Python数据分析之数据探索分析(EDA)
探索性数据是一种态度,是对我们相信存在抑或不存在的事物保持灵活的审视。
---- EDA 之父 John Tukey
Exploratory data analysis is an attitude, a state of flexibility, a willingness to look for those things that we believe are not there, as well as those that we believe to be there.
何为EDA,何谓探索性数据分析?英文名为Exploratory Data Analysis,是在你拿到数据集后,并不能预知能从数据集中找到什么,但又需要了解数据的基本情况,为了后续更好地预处理数据、特征工程乃至模型建立。因此探索性数据分析,对了解数据集、了解变量之间对相互关系以及变量与预测值之间的关系尤其重要。

所谓EDA,在没有任何假设检验的前提下,通过检验数据集的数据质量、绘制图表、计算某些特征量等手段,对样本数据集的结构和规律进行分析的过程。探索性更像是侦探,需要对数据进行一次又一次地探索,寻求线索,并对结果保持开放心态。
本期Python数据分析实战将详细介绍日常工作中所常用的数据探索分析方法与技巧,将从数据质量分析和数据特征分析两大方面进行刨析。
数据质量分析
在做数据质量分析之前需要正确理解业务需要,从一定的渠道正确获取适量的数据。接下来利用Python进行数据分析时,需要根据所获得数据的具体特征,选用合适的数据读取方法和工具,数据获取三大招将帮助读者快速理解并选择合适并适合的方法,便于后续数据探索工作。
数据质量分析即检查原始数据中是否存在"脏数据"----缺失值、异常值、不一致的值、重复数据记忆含有特殊符号(如#、¥、*等)的数据。
缺失值分析
缺失值分析主要从缺失值类型、成因、影响等方面考虑。其方法包括但不限于统计缺失值数量,计算缺失值比例,matplotlib.pyplot 和 missingno 三方库对缺失值进行可视化分析,从而达到对缺失值详细对分析,并有针对性地定制缺失值处理策略,便于在后续数据预处理阶段更加高效处理。
关于缺失值处理详细内容,请移步至缺失值处理,此处不作详细介绍。
异常值分析
异常值分析是检验数据是否有录入错误以及含有不合常理的数据。忽视异常值的存在是十分危险的,不加剔除地把异常值包括进数据的计算分析过程中,会给结果带来不良影响。分析异常值常常成为发现问题进而改进决策的契机。异常值是指样本中个别值,其数量明显偏离其他的观测值。异常值也称为离群点,异常值的分析也称为离群点分析。
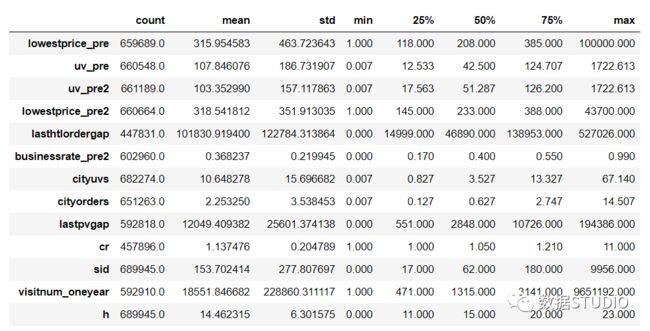
简单统计量分析----
data.describe()
可以先对变量做一个描述性统计,进而查看哪些数据是不合理的。最常用的统计量是最大值和最小值,用来判断这个变量的取值是否超出了合理的范围。
原则----
pd.mean()+/-3*pd.std()
如果数据服从正态分布,在 原则下,异常值被定义为一组测定值与平均值的偏差超过3倍标准差的值。 ,属于极个别的小概率事件。如果数据不服从标准正态分布同样成立。
箱型图分析----
data.boxplot()
提供识别异常值的标准:
小于 或大于 的值。
上四分位, 下四分位, 四分位间距。
没有任何限制下要求,真实直观地表现数据分布的本来面貌;箱形图判断异常值的标准以四分位数和四分位距为基础,四分位数具有一定的鲁棒性:多达25% 的数据可以任意元而不会扰动四分位数,所以异常值不能对这个标准施加影响。
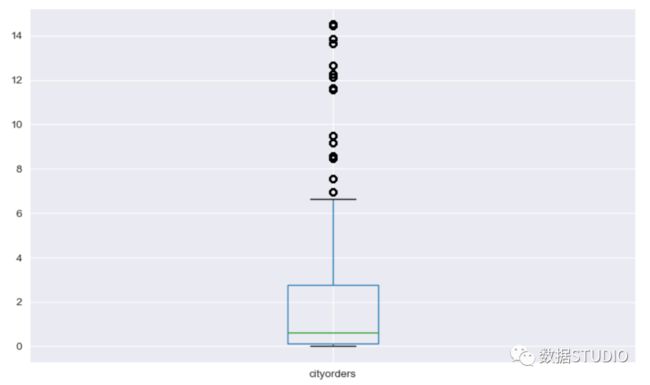
例:
>>> data.loc[:, ['cityorders']].boxplot()
输出结果:
小提琴图查看异常值
Violin Plot是用来展示多组数据的分布状态以及概率密度。 这种图表结合了箱形图和密度图的特征,主要用来显示数据的分布形状 。跟箱形图类似,但是在密度层面展示更好。在数据量非常大不方便一个一个展示的时候小提琴图特别适用。
小提琴图中间一条就是箱线图数据,25%,50%,75%位置,细线区间为95%置信区间。
代码:
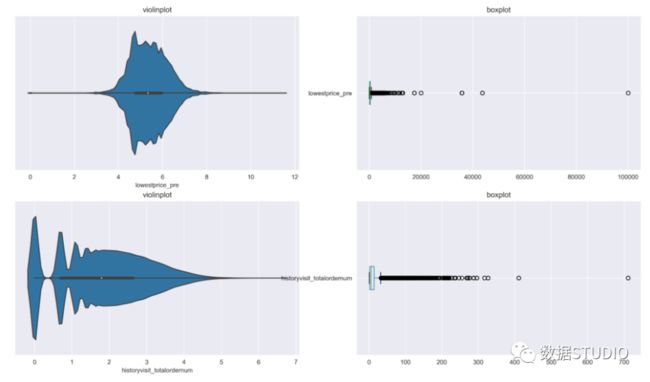
# 小提琴图与箱型图对比
>>> plt.figure(figsize=(18,10), dpi=150)
>>> plt.subplot(2,2,1)
>>> sns.violinplot(np.log(data['lowestprice_pre']))
>>> plt.title('violinplot')
>>> plt.subplot(2,2,2)
>>> data.loc[:, ['lowestprice_pre']].boxplot(vert=False)
>>> plt.title('boxplot')
>>> plt.subplot(2,2,3)
>>> sns.violinplot(np.log(data['historyvisit_totalordernum']))
>>> plt.title('violinplot')
>>> plt.subplot(2,2,4)
>>> data.loc[:, ['historyvisit_totalordernum']].boxplot(vert=False)
>>> plt.title('boxplot')输出结果:
其参数及例子详解可参见文档:https://seaborn.pydata.org/generated/seaborn.violinplot.html
一致性分析
数据不一致性是指数据的矛盾性、不相容性。直接对不一致的数据进行挖掘,可能会产生与实际相违背的挖掘结果。在数据挖掘过程中,不一致数据的产生主要发生在数据集成的过程中,可能是由被挖掘数据来自于不同的数据源、对于重复存放的数据未能进行一致性更新造成的。例如,两张表中都存储了用户的电话号码,但在用户的电话号码发生改变时只更新了一张表中的数据,那么这两张表中就有了不一致的数据。
数据特征分析
对数据进行质量分析后,通过绘制图表、计算某些特征量等手段进行数据的特征分析。
从五个角度出发,利用统计指标对定量数据进行统计描述。常用集中趋势和离散程度(离中趋势)
总体规模的描述 ---- 总量指标
分布形态的描述 ---- 偏态与峰态
对比关系的描述 ---- 相对指标
集中趋势的描述 ---- 平均指标
离散程度的描述 ---- 变异指标
1、总体规模的描述
总量指标:反映在一定时间、空间条件下某种现象的总体规模、总水平或总成果的统计指标。
分类:
按内容分:单位总量指标(人、物、…); 标志总量指标 (营业额、利润、…)
按时间不同分:时期指标、时点指标
按计量不同分:实物指标、价值指标、劳动量指标
2、分布分析
揭示数据分布特征和分布类型,可用于定量数据和定性数据的分析,且有着不同的分析策略。
定量数据等分布分析
预得到其分布形式是对称的还是非对称的、发现某些特大或特小的可疑值,可做频率分布表、频率分布直方图、绘制茎叶图进行直观分析。重点是选择"组数"和"组宽"。
有很多算法的前提假设是数据符合正态分布,例如线性回归里面最小二乘法。因此需要查看数据分布,目标变量是否符合高斯分布。
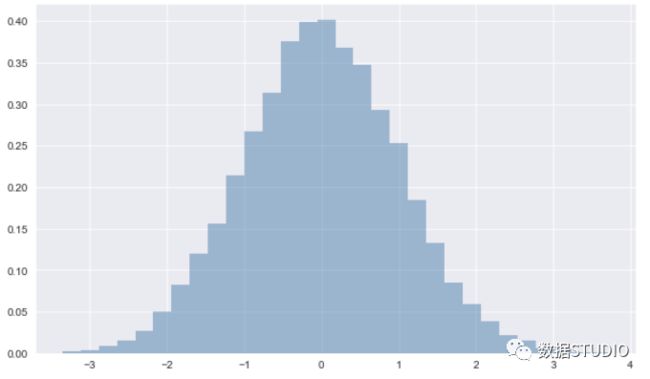
matplotlib.pyplot----hist
频率分布直方图代码:
>>> plt.hist(data, bins=30, normed=True, alpha=0.5, histtype='stepfilled',color='steelblue',edgecolor='none')输出结果:
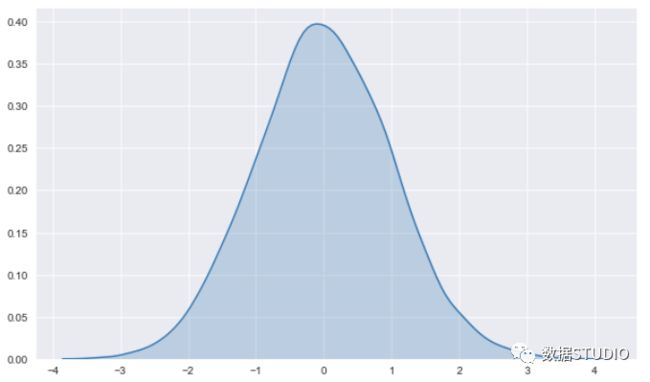
seaborn--kdeplot
seaborn中的kdeplot可用于使用核密度估计绘制单变量或双变量分布。
核密度估计(KDE)图是一种可视化数据集中观测分布的方法,与直方图呈正相关。KDE在一个或多个维度上使用连续的概率密度曲线表示数据。
相对于柱状图,KDE可以生成一个不那么杂乱且更具可解释性的图,特别是在绘制多个分布时。但是,如果底层分布是有界的或不平滑的,它就有可能导致扭曲。
代码:
>>> seaborn.kdeplot(data[col], shade=True) # KDE
输出结果:
其参数及例子详解可参见文档:http://seaborn.pydata.org/generated/seaborn.kdeplot.html
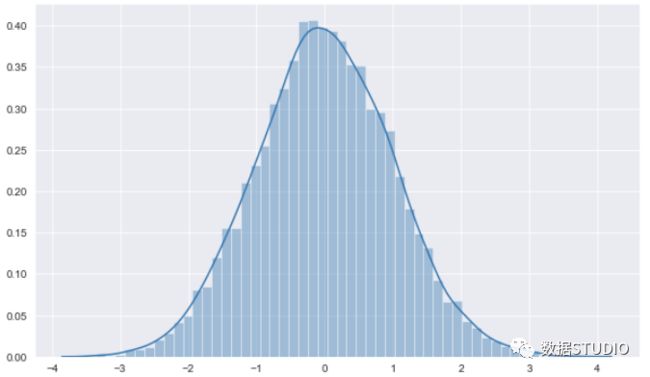
seaborn--displot
用 distplot 可以让频次直方图与 KDE 结合起来。
代码:
>>> sns.displot(data[col])
输出结果:
其参数及例子详解可参见文档:
http://seaborn.pydata.org/generated/seaborn.displot.html
定性数据等分布分析
定性数据分析是用来描述事物的分类,可用饼图、直方图或帕累托图直观地显示其分布 。如plt.bar(X,y)
分布形态的描述——偏态与峰态
偏态(skewness) 是指数据分布偏斜程度。使用偏态系数(SK)来测度数据的偏态。
偏态系数的计算:
未分组数据:
分组数据:
是否存在:
SK=0对称分布
SK>0右偏分布
SK<0左偏分布
偏态的程度:
低度偏态分布
中等偏态分布
高度偏态分布
偏态对众数、中位数和均值之间关系的影响:
对称分布:均值=中位数=众数
左偏分布:均值<中位数<众数
右偏分布:众数<中位数<均值
例:
>>> import pandas as pd
>>> import numpy as np
>>> data = list(np.random.randn(10000))
>>> pd.Series(data).skew()
-0.04896518936723592
>>> pd.Series(data).kurt()
0.05007456475593397
峰态(kurtosis) 是指数据分布的扁平程度。使用峰态系数(K)来测度数据的偏态。
偏态系数的计算:
未分组数据:
分组数据:
是否存在:
K=0扁平峰度适中
K > 0尖峰分布
K < 0扁平分布
偏态的程度:
低度尖峰分布
中等尖峰分布
高度尖峰分布
可视化:
>>> import numpy as np
>>> from scipy.stats import norm
>>> from matplotlib import pyplot as plt
>>> import seaborn as sns
>>> sns.set_style('darkgrid')
>>> plt.figure(figsize=(10,6))
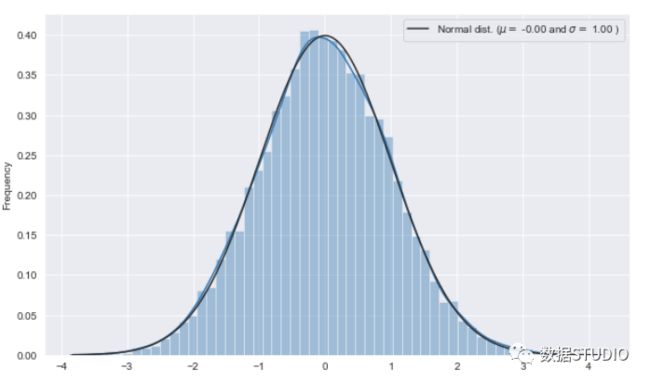
>>> data = list(np.random.randn(10000)) # 满足高斯分布的10000个数
>>> sns.distplot(data, fit=norm)
>>> (mu, sigma) = norm.fit(data)
>>> print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
>>> plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],loc='best')
>>> plt.ylabel('Frequency');
输出结果:
3、对比关系的描述
对比分析是把两个相互联系的指标进行比较,从数量上展示和说明研究对象规模的大、水平的高低、速度的快慢以及各种关系是否协调。
适合指标间的横纵向对比、时间序列的比较分析。
绝对数对比
绝对数比较分析法直接以数值进行比较,根据差异进行分析。绝对数比较分析法是指将反映企业某一方面的财务指标的绝对值进行对比和分析,通过分析来确定财务指标的增减变动情况。
相对数对比
两个有联系的指标对比计算,用以反映客观现象之间数量联系程度的综合对比。
结构相对数
将同一总体内的部分数值与全部数值进行对比求得比重——产品合格率
说明事物的性质、结构或质量
部分/总体
比例相对数
将同一总体内的不同部分的数值进行对比——人口性别比例、投资
表明总体内各部分的比例关系
一部分/另一部分
比较相对数
同一时期两个性质相同的指标数值进行对比——不同地区的商品价格对比
说明同类现象在不同空间条件下的数量对比关系
A的指标/B的相同指标
强度相对数
将两个性质不同但有一定联系的总量指标进行对比——人口密度(人/平方公里)
说明现象的强度、密度和普遍程度
某总量指标/另一性质不同但关联的总量指标
计划完成程度相对数
将某一时期实际完成数与计划完成数进行对比
说明计划的完成程度
动态相对数
将同一现象在不同时期的指标数值进行对比——发展速度
说明发展方向和变化速度
报告期/基期
4、统计分析
集中趋势的描述(Central tendency)
---- 一组数据向其中心值靠拢的趋势。
平均(mean)
----数是统计学中最常用的统计量,用来表明资料中各观测值相对集中较多的中心位置。
算术平均数
----数据的和与数据个数之比。
易受极端值的影响,受
max的影响程度>受min的影响程度
简单算术平均:所有数据的平均值
加权算术平均数:反映均值中不同成分的重要程度
频率分布表组中值和频率:
调和平均数(harmonic mean)
----变量值倒数的算术平均数的倒数。
易受极端值的影响,受
min的影响>受max的影响 调和平均数总小于算术平均数 有一项为0就无法计算H
简单调和平均:
加权调和平均数:
几何平均数(geometric mean)
----n个变量值乘积的 n 次方根。
易受极端值的影响,但受极端值的影响比算术平均数和调和平均数要小, 适用于对比率数据的平均, 主要用于计算平均增长率, 看作是均值的一种变形, 有一项为
0就无法计算H
简单几何平均:
加权几何平均数:
幂平均数(power mean)
----是毕达哥拉斯平均(包含了算术、几何、调和平均)的一种抽象化。
是所有平均数的通式, k的递增函数
当 时,是算术平均数;
当 时,是调和平均数;
当 时,是几何平均数。
例:
>>> import pandas as pd
>>> df = pd.DataFrame([1,2,3,4,5,6,7,8])
>>> df.mean()
0 4.5
dtype: float64
中位数(Median)
----又称中值,是按顺序排列的一组数据中居于中间位置的数,代表一个样本、种群或概率分布中的一个数值,其可将数值集合划分为相等的上下两部分。
将数据从小到大排列后
为奇数
众数(Mode)
----指在统计分布上具有明显集中趋势点的数值,代表数据的一般水平。也是一组数据中出现次数最多的数值,有时众数在一组数中有好几个。
离散程度的描述(Dispersion degree)
极差(Range)
----又称范围误差或全距,以R表示,是用来表示统计资料中的变异量数(measures of variation),其最大值与最小值之间的差距,即最大值减最小值后所得之数据。
例:
>>> df.max()-df.min()
0 7
dtype: int64
方差(variance)
----统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。标准差( standard deviation, std)
----是离均差平方的算术平均数的算术平方根,用σ表示。最常使用作为统计分布程度上的测量依据。
例:
>>> df.std()
0 2.44949
dtype: float64
>>> df.var()
0 6.0
dtype: float64
变异系数(coefficient of variation)
----又称“离散系数”,是概率分布离散程度的一个归一化量度,其定义为标准差与平均值之比。
标准差相对于均值离中趋势 比较具有不同单位和不同波动幅度的数据集的离中趋势。
当需要比较两组数据离散程度大小的时候,如果两组数据的测量尺度相差太大,或者数据量纲的不同,直接使用标准差来进行比较不合适,此时就应当消除测量尺度和量纲的影响,而变异系数可以做到这一点,它是原始数据标准差与原始数据平均数的比。
例:
>>> df.std()/df.mean()
0 0.544331
dtype: float64分位数(Quantile)
----亦称分位点,是指用分割点(cut point,分割点的数量比划分出的区间少1)将一个随机变量的概率分布范围分为几个具有相同概率的连续区间。
q-quantile是指将有限值集分为q个接近相同尺寸的子集。
分位数指的就是连续分布函数中的一个点,这个点对应概率p。
四分位数(Quartile)
----是统计学中分位数的一种,即把所有数值由小到大排列,然后按照总数量分成四等份,即每份中的数值的数量相同,处于三个分割点位置的数值就是四分位数。
第一四分位数:又称较小四分位数,等于该样本中所有数值由小到大排列后第25%的数字。
第二四分位数:又称中位数,等于该样本中所有数值由小到大排列后第50%的数字。
第三四分位数:又称较大四分位数,等于该样本中所有数值由小到大排列后第75%的数字。
四分位数间距(InterQuartile Range, IQR)
----第三四分位数与第一四分位数的差距,值越大说明变异程度越大。四分位距通常是用来构建箱形图,以及对概率分布)的简要图表概述。
例:
>>> import pandas as pd
>>> df = pd.DataFrame([1,2,3,4,5,6,7,8])
>>> df.describe() # 描述统计
0
count 8.00000
mean 4.50000
std 2.44949
min 1.00000
25% 2.75000
50% 4.50000
75% 6.25000
max 8.00000
例:
>>> df.quantile(0.25)
0 2.75
Name: 0.25, dtype: float64
>>> df.quantile(0.5)
0 4.5
Name: 0.5, dtype: float64
>>> import numpy as np
>>> np.percentile(df,50)
4.5
5、其他角度分析
周期性分析
探索某个变量是否随着时间的变化而呈现出某种周期变化趋势。
贡献度分析
利用帕累托法则(二八定律)的帕累托分析——同样的投入放在不同的地方会产生不同的效益。
相关性分析
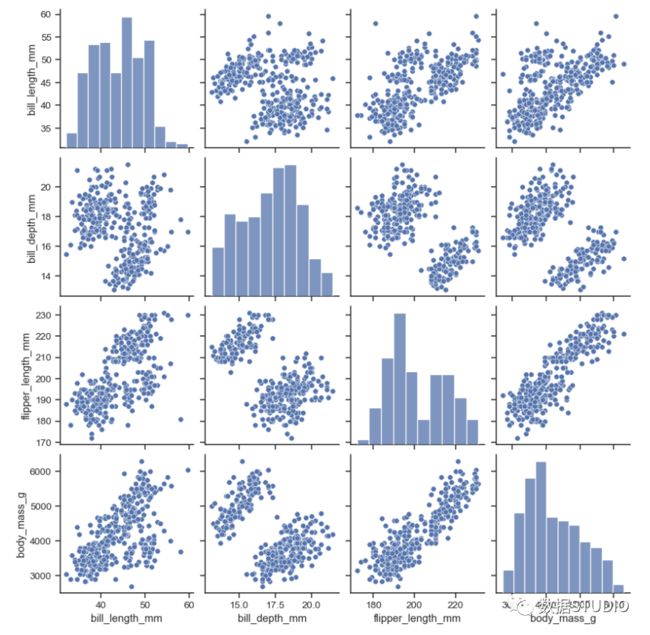
分析连续变量之间是否具有线性相关关系最直观的方法是直接绘制散点图。
直接绘制散点图:
绘制点阵矩阵
例:
>>> penguins = sns.load_dataset("penguins")
>>> sns.pairplot(penguins)其参数及例子详解可参见
http://seaborn.pydata.org/generated/seaborn.pairplot.html
输出结果:
计算相关系数
---- 更加准确地描述变量之间的线性相关程度。
Spearman 秩相关系数
斯皮尔曼等级相关系数,不服从正态分布的变量、分类或等级变量之间的关联性:
Pearson (皮尔逊)相关系数
(X和Y的协方差)/(X的标准差*Y的标准差)
---- 要求连续变量的取值服从正态分布。用以两个连续性变量之间的系数:
D.corr(method='pearson'),D1.corr(D2)
协方差用于衡量两个变量的总体误差=E[XY]-E[X]E[Y]。
D.cov(),D[0].cov(D[1]
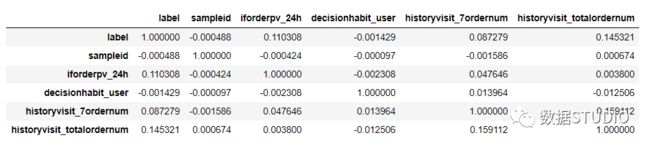
例:
>>> data.iloc[:,0:8].corr(method='pearson')
输出结果:
两者区别:
连续数据,正态分布,线性关系,用
pearson相关系数是最恰当,当然用spearman相关系数也可以,效率没有pearson相关系数高。上述任一条件不满足,就用
spearman相关系数,不能用pearson相关系数。两个定序测量数据(顺序变量)之间也用
spearman相关系数,不能用pearson相关系数。
pearson相关系数的一个明显缺陷是,作为特征排序机制,他只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应的关系,pearson相关性也可能会接近0。
判定系数
相关系数的平方 ——用来衡量回归方程对 的解释程度kendall相关系数(肯德尔相关性系数)
是一种秩相关系数,不过它所计算的对象是分类变量。
总结
本文内容包含了在数据竞赛中使用的大部分分析过程。另外,一般情况下使用EDA完成数据分析的过程如下:
读取并分析数据质量
探索性分析每个变量
变量是什么类型
变量是否有缺失值
变量是否有异常值
变量是否有重复值
变量是否均匀
变量是否需要转换
探索性分析变量与目标标签的关系
变量与标签是否存在相关性
变量与标签是否存在业务逻辑
探索性分析变量之间的关系
连续型变量
可视化:散点图、相关性热力图
皮尔逊系数、互信息
离散变量
可视化:柱状图、饼图、分组表
卡方检验
检查变量之间的正态性
直方图、箱线图、Quantile-Quantile (QQ图)
本文内容较多,建议收藏!