李宏毅机器学习课程笔记
李宏毅机器学习课程笔记,持续更新~
- 1. Convolutional Neural Network
- 2. Recurrent Neural Network
- 3. Graph Neural Network
- 4. Generative Adversarial Network
- 5. Auto-encoder
- 6. Transformer
- 7. ELMO, BERT, GPT
- 1. Transfer Learning
- 2. Anomaly Detection
-
- 训练数据带有标签
- 训练数据没有标签,混杂部分异常数据
- 3. Attack Machine Learning Models
-
- 攻击部分
- 防御部分
- 4. Explainable Machine Learning
-
- Local Explanation
- Global Explanation
- 5. Life Long Learning
-
- 如何保留知识?
- 如何迁移知识?
- 如何扩展模型?
- Curriculum Learning
- 6. Meta Learning
- 7. Network Compression
-
- Network Pruning
- Knowledge Distillation
- Parameter Quantization
- Architecture Design
- Dynamic Computation
- 8. Reinforcement Learning
1. Convolutional Neural Network
2. Recurrent Neural Network
3. Graph Neural Network
4. Generative Adversarial Network
5. Auto-encoder
6. Transformer
7. ELMO, BERT, GPT
1. Transfer Learning
2. Anomaly Detection
异常检测网络:机器是不是知道自己在某种情况下并不知道。
检测与训练数据不同的数据。
应用场景有:
- Fraud Detection,检测是否为正常刷卡行为;
- Network Intrusion Detection,检测是否为正常服务器请求;
- Cancer Detection,检测是否为正常细胞。
为什么不使用二分类?
- 无法穷举所有异常情况;
- 异常数据难以获取。

训练数据可以分为:
- 训练数据有标签;
- 训练数据没有标签,但是都为正常数据;
- 训练数据没有标签,但是混杂了部分异常数据。
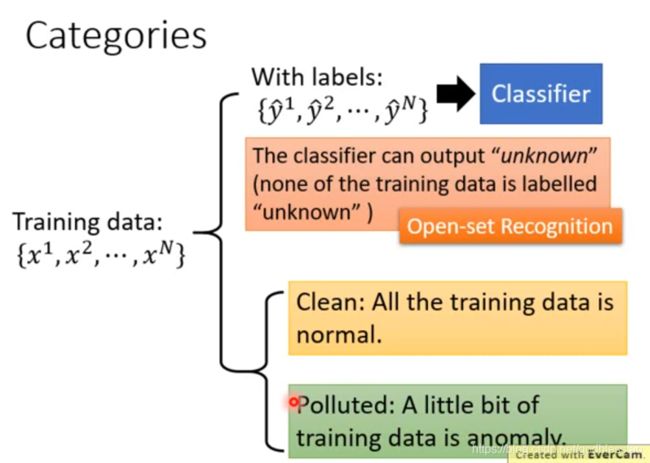
训练数据带有标签
对于网络输出层的置信度,选择最高的一个,与人为设置的阈值进行比较,如果最高置信度大于阈值,则为正常;反之,则为异常。
论文:Learning Confidence for Out-of-Distribution Detection in Neural Networks, arXiv, 2018。

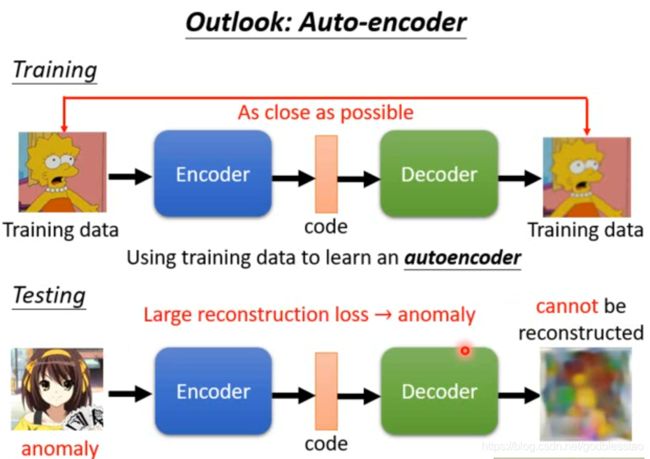
训练数据没有标签,混杂部分异常数据
利用概率模型,预测输出,比较输出概率与阈值,根据输出做出判断。

使用自编码器,如果不能正常还原输入,则为异常数据。
其他使用SVM和随机森林的方法。

3. Attack Machine Learning Models
对抗攻击网络:机器会不会有错觉,被欺骗?
攻击部分
可以分为对white box(知道要攻击模型的参数)的攻击,black box(不知道要攻击模型的参数)的攻击。也可以分为针对单个样本的攻击(每个样本需要不同的noise),针对所有样本的攻击。


方法一:FGSM
这类型方法需要知道模型的参数。white box。

方法二:black box attach
利用训练数据,自己训练一个代理模型,然后找到可以攻击代理模型的方法,再用来攻击黑箱模型。
方法三:统一攻击

方法四:真实世界的攻击

防御部分

方法一:被动防御
通过平滑降低noise的影响。



方法二:主动防御

4. Explainable Machine Learning
可解释性网络:机器能不能说出为什么知道?
Local Explanation
Local Explanation就是解释模型输出的依据是什么。可以知道模型学到了哪些知识。
现有方法的原理,通过观察图像的哪部分(一个像素,一个分割块,一个单词)是重要的,确定模型的决策依据。
方法一:将一个纯色块在图像上进行移动,观察其对决策结果的影响。参考论文Visualizing and understanding convolutional networks(ECCV 2014)。缺点是,需要选择纯色块的大小,颜色。

方法二:通过观察单个像素扰动对决策结果的影响,绘制saliency map,从saliency map可以观察到模型的决策依据。参考论文Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps(CVPR 2013)。缺点,本质是利用输出对输入的梯度进行判断的,但是梯度饱和的时候,梯度也会是0。解决梯度饱和的问题,参考论文Integrated gradient和DeepLIFT。
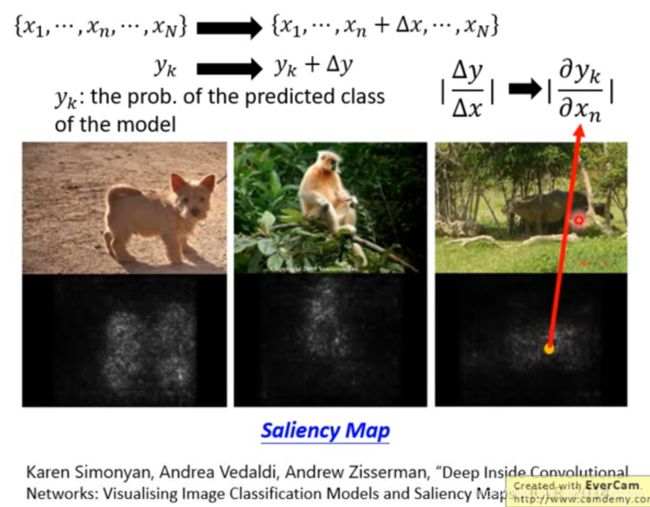
其他参考论文:
Grad-CAM
SmoothGrad
Layer-wise Relevance Propagation
Guided Backpropagation
方法三:使用可解释的模型,去模仿不可解释模型。缺点,可解释的模型的表达能力,一般比不可解释模型的表达能力差。解决方法,使用可解释模型模仿不可解释模型的局部,同时对于局部的定义会影响解释的结果。参考文献Local Interpretable Model-Agnostic Explanations(LIME)。

方法四:也可以使用决策树作为简单的模型,去解释复杂模型。但是,用于解释的决策树不能太复杂,越简单越好。使用tree regularization的方法,在训练神经网络时,将对应的决策树平均复杂程度加入到损失函数中。其中,需要训练一个模型,求取原模型转化为决策树的平均复杂程度。


Global Explanation
Global Explanation就是解释模型理想的输入是什么。
方法一:Activation Maximization,找一个可以使输出最大化的输入。参考视频Deep Neural Networks are Easily Fooled。缺点,通常需要添加很多regularization和hyperparameter tuning,才能获得很好的效果。

方法二:与方法一相同,但是使用Generator去约束理想输入。Generator使用GAN,VAE等方法训练得到。

5. Life Long Learning
又称为continuous learning,never ending learning,incremental learning。终身学习需要解决问题,后续任务的学习会使历史任务的知识被遗忘:
- 知识保留(knowledge retention),但不能知识固化(not intransigence);
- 知识迁移(knowledge transfer)
- 模型扩展(model expansion),参数高效。
Muti-task learning,多任务学习中,后续任务的学习会使历史任务的知识被遗忘。如果使用所有任务的数据,同时训练,一方面需要存储所有的历史数据,另一方面,越来越多的数据会导致训练时间的不断加长。
如何保留知识?
方法一:弹性参数合并,elastic weight consolidation(EWC),历史任务中的重要参数,在后续的学习中,不进行更新。本质是不能遗忘历史任务中的知识。其变形算法,主要是更改重要程度 b i b_i bi的计算方法,包含Elastic Weight Consolidation(EWC)、Synaptic Intelligence(SI)、Memory Aware Synapses(MAS)。

方法二:通过生成模型产生历史任务的数据,解决存储所有历史数据占用空间太大的问题。需要不断的使用历史生成模型生成的数据,训练新的生成模型。

方法三:如果不同的任务需要不同的网络架构,参考文献Learning without forgetting(LwF),Incremental Classifier and Representation learning(iCaRL)。
如何迁移知识?
希望机器学习,不同的任务中,可以利用到其他任务所学习的知识,做到触类旁通。
终身学习与迁移学习的区别:迁移学习,在学习完任务二后,任务一的知识会不会使任务二做的更好(knowledge transfer);终身学习,在学习完任务二后,任务一和任务二会不会都做的很好(knowledge transfer and knowledge retention)。
模型的评估方法,可以为任务平均精度,在学习完Task T后,在每个task上的精度叠加,然后求取平均;backward transfer,用每个任务学习完所有任务后的精度减去第一次学习完该任务的精度,一般为负数,用于衡量模型的遗忘程度;forward transfer,用每个任务学习完该任务后的精度减去随机初始化时的精度,用于衡量模型的知识迁移能力。

方法一:Gradient Episodic Memory(GEM),在更新梯度时,要考虑历史任务在这一步的梯度和当前任务在这一步的梯度。

如何扩展模型?
任务太多,参数太多,导致现有的终身学习模型无法同时学习所有的任务。此时,需要扩展模型。
方法一:Progressive Neural Networks,把历史所有任务模型的每一层输出接到当前任务模型的下一层输入。

方法二:Expert Gate,在当前任务与历史任务中的某个任务相似时,利用该历史任务初始化该任务,用于知识迁移。

方法三:Net2Net,在新任务的精度太低时,分裂一些神经元,添加微弱扰动,使其不同。

Curriculum Learning
多任务的学习,前后顺序会影响结果,需要设计一个合理的任务学习顺序,也可以避免知识的遗忘。

6. Meta Learning
元学习:让机器具备学习如何学习的能力?
7. Network Compression
模型压缩:受限于存储资源和计算资源的限制,所以要压缩模型的大小,加快模型在边缘设备的运算速度。
Network Pruning
模型剪枝。
有剪去权重和剪去神经元两种,但是剪去权重很难实现,没有实现加速的功能。所以一般是剪去神经元。

Knowledge Distillation
知识蒸馏。

temperature的意义,避免经过softmax导致输出变成one hot编码。

Parameter Quantization
参数量化。

Architecture Design
插入线性层可以有限降低参数量,但也会降低模型的表达能力,Rank小于K。

分步卷积。


Dynamic Computation
动态计算,根据资源的限制,尽量使用效果好的模型。

8. Reinforcement Learning
增强学习:
包含一个代理Agent及其行动Action,和环境Environment以及环境的状态State。代理根据对环境的观察,采取行动;行动导致环境改变,环境会反馈给模型一个奖励Reward;然后代理根据对新环境的观察,采取新的行动,产生新的奖励。目标是通过一定的行动,使奖励最大化。
训练的难点在于,很多情况下奖励为0,少数情况下会出现奖励为正或为负。

