终于有人把数据湖讲明白了
作者:彭锋 宋文欣 孙浩峰
来源:数仓宝贝库

作为全局数据汇总及处理的核心功能,数据湖在数据中台建设中必不可少。那么它与数据仓库、数据中台是什么关系?
图10-1显示了一个典型的从数据采集到数据湖、数据仓库及数据集市,最后为数据应用提供服务的流程。可以看到,除了为数据仓库提供原始数据之外,数据湖也可以直接为上层的数据应用提供服务。
与数据湖不同,数据仓库是针对OLAP需求建设的数据库,可以分析来自交易系统或不同业务部门的结构化数据。数据仓库中的数据由原始数据经过清理、填充和转换后按照核心业务逻辑组织生成。数据仓库一般必须预先定义好数据库Schema,重点是实现更快的SQL驱动的深度报告和分析。
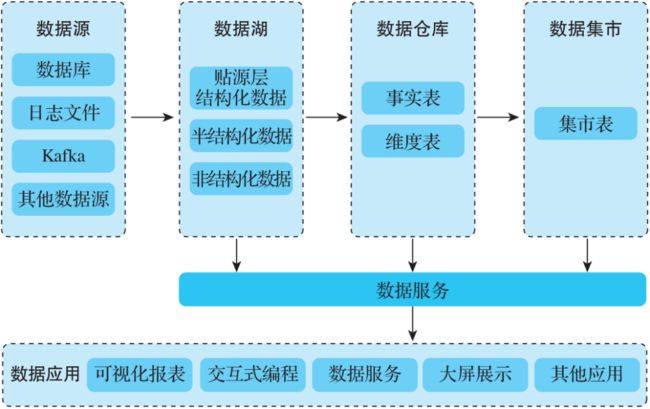
▲图10-1 从数据采集到提供数据服务的流程
01 数据湖的起源与作用
数据湖的出现主要是为了解决存储全域原始数据的问题。在捕获来自业务应用程序、移动应用程序、IoT设备和互联网的结构化和非结构化数据时,实际上并没有预先定义好数据结构,这意味着可以先存储数据而无须进行精心设计,也无须明确要进行什么分析,由数据科学家和数据工程师在后续工作中探索和尝试。
这个改动极大推动了大数据的发展,早期大数据系统的一大吸引力是能够存储大量日志数据供后期探索,很多大数据应用就是在大数据系统将数据采集上来之后才出现的。
为什么一定要单独建立数据湖呢?要回答这个问题,我们先来了解数据湖的一个重要组成部分——ODS(Operating Data Store,运营数据存储)。
在20世纪90年代数据仓库刚出来的时候,就已经有ODS了。可以说ODS是数据湖的先行者,因为ODS和数据湖有两个共同的重要特征:不加转换的原始数据,可以进行不预先设置的分析。
ODS一般用来存储业务运营数据,也就是OLTP(联机事务处理)数据的快照和历史,而数据仓库一般用来存储分析数据,对应OLAP(联机分析处理)需求。表10-1列出了OLTP和OLAP的一些区别。
▼表10-1 OLTP和OLAP的区别
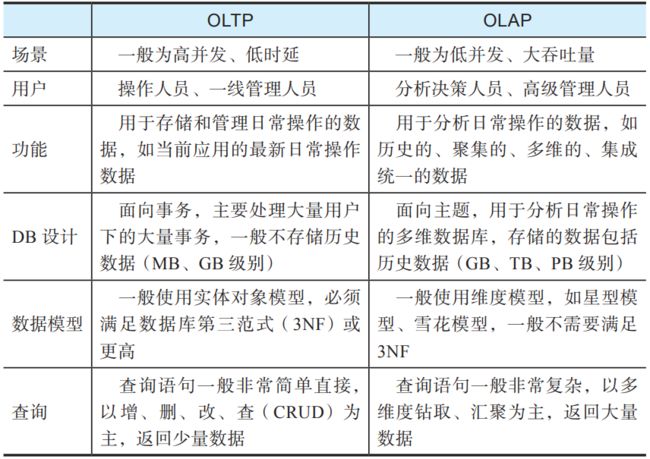
绝大多数情况下,业务数据库的SQL库表的结构与数据仓库的结构是不一样的:业务数据库是为OLTP设计的,是系统实时状态的数据;而数据仓库的数据是为OLAP的需求建设的,是为了深度的多维度分析。这个差异造成基于数据仓库的数据分析受到以下限制:
数据仓库的架构设计是事先定好的,很难做到全面覆盖,因此基于数据仓库的分析是受到事先定义的分析目标及数据库Schema限制的;
从OLTP的实时状态到OLAP的分析数据的转换中会有不少信息损失,例如某个账户在某个具体时间点的余额,在OLTP系统里一般只存储最新的值,在OLAP系统里只会存储对账户操作的交易,一般不会专门存储历史余额,这就使得进行基于历史余额的分析非常困难。
因此,在建立数据仓库的时候,我们必须先将OLTP数据导入ODS,然后在ODS上进行ETL操作,生成便于分析的数据,最后将其导入数据仓库。这也是为什么ODS有时也被称为数据准备区(staging area)。
随着Hadoop的逐渐普及,大家发现数据仓库底层的技术(关系型数据库)无法处理一些非结构化数据,最典型的就是服务器日志包含的数据。除了这些分析上的功能缺陷之外,传统数据仓库底层使用的关系型数据库在处理能力上有很大局限,这也是数据湖,直至整个大数据生态出现的一个主要原因。
在Hadoop出现之前,就有Teradata和Vertica等公司试图使用MPP(Massively Parallel Processing,大规模并行处理)数据库技术来解决数据仓库的性能问题。在Hadoop出现之后,Hive成为一个比较廉价的数据仓库实现方式,也出现了Presto、Impala这些SQL-on-Hadoop的开源MPP系统。
从2010年开始,业界逐渐将ODS、采集的日志以及其他存放在Hadoop上的非结构或半结构化数据统称为数据湖。有时,数据湖中直接存储源数据副本的部分(包括ODS和日志存储)被称为贴源数据层,意思是原始数据的最直接副本。
从根本上来讲,数据湖的最主要目标是尽可能保持业务的可还原度。例如,在处理业务交易的时候,数据湖不仅会把OLTP业务数据库的交易记录采集到数据湖中的ODS,也会把产生这笔交易的相关服务器日志采集到数据湖的HDFS文件系统中,有时还会把发回给客户的交易凭证作为文档数据存放。
这样,在分析与这笔交易相关的信息时,系统能够知道这笔交易产生的渠道(从服务器分析出来的访问路径),给客户的凭证是否有不合理的数据格式(因为凭证的格式很多时候是可以动态变化的)。

02 数据湖建设的4个目标
数据湖的建设方式有很多种,有的企业使用以Hadoop为核心的数据湖实现,有的企业以MPP为核心加上一些对象存储来实现。虽然建设方式不同,但是它们建设数据湖的目标是一致的,主要有以下4点。
高效采集和存储尽可能多的数据。将尽可能多的有用数据存放在数据湖中,为后续的数据分析和业务迭代做准备。一般来说,这里的“有用数据”就是指能够提高业务还原度的数据。
对数据仓库的支持。数据湖可以看作数据仓库的主要数据来源。业务用户需要高性能的数据湖来对PB级数据运行复杂的SQL查询,以返回复杂的分析输出。
数据探索、发现和共享。允许高效、自由、基于数据湖的数据探索、发现和共享。在很多情况下,数据工程师和数据分析师需要运行SQL查询来分析海量数据湖数据。诸如Hive、Presto、Impala之类的工具使用数据目录来构建友好的SQL逻辑架构,以查询存储在选定格式文件中的基础数据。这允许直接在数据文件中查询结构化和非结构化数据。
机器学习。数据科学家通常需要对庞大的数据集运行机器学习算法以进行预测。数据湖提供对企业范围数据的访问,以便于用户通过探索和挖掘数据来获取业务洞见。
基于这几个目标,数据湖必须支持以下特性。
数据源的全面性:数据湖应该能够从任何来源高速、高效地收集数据,帮助执行完整而深入的数据分析。
数据可访问性:以安全授权的方式支持组织/部门范围内的数据访问,包括数据专业人员和企业等的访问,而不受IT部门的束缚。
数据及时性和正确性:数据很重要,但前提是及时接收正确的数据。所有用户都有一个有效的时间窗口,在此期间正确的信息会影响他们的决策。
工具的多样性:借助组织范围的数据,数据湖应使用户能够使用所需的工具集构建其报告和模型。

03 数据湖数据的采集和存储
数据采集系统负责将原始数据从源头采集到数据湖中。数据湖中主要采集如下数据。
1. ODS
存储来自各业务系统(生产系统)的原始数据,一般以定时快照的方式从生产数据库中采集,或者采用变化数据捕获(Change Data Capture,CDC)的方式从数据库日志中采集。
后者稍微复杂一些,但是可以减少数据库服务器的负载,达到更好的实时性。在从生产数据库中采集的时候,建议设置主从集群并从从库中采集,以避免造成对生产数据库的性能影响。
2. 服务器日志
系统中各个服务器产生的各种事件日志。典型例子是互联网服务器的日志,其中包含页面请求的历史记录,如客户端IP地址、请求日期/ 时间、请求的网页、HTTP代码、提供的字节数、用户代理、引用地址等。
这些数据可能都在一个文件中,也可能分隔成不同的日志,如访问日志、错误日志、引荐者日志等。我们通常会将各个业务应用的日志不加改动地采集到数据湖中。
3. 动态数据
有些动态产生的数据不在业务系统中,例如为客户动态产生的推荐产品、客户行为的埋点数据等。这些数据有时在服务器日志中,但更多的时候要以独立的数据表或Web Service的方式进行采集。
埋点是数据采集领域(尤其是用户行为数据采集领域)的术语,指的是对特定用户行为或事件进行捕获、处理和发送的相关技术及其实施过程,比如用户点击某个图标的次数、观看某个视频的时长等。
埋点是用户行为分析中非常重要的环节,决定了数据的广度、深度、质量,能影响后续所有的环节。因此,这部分埋点数据应该采集到数据湖中。
4. 第三方数据
从第三方获得的数据,例如用户的征信数据、广告投放的用户行为数据、应用商店的下载数据等。
采集这些原始数据的常见方式如下。
传统数据库数据采集:数据库采集是通过Sqoop或DataX等采集工具,将数据库中的数据上传到Hadoop的分布式文件系统中,并创建对应的Hive表的过程。数据库采集分为全量采集和增量采集,全量采集是一次性将某个源表中的数据全部采集过来,增量采集是定时从源表中采集新数据。
Kafka实时数据采集:Web服务的数据常常会写入Kafka,通过Kafka快速高效地传输到Hadoop中。由Confluent开源的Kafka Connect架构能很方便地支持将Kafka中的数据传输到Hive表中。
日志文件采集:对于日志文件,通常会采用Flume或Logstash来采集。
爬虫程序采集:很多网页数据需要编写爬虫程序模拟登录并进行页面分析来获取。
Web Service数据采集:有的数据提供商会提供基于HTTP的数据接口,用户需要编写程序来访问这些接口以持续获取数据。
数据湖需要支持海量异构数据的存储。下面是一些常见的存储系统及其适用的数据类型。
HDFS:一般用来存储日志数据和作为通用文件系统。
Hive:一般用来存储ODS和导入的关系型数据。
键-值存储(Key-value Store):例如Cassandra、HBase、ClickHouse等,适合对性能和可扩展性有要求的加载和查询场景,如物联网、用户推荐和个性化引擎等。
文档数据库(Document Store):例如MongoDB、Couchbase等,适合对数据存储有扩展性要求的场景,如处理游戏账号、票务及实时天气警报等。
图数据库(Graph Store):例如Neo4j、JanusGraph等,用于在处理大型数据集时建立数据关系并提供快速查询,如进行相关商品的推荐和促销,建立社交图谱以增强内容个性化等。
对象存储(Object Store):例如Ceph、Amazon S3等,适合更新变动较少的对象文件数据、没有目录结构的文件和不能直接打开或修改的文件,如图片存储、视频存储等。

一般来讲,数据湖的存储应该支持以下特性。
1. 可扩展性
企业数据湖充当整个组织或部门数据的集中数据存储,它必须能够弹性扩展。注意,虽然云原生架构比较容易支持弹性扩展,但是数据中心都会有空间和电力限制,准备建设大规模数据湖的企业需要考虑多数据中心或混合云的架构,否则就会陷入几年就要“搬家”的窘境。
2. 数据高可用性
数据的及时性和持续可用性是辅助决策制定的关键,因此必须使用HDFS、Ceph、GlusterFS等支持多备份、分布式高可用的架构。
3. 高效的存储效率
数据湖的数据量是以PB计的,而且因为需要多备份(3份或更多),其存储效率就非常重要。例如,使用LZO压缩存储HDFS文件可以达到1∶6甚至1∶7的压缩比例,而且可以通过系统支持实现透明访问,也就是说,程序可以直接使用数据而无须先展开到临时空间。
另外,列式存储也是一种常用的利于压缩的存储方式。存储效率越高,意味着需要的服务器越少,使用的电量越少,扩容的时间间隔越长,因此存储效率对数据湖的运营非常重要。
4. 数据持久性
数据一旦存储,就不能因为磁盘、设备、灾难或任何其他因素而丢失。除了使用分布式架构,一般还需要考虑多数据中心和混合云架构支持的异地备份。
5. 安全性
对于本地和基于云的企业数据湖来说,安全都是至关重要的,应将其放在首位。
例如,数据必须经过加密,必须不可变(在任何需要的地方),并且必须符合行业标准;数据系统的访问必须支持端到端的授权和鉴权集成等。应该从刚开始建设数据湖时就进行安全性的设计,并将其纳入基本的体系结构和设计中。只有在企业整体安全基础架构和控件的框架内部署和管理,数据湖的安全性才有保障。
6. 治理和审计
要能够应用治理规则及数据不变性,识别用户隐私数据以及提供完整的数据使用审计日志的能力,这对于满足法规和法定要求至关重要。
7. 可以存储任何内容
数据湖在设计之初,有一个主要考虑的因素:存储任何格式(结构化和非结构化)的数据并提供快速检索。当然,这里的“快速”并不是说要像面向用户的系统一样提供实时响应,在数据湖上运行的应用对交互的要求会低一些。即便如此,Presto、Impala等SQL-on-Hadoop的解决方案正在逐步提高数据湖的交互体验。
8. 可以支持不同存储文件的大小和格式
在很多场景中,系统需要存储很多小文件,这些文件的尺寸远小于Hadoop文件系统(HDFS)的默认块大小128MB。在基于Hadoop的框架中,每个文件在集群的名称节点的内存中均表示为一个对象,每个对象通常占用150B。这意味着大量文件将消耗大量内存。
因此,大多数基于Hadoop的框架无法有效使用小文件。另一个重要方面是文件的格式,例如使用列存储(ORC和Parquet)可以加大文件的压缩比例,在读取时仅解压缩和处理当前查询所需的值,这样可以大大减少磁盘I/O和查询时间。

04 数据湖中的数据治理
很多人认为数据湖中存储的是原始数据,不需要治理,这其实是个误区。确切地说,数据湖存储的是未经转换的数据,任何需要支持分析的数据都是需要治理的。数据治理是指对企业中数据的可用性、完整性和安全性的全面管理,具体内容主要取决于企业的业务策略和技术实践。
比如,我们可以要求写入数据湖的ODS数据经过Schema的检查,确保业务系统Schema的改变不会未经协调就进入数据湖,造成现有数据湖应用的失效。
再比如合规的要求,数据湖负责全域数据采集,其中往往包括消费者的个人可识别信息。这些敏感数据必须经过合规处理,以确保系统遵守隐私法律和法规。因此,从最开始就应将数据治理纳入数据湖的设计中,至少应采用最低的治理标准。
数据湖中的数据治理主要涵盖以下领域。
1. 数据目录
由于数据湖中存储的数据量非常大,因此很难跟踪有哪些数据可用,而且数据容易被淹没。解决方案是维护数据目录。数据目录是元数据的集合,结合了数据管理和搜索工具,可帮助分析师和其他用户查找数据。数据目录充当可用数据的清单,并提供信息以评估适用数据的预期用途。
最有效的方法是维护中央数据目录,并在各种处理框架(如Hadoop、Spark以及其他可用工具)中使用,这样可以应用简单的数据治理规则来确保元数据的完整性。
2. 数据质量
数据质量系统应该确保数据的完整性、准确性、一致性以及标准化,否则基于数据得出的结果是不可靠的,所谓的“垃圾进,垃圾出”(Garbage In, Garbage Out)就是这个意思。现在并没有一个通用的数据质量管理系统适用于数据湖,但是类似于Delta Lake这样的项目已经在探索如何解决这些问题。
3. 数据合规
根据所运营的业务领域,数据湖必须满足一些合规要求,例如GDPR(《通用数据保护条例》)、HIPAA(《健康保险便利和责任法案》)和ISO等标准和规范。对于很多企业而言,数据合规是很重要的工作,数据合规一旦出问题,可能导致巨额罚款或者数据泄露,损害企业的信誉。
关于作者:彭锋,智领云科技联合创始人兼CEO。武汉大学计算机系本科及硕士,美国马里兰大学计算机专业博士,主要研究方向是流式半结构化数据的高性能查询引擎,在数据库顶级会议和期刊SIGMOD、ICDE、TODS上发表多篇开创性论文。2011年加入Twitter,任大数据平台主任工程师、公司架构师委员会大数据负责人,负责公司大数据平台及流水线的建设和管理。
宋文欣,智领云科技联合创始人兼CTO。武汉大学计算机系本科及硕士,美国纽约州立大学石溪分校计算机专业博士。曾先后就职于Ask.com和EA(电子艺界)。2016年回国联合创立智领云科技有限公司,组建智领云技术团队,开发了BDOS大数据平台操作系统。
孙浩峰,智领云科技市场总监。前CSDN内容运营副总编,关注云计算、大数据、人工智能、区块链等技术领域,对云计算、网络技术、网络存储有深刻认识。拥有丰富的媒体从业经验和专业的网络安全技术功底,具有超过15年的企业级IT市场传播、推广、宣传和写作经验,撰写过多篇在业界具有一定影响力的文章。
本文摘编自《云原生数据中台:架构、方法论与实践》,经出版方授权发布。

延伸阅读《云原生数据中台:架构、方法论与实践》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:前Twitter大数据平台主任工程师撰写,融合硅谷与国内经验,全面讲解云原生数据中台架构、选型、方法论、实施路径,国内外专家联袂推荐。
![]()
划重点
干货直达
什么是物联网?有哪些应用?终于有人讲明白了
终于有人把云原生讲明白了
为什么你一直在写bug?原因找到了
吐血整理:人工智能、机器学习领域13个常见概念
更多精彩
在公众号对话框输入以下关键词
查看更多优质内容!
读书 | 书单 | 干货 | 讲明白 | 神操作 | 手把手
大数据 | 云计算 | 数据库 | Python | 爬虫 | 可视化
AI | 人工智能 | 机器学习 | 深度学习 | NLP
5G | 中台 | 用户画像 | 数学 | 算法 | 数字孪生
据统计,99%的大咖都关注了这个公众号