AGX Xavier & DRIVE AGX Orin对比
一、引言
随着智能网联汽车大会
的召开,智能网联汽车技术路线图2.0发布,智能汽车技术的发展方向更趋清晰,“三横两纵”中车辆关键技术作为智能汽车功能实现的承载基础,智能计算平台的开发尤为重要。
智能计算平台核心的就是AI芯片,目前接触NVIDIA Xavier较多,并且团队内基于Xavier+TC297的架构设计了几款域控制器投放市场。同时由于项目需要,对于Mobieye EyeQ4、地平线J2等也不陌生。团队也针对未来智能计算平台的发展方向开展过多次讨论,FPGA是最接近量产的方案,但是基于Xavier、J2等AI芯片的开发方案却是最容易产品化的选择。智能计算平台核心的就是AI芯片,目前接触NVIDIA Xavier较多,不过目前Xavier等芯片也有很多的问题,NVIDIA在2019年GTC上发布的Orin芯片
作为Xavier的换代品,要到2022年才可以量产,希望今年12月份的NVIDIA 2020 GTC可以带来更多关于Orin的信息,本文通过简单对比Xavier和Orin,为后续智能计算平台的产品设计提供一些参考。更希望Xavier目前的一些问题在Orin上可以得到解决,如车规级、功能安全、温度范围、功耗和散热等等。
二、Xavier-世界上最强大的SoC
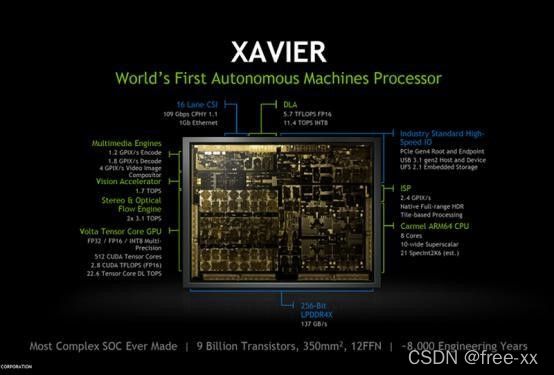
Xavier被NVIDIA称作为“世界上最强大的SoC(片上系统)”,作为NVIDIA AI芯片当打选手,Xavier具有高达 32 TOPS的峰值计算能力和 750 Gbps 的高速 I/O 性能。可处理来自车辆雷达、摄像头、激光雷达和超声波系统
的L5级自主驾驶数据。
Xavier SoC基于台积电12nm工艺,集成90亿颗晶体管,芯片面积350平方毫米,CPU采用NVIDIA自研8核ARM64架构(代号Carmel),GPU采用512颗CUDA的Volta,支持FP32/FP16/INT8,20W功耗下单精度浮点性能
1.3TFLOPS,Tensor核心性能20TOPs,解锁到30W后可达30TOPs。
Xavier 内有六种不同的处理器:Volta TensorCore GPU,八核ARM64 CPU,双NVDLA 深度学习加速器,图像处理器,视觉处理器和视频处理器。这些处理器使其能够同时、且实时地处理数十种算法,以用于传感器处理、测距、定位和绘图、视觉和感知以及路径规划
。
三、Orin-NVIDIA的核弹级AI芯片
Orin是NVIDIA在GTC China 2019大会
发布的,号称核弹产品,采用全新的NVIDIA GPU及12核ARM CPU,单片运算能力可达到每秒200TOPS,性能是Xavier的7倍。

Orin(DRIVE AGX Orin)——NVIDIA定位是用于自动驾驶和机器人的高度先进的软件定义平台。内置的全新Orin系统级芯片,由170亿个晶体管组成,集成了英伟达新一代 GPU架构和12核的Arm Hercules CPU内核以及全新深度学习和计算机视觉加速器。根据黄教主厨房GTC 2020发布的消息,Orin有可能会用到安培架构。
Orin 可处理在自动驾驶汽车和机器人中同时运行的大量应用和深度神经网络,并且达到了 ISO 26262 ASIL-D 等系统安全标准。根据NVIDIA官方数据,L5级别的全自动驾驶可以使用2路DRIVE AGX Orin+2组GPU的方案,性能可达2000TFLOPS。

DRIVE AGX Orin 作为一个软件定义的智能计算平台,能够覆盖从 L2 级到 L5 级完全自动驾驶汽车开发的兼容架构平台,有助于 OEM 厂商开发大型复杂的软件产品。Orin 和 Xavier 均可通过开放的 CUDA、TensorRT API 及各类库进行编程,方便开发者跨平台移植和应用。
另外,Orin芯片中的CPU部分为ARM架构,据分析NVIDIA之所以选择ARM平台是与PCI Express有一定关系。PCI Express是大家都会遵守的行业标准,PCI Express不仅可以为ARM提供有力支持,而且通过PCI Express可以方便的连通ARM处理器,便于开发者实现软件部署。ARM处理器
再就是ARM平台拥有非常出色的工具和生态,通过ARM可以非常轻松的实现CUDA编译。最近有报到NVIDIA在积极收购ARM,如果这一收购能够达成,那么AI芯片领域GPU+ARM架构CPU的路线将会继续引领航行业发展。
四、基于Xavier的智能计算平台设计
优控智行设计的一款自动驾驶域控制器ADCU,基于NVIDIA Jetson Xavier和Infineon TC297,端口配置资源丰富,支持Camera、Radar、Lidar、IMU等传感器接入,并支持车载以太网通讯。Xavier用于环境感知、图像融合、路径规划等,TC297用于安全监控、冗余控制、网关通讯及整车控制,符合行业最先进的智能网联汽车电气架构设计理念,集成多个电控单元功能,降低设计风险,功能安全面向ISO26262标准中的最高级ASIL-D。
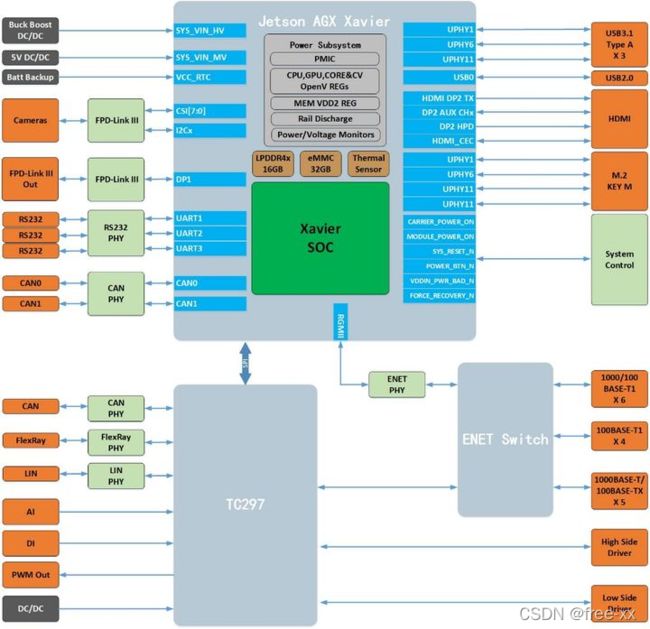
目前基于NVIDIA Xavier的智能计算平台均采用类似架构设计方案,有部分企业的产品设计有2个或多个Xavier芯片,也是通过Ethernet Switch来进行级联和通讯,而Infineon的TC297/397成为功能安全MCU的不二之选。
五、Orin的市场潜力
根据目前自动驾驶行业算法和数据方面的积累,Drive Xavier 30TOPS(万亿次计算每秒)的自动驾驶算力应付L2级别的全速域ACC自适应巡航、车道居中、车道偏离预警等等都是足够的。但是对于L3及以上自动驾驶系统而言,Xavier的算力已经捉襟见肘,比如特斯拉的NOA(Navigate on Autopilot)、蔚来NOP(Navigate on Pilot)蔚来NOP、小鹏NGP(Navigation Guided Pilot)等高
速自主导航驾驶功能(仍需驾驶员握紧方向盘),对系统算力要求已经远超30Tops。
因此,实现L4 以及L5完全自动驾驶,智能计算平台需要更多的算力支撑,而Orin的推出水到渠成。

和Xavier相比,Orin的算力提升7倍,从30TOPS提升到了200TOPS。自半导体工艺进步、芯片架构的革新、以及CPU从ARM Cortex A57到A78带来的性能飞跃,让7倍的性能提升成为现实。
目前根据行业反馈来看,L3级以上自动驾驶车型,AI芯片基本都来自Mobileye和英伟达,以及自研FSD芯片的特斯拉。号称汽车界的苹果的特斯拉自研FSD芯片单颗算力也才72TOPS,Autopilot硬件3.0用两块芯片也就是144TOPS,目前特斯拉发布的AP3.0就已经支持高速自主导航驾驶也就是NOA。200TOPS算力到什么程度可想而知。
Orin和Xavier对比功耗方面也有明显改善,Orin在性能提升7倍的前提下,功耗仅为45W左右,功耗提高了1.5倍,在车载电子领域对功耗极其敏感的情况下,对于结构工程师而言,不用考虑向特斯拉一样的水冷系统而烦恼了。
除此之外,Orin也延续了英伟达Drive系列
的传统,针对L5全自动驾驶提供多芯片方案。最强版本采用两个Orin+两个7纳米A100 GPU,算力达到了疯狂的2000TOPS,堪比性能怪兽,比上一代Drive Pegasus的320TOPS也提升到超过6倍。
针对目前主流的AI芯片供应商而言,小鹏P7搭载英伟达Xavier,威马的L3自动驾驶方案也是来自英伟达的芯片,蔚来和广汽 Aion LX都是采用Mobileye的芯片。而理想汽车在9月份已经和NVIDIA达成合作,在新车型上搭载Orin芯片。
虽然目前看来Mobileye市场份额占据绝对优势,但是EyeQ系列芯片算力的瓶颈始终无法突破。而Orin的200TOPS和45W的功耗以及ASIL-D及功能安全,称为核弹绝不过分,期待今年的GTC中国上可以有更多关于自动驾驶相关的介绍和信息发布。