同的属性,与其他对象也可以不同
所有对象的base下必须一致*/
————————————————
考题:
A.hbase-shell的命令
1. 建表操作
举例:建立student表,列簇名为info
hbase(main):002:0> create 'student','info'
2.插入数据操作
插入 表名 行键 列簇:列 值
hbase(main):003:0> put 'student','1001','info:sex','male'
hbase(main):004:0> put 'student','1001','info:age','18'
hbase(main):005:0> put 'student','1002','info:name','Janna'
hbase(main):006:0> put 'student','1002','info:sex','female'
hbase(main):007:0> put 'student','1002','info:age','20'
3.浏览操作
get 表名 行键
hbase(main):014:0> get 'student','1001'
hbase(main):015:0> get 'student','1001','info:name'
补充A.:coloum:列族+列名
cell:由{row key, column( = + ), version} 唯一确定的单元。
HBase中通过row和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
B.为什么添加时间戳?(考)
TimeStamp就像是一条时间轴,用户每次对表进行增删改查操作,都会留下相应的时间戳,而HBase向用户呈现的永远是时间轴上最新时间所对应的操作。
因此在进行delete、put等操作时可以带上TimeStamp,获得更确切的结果,但版本信息中的操作还是会保留.
4.HBase与关系数据库的插入和删除分别有什么不同?
插入操作:
详细版本:SQL 针对结构化查询语句 是结构化数据,hadoop针对的是非结构化数据,文本形式
关系数据库是 有一定格式,而存放文本、图片和xml文件 则应该用键值对的方式。HBase只有很简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系,而传统数据库通常有各式各样的函数和连接操作。 用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过AsyncProcess异步批量提交。HBase默认设置autoflush=true,表示put请求直接会提交给服务器进行处理;用户可以设置autoflush=false,这样的话put请求会首先放到本地buffer,等到本地buffer大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会提交。很显然,后者采用group commit机制提交请求,可以极大地提升写入性能,但是因为没有保护机制,如果客户端崩溃的话会导致提交的请求丢失。
傻瓜版本:hbase一次只能插入一个表一个列族某单元格的数据,插入时自动加时间戳;
关系数据库按行插入,执行insert时高度结构化,严格按照结构插入。
删除操作:
对于Hbase,和删除列,跟传统关系数据库里面的删除记录类似.
传统关系型数据库的修改与删除,可以快速通过主键、列或索引直接锁定到某一行或某些行,进行物理删除。
而对于Hbase来说,受到hdfs文件系统的局限(hdfs文件系统不能修改,添加也很不方便),进行CRUD的操作就会变得相对复杂。
HBase的删除则是通过标记来实现,如果要删除某行记录,Hbase会添加一个带有删除标记的行,通过这个删除标记来辨认该行建的数据是否删除。
B.Hbase API编程
1.建立连接(即获取 Configuration 对象)
public static Configuration conf;
static{
//使用 HBaseConfiguration 的单例方法实例化
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "192.166.9.102");
conf.set("hbase.zookeeper.property.clientPort", "2181");
}
2.创建表
public static void createTable(String tableName, String...
columnFamily) throws
MasterNotRunningException, ZooKeeperConnectionException,
IOException{
HBaseAdmin admin = new HBaseAdmin(conf);
//判断表是否存在
if(isTableExist(tableName)){
System.out.println("表" + tableName + "已存在");
//System.exit(0);
}else{
//创建表属性对象,表名需要转字节
HTableDescriptor descriptor = new
HTableDescriptor(TableName.valueOf(tableName));
//创建多个列族
for(String cf : columnFamily){
descriptor.addFamily(new HColumnDescriptor(cf));
}
//根据对表的配置,创建表
admin.createTable(descriptor);
System.out.println("表" + tableName + "创建成功!");
} }
3.删除表
public static void dropTable(String tableName) throws
MasterNotRunningException,
ZooKeeperConnectionException, IOException{
HBaseAdmin admin = new HBaseAdmin(conf);
if(isTableExist(tableName)){
admin.disableTable(tableName);
admin.deleteTable(tableName);
System.out.println("表" + tableName + "删除成功!");
}else{
System.out.println("表" + tableName + "不存在!");
} }
4.插入操作
public static void addRowData(String tableName, String rowKey,
String columnFamily, String
column, String value) throws IOException{
//创建 HTable 对象
HTable hTable = new HTable(conf, tableName);
//向表中插入数据
Put put = new Put(Bytes.toBytes(rowKey));
//向 Put 对象中组装数据
put.add(Bytes.toBytes(columnFamily), Bytes.toBytes(column),
Bytes.toBytes(value));
hTable.put(put);
hTable.close();
System.out.println("插入数据成功");
}
5浏览操作
浏览全部
#获取所有数据
public static void getAllRows(String tableName) throws IOException{
HTable hTable = new HTable(conf, tableName);
//得到用于扫描 region 的对象
Scan scan = new Scan();
//使用 HTable 得到 resultcanner 实现类的对象
ResultScanner resultScanner = hTable.getScanner(scan);
for(Result result : resultScanner){
Cell[] cells = result.rawCells();
for(Cell cell : cells){
//得到 rowkey
System.out.println(" 行 键 :" +
Bytes.toString(CellUtil.cloneRow(cell)));
//得到列族
System.out.println(" 列 族 " +
Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println(" 列 :" +
Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println(" 值 :" +
Bytes.toString(CellUtil.cloneValue(cell)));
} } }
浏览某一行数据
public static void getRow(String tableName, String rowKey) throws
IOException{
HTable table = new HTable(conf, tableName);
Get get = new Get(Bytes.toBytes(rowKey));
//get.setMaxVersions();显示所有版本
//get.setTimeStamp();显示指定时间戳的版本
Result result = table.get(get);
for(Cell cell : result.rawCells()){
System.out.println(" 行 键 :" +Bytes.toString(result.getRow()));
System.out.println(" 列 族 " +
Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println(" 列 :" +
Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println(" 值 :" +
Bytes.toString(CellUtil.cloneValue(cell)));
System.out.println("时间戳:" + cell.getTimestamp());
} }
浏览某一行指定“列族:列”的数据
public static void getRowQualifier(String tableName, String rowKey,
String family, String
qualifier) throws IOException{
HTable table = new HTable(conf, tableName);
Get get = new Get(Bytes.toBytes(rowKey));
get.addColumn(Bytes.toBytes(family),
Bytes.toBytes(qualifier));
Result result = table.get(get);
for(Cell cell : result.rawCells()){
System.out.println(" 行 键 :" +
Bytes.toString(result.getRow()));
System.out.println(" 列 族 " +
Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println(" 列 :" +
Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println(" 值 :" +
Bytes.toString(CellUtil.cloneValue(cell)));
} }
二、SPARK SHELL和镜像的应用
A.用Dockerfile制作CentOS+jdk+tomcat镜像
#拉取镜像(拉取空白版本的Centos)
#name代指镜像名
docker pull Centos
#构建镜像
#利用Dockerfile,docker build自动化构建
当搜索不到需要的镜像时,可以使用 docker build 命令构建镜像,以 cnetos:latest 为基础镜像,添加自定义脚本,并在容器启动时执行脚本test.sh并且输出题目要求的信息
vim test.sh
echo"i am Rookie."
vim DockerFile
#local 文件路径 视题目要求而定
FROM Centos:latest
MAINTAINER QQ:738441412#维护者信息
#ADD jdk-8u251-linux-x64.tar.gz /usr/local/java#拉取JDK
#ENV JAVA_HOME /usr/local/java/jdk1.8.0_251#配置环境变量
#ENV CLASSPATH $JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#ENV PATH $PATH:$JAVA_HOME/bin
RUN MKDIR localhost
ADD ./test.sh /test.sh
RUN chmod +x /test.sh
CMD ["/bin/sh", "-c", "/test.sh"]#不执行test.sh直接只有第一个可执行文件的参数即可
最后,在终端执行
Docker build -t 镜像名字 .
#最后是一个空格加一个“. ”不要漏掉QAQ
TOMCAT的拉取可以通过ADD远程网络的方式实现.
ADD apache-tomcat-9.0.22.tar.gz /usr/local/
#这里是本地的文件直接拉取,安装样例项目部署于制定的文件下.
补充:DockFIle镜像指令
1.复制的两种方式
ADD :可以远程拉取,识别出来压缩包后,可以自动解压.
查看是否地址为URL地址
COPY:只适用于本地的复制
COPY <源路径> … <目标路径>
用于与
RUN tar -zxvf 本地压缩包 -C 目的位置
命令组合.
2.RUN 运行linux下命令 执行命令
3.FROM 以xxx为基础镜像
4.CMD 容器启动命令
CMD 指令有三种格式:
1.shell 格式: CMD <命令>
2.exec 格式:CMD [“可执行文件”,“参数1”,“参数2”, …]//是双引号哟
3.参数列表格式:CMD [“参数1”,“参数2”,…] , 这个时候CMD作为 ENTRYPOINT的参数。
B.通过k8s部署自己的应用
kubectl create deploy 应用name --image=镜像name
#暴露外部接口,以便外界访问
kubectl expose deployment 应用name --port=80 --type=NodePort
#查询访问外部接口
kubectl get services
C.SPARK SHELL
前置知识:
Spark SQL可以提供DataFrame API,可以对内部和外部各种数据源执行各种关系操作;可以访问的数据源包括Hive、Parquet['pɑːkeɪ]、JSON和JDBC等。采用了DataFrame数据模型(既带有Schema信息的RDD),支持用户在Spark SQL中执行SQL语句,实现对结构化数据的处理。
Spark SQL架构:
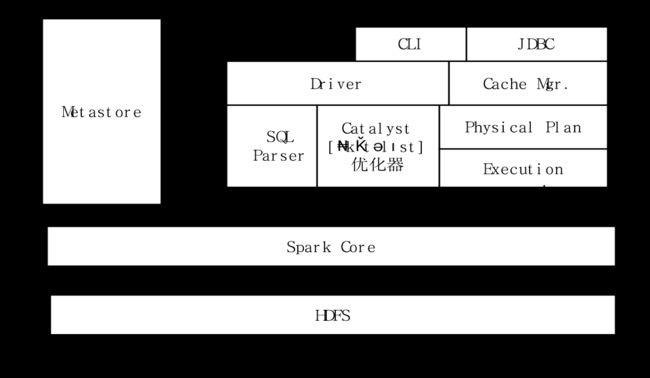
其中HDFS建立在Linux系统上
1.DataFrame(可能考察)
Spark SQL所使用的数据抽象并非RDD,而是DataFrame。DataFrame让Spark具备了处理大规模结构化数据的能力,它不仅比原有的RDD转化方式更加简单易用,而且获得了更高的系统性能。借助DataFrame,Spark能够轻松实现从MySQL到DataFrame的转化,并支持SQL查询。
RDD是分布式的Java对象集合,隐藏了对象内部结构。DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息,给出了对象内部结构,相当于关系数据库的一张表。

2.外部数据源的创建
/*import org.apache.spark.sql.SparkSession
val spark=SparkSession.builder().getOrCreate()
import spark.implicits._
应该不会考察*/
val df =
spark.read.json("file:///usr/local/spark/examples/src/main/resources/people.json")
//或者如下形式(黑板上给的)
val df =spark.read.format("json").load("file:///usr/local/spark/examples/src/main/resources/people.json")
//load后面添加文件位置即可
3.JSON文件如下
{"name":"zhang","height":170} {"name":"liu", "sex":"male"}
则要求转化成逻辑结构
| name | height | sex |
|---|---|---|
| ‘zhang’ | ‘170’ | |
| ‘liu’ | ‘male’ |
4.相关操作(与前面df对象联动)
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
df.select("name", "sex").
write.format("csv").save("file:///usr/local/spark/mycode/sql/newpeople.csv")
//列出所有name sex的信息 以csv格式写入文件位置
df.select("name")).show()
//输出所有人名信息
//打印模式信息:
df.printSchema()
//选择多列信息:
df.select(df("name"),df("height")+1).show()
//条件筛选信息:
df.filter(df("height") > 20 ).show()
//分组聚合信息:
df.groupBy("height").count().show()
利用sql语句来调用操作
scala>df.createTempView("table1")//创建新表
scala> spark.sql("select * from table1 where height >170 limit 10") //以10行限制查询表,应该是考察单表的操作,sql语句不会太复杂
三、计算资源管理
前置知识:mesos是分布式计算资源管理框架,并不负责计算的部分
yarn部分包括NodeManager和ResourceManager.
Mesos填写主机是slave还是master(spark同mesos)
A.Mesos
| 主机名 | IP地址 | Mesos | Yarn | Spark |
|---|---|---|---|---|
B.OpenStack
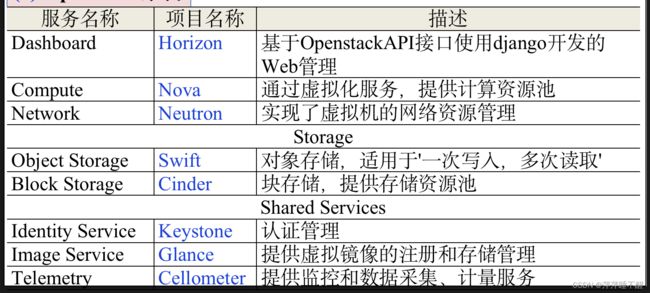

不知道考什么,背就完事了好么
配置文件
[general]
CONFIG_SSH_KEY=/localhost/.ssh/id_rsa.pub
CONFIG_DEFAULT_PASSWORD=123456
CONFIG_SERVICE_WORKERS=%{::processorcount}
CONFIG_MARIADB_INSTALL=y
**CONFIG_GLANCE_INSTALL=y**
**CONFIG_CINDER_INSTALL=y**
CONFIG_MANILA_INSTALL=n
**CONFIG_NOVA_INSTALL=y**
**CONFIG_NEUTRON_INSTALL=y**
**CONFIG_HORIZON_INSTALL=y**
**CONFIG_SWIFT_INSTALL=y**
CONFIG_CEILOMETER_INSTALL=y
**CONFIG_AODH_INSTALL=y**
CONFIG_GNOCCHI_INSTALL=y
CONFIG_SAHARA_INSTALL=n
CONFIG_HEAT_INSTALL=n
CONFIG_TROVE_INSTALL=n
CONFIG_IRONIC_INSTALL=n
CONFIG_CLIENT_INSTALL=y
CONFIG_NTP_SERVERS=
CONFIG_NAGIOS_INSTALL=y
EXCLUDE_SERVERS=
CONFIG_DEBUG_MODE=n
CONFIG_CONTROLLER_HOST=192.168.0.91
CONFIG_COMPUTE_HOSTS=192.168.0.91
CONFIG_NETWORK_HOSTS=192.168.0.91
加星号的是ppt上标红的,可能是让重点背吧
可是我真的背不完全部,呜呜呜
噢?写完了?那没事了.
完结撒花吧~
有错误请及时评论啊,谢谢家人