神经网络与深度学习-课后习题
《神经网络与深度学习-邱锡鹏》习题解答
https://github.com/nndl/solutions
面试锦囊之LR
面试篇——线性回归怎么问?
面试篇——SVM怎么问
面试篇——决策树/集成学习(上篇)
面试篇——决策树/集成学习(下篇)
面试篇——机器学习中的损失函数
面试篇——机器学习中的评估指标
面试篇——神经网络高频面试题(上)
面试篇——神经网络高频面试题(下)
【机器学习】逻辑回归(非常详细)
LR和SVM的区别
文章目录
- 2 机器学习概述
-
- 习题2-1 分析为什么平方损失函数不适用于分类问题.
- 习题2-2 线性回归的样本权重
- 习题2-3 X X T XX^T XXT的秩
- 2-4 结构风险最小化 最小二乘估计 岭回归
- 2-5 最大似然估计与最小二乘估计在标签服从高斯分布时等价
- 2.6 最大似然估计与最大后验估计
- 2.9 欠拟合→高偏差,过拟合→高方差
- 2.11 N-gram
- 3 线性模型
-
- 多分类
- Logistic Regression
- Softmax Regression
- 感知机
- 支持向量机
- y ⋅ y ^ y\cdot \hat{y} y⋅y^ 形式的损失函数
- LR SVM 联系区别
- 3.1 证明在两类线性分类中,权重向量与决策平面正交.
- 3.2 y=wx+b 与几何距离
- 3.3 线性分类中,权重向量一定是训练样本特征的线性组合
- 3.4 线性分类的决策区域是凸的
- 3.5 多分类线性可分的充要条件
- 3.6 不能用平方损失优化分类问题
- 3.7 softmax 正则化
- 3.10 线性可分 SVM 超平面存在且唯一
- 4 前馈神经网络
-
- 自动梯度计算
- 梯度消失、梯度爆炸的现象、原因、解决方法
- 神经网络不收敛的现象、原因、解决方法
- 4.1 为什么逻辑回归需要做 归一化/标准化/零均值化
- 4.2 设计一个解决xor问题的神经网络
- 4.3 死亡ReLU问题
- 4.4 计算Swish函数和GELU函数的导数
- 4.5 MLP参数计算
- 4.7 为什么不对b进行正则化
- 4.8 为什么要对参数进行随机初始化
- 4.9 梯度消失问题是否可以通过增加学习率来缓解?
- 网络优化
-
- 网络优化
- batch的选择
- 学习率调整
-
- 学习率衰减
- 学习率预热
- 周期性学习率调整
- 优化器
-
- AdaGrad
- RMSprop
- AdaDelta
- Momentum
- Nesterov
- Adam
- 梯度截断
- 优化总结
- 参数初始化
-
- 基于固定方差的参数初始化
- Xavier
- Kaiming初始化
- 正交初始化
- 归一化
-
- 数据归一化/标准化/白化
- 逐层归一化
- 批量归一化 BN
- 层归一化 LN
- 网络正则化
-
- dropout
- 标签平滑
- 7 作业
-
- 在小批量梯度下降中,试分析为什么学习率要和批量大小成正比
- 试分析为什么不能在循环神经网络中的循环连接上直接应用丢弃法?
- 若使用标签平滑正则化方法,给出其交叉熵损失函数。
- CNN
-
- H × W H\times W H×W的特征图卷积后的大小如何计算
2 机器学习概述
习题2-1 分析为什么平方损失函数不适用于分类问题.


写错了,是 x y ( y − σ ) σ ( 1 − σ ) xy(y-\sigma)\sigma(1-\sigma) xy(y−σ)σ(1−σ)
- 从损失函数上限、距离角度
直观上,对特定的分类问题,平方差的损失有上限(所有标签都错,损失值是一个有效值),但交叉熵则可以用整个非负域来反映优化程度的程度。
分类问题中的标签,是没有连续的概念的。1-hot作为标签的一种表达方式,每个标签之间的距离也是没有实际意义的,所以预测值和标签两个向量之间的平方差这个值不能反应分类这个问题的优化程度。
- 从分布的角度
平方损失函数意味着模型的输出是以预测值为均值的高斯分布,损失函数是在这个预测分布下真实值的似然度
※ 最小化平方损失函数本质上等同于在误差服从高斯分布的假设下的极大似然估计,然而大部分分类问题的误差并不服从高斯分布。
- 从梯度的角度
※ 而且在实际应用中,交叉熵在和Softmax激活函数的配合下,能够使得损失值越大导数越大,损失值越小导数越小,这就能加快学习速率。然而若使用平方损失函数,则损失越大导数反而越小(看后面的图),学习速率很慢。
还有个原因应该是softmax带来的vanishing gradient吧。预测值离标签越远,有可能的梯度越小。李龙说的non-convex 问题 ,应该是一种提现形式。
习题2-2 线性回归的样本权重


- 权重 r ( n ) r^{(n)} r(n)的作用:
为每个样本都分配了权重,相当于每个样本都设置了不同的学习率,每个样本的重视程度不一样
局部线性回归可以实现对临近点的精确拟合同时忽略那些距离较远的点的贡献,即近点的权值大,远点的权值小,k为波长参数,控制了权值随距离下降的速度,越大下降的越快。越小越精确并且太小可能出现过拟合的问题。
但局部线性回归不会得到一条适合于全局的函数模型,在每一次预测新样本时都会重新的确定参数,从而达到更好的预测效果。当数据规模比较大的时候计算量很大,学习效率很低。
习题2-3 X X T XX^T XXT的秩


2-4 结构风险最小化 最小二乘估计 岭回归

2-5 最大似然估计与最小二乘估计在标签服从高斯分布时等价

2.6 最大似然估计与最大后验估计

2.9 欠拟合→高偏差,过拟合→高方差

2.11 N-gram
假设以每个字字为基本单位,一元:|我|打|了|张|三|#;二元:我|我打|打了|了张|张三|三#;三元:我打|我打了|打了张|了张三|张三#。
当n增长时,计算压力和参数空间会迅速增长。n越大,数据越稀疏。然而,当n很小的时候,例一元模型,仅仅只是根据当前一个字来判断下一个字可能是什么,未免有失偏颇。


3 线性模型
多分类

“一对其余”方式和“一对一”方式都存在一个缺陷:特征空间中会存在一些难以确定类别的区域,

argmax方法是不是可以这样理解:如果有C个类,那么对于每个类都训练一个二分类器,如logisticsRegression。预测的时候对每个类输出一个概率值,取概率值最大的那个类
Logistic Regression

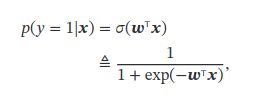


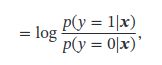

看不懂:

有空搞一下其他形式的logistics:
请问Logit 、 tobit模型、Probit模型有什么区别?它们各自适用的条件是什么?

Softmax Regression
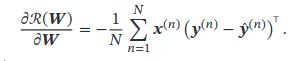

感知机



感觉不太会考,有空看看。。
支持向量机




对于一个线性可分的数据集,其分割超平面有很多个,但是间隔最大的超平面是唯一的.



y ⋅ y ^ y\cdot \hat{y} y⋅y^ 形式的损失函数
LR和SVM的区别
- 交叉熵
- 感知机
损失函数:误分类点到超平面的距离

- 软间隔支持向量机
损失函数:合页损失(Hinge Loss)

- 平方损失
y 2 = 1 y^2=1 y2=1

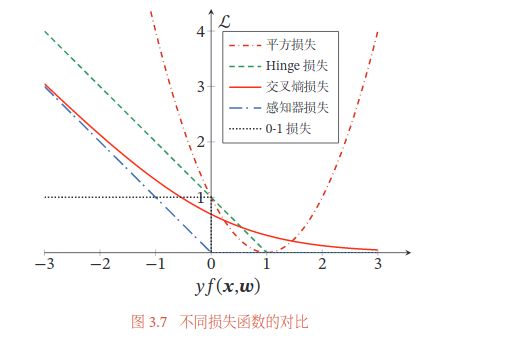

LR SVM 联系区别
参数模型与非参数模型
参数模型和非参数模型中的“参数”并不是模型中的参数,而是数据分布的参数。
-
参数模型通常假设
总体服从某个分布,这个分布可以由一些参数确定,如正态分布由均值和标准差确定,在此基础上构建的模型称为参数模型; -
非参数模型对于总体的分布
不做任何假设或者说是数据分布假设自由,只知道其分布是存在的,所以就无法得到其分布的相关参数,只能通过非参数统计的方法进行推断。
- 非参数模型也并不是没有参数,而是参数的数目很多
- non-parametric类似单词priceless,并不是没有价值,而是价值很高。

今日面试题分享:LR和SVM的联系与区别


这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
SVM的处理方法是只考虑 support vectors,也就是和分类最相关的少数点,去学习分类器。
而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重,两者的根本目的都是一样的。

3.1 证明在两类线性分类中,权重向量与决策平面正交.

3.2 y=wx+b 与几何距离

3.3 线性分类中,权重向量一定是训练样本特征的线性组合
没太能看懂。。

- 优化目标
( X w ) y T > 0 (Xw)y^T>0 (Xw)yT>0
- 误差为0
X p = 0 Xp=0 Xp=0
X ( y − X w ) = 0 X(y-Xw)=0 X(y−Xw)=0
- 重点
w = ( X X T ) − 1 y w=(XX^T)^{-1}y w=(XXT)−1y
3.4 线性分类的决策区域是凸的
- sigmoid

Logistic regression - Prove That the Cost Function Is Convex


3.5 多分类线性可分的充要条件
有点每太看懂

3.6 不能用平方损失优化分类问题

3.7 softmax 正则化



3.10 线性可分 SVM 超平面存在且唯一

统计方法学习之:svm超平面存在唯一性证明过程
4 前馈神经网络


- ReLU
- 优点
- 具有较好的稀疏性(sigmoid不够稀疏)
- 是左饱和函数(sigmoid是两端饱和函数)
- 缓解了梯度消失问题,加速梯度下降的收敛速度
- 缺点
- 是非零中心化的,给后一层的神经网络引入偏置偏移,影响梯度下降的效率
- 容易“死亡”,永远是0
- 优点
- leakyReLU
- 相当于简单的maxout单元
- PReLU
- 允许不同神经元具有不同的参数,也可以一组神经元共享一个参数.
- max ( 0 , x ) + γ i min ( 0 , x ) \max (0, x)+\gamma_{i} \min (0, x) max(0,x)+γimin(0,x)
有很多骚激活函数,有空再补充
自动梯度计算
- 数值微分
Δ x \Delta{x} Δx过小 → \rightarrow →舍入误差,过大 → \rightarrow →截断误差



- 符号微分

- 自动微分(AD)

有空推一下这个计算图
计算导数的顺序分为前向模式和反向模式,反向模式和反向传播的计算梯度的方式相同

梯度消失、梯度爆炸的现象、原因、解决方法

梯度消失问题(Vanishing GradientProblem)

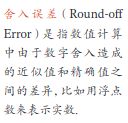
神经网络不收敛的现象、原因、解决方法
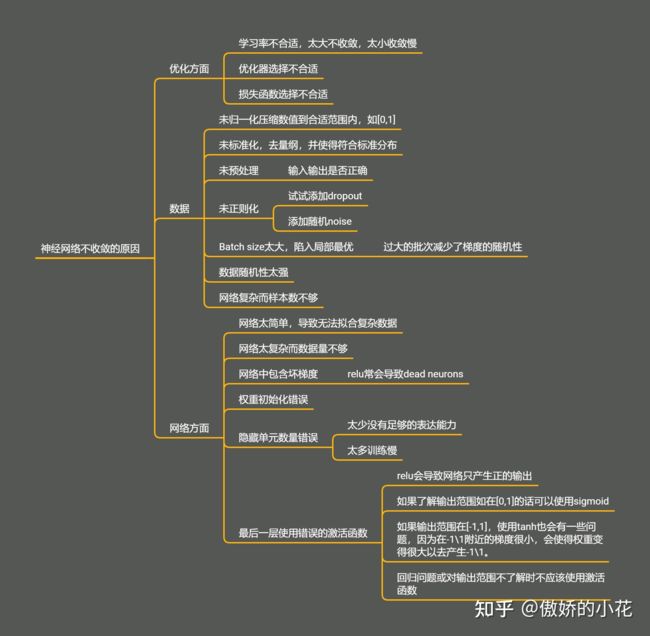
4.1 为什么逻辑回归需要做 归一化/标准化/零均值化

4.2 设计一个解决xor问题的神经网络

道理我都懂,可怎么算的
4.3 死亡ReLU问题

某个节点上所有样本的输出全部为负数,因而梯度为0,因而此处权重无法更新,因而成了死亡节点。
举例算出来的交叉熵损失是胡扯
In [4]: y_true=torch.tensor([1,0,1,0])
In [5]: y_pred=torch.tensor([0,1,1,0])
In [9]: F.binary_cross_entropy(y_true.float(), y_pred.float(),reduction="none")
Out[9]: tensor([27.6310, 27.6310, -0.0000, -0.0000])
4.4 计算Swish函数和GELU函数的导数

4.5 MLP参数计算


- M 0 N L M_0\frac{N}{L} M0LN - 输入层
- ( L − 1 ) ( N L ) 2 (L-1)(\frac{N}{L})^2 (L−1)(LN)2 - 隐藏层到隐藏层
- N L \frac{N}{L} LN - 输出层
- N + 1 N+1 N+1 偏置
from tensorflow import keras
from tensorflow.keras import layers
L=3
N=18
m=3
network=keras.Sequential([])
for _ in range(L):
network.add(layers.Dense(N/L))
network.add(layers.ReLU())
network.add(layers.Dense(1))
network.build(input_shape=(None,m))
network.count_params()==N+1+(L-1)*(N/L)*(N/L)+m*N/L+N/L
4.7 为什么不对b进行正则化
过拟合一般表现为模型对于输入的微小改变产生了输出的较大差异,这主要是由于有些参数 w w w 过大的关系,通过对 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣ 进行惩罚,可以缓解这种问题。

4.8 为什么要对参数进行随机初始化

权重初始化决定了模型算法的起跑线
4.9 梯度消失问题是否可以通过增加学习率来缓解?

网络优化
网络优化
深度神经网络是一个高度非线性的模型,其风险函数是一个非凸函数,因此风险最小化是一个非凸优化问题.
- 鞍点

在高维空间中大部分驻点都是鞍点.
- 平坦最小值
当一个模型收敛到一个平坦的局部最小值时,其鲁棒性会更好,即微小的参数变动不会剧烈影响模型能力;而当一个模型收敛到一个尖锐的局部最小值时,其鲁棒性也会比较差.具备良好泛化能力的模型通常应该是鲁棒的,因此理想的局部最小值应该是平坦的.

- 局部最小值的等价性
batch的选择
批量大小不影响随机梯度的 期望 ,但是会影响随机梯度的方差.
- 批量大小越大时,随机梯度的方差越小,引入的噪声也越小,训练也越稳定,因此可以设置较大的学习率。
- 批量大小较小时,需要设置较小的学习率,否则模型会不收敛.学习率通常要随着批量大小的增大而相应地增大.



学习率调整
学习率衰减
- 逆时衰减(Inverse Time Decay)

- 指数衰减(Exponential Decay)

其中 < 1为衰减率.
- 自然指数衰减(Natural Exponential Decay)

- 余弦衰减(Cosine Decay)


学习率预热
当批量大小的设置比较大时,通常需要比较大的学习率.
刚开始训练时,由于参数是随机初始化的,梯度往往也比较大,再加上比较大的初始学习率,会使得训练不稳定.
为了提高训练稳定性,我们可以在最初几轮迭代时,采用比较小的学习率,等梯度下降到一定程度后再恢复到初始的学习率,这种方法称为学习率预热(Learning Rate Warmup).

周期性学习率调整
为了使得梯度下降法能够逃离鞍点或尖锐最小值,一种经验性的方式是在训练过程中周期性地增大学习率.
当参数处于尖锐最小值附近时,增大学习率有助于逃离尖锐最小值;当参数处于平坦最小值附近时,增大学习率依然有可能在该平坦最小值的**吸引域(Basin of Attraction)**内.
从长期来看有助于找到更好的局部最优解.
- 循环学习率(CyclicLearningRate)
让学习率在一个区间内周期性地增大和缩小.通常可以使用线性缩放来调整学习率,称为三角循环学习率(Triangular Cyclic Learning Rate).

- 带热重启的随机梯度下降(Stochastic Gradient De-scent with Warm Restarts,SGDR)


优化器
内容详细,并且包含并行SGD和梯度噪音
An overview of gradient descent optimization algorithms
AdaGrad
借鉴ℓ2正则化的思想,每次迭代时自适应地调整每个参数的学习率.
在AdaGrad算法中,如果某个参数的偏导数累积比较大,其学习率相对较小;相反,如果其偏导数累积较小,其学习率相对较大.但整体是随着迭代次数的增加,学习率逐渐缩小.
AdaGrad算法的缺点是在经过一定次数的迭代依然没有找到最优点时,由于这时的学习率已经非常小,很难再继续找到最优点.
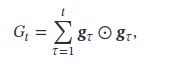

RMSprop
自适应学习率的方法
可以在有些情况下避免AdaGrad算法中学习率不断单调下降以至于过早衰减的缺点.


其中为衰减率,一般取值为0.9.是初始的学习率,比如0.001
AdaDelta

没太看懂
Momentum
除了调整学习率之外,还可以进行梯度估计(Gradient Estimation)的修正.
在随机(小批量)梯度下降法中,如果每次选取样本数量比较小,损失会呈现振荡的方式下降.也就是说,随机梯度下降方法中每次迭代的梯度估计和整个训练集上的最优梯度并不一致,具有一定的随机性
每次迭代的梯度可以看作加速度.
计算负梯度的“加权移动平均”作为参数的更新方向,
一般而言,在迭代初期,梯度方向都比较一致,动量法会起到加速作用,可以更快地到达最优点.
在迭代后期,梯度方向会不一致,在收敛值附近振荡,动量法会起到减速作用,增加稳定性.
从某种角度来说,当前梯度叠加上部分的上次梯度,一定程度上可以近似看作二阶梯度.
Nesterov
Nesterov Accelerated Gradient,简称NAG
内斯特洛夫

有空细看一下优化部分
比Momentum更快:揭开Nesterov Accelerated Gradient的真面目
- 公式1,Momentum的数学形式
d i = β d i − 1 + g ( θ i − 1 ) d_{i}=\beta d_{i-1}+g\left(\theta_{i-1}\right) di=βdi−1+g(θi−1)
θ i = θ i − 1 − α d i \theta_{i}=\theta_{i-1}-\alpha d_{i} θi=θi−1−αdi
对于这个公式,合并可得:
θ i = θ i − 1 − α β d i − 1 − α g ( θ i − 1 ) \theta_i=\theta_{i-1}-\alpha \beta d_{i-1} -\alpha g(\theta_{i-1}) θi=θi−1−αβdi−1−αg(θi−1)
可知,参数必然走过 α β d i − 1 \alpha \beta d_{i-1} αβdi−1这个点
- 公式2,NAG的原始形式
d i = β d i − 1 + g ( θ i − 1 − α β d i − 1 ) d_{i}=\beta d_{i-1}+g\left(\theta_{i-1}-\alpha \beta d_{i-1}\right) di=βdi−1+g(θi−1−αβdi−1)
θ i = θ i − 1 − α d i \theta_{i}=\theta_{i-1}-\alpha d_{i} θi=θi−1−αdi
对于这个改动,很多文章给出的解释是,能够让算法提前看到前方的地形梯度,如果前面的梯度比当前位置的梯度大,那我就可以把步子迈得比原来大一些,如果前面的梯度比现在的梯度小,那我就可以把步子迈得小一些。这个大一些、小一些,都是相对于原来不看前方梯度、只看当前位置梯度的情况来说的。
Adam



梯度截断
用大的梯度更新参数反而会导致其远离最优点.
当梯度的模大于一定阈值时,就对梯度进行截断,称为梯度截断(Gradient Clipping)
在训练循环神经网络时,按模截断是避免梯度爆炸问题的有效方法.

优化总结
- 调整学习率,使得优化更稳定
- 梯度估计修正,优化训练速度
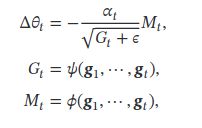


参数初始化
基于固定方差的参数初始化


-
引起梯度消失梯度爆炸(激活函数饱和)
-
需要配合逐层归一化
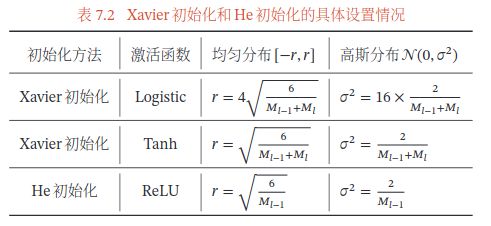
Xavier
泽维尔
初始化一个深度网络时,为了缓解梯度消失或爆炸问题,我们尽可能保持每个神经元的输入和输出的方差一致,根据神经元的连接数量来自适应地调整初始化分布的方差,这类方法称为方差缩放(Variance Scaling).

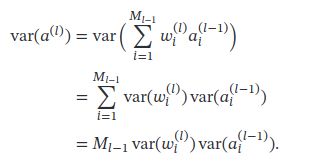
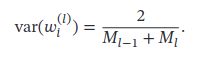
Xavier初始化也适用于Logistic函数和Tanh函数.这是因为神经元的参数和输入的绝对值通常比较小,处于激活函数的线性区间.这时Logistic函数和Tanh函数可以近似为线性函数.

Kaiming初始化


正交初始化
由于采样的随机性,采样出来的权重矩阵依然可能存在梯度消失或梯度爆炸问题.
正交初始化通常用在循环神经网络中循环边上的权重矩阵上.
为了避免梯度消失或梯度爆炸问题,我们希望误差项在反向传播中具有范数保持性(Norm-Preserving)
∥ δ ( l − 1 ) ∥ 2 = ∥ δ ( l ) ∥ 2 = ∥ ( W ( l ) ) ⊤ δ ( l ) ∥ 2 \left\|\delta^{(l-1)}\right\|^{2}=\left\|\delta^{(l)}\right\|^{2}=\left\|\left(\boldsymbol{W}^{(l)}\right)^{\top} \delta^{(l)}\right\|^{2} ∥∥δ(l−1)∥∥2=∥∥δ(l)∥∥2=∥∥∥∥(W(l))⊤δ(l)∥∥∥∥2

- 用 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1)的高斯分布初始化一个矩阵
- 对这个矩阵进行奇异值分解得到两个正交矩阵 A = U Σ V T A=U\Sigma V^T A=UΣVT
求模当然要平方了


归一化
数据归一化/标准化/白化
如果一个机器学习算法在缩放全部或部分特征后不影响它的学习和预测,我们就称该算法具有尺度不变性(Scale Invariance).比如线性分类器是尺度不变的,而最近邻分类器就是尺度敏感的.
除了参数初始化比较困难之外,不同输入特征的尺度差异比较大时,梯度下降法的效率也会受到影响.

逐层归一化
- 更好的尺度不变形
如果一个神经层的输入分布发生了改变,那么其参数需要重新学习,这种现象叫作内部协变量偏移(Internal Covariate Shift).
把每个神经层的输入分布都归一化为标准正态分布,可以使得每个神经层对其输入具有更好的尺度不变性.
不论低层的参数如何变化,高层的输入保持相对稳定.
尺度不变性可以使得我们更加高效地进行参数初始化以及超参选择.
- 更平滑的优化地形
使得大部分神经层的输入处于不饱和区域,从而让梯度变大,避免梯度消失问题;
另一方面还可以使得神经网络的优化地形(Optimization Landscape)更加平滑,以及使梯度变得更加稳定,从而允许我们使用更大的学习率,并提高收敛速度;
批量归一化 BN
批量归一化(Batch Normalization,BN)可以对神经网络中任意的中间层进行归一化操作.
顺序:

Dense → \rightarrow →BatchNorm → \rightarrow →Activate

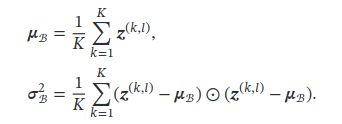



自用Pytorch笔记(十六:Batch Normalization)(1.1版本)
逐层归一化不但可以提高优化效率,还可以作为一种隐形的正则化方法.
在训练时,神经网络对一个样本的预测不仅和该样本自身相关,也和同一批次中的其他样本相关.由于在选取批次时具有随机性,因此使得神经网络不会“过拟合”到某个特定样本,从而提高网络的泛化能力.
CNN的BN算的是channel
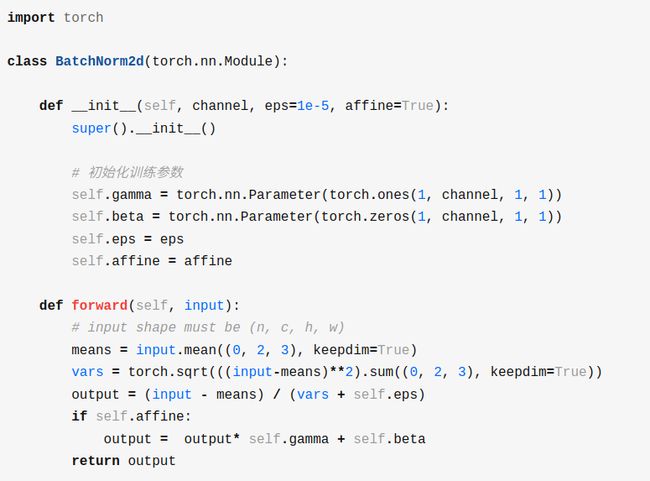
CNN 模型所需的计算力flops是什么?怎么计算?
层归一化 LN
批量归一化是对一个中间层的单个神经元进行归一化操作,因此要求小批量样本的数量不能太小,否则难以计算单个神经元的统计信息.此外,如果一个神经元的净输入的分布在神经网络中是动态变化的,比如循环神经网络,那么就无法应用批量归一化操作.
层归一化是对一个中间层的所有神经元进行归一化.
而LN则是针对一句话进行缩放的,且LN一般用在第三维度,如[batchsize, seq_len, dims]中的dims,一般为词向量的维度,或者是RNN的输出维度等等,这一维度各个特征的量纲应该相同。因此也不会遇到上面因为特征的量纲不同而导致的缩放问题。
## 权重归一化
## 局部相应归一化
网络正则化
dropout




在测试时需要将神经层的输入乘以,也相当于把不同的神经网络做了平均.
一般来讲,对于隐藏层的神经元,其保留率 = 0.5时效果最好,这对大部分的网络和任务都比较有效.
当 = 0.5时,在训练时有一半的神经元被丢弃,只剩余一半的神经元是可以激活的,随机生成的网络结构最具多样性.
对于输入层的神经元,其保留率通常设为更接近1的数,使得输入变化不会太大.
对输入层神经元进行丢弃时,相当于给数据增加噪声,以此来提高网络的鲁棒性.
丢弃法一般是针对神经元进行随机丢弃,但是也可以扩展到对神经元之间的连接进行随机丢弃,或每一层进行随机丢弃.

- 集成学习的角度

- 贝叶斯学习的角度
没太看懂贝叶斯角度

- 训练时缩放:乘以 1 1 − p \frac{1}{1-p} 1−p1 1 − p 1-p 1−p表示剩下的神经元,希望将剩下的神经元归一化到1
- 推理时缩放:乘以 p p p

dropout for embedding——spatialdropout
PyTorch1.0实现L1,L2正则化及Dropout (附dropout原理的python实现)
- 循环神经网络 变分丢弃法

标签平滑
标签平滑&深度学习:Google Brain解释了为什么标签平滑有用以及什么时候使用它


7 作业
在小批量梯度下降中,试分析为什么学习率要和批量大小成正比

试分析为什么不能在循环神经网络中的循环连接上直接应用丢弃法?
循环神经网络中的循环连接具有误差累积的效果,最终会导致将丢弃法所造成的噪声放大,破坏模型的学习能力
若使用标签平滑正则化方法,给出其交叉熵损失函数。

CNN
卷积神经网络具有3个结构上的特性:
- 局部连接
- 权重共享
- 汇聚
使得卷积神经网络具有一定程度上的:
- 平移,缩放,旋转 不变形
pooling层的作用:
- 进行特征选择
- 降低特征数量
- 避免过拟合
identity mappings,恒等映射


神经网络高频面试题(续)
H × W H\times W H×W的特征图卷积后的大小如何计算
