Mybatis系列全解(八):Mybatis的9大动态SQL标签你知道几个?提前致女神!
封面:洛小汐
作者:潘潘


2021年,仰望天空,脚踏实地。


这算是春节后首篇 Mybatis 文了~
跨了个年感觉写了有半个世纪 …
借着女神节 ヾ(◍°∇°◍)ノ゙
提前祝男神女神们越靓越富越嗨森!
上图保存可做朋友圈封面图 ~
前言
本节我们介绍 Mybatis 的强大特性之一:动态 SQL ,从动态 SQL 的诞生背景与基础概念,到动态 SQL 的标签成员及基本用法,我们徐徐道来,再结合框架源码,剖析动态 SQL (标签)的底层原理,最终在文末吐槽一下:在无动态 SQL 特性(标签)之前,我们会常常掉进哪些可恶的坑吧~

建议关注我们! Mybatis 全解系列一直在更新哦
Mybaits系列全解
- Mybatis系列全解(一):手写一套持久层框架
- Mybatis系列全解(二):Mybatis简介与环境搭建
- Mybatis系列全解(三):Mybatis简单CRUD使用介绍
- Mybatis系列全解(四):全网最全!Mybatis配置文件XML全貌详解
- Mybatis系列全解(五):全网最全!详解Mybatis的Mapper映射文件
- Mybatis系列全解(六):Mybatis最硬核的API你知道几个?
- Mybatis系列全解(七):Dao层的两种实现之传统与代理
- Mybatis系列全解(八):Mybatis的动态SQL
- Mybatis系列全解(九):Mybatis的复杂映射
- Mybatis系列全解(十):Mybatis注解开发
- Mybatis系列全解(十一):Mybatis缓存全解
- Mybatis系列全解(十二):Mybatis插件开发
- Mybatis系列全解(十三):Mybatis代码生成器
- Mybatis系列全解(十四):Spring集成Mybatis
- Mybatis系列全解(十五):SpringBoot集成Mybatis
- Mybatis系列全解(十六):Mybatis源码剖析
本文目录
1、什么是动态SQL
2、动态SQL的诞生记
3、动态SQL标签的9大标签
4、动态SQL的底层原理

1、什么是动态SQL ?
关于动态 SQL ,允许我们理解为 “ 动态的 SQL ”,其中 “ 动态的 ” 是形容词,“ SQL ” 是名词,那显然我们需要先理解名词,毕竟形容词仅仅代表它的某种形态或者某种状态。
SQL 的全称是:
Structured Query Language,结构化查询语言。
SQL 本身好说,我们小学时候都学习过了,无非就是 CRUD 嘛,而且我们还知道它是一种 语言,语言是一种存在于对象之间用于交流表达的 能力,例如跟中国人交流用汉语、跟英国人交流用英语、跟火星人交流用火星语、跟小猫交流用喵喵语、跟计算机交流我们用机器语言、跟数据库管理系统(DBMS)交流我们用 SQL。
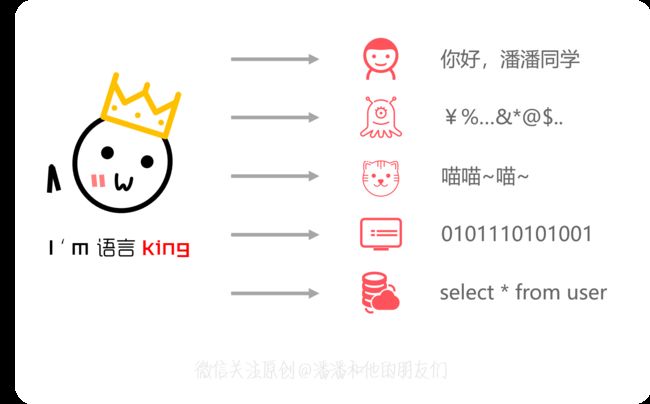
想必大家立马就能明白,想要与某个对象交流,必须拥有与此对象交流的语言能力才行!所以无论是技术人员、还是应用程序系统、或是某个高级语言环境,想要访问/操作数据库,都必须具备 SQL 这项能力;因此你能看到像 Java ,像 Python ,像 Go 等等这些高级语言环境中,都会嵌入(支持) SQL 能力,达到与数据库交互的目的。
很显然,能够学习 Mybatis 这么一门高精尖(ru-men)持久层框架的编程人群,对于 SQL 的编写能力肯定已经掌握得 ss 的,平时各种 SQL 编写那都是信手拈来的事, 只不过对于 动态SQL 到底是个什么东西,似乎还有一些朋友似懂非懂!但是没关系,我们百度一下。
动态 SQL:一般指根据用户输入或外部条件 动态组合 的 SQL 语句块。
很容易理解,随外部条件动态组合的 SQL 语句块!我们先针对动态 SQL 这个词来剖析,世间万物,有动态那就相对应的有静态,那么他们的边界在哪里呢?又该怎么区分呢?

其实,上面我们已经介绍过,在例如 Java 高级语言中,都会嵌入(支持)SQL 能力,一般我们可以直接在代码或配置文件中编写 SQL 语句,如果一个 SQL 语句在 “编译阶段” 就已经能确定 主体结构,那我们称之为静态 SQL,如果一个 SQL 语句在编译阶段无法确定主体结构,需要等到程序真正 “运行时” 才能最终确定,那么我们称之为动态 SQL,举个例子:
<mapper namespace="dao">
<select id="selectAll" resultType="user">
select * from t_user
select>
mapper>
// 2、执行SQL
sqlSession.select("dao.selectAll");
很明显,以上这个 SQL ,在编译阶段我们都已经知道它的主体结构,即查询 t_user 表的所有记录,而无需等到程序运行时才确定这个主体结构,因此以上属于 静态 SQL。那我们再看看下面这个语句:
<mapper namespace="dao">
<select id="selectAll" parameterType="user">
select * from t_user
<if test="id != null">
where id = #{id}
if>
select>
mapper>
// 2、执行SQL
User user1 = new User();
user1.setId(1);
sqlSession.select("dao.selectAll",user1); // 有 id
User user2 = new User();
sqlSession.select("dao.selectAll",user2); // 无 id
认真观察,以上这个 SQL 语句,额外添加了一块 if 标签 作为条件判断,所以应用程序在编译阶段是无法确定 SQL 语句最终主体结构的,只有在运行时根据应用程序是否传入 id 这个条件,来动态的拼接最终执行的 SQL 语句,因此属于动态 SQL 。

另外,还有一种常见的情况,大家看看下面这个 SQL 语句算是动态 SQL 语句吗?
<mapper namespace="dao">
<select id="selectAll" parameterType="user">
select * from t_user where id = #{id}
select>
mapper>
// 2、执行SQL
User user1 = new User();
user1.setId(1);
sqlSession.select("dao.selectAll",user1); // 有 id
根据动态 SQL 的定义,大家是否能判断以上的语句块是否属于动态 SQL?
答案:不属于动态 SQL !
原因很简单,这个 SQL 在编译阶段就已经明确主体结构了,虽然外部动态的传入一个 id ,可能是1,可能是2,可能是100,但是因为它的主体结构已经确定,这个语句就是查询一个指定 id 的用户记录,它最终执行的 SQL 语句不会有任何动态的变化,所以顶多算是一个支持动态传参的静态 SQL 。
至此,我们对于动态 SQL 和静态 SQL 的区别已经有了一个基础认知,但是有些好奇的朋友又会思考另一个问题:动态 SQL 是 Mybatis 独有的吗?


2、动态SQL的诞生记
我们都知道,SQL 是一种伟大的数据库语言 标准,在数据库管理系统纷争的时代,它的出现统一规范了数据库操作语言,而此时,市面上的数据库管理软件百花齐放,我最早使用的 SQL Server 数据库,当时用的数据库管理工具是 SQL Server Management Studio,后来接触 Oracle 数据库,用了 PL/SQL Developer,再后来直至今日就几乎都在用 MySQL 数据库(这个跟各种云厂商崛起有关),所以基本使用 Navicat 作为数据库管理工具,当然如今市面上还有许多许多,数据库管理工具嘛,只要能便捷高效的管理我们的数据库,那就是好工具,duck 不必纠结选择哪一款!

那这么多好工具,都提供什么功能呢?相信我们平时接触最多的就是接收执行 SQL 语句的输入界面(也称为查询编辑器),这个输入界面几乎支持所有 SQL 语法,例如我们编写一条语句查询 id 等于15 的用户数据记录:
select * from user where id = 15 ;
我们来看一下这个查询结果:
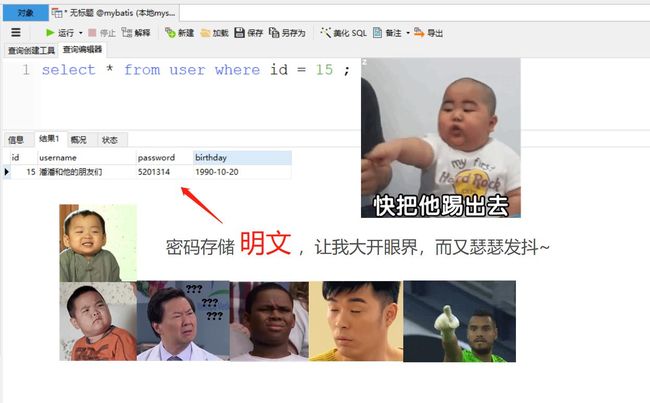
很显然,在这个输入界面内输入的任何 SQL 语句,对于数据库管理工具来说,都是 动态 SQL!因为工具本身并不可能提前知道用户会输入什么 SQL 语句,只有当用户执行之后,工具才接收到用户实际输入的 SQL 语句,才能最终确定 SQL 语句的主体结构,当然!即使我们不通过可视化的数据库管理工具,也可以用数据库本身自带支持的命令行工具来执行 SQL 语句。但无论用户使用哪类工具,输入的语句都会被工具认为是 动态 SQL!
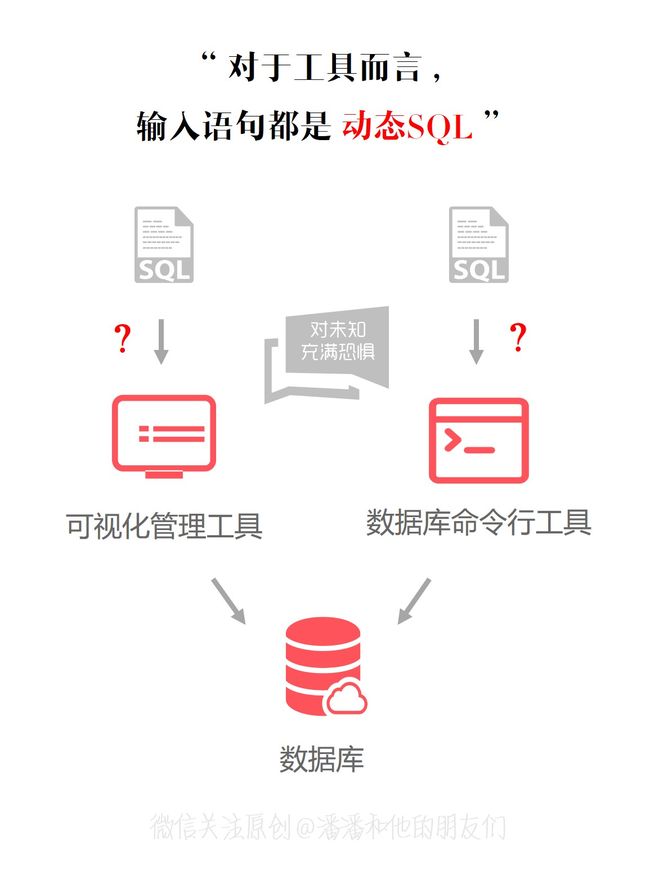
这么一说,动态 SQL 原来不是 Mybatis 独有的特性!其实除了以上介绍的数据库管理工具以外,在纯 JDBC 时代,我们就经常通过字符串来动态的拼接 SQL 语句,这也是在高级语言环境(例如 Java 语言编程环境)中早期常用的动态 SQL 构建方式!
// 外部条件id
Integer id = Integer.valueOf(15);
// 动态拼接SQL
StringBuilder sql = new StringBuilder();
sql.append(" select * ");
sql.append(" from user ");
// 根据外部条件id动态拼接SQL
if ( null != id ){
sql.append(" where id = " + id);
}
// 执行语句
connection.prepareStatement(sql);
只不过,这种构建动态 SQL 的方式,存在很大的安全问题和异常风险(我们第5点会详细介绍),所以不建议使用,后来 Mybatis 入世之后,在对待动态 SQL 这件事上,就格外上心,它默默发誓,一定要为使用 Mybatis 框架的用户提供一套棒棒的方案(标签)来灵活构建动态 SQL!

于是乎,Mybatis 借助 OGNL 的表达式的伟大设计,可算在动态 SQL 构建方面提供了各类功能强大的辅助标签,我们简单列举一下有:if、choose、when、otherwise、trim、where、set、foreach、bind等,我随手翻了翻我电脑里头曾经保存的学习笔记,我们一起在第3节中温故知新,详细的讲一讲吧~
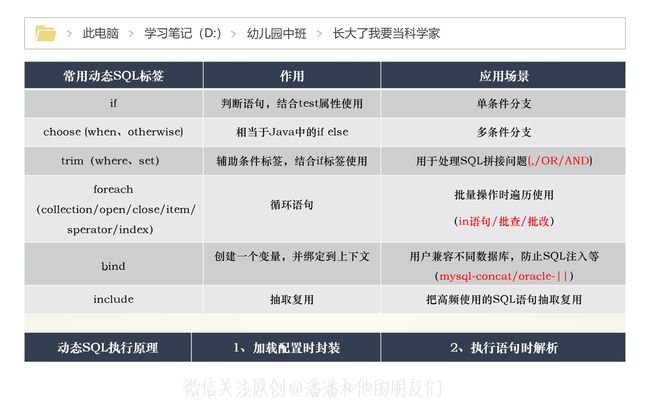
另外,需要纠正一点,就是我们平日里在 Mybatis 框架中常说的动态 SQL ,其实特指的也就是 Mybatis 框架中的这一套动态 SQL 标签,或者说是这一 特性,而并不是在说动态 SQL 本身。

3、动态SQL标签的9大标签
很好,可算进入我们动态 SQL 标签的主题,根据前面的铺垫,其实我们都能发现,很多时候静态 SQL 语句并不能满足我们复杂的业务场景需求,所以我们需要有适当灵活的一套方式或者能力,来便捷高效的构建动态 SQL 语句,去匹配我们动态变化的业务需求。举个栗子,在下面此类多条件的场景需求之下,动态 SQL 语句就显得尤为重要(先登场 if 标签)。

当然,很多朋友会说这类需求,不能用 SQL 来查,得用搜索引擎,确实如此。但是呢,在我们的实际业务需求当中,还是存在很多没有引入搜索引擎系统,或者有些根本无需引入搜索引擎的应用程序或功能,它们也会涉及到多选项多条件或者多结果的业务需求,那此时也就确实需要使用动态 SQL 标签来灵活构建执行语句。
那么, Mybatis 目前都提供了哪些棒棒的动态 SQL 标签呢 ?我们先引出一个类叫做 XMLScriptBuilder ,大家先简单理解它是负责解析我们的动态 SQL 标签的这么一个构建器,在第4点底层原理中我们再详细介绍。
// XML脚本标签构建器
public class XMLScriptBuilder{
// 标签节点处理器池
private final Map<String, NodeHandler> nodeHandlerMap = new HashMap<>();
// 构造器
public XMLScriptBuilder() {
initNodeHandlerMap();
//... 其它初始化不赘述也不重要
}
// 初始化
private void initNodeHandlerMap() {
nodeHandlerMap.put("trim", new TrimHandler());
nodeHandlerMap.put("where", new WhereHandler());
nodeHandlerMap.put("set", new SetHandler());
nodeHandlerMap.put("foreach", new ForEachHandler());
nodeHandlerMap.put("if", new IfHandler());
nodeHandlerMap.put("choose", new ChooseHandler());
nodeHandlerMap.put("when", new IfHandler());
nodeHandlerMap.put("otherwise", new OtherwiseHandler());
nodeHandlerMap.put("bind", new BindHandler());
}
}
其实源码中很清晰得体现,一共有 9 大动态 SQL 标签!Mybatis 在初始化解析配置文件的时候,会实例化这么一个标签节点的构造器,那么它本身就会提前把所有 Mybatis 支持的动态 SQL 标签对象对应的处理器给进行一个实例化,然后放到一个 Map 池子里头,而这些处理器,都是该类 XMLScriptBuilder 的一个匿名内部类,而匿名内部类的功能也很简单,就是解析处理对应类型的标签节点,在后续应用程序使用动态标签的时候,Mybatis 随时到 Map 池子中匹配对应的标签节点处理器,然后进解析即可。下面我们分别对这 9 大动态 SQL 标签进行介绍,排(gen)名(ju)不(wo)分(de)先(xi)后(hao):
Top1、if 标签
常用度:★★★★★
实用性:★★★★☆
if 标签,绝对算得上是一个伟大的标签,任何不支持流程控制(或语句控制)的应用程序,都是耍流氓,几乎都不具备现实意义,实际的应用场景和流程必然存在条件的控制与流转,而 if 标签在 单条件分支判断 应用场景中就起到了舍我其谁的作用,语法很简单,如果满足,则执行,不满足,则忽略/跳过。
- if 标签 : 内嵌于 select / delete / update / insert 标签,如果满足 test 属性的条件,则执行代码块
- test 属性 :作为 if 标签的属性,用于条件判断,使用 OGNL 表达式。
举个例子:
<select id="findUser">
select * from User where 1=1
<if test=" age != null ">
and age > #{age}
if>
<if test=" name != null ">
and name like concat(#{name},'%')
if>
select>
很明显,if 标签元素常用于包含 where 子句的条件拼接,它相当于 Java 中的 if 语句,和 test 属性搭配使用,通过判断参数值来决定是否使用某个查询条件,也可用于 Update 语句中判断是否更新某个字段,或用于 Insert 语句中判断是否插入某个字段的值。
每一个 if 标签在进行单条件判断时,需要把判断条件设置在 test 属性中,这是一个常见的应用场景,我们常用的用户查询系统功能中,在前端一般提供很多可选的查询项,支持性别筛选、年龄区间筛查、姓名模糊匹配等,那么我们程序中接收用户输入之后,Mybatis 的动态 SQL 节省我们很多工作,允许我们在代码层面不进行参数逻辑处理和 SQL 拼接,而是把参数传入到 SQL 中进行条件判断动态处理,我们只需要把精力集中在 XML 的维护上,既灵活也方便维护,可读性还强。
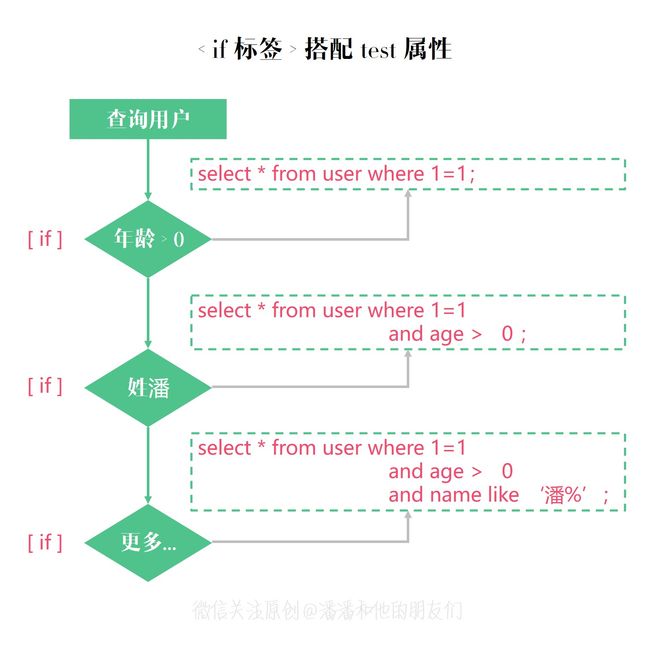
有些心细的朋友可能就发现一个问题,为什么 where 语句会添加一个 1=1 呢?其实我们是为了方便拼接后面符合条件的 if 标签语句块,否则没有 1=1 的话我们拼接的 SQL 就会变成 select * from user where and age > 0 , 显然这不是我们期望的结果,当然也不符合 SQL 的语法,数据库也不可能执行成功,所以我们投机取巧添加了 1=1 这个语句,但是始终觉得多余且没必要,Mybatis 也考虑到了,所以等会我们讲 where 标签,它是如何完美解决这个问题的。
注意:if 标签作为单条件分支判断,只能控制与非此即彼的流程,例如以上的例子,如果年龄 age 和姓名 name 都不存在,那么系统会把所有结果都查询出来,但有些时候,我们希望系统更加灵活,能有更多的流程分支,例如像我们 Java 当中的 if else 或 switch case default,不仅仅只有一个条件分支,所以接下来我们介绍 choose 标签,它就能满足多分支判断的应用场景。
Top2、choose 标签、when 标签、otherwise 标签
常用度:★★★★☆
实用性:★★★★☆
有些时候,我们并不希望条件控制是非此即彼的,而是希望能提供多个条件并从中选择一个,所以贴心的 Mybatis 提供了 choose 标签元素,类似我们 Java 当中的 if else 或 switch case default,choose 标签必须搭配 when 标签和 otherwise 标签使用,验证条件依然是使用 test 属性进行验证。
- choose 标签:顶层的多分支标签,单独使用无意义
- when 标签:内嵌于 choose 标签之中,当满足某个 when 条件时,执行对应的代码块,并终止跳出 choose 标签,choose 中必须至少存在一个 when 标签,否则无意义
- otherwise 标签:内嵌于 choose 标签之中,当不满足所有 when 条件时,则执行 otherwise 代码块,choose 中 至多 存在一个 otherwise 标签,可以不存在该标签
- test 属性 :作为 when 与 otherwise 标签的属性,作为条件判断,使用 OGNL 表达式
依据下面的例子,当应用程序输入年龄 age 或者姓名 name 时,会执行对应的 when 标签内的代码块,如果 when 标签的年龄 age 和姓名 name 都不满足,则会拼接 otherwise 标签内的代码块。
<select id="findUser">
select * from User where 1=1
<choose>
<when test=" age != null ">
and age > #{age}
when>
<when test=" name != null ">
and name like concat(#{name},'%')
when>
<otherwise>
and sex = '男'
otherwise>
choose>
select>
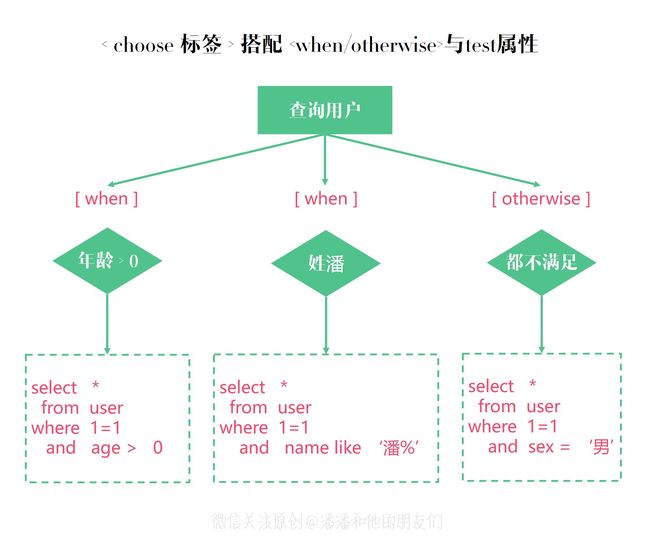
很明显,choose 标签作为多分支条件判断,提供了更多灵活的流程控制,同时 otherwise 的出现也为程序流程控制兜底,有时能够避免部分系统风险、过滤部分条件、避免当程序没有匹配到条件时,把整个数据库资源全部查询或更新。
至于为何 choose 标签这么棒棒,而常用度还是比 if 标签少了一颗星呢?原因也简单,因为 choose 标签的很多使用场景可以直接用 if 标签代替。另外据我统计,if 标签在实际业务应用当中,也要多于 choose 标签,大家也可以具体核查自己的应用程序中动态 SQL 标签的占比情况,统计分析一下。
Top3、foreach 标签
常用度:★★★☆☆
实用性:★★★★☆
有些场景,可能需要查询 id 在 1 ~ 100 的用户记录
有些场景,可能需要批量插入 100 条用户记录
有些场景,可能需要更新 500 个用户的姓名
有些场景,可能需要你删除 10 条用户记录
请问大家:
很多增删改查场景,操作对象都是集合/列表
如果是你来设计支持 Mybatis 的这一类集合/列表遍历场景,你会提供什么能力的标签来辅助构建你的 SQL 语句从而去满足此类业务场景呢?

额(⊙o⊙)…
那如果一定要用 Mybatis 框架呢?

没错,确实 Mybatis 提供了 foreach 标签来处理这几类需要遍历集合的场景,foreach 标签作为一个循环语句,他能够很好的支持数组、Map、或实现了 Iterable 接口(List、Set)等,尤其是在构建 in 条件语句的时候,我们常规的用法都是 id in (1,2,3,4,5 … 100) ,理论上我们可以在程序代码中拼接字符串然后通过 ${ ids } 方式来传值获取,但是这种方式不能防止 SQL 注入风险,同时也特别容易拼接错误,所以我们此时就需要使用 #{} + foreach 标签来配合使用,以满足我们实际的业务需求。譬如我们传入一个 List 列表查询 id 在 1 ~ 100 的用户记录:
<select id="findAll">
select * from user where ids in
<foreach collection="list"
item="item" index="index"
open="(" separator="," close=")">
#{item}
foreach>
select>
最终拼接完整的语句就变成:
select * from user where ids in (1,2,3,...,100);
当然你也可以这样编写:
<select id="findAll">
select * from user where
<foreach collection="list"
item="item" index="index"
open=" " separator=" or " close=" ">
id = #{item}
foreach>
select>
最终拼接完整的语句就变成:
select * from user where id =1 or id =2 or id =3 ... or id = 100;
在数据量大的情况下这个性能会比较尴尬,这里仅仅做一个用法的举例。所以经过上面的举栗,相信大家也基本能猜出 foreach 标签元素的基本用法:
- foreach 标签:顶层的遍历标签,单独使用无意义
- collection 属性:必填,Map 或者数组或者列表的属性名(不同类型的值获取下面会讲解)
- item 属性:变量名,值为遍历的每一个值(可以是对象或基础类型),如果是对象那么依旧是 OGNL 表达式取值即可,例如 #{item.id} 、#{ user.name } 等
- index 属性:索引的属性名,在遍历列表或数组时为当前索引值,当迭代的对象时 Map 类型时,该值为 Map 的键值(key)
- open 属性:循环内容开头拼接的字符串,可以是空字符串
- close 属性:循环内容结尾拼接的字符串,可以是空字符串
- separator 属性:每次循环的分隔符
第一,当传入的参数为 List 对象时,系统会默认添加一个 key 为 ‘list’ 的值,把列表内容放到这个 key 为 list 的集合当中,在 foreach 标签中可以直接通过 collection=“list” 获取到 List 对象,无论你传入时使用 kkk 或者 aaa ,都无所谓,系统都会默认添加一个 key 为 list 的值,并且 item 指定遍历的对象值,index 指定遍历索引值。
// java 代码
List kkk = new ArrayList();
kkk.add(1);
kkk.add(2);
...
kkk.add(100);
sqlSession.selectList("findAll",kkk);
<select id="findAll">
select * from user where ids in
<foreach collection="list"
item="item" index="index"
open="(" separator="," close=")">
#{item}
foreach>
select>
第二,当传入的参数为数组时,系统会默认添加一个 key 为 ‘array’ 的值,把列表内容放到这个 key 为 array 的集合当中,在 foreach 标签中可以直接通过 collection=“array” 获取到数组对象,无论你传入时使用 ids 或者 aaa ,都无所谓,系统都会默认添加一个 key 为 array 的值,并且 item 指定遍历的对象值,index 指定遍历索引值。
// java 代码
String [] ids = new String[3];
ids[0] = "1";
ids[1] = "2";
ids[2] = "3";
sqlSession.selectList("findAll",ids);
<select id="findAll">
select * from user where ids in
<foreach collection="array"
item="item" index="index"
open="(" separator="," close=")">
#{item}
foreach>
select>
第三,当传入的参数为 Map 对象时,系统并 不会 默认添加一个 key 值,需要手工传入,例如传入 key 值为 map2 的集合对象,在 foreach 标签中可以直接通过 collection=“map2” 获取到 Map 对象,并且 item 代表每次迭代的的 value 值,index 代表每次迭代的 key 值。其中 item 和 index 的值名词可以随意定义,例如 item = “value111”,index =“key111”。
// java 代码
Map map2 = new HashMap<>();
map2.put("k1",1);
map2.put("k2",2);
map2.put("k3",3);
Map map1 = new HashMap<>();
map1.put("map2",map2);
sqlSession.selectList("findAll",map1);
挺闹心,map1 套着 map2,才能在 foreach 的 collection 属性中获取到。
<select id="findAll">
select * from user where
<foreach collection="map2"
item="value111" index="key111"
open=" " separator=" or " close=" ">
id = #{value111}
foreach>
select>
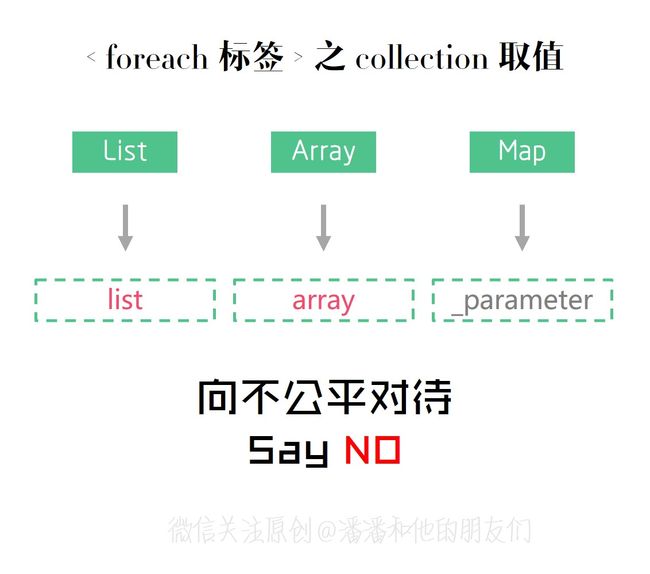
可能你会觉得 Map 受到不公平对待,为何 map 不能像 List 或者 Array 一样,在框架默认设置一个 ‘map’ 的 key 值呢?但其实不是不公平,而是我们在 Mybatis 框架中,所有传入的任何参数都会供上下文使用,于是参数会被统一放到一个内置参数池子里面,这个内置参数池子的数据结构是一个 map 集合,而这个 map 集合可以通过使用 “_parameter” 来获取,所有 key 都会存储在 _parameter 集合中,因此:
- 当你传入的参数是一个 list 类型时,那么这个参数池子需要有一个 key 值,以供上下文获取这个 list 类型的对象,所以默认设置了一个 ‘list’ 字符串作为 key 值,获取时通过使用 _parameter.list 来获取,一般使用 list 即可。
- 同样的,当你传入的参数是一个 array 数组时,那么这个参数池子也会默认设置了一个 ‘array’ 字符串作为 key 值,以供上下文获取这个 array 数组的对象值,获取时通过使用 _parameter.array 来获取,一般使用 array 即可。
- 但是!当你传入的参数是一个 map 集合类型时,那么这个参数池就没必要为你添加默认 key 值了,因为 map 集合类型本身就会有很多 key 值,例如你想获取 map 参数的某个 key 值,你可以直接使用 _parameter.name 或者 _parameter.age 即可,就没必要还用 _parameter.map.name 或者 _parameter.map.age ,所以这就是 map 参数类型无需再构建一个 ‘map’ 字符串作为 key 的原因,对象类型也是如此,例如你传入一个 User 对象。
因此,如果是 Map 集合,你可以这么使用:
// java 代码
Map map2 = new HashMap<>();
map2.put("k1",1);
map2.put("k2",2);
map2.put("k3",3);
sqlSession.selectList("findAll",map2);
直接使用 collection="_parameter",你会发现神奇的 key 和 value 都能通过 _parameter 遍历在 index 与 item 之中。
<select id="findAll">
select * from user where
<foreach collection="_parameter"
item="value111" index="key111"
open=" " separator=" or " close=" ">
id = #{value111}
foreach>
select>
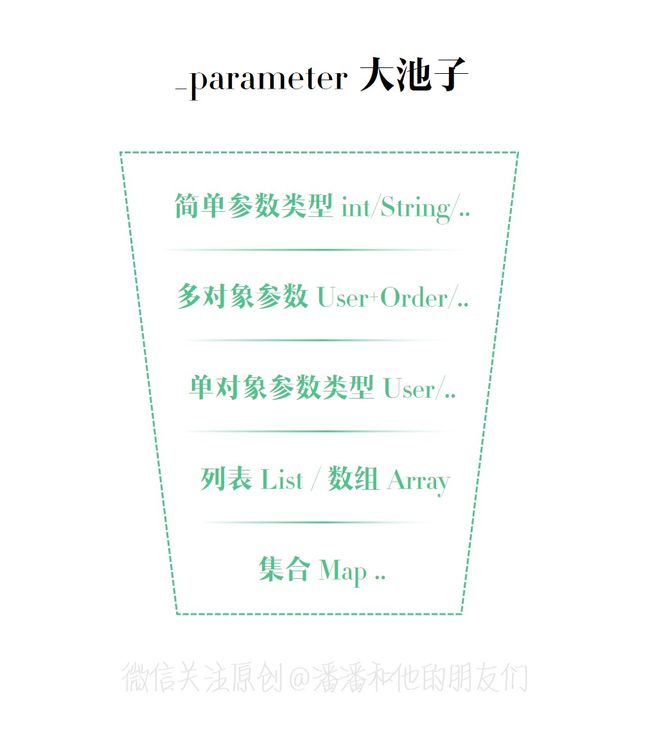
延伸:当传入参数为多个对象时,例如传入 User 和 Room 等,那么通过内置参数获取对象可以使用 _parameter.get(0).username,或者 _parameter.get(1).roomname 。假如你传入的参数是一个简单数据类型,例如传入 int =1 或者 String = ‘你好’,那么都可以直接使用 _parameter 代替获取值即可,这就是很多人会在动态 SQL 中直接使用 # { _parameter } 来获取简单数据类型的值。
那到这里,我们基本把 foreach 基本用法介绍完成,不过以上只是针对查询的使用场景,对于删除、更新、插入的用法,也是大同小异,我们简单说一下,如果你希望批量插入 100 条用户记录:
<insert id="insertUser" parameterType="java.util.List">
insert into user(id,username) values
<foreach collection="list"
item="user" index="index"
separator="," close=";" >
(#{user.id},#{user.username})
foreach>
insert>
如果你希望更新 500 个用户的姓名:
<update id="updateUser" parameterType="java.util.List">
update user
set username = '潘潘'
where id in
<foreach collection="list"
item="user" index="index"
separator="," open="(" close=")" >
#{user.id}
foreach>
update>
如果你希望你删除 10 条用户记录:
<delete id="deleteUser" parameterType="java.util.List">
delete from user
where id in
<foreach collection="list"
item="user" index="index"
separator="," open="(" close=")" >
#{user.id}
foreach>
delete>
更多玩法,期待你自己去挖掘!

注意:使用 foreach 标签时,需要对传入的 collection 参数(List/Map/Set等)进行为空性判断,否则动态 SQL 会出现语法异常,例如你的查询语句可能是 select * from user where ids in () ,导致以上语法异常就是传入参数为空,解决方案可以用 if 标签或 choose 标签进行为空性判断处理,或者直接在 Java 代码中进行逻辑处理即可,例如判断为空则不执行 SQL 。
Top4、where 标签、set 标签
常用度:★★☆☆☆
实用性:★★★★☆
我们把 where 标签和 set 标签放置一起讲解,一是这两个标签在实际应用开发中常用度确实不分伯仲,二是这两个标签出自一家,都继承了 trim 标签,放置一起方便我们比对追根。(其中底层原理会在第4部分详细讲解)

之前我们介绍 if 标签的时候,相信大家都已经看到,我们在 where 子句后面拼接了 1=1 的条件语句块,目的是为了保证后续条件能够正确拼接,以前在程序代码中使用字符串拼接 SQL 条件语句常常如此使用,但是确实此种方式不够体面,也显得我们不高级。
<select id="findUser">
select * from User where 1=1
<if test=" age != null ">
and age > #{age}
if>
<if test=" name != null ">
and name like concat(#{name},'%')
if>
select>
以上是我们使用 1=1 的写法,那 where 标签诞生之后,是怎么巧妙处理后续的条件语句的呢?
<select id="findUser">
select * from User
<where>
<if test=" age != null ">
and age > #{age}
if>
<if test=" name != null ">
and name like concat(#{name},'%')
if>
where>
select>
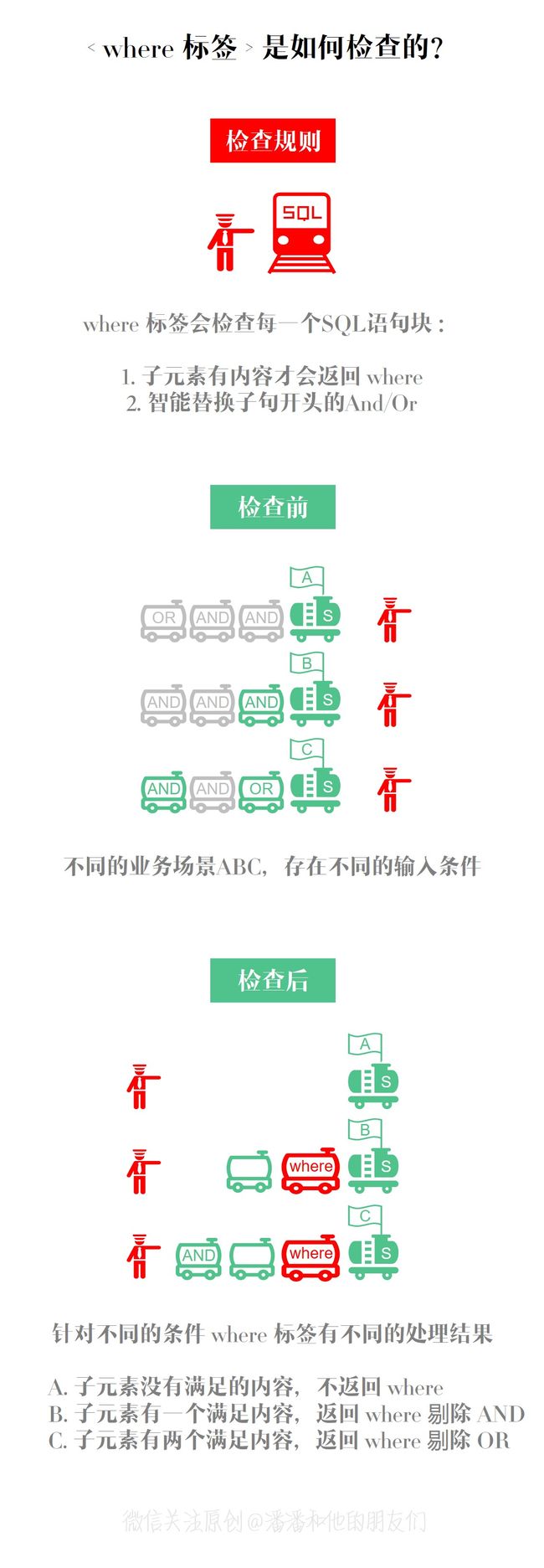
我们只需把 where 关键词以及 1=1 改为 < where > 标签即可,另外还有一个特殊的处理能力,就是 where 标签能够智能的去除(忽略)首个满足条件语句的前缀,例如以上条件如果 age 和 name 都满足,那么 age 前缀 and 会被智能去除掉,无论你是使用 and 运算符或是 or 运算符,Mybatis 框架都会帮你智能处理。
用法特别简单,我们用官术总结一下:
- where 标签:顶层的遍历标签,需要配合 if 标签使用,单独使用无意义,并且只会在子元素(如 if 标签)返回任何内容的情况下才插入 WHERE 子句。另外,若子句的开头为 “AND” 或 “OR”,where 标签也会将它替换去除。
了解了基本用法之后,我们再看看刚刚我们的例子中:
<select id="findUser">
select * from User
<where>
<if test=" age != null ">
and age > #{age}
if>
<if test=" name != null ">
and name like concat(#{name},'%')
if>
where>
select>
如果 age 传入有效值 10 ,满足 age != null 的条件之后,那么就会返回 where 标签并去除首个子句运算符 and,最终的 SQL 语句会变成:
select * from User where age > 10;
-- and 巧妙的不见了
值得注意的是,where 标签 只会 智能的去除(忽略)首个满足条件语句的前缀,所以就建议我们在使用 where 标签的时候,每个语句都最好写上 and 前缀或者 or 前缀,否则像以下写法就很有可能出大事:
<select id="findUser">
select * from User
<where>
<if test=" age != null ">
age > #{age}
if>
<if test=" name != null ">
name like concat(#{name},'%')
if>
where>
select>
当 age 传入 10,name 传入 ‘潘潘’ 时,最终的 SQL 语句是:
select * from User
where
age > 10
name like concat('潘%')
-- 所有条件都没有and或or运算符
-- 这让age和name显得很尴尬~
由于 name 前缀没有写 and 或 or 连接符,而 where 标签又不会智能的去除(忽略)非首个 满足条件语句的前缀,所以当 age 条件语句与 name 条件语句同时成立时,就会导致语法错误,这个需要谨慎使用,格外注意!原则上每个条件子句都建议在句首添加运算符 and 或 or ,首个条件语句可添加可不加。
另外还有一个值得注意的点,我们使用 XML 方式配置 SQL 时,如果在 where 标签之后添加了注释,那么当有子元素满足条件时,除了 < !-- --> 注释会被 where 忽略解析以外,其它注释例如 // 或 /**/ 或 – 等都会被 where 当成首个子句元素处理,导致后续真正的首个 AND 子句元素或 OR 子句元素没能被成功替换掉前缀,从而引起语法错误!

基于 where 标签元素的讲解,有助于我们快速理解 set 标签元素,毕竟它俩是如此相像。我们回忆一下以往我们的更新 SQL 语句:
<update id="updateUser">
update user
set age = #{age},
username = #{username},
password = #{password}
where id =#{id}
update>
以上语句是我们日常用于更新指定 id 对象的 age 字段、 username 字段以及 password 字段,但是很多时候,我们可能只希望更新对象的某些字段,而不是每次都更新对象的所有字段,这就使得我们在语句结构的构建上显得惨白无力。于是有了 set 标签元素。
用法与 where 标签元素相似:
- set 标签:顶层的遍历标签,需要配合 if 标签使用,单独使用无意义,并且只会在子元素(如 if 标签)返回任何内容的情况下才插入 set 子句。另外,若子句的 开头或结尾 都存在逗号 “,” 则 set 标签都会将它替换去除。

根据此用法我们可以把以上的例子改为:
<update id="updateUser">
update user
<set>
<if test="age !=null">
age = #{age},
if>
<if test="username !=null">
username = #{username},
if>
<if test="password !=null">
password = #{password},
if>
set>
where id =#{id}
update>
很简单易懂,set 标签会智能拼接更新字段,以上例子如果传入 age =10 和 username = ‘潘潘’ ,则有两个字段满足更新条件,于是 set 标签会智能拼接 " age = 10 ," 和 “username = ‘潘潘’ ,” 。其中由于后一个 username 属于最后一个子句,所以末尾逗号会被智能去除,最终的 SQL 语句是:
update user set age = 10,username = '潘潘'
另外需要注意,set 标签下需要保证至少有一个条件满足,否则依然会产生语法错误,例如在无子句条件满足的场景下,最终的 SQL 语句会是这样:
update user ; ( oh~ no!)
既不会添加 set 标签,也没有子句更新字段,于是语法出现了错误,所以类似这类情况,一般需要在应用程序中进行逻辑处理,判断是否存在至少一个参数,否则不执行更新 SQL 。所以原则上要求 set 标签下至少存在一个条件满足,同时每个条件子句都建议在句末添加逗号 ,最后一个条件语句可加可不加。或者 每个条件子句都在句首添加逗号 ,第一个条件语句可加可不加,例如:
<update id="updateUser">
update user
<set>
<if test="age !=null">
,age = #{age}
if>
<if test="username !=null">
,username = #{username}
if>
<if test="password !=null">
,password = #{password}
if>
set>
where id =#{id}
update>
与 where 标签相同,我们使用 XML 方式配置 SQL 时,如果在 set 标签子句末尾添加了注释,那么当有子元素满足条件时,除了 < !-- --> 注释会被 set 忽略解析以外,其它注释例如 // 或 /**/ 或 – 等都会被 set 标签当成末尾子句元素处理,导致后续真正的末尾子句元素的逗号没能被成功替换掉后缀,从而引起语法错误!

到此,我们的 where 标签元素与 set 标签就基本介绍完成,它俩确实极为相似,区别仅在于:
- where 标签插入前缀 where
- set 标签插入前缀 set
- where 标签仅智能替换前缀 AND 或 OR
- set 标签可以只能替换前缀逗号,或后缀逗号,
而这两者的前后缀去除策略,都源自于 trim 标签的设计,我们一起看看到底 trim 标签是有多灵活!
Top5、trim 标签
常用度:★☆☆☆☆
实用性:★☆☆☆☆
上面我们介绍了 where 标签与 set 标签,它俩的共同点无非就是前置关键词 where 或 set 的插入,以及前后缀符号(例如 AND | OR | ,)的智能去除。基于 where 标签和 set 标签本身都继承了 trim 标签,所以 trim 标签的大致实现我们也能猜出个一二三。
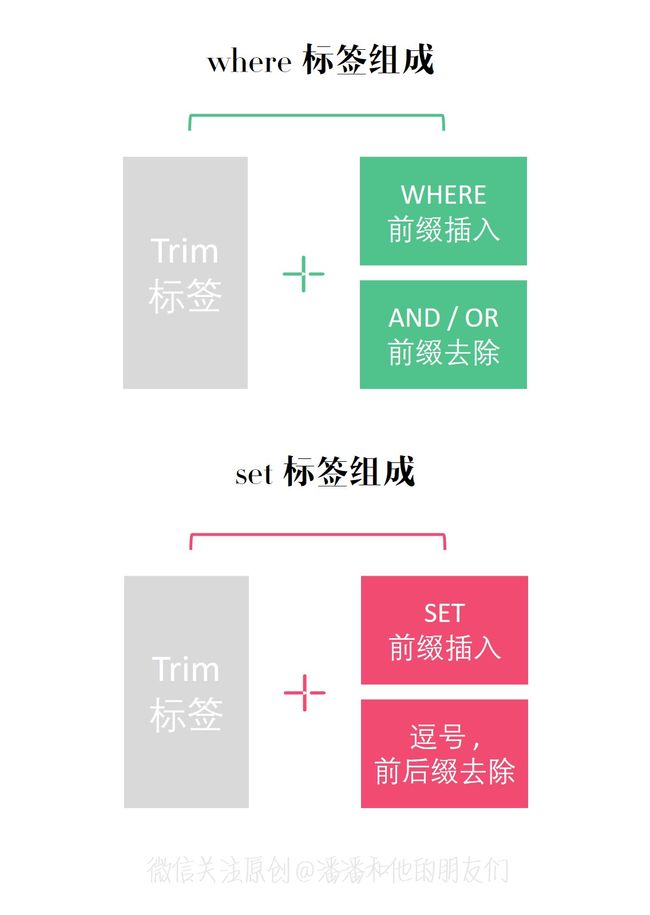
其实 where 标签和 set 标签都只是 trim 标签的某种实现方案,trim 标签底层是通过 TrimSqlNode 类来实现的,它有几个关键属性:
- prefix :前缀,当 trim 元素内存在内容时,会给内容插入指定前缀
- suffix :后缀,当 trim 元素内存在内容时,会给内容插入指定后缀
- prefixesToOverride :前缀去除,支持多个,当 trim 元素内存在内容时,会把内容中匹配的前缀字符串去除。
- suffixesToOverride :后缀去除,支持多个,当 trim 元素内存在内容时,会把内容中匹配的后缀字符串去除。
所以 where 标签如果通过 trim 标签实现的话可以这么编写:(
<trim prefix="WHERE" prefixOverrides="AND | OR" >
...
trim>
而 set 标签如果通过 trim 标签实现的话可以这么编写:
<trim prefix="SET" prefixOverrides="," >
...
trim>
或者
<trim prefix="SET" suffixesToOverride="," >
...
trim>
所以可见 trim 是足够灵活的,不过由于 where 标签和 set 标签这两种 trim 标签变种方案已经足以满足我们实际开发需求,所以直接使用 trim 标签的场景实际上不太很多(其实是我自己使用的不多,基本没用过)。
注意,set 标签之所以能够支持去除前缀逗号或者后缀逗号,是由于其在构造 trim 标签的时候进行了前缀后缀的去除设置,而 where 标签在构造 trim 标签的时候就仅仅设置了前缀去除。
set 标签元素之构造时:
// Set 标签
public class SetSqlNode extends TrimSqlNode {
private static final List<String> COMMA = Collections.singletonList(",");
// 明显使用了前缀后缀去除,注意前后缀参数都传入了 COMMA
public SetSqlNode(Configuration configuration,SqlNode contents) {
super(configuration, contents, "SET", COMMA, null, COMMA);
}
}
where 标签元素之构造时:
// Where 标签
public class WhereSqlNode extends TrimSqlNode {
// 其实包含了很多种场景
private static List<String> prefixList = Arrays.asList("AND ","OR ","AND\n", "OR\n", "AND\r", "OR\r", "AND\t", "OR\t");
// 明显只使用了前缀去除,注意前缀传入 prefixList,后缀传入 null
public WhereSqlNode(Configuration configuration, SqlNode contents) {
super(configuration, contents, "WHERE", prefixList, null, null);
}
}
Top6、bind 标签
常用度:☆☆☆☆☆
实用性:★☆☆☆☆
简单来说,这个标签就是可以创建一个变量,并绑定到上下文,即供上下文使用,就是这样,我把官网的例子直接拷贝过来:
<select id="selecUser">
<bind name="myName" value="'%' + _parameter.getName() + '%'" />
SELECT * FROM user
WHERE name LIKE #{myName}
select>
大家应该大致能知道以上例子的功效,其实就是辅助构建模糊查询的语句拼接,那有人就好奇了,为啥不直接拼接语句就行了,为什么还要搞出一个变量,绕一圈呢?

我先问一个问题:平时你使用 mysql 都是如何拼接模糊查询 like 语句的?
select * from user where name like concat('%',#{name},'%')
确实如此,但如果有一天领导跟你说数据库换成 oracle 了,怎么办?上面的语句还能用吗?明显用不了,不能这么写,因为 oracle 虽然也有 concat 函数,但是只支持连接两个字符串,例如你最多这么写:
select * from user where name like concat('%',#{name})
但是少了右边的井号符号,所以达不到你预期的效果,于是你改成这样:
select * from user where name like '%'||#{name}||'%'
确实可以了,但是过几天领导又跟你说,数据库换回 mysql 了?额… 那不好意思,你又得把相关使用到模糊查询的地方改回来。
select * from user where name like concat('%',#{name},'%')
很显然,数据库只要发生变更你的 sql 语句就得跟着改,特别麻烦,所以才有了一开始我们介绍 bind 标签官网的这个例子,无论使用哪种数据库,这个模糊查询的 Like 语法都是支持的:
<select id="selecUser">
<bind name="myName" value="'%' + _parameter.getName() + '%'" />
SELECT * FROM user
WHERE name LIKE #{myName}
select>
这个 bind 的用法,实打实解决了数据库重新选型后导致的一些问题,当然在实际工作中发生的概率不会太大,所以 bind 的使用我个人确实也使用的不多,可能还有其它一些应用场景,希望有人能发现之后来跟我们分享一下,总之我勉强给了一颗星(虽然没太多实际用处,但毕竟要给点面子)。
拓展:sql标签 + include 标签
常用度:★★★☆☆
实用性:★★★☆☆
sql 标签与 include 标签组合使用,用于 SQL 语句的复用,日常高频或公用使用的语句块可以抽取出来进行复用,其实我们应该不陌生,早期我们学习 JSP 的时候,就有一个 include 标记可以引入一些公用可复用的页面文件,例如页面头部或尾部页面代码元素,这种复用的设计很常见。
严格意义上 sql 、include 不算在动态 SQL 标签成员之内,只因它确实是宝藏般的存在,所以我要简单说说,sql 标签用于定义一段可重用的 SQL 语句片段,以便在其它语句中使用,而 include 标签则通过属性 refid 来引用对应 id 匹配的 sql 标签语句片段。
简单的复用代码块可以是:
<sql id="userColumns">
id,username,password
sql>
查询或插入时简单复用:
<select id="selectUsers" resultType="map">
select
<include refid="userColumns">include>
from user
select>
<insert id="insertUser" resultType="map">
insert into user(
<include refid="userColumns">include>
)values(
#{id},#{username},#{password}
)
insert>
当然,复用语句还支持属性传递,例如:
<sql id="userColumns">
${pojo}.id,${pojo}.username
sql>
这个 SQL 片段可以在其它语句中使用:
<select id="selectUsers" resultType="map">
select
<include refid="userColumns">
<property name="pojo" value="u1"/>
include>,
<include refid="userColumns">
<property name="pojo" value="u2"/>
include>
from user u1 cross join user u2
select>
也可以在 include 元素的 refid 属性或多层内部语句中使用属性值,属性可以穿透传递,例如:
<sql id="sql1">
${prefix}_user
sql>
<sql id="sql2">
from
<include refid="${include_target}"/>
sql>
<select id="select" resultType="map">
select
id, username
<include refid="sql2">
<property name="prefix" value="t"/>
<property name="include_target" value="sql1"/>
include>
select>
至此,关于 9 大动态 SQL 标签的基本用法我们已介绍完毕,另外我们还有一些疑问:Mybatis 底层是如何解析这些动态 SQL 标签的呢?最终又是怎么构建完整可执行的 SQL 语句的呢?带着这些疑问,我们在第4节中详细分析。


4、动态SQL的底层原理
想了解 Mybatis 究竟是如何解析与构建动态 SQL ?首先推荐的当然是读源码,而读源码,是一个技术钻研问题,为了借鉴学习,为了工作储备,为了解决问题,为了让自己在编程的道路上跑得明白一些… 而希望通过读源码,去了解底层实现原理,切记不能脱离了整体去读局部,否则你了解到的必然局限且片面,从而轻忽了真核上的设计。如同我们读史或者观宇宙一样,最好的办法都是从整体到局部,不断放大,前后延展,会很舒服通透。所以我准备从 Mybatis 框架的核心主线上去逐步放大剖析。
通过前面几篇文章的介绍(建议阅读 Mybatis 系列全解之六:《Mybatis 最硬核的 API 你知道几个?》),其实我们知道了 Mybatis 框架的核心部分在于构件的构建过程,从而支撑了外部应用程序的使用,从应用程序端创建配置并调用 API 开始,到框架端加载配置并初始化构件,再创建会话并接收请求,然后处理请求,最终返回处理结果等。

我们的动态 SQL 解析部分就发生在 SQL 语句对象 MappedStatement 构建时(上左高亮橘色部分,注意观察其中 SQL 语句对象与 SqlSource 、 BoundSql 的关系,在动态 SQL 解析流程特别关键)。我们再拉近一点,可以看到无论是使用 XML 配置 SQL 语句或是使用注解方式配置 SQL 语句,框架最终都会把解析完成的 SQL 语句对象存放到 MappedStatement 语句集合池子。
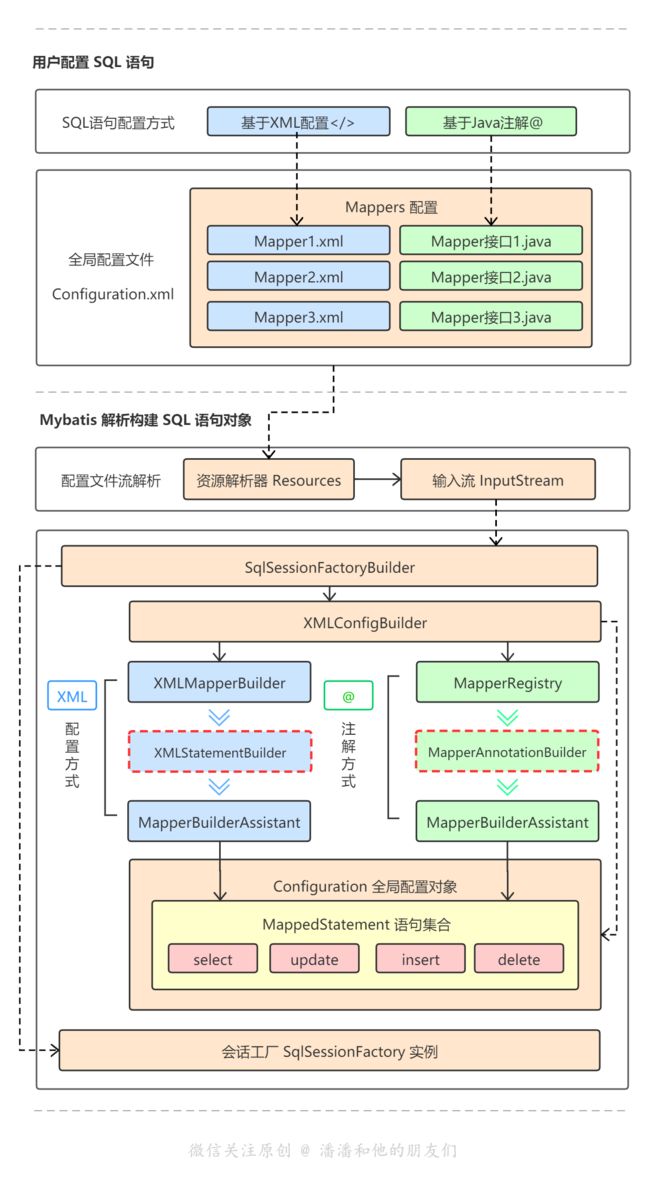
而以上虚线高亮部分,即是 XML 配置方式解析过程与注解配置方式解析过程中涉及到动态 SQL 标签解析的流程,我们分别讲解:
- 第一,XML 方式配置 SQL 语句,框架如何解析?

以上为 XML 配置方式的 SQL 语句解析过程,无论是单独使用 Mybatis 框架还是集成 Spring 与 Mybatis 框架,程序启动入口都会首先从 SqlSessionFactoryBuilder.build() 开始构建,依次通过 XMLConfigBuilder 构建全局配置 Configuration 对象、通过 XMLMapperBuilder 构建每一个 Mapper 映射器、通过 XMLStatementBuilder 构建映射器中的每一个 SQL 语句对象(select/insert/update/delete)。而就在解析构建每一个 SQL 语句对象时,涉及到一个关键的方法 parseStatementNode(),即上图橘红色高亮部分,此方法内部就出现了一个处理动态 SQL 的核心节点。
// XML配置语句构建器
public class XMLStatementBuilder {
// 实际解析每一个 SQL 语句
// 例如 select|insert|update|delete
public void parseStatementNode() {
// [忽略]参数构建...
// [忽略]缓存构建..
// [忽略]结果集构建等等..
// 【重点】此处即是处理动态 SQL 的核心!!!
String lang = context.getStringAttribute("lang");
LanguageDriver langDriver = getLanguageDriver(lang);
SqlSource sqlSource = langDriver.createSqlSource(..);
// [忽略]最后把解析完成的语句对象添加进语句集合池
builderAssistant.addMappedStatement(语句对象)
}
}
大家先重点关注一下这段代码,其中【重点】部分的 LanguageDriver 与 SqlSource 会是我们接下来讲解动态 SQL 语句解析的核心类,我们不着急剖析,我们先把注解方式流程也梳理对比一下。
- 第二,注解方式配置 SQL 语句,框架如何解析?
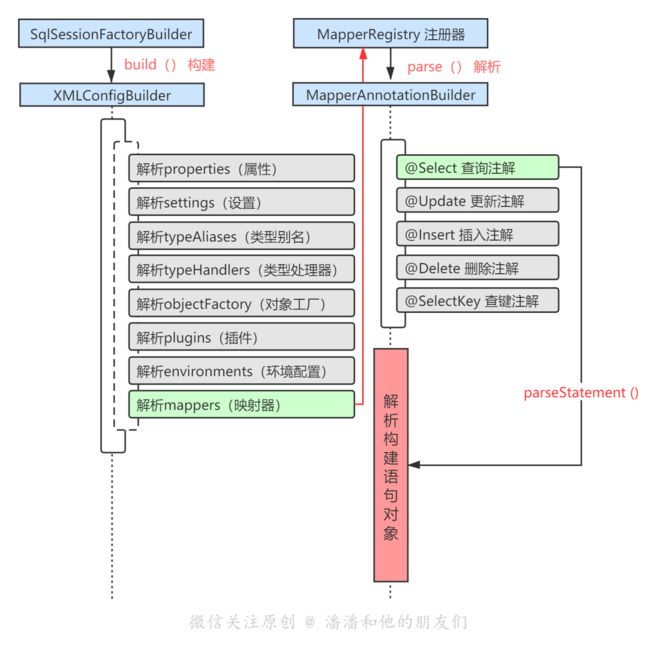
大家会发现注解配置方式的 SQL 语句解析过程,与 XML 方式极为相像,唯一不同点就在于解析注解 SQL 语句时,使用了 MapperAnnotationBuilder 构建器,其中关于每一个语句对象 (@Select,@Insert,@Update,@Delete等) 的解析,又都会通过一个关键解析方法 parseStatement(),即上图橘红色高亮部分,此方法内部同样的出现了一个处理动态 SQL 的核心节点。
// 注解配置语句构建器
public class MapperAnnotationBuilder {
// 实际解析每一个 SQL 语句
// 例如 @Select,@Insert,@Update,@Delete
void parseStatement(Method method) {
// [忽略]参数构建...
// [忽略]缓存构建..
// [忽略]结果集构建等等..
// 【重点】此处即是处理动态 SQL 的核心!!!
final LanguageDriver languageDriver = getLanguageDriver(method);
final SqlSource sqlSource = buildSqlSource( languageDriver,... );
// [忽略]最后把解析完成的语句对象添加进语句集合池
builderAssistant.addMappedStatement(语句对象)
}
}
由此可见,不管是通过 XML 配置语句还是注解方式配置语句,构建流程都是 大致相同,并且依然出现了我们在 XML 配置方式中涉及到的语言驱动 LanguageDriver 与语句源 SqlSource ,那这两个类/接口到底为何物,为何能让 SQL 语句解析者都如此绕不开 ?
这一切,得从你编写的 SQL 开始讲起 …
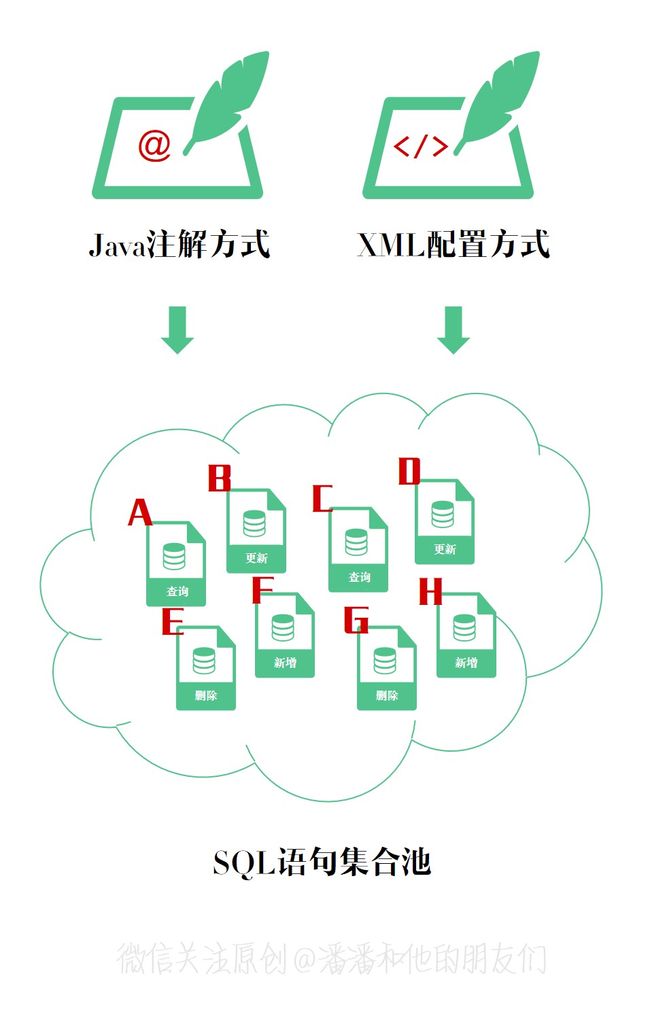
我们知道,无论 XML 还是注解,最终你的所有 SQL 语句对象都会被齐齐整整的解析完放置在 SQL 语句对象集合池中,以供执行器 Executor 具体执行增删改查 ( CRUD ) 时使用。而我们知道每一个 SQL 语句对象的属性,特别复杂繁多,例如超时设置、缓存、语句类型、结果集映射关系等等。
// SQL 语句对象
public final class MappedStatement {
private String resource;
private Configuration configuration;
private String id;
private Integer fetchSize;
private Integer timeout;
private StatementType statementType;
private ResultSetType resultSetType;
// SQL 源
private SqlSource sqlSource;
private Cache cache;
private ParameterMap parameterMap;
private List<ResultMap> resultMaps;
private boolean flushCacheRequired;
private boolean useCache;
private boolean resultOrdered;
private SqlCommandType sqlCommandType;
private KeyGenerator keyGenerator;
private String[] keyProperties;
private String[] keyColumns;
private boolean hasNestedResultMaps;
private String databaseId;
private Log statementLog;
private LanguageDriver lang;
private String[] resultSets;
}
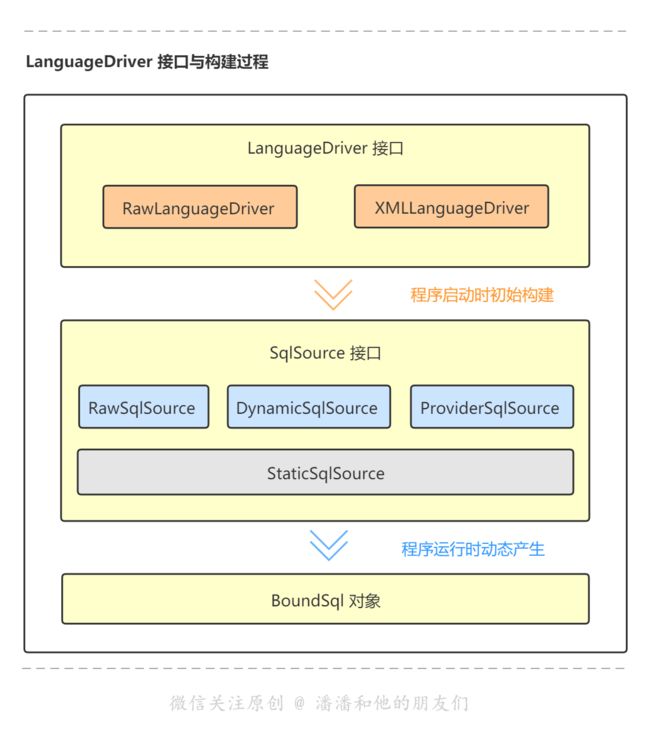
而其中有一个特别的属性就是我们的语句源 SqlSource ,功能纯粹也恰如其名 SQL 源。它是一个接口,它会结合用户传递的参数对象 parameterObject 与动态 SQL,生成 SQL 语句,并最终封装成 BoundSql 对象。SqlSource 接口有5个实现类,分别是:StaticSqlSource、DynamicSqlSource、RawSqlSource、ProviderSqlSource、VelocitySqlSource (而 velocitySqlSource 目前只是一个测试用例,还没有用作实际的 Sql 源实现)。
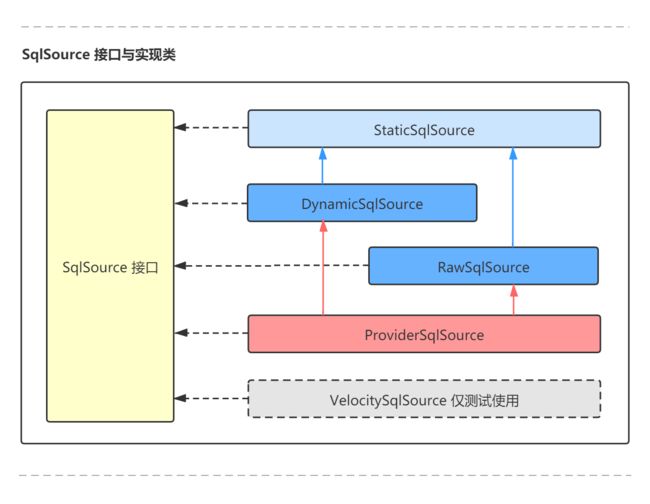
- StaticSqlSource:静态 SQL 源实现类,所有的 SQL 源最终都会构建成 StaticSqlSource 实例,该实现类会生成最终可执行的 SQL 语句供 statement 或 prepareStatement 使用。
- RawSqlSource:原生 SQL 源实现类,解析构建含有 ‘#{}’ 占位符的 SQL 语句或原生 SQL 语句,解析完最终会构建 StaticSqlSource 实例。
- DynamicSqlSource:动态 SQL 源实现类,解析构建含有 ‘${}’ 替换符的 SQL 语句或含有动态 SQL 的语句(例如 If/Where/Foreach等),解析完最终会构建 StaticSqlSource 实例。
- ProviderSqlSource:注解方式的 SQL 源实现类,会根据 SQL 语句的内容分发给 RawSqlSource 或 DynamicSqlSource ,当然最终也会构建 StaticSqlSource 实例。
- VelocitySqlSource:模板 SQL 源实现类,目前(V3.5.6)官方申明这只是一个测试用例,还没有用作真正的模板 Sql 源实现类。
SqlSource 实例在配置类 Configuration 解析阶段就被创建,Mybatis 框架会依据3个维度的信息来选择构建哪种数据源实例:(纯属我个人理解的归类梳理~)
- 第一个维度:客户端的 SQL 配置方式:XML 方式或者注解方式。
- 第二个维度:SQL 语句中是否使用动态 SQL ( if/where/foreach 等 )。
- 第三个维度:SQL 语句中是否含有替换符 ‘${}’ 或占位符 ‘#{}’ 。
SqlSource 接口只有一个方法 getBoundSql ,就是创建 BoundSql 对象。
public interface SqlSource {
BoundSql getBoundSql(Object parameterObject);
}
通过 SQL 源就能够获取 BoundSql 对象,从而获取最终送往数据库(通过JDBC)中执行的 SQL 字符串。
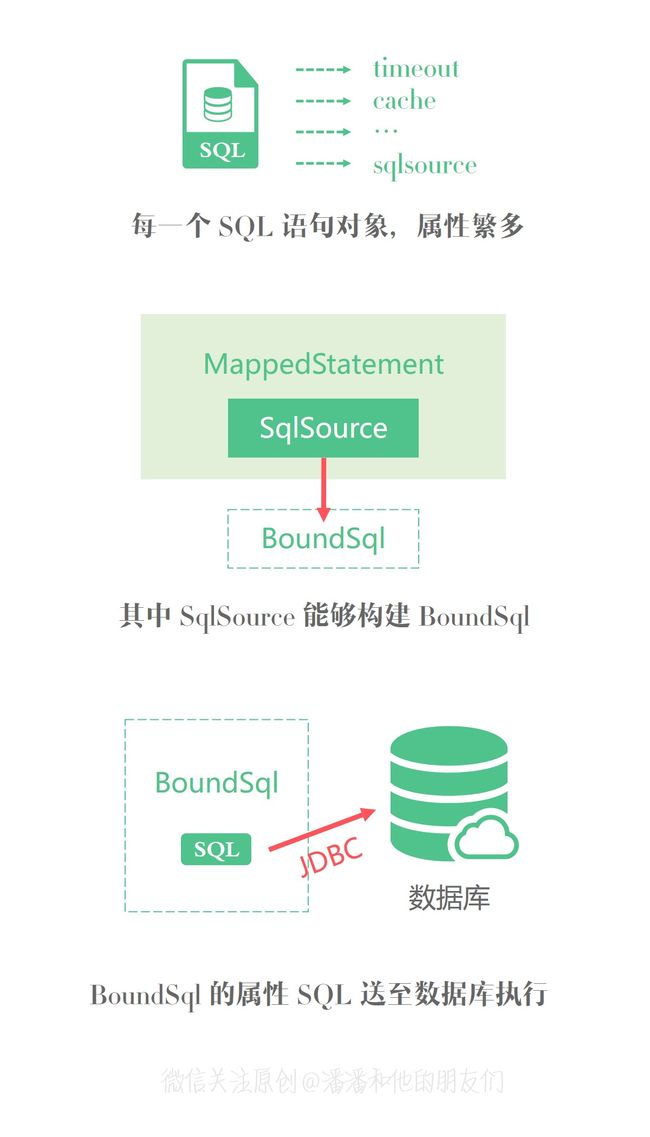
JDBC 中执行的 SQL 字符串,确实就在 BoundSql 对象中。BoundSql 对象存储了动态(或静态)生成的 SQL 语句以及相应的参数信息,它是在执行器具体执行 CURD 时通过实际的 SqlSource 实例所构建的。
public class BoundSql {
//该字段中记录了SQL语句,该SQL语句中可能含有"?"占位符
private final String sql;
//SQL中的参数属性集合
private final List<ParameterMapping> parameterMappings;
//客户端执行SQL时传入的实际参数值
private final Object parameterObject;
//复制 DynamicContext.bindings 集合中的内容
private final Map<String, Object> additionalParameters;
//通过 additionalParameters 构建元参数对象
private final MetaObject metaParameters;
}
在执行器 Executor 实例(例如BaseExecutor)执行增删改查时,会通过 SqlSource 构建 BoundSql 实例,然后再通过 BoundSql 实例获取最终输送至数据库执行的 SQL 语句,系统可根据 SQL 语句构建 Statement 或者 PrepareStatement ,从而送往数据库执行,例如语句处理器 StatementHandler 的执行过程。

墙裂推荐阅读之前第六文之 Mybatis 最硬核的 API 你知道几个?这些执行流程都有细讲。
到此我们介绍完 SQL 源 SqlSource 与 BoundSql 的关系,注意 SqlSource 与 BoundSql 不是同个阶段产生的,而是分别在程序启动阶段与运行时。
- 程序启动初始构建时,框架会根据 SQL 语句类型构建对应的 SqlSource 源实例(静态/动态).
- 程序实际运行时,框架会根据传入参数动态的构建 BoundSql 对象,输送最终 SQL 到数据库执行。
在上面我们知道了 SQL 源是语句对象 BoundSql 的属性,同时还坐拥5大实现类,那究竟是谁创建了 SQL 源呢?其实就是我们接下来准备介绍的语言驱动 LanguageDriver !
public interface LanguageDriver {
SqlSource createSqlSource(...);
}
语言驱动接口 LanguageDriver 也是极简洁,内部定义了构建 SQL 源的方法,LanguageDriver 接口有2个实现类,分别是: XMLLanguageDriver 、 RawLanguageDriver。简单介绍一下:
- XMLLanguageDriver :是框架默认的语言驱动,能够根据上面我们讲解的 SQL 源的3个维度创建对应匹配的 SQL 源(DynamicSqlSource、RawSqlSource等)。下面这段代码是 Mybatis 在装配全局配置时的一些跟语言驱动相关的动作,我摘抄出来,分别有:内置了两种语言驱动并设置了别名方便引用、注册了两种语言驱动至语言注册工厂、把 XML 语言驱动设置为默认语言驱动。
// 全局配置的构造方法
public Configuration() {
// 内置/注册了很多有意思的【别名】
// ...
// 其中就内置了上述的两种语言驱动【别名】
typeAliasRegistry.registerAlias("XML", XMLLanguageDriver.class);
typeAliasRegistry.registerAlias("RAW", RawLanguageDriver.class);
// 注册了XML【语言驱动】 --> 并设置成默认!
languageRegistry.setDefaultDriverClass(XMLLanguageDriver.class);
// 注册了原生【语言驱动】
languageRegistry.register(RawLanguageDriver.class);
}
- RawLanguageDriver :看名字得知是原生语言驱动,事实也如此,它只能创建原生 SQL 源(RawSqlSource),另外它还继承了 XMLLanguageDriver 。
/**
* As of 3.2.4 the default XML language is able to identify static statements
* and create a {@link RawSqlSource}. So there is no need to use RAW unless you
* want to make sure that there is not any dynamic tag for any reason.
*
* @since 3.2.0
* @author Eduardo Macarron
*/
public class RawLanguageDriver extends XMLLanguageDriver {
}
注释的大致意思:自 Mybatis 3.2.4 之后的版本, XML 语言驱动就支持解析静态语句(动态语句当然也支持)并创建对应的 SQL 源(例如静态语句是原生 SQL 源),所以除非你十分确定你的 SQL 语句中没有包含任何一款动态标签,否则就不要使用 RawLanguageDriver !否则会报错!!!先看个别名引用的例子:
<select id="findAll" resultType="map" lang="RAW" >
select * from user
select>
<select id="findAll" resultType="map" lang="org.apache.ibatis.scripting.xmltags.XMLLanguageDriver">
select * from user
select>
框架允许我们通过 lang 属性手工指定语言驱动,不指定则系统默认是 lang = “XML”,XML 代表 XMLLanguageDriver ,当然 lang 属性可以是我们内置的别名也可以是我们的语言驱动全限定名,不过值得注意的是,当语句中含有动态 SQL 标签时,就只能选择使用 lang=“XML”,否则程序在初始化构件时就会报错。
## Cause: org.apache.ibatis.builder.BuilderException:
## Dynamic content is not allowed when using RAW language
## 动态语句内容不被原生语言驱动支持!
这段错误提示其实是发生在 RawLanguageDriver 检查动态 SQL 源时:
public class RawLanguageDriver extends XMLLanguageDriver {
// RAW 不能包含动态内容
private void checkIsNotDynamic(SqlSource source) {
if (!RawSqlSource.class.equals(source.getClass())) {
throw new BuilderException(
"Dynamic content is not allowed when using RAW language"
);
}
}
}
至此,基本逻辑我们已经梳理清楚:程序启动初始阶段,语言驱动创建 SQL 源,而运行时, SQL 源动态解析构建出 BoundSql 。
那么除了系统默认的两种语言驱动,还有其它吗?
答案是:有,例如 Mybatis 框架中目前使用了一个名为 VelocityLanguageDriver 的语言驱动。相信大家都学习过 JSP 模板引擎,同时还有很多人学习过其它一些(页面)模板引擎,例如 freemark 和 velocity ,不同模板引擎有自己的一套模板语言语法,而其中 Mybatis 就尝试使用了 Velocity 模板引擎作为语言驱动,目前虽然 Mybatis 只是在测试用例中使用到,但是它告诉了我们,框架允许自定义语言驱动,所以不只是 XML、RAW 两种语言驱动中使用的 OGNL 语法,也可以是 Velocity (语法),或者你自己所能定义的一套模板语言(同时你得定义一套语法)。 例如以下就是 Mybatis 框架中使用到的 Velocity 语言驱动和对应的 SQL 源,它们使用 Velocity 语法/方式解析构建 BoundSql 对象。
/**
* Just a test case. Not a real Velocity implementation.
* 只是一个测试示例,还不是一个真正的 Velocity 方式实现
*/
public class VelocityLanguageDriver implements LanguageDriver {
public SqlSource createSqlSource() {...}
}
public class VelocitySqlSource implements SqlSource {
public BoundSql getBoundSql() {...}
}
好,语言驱动的基本概念大致如此。我们回过头再详细看看动态 SQL 源 SqlSource,作为语句对象 MappedStatement 的属性,在 程序初始构建阶段,语言驱动是怎么创建它的呢?不妨我们先看看常用的动态 SQL 源对象是怎么被创建的吧!
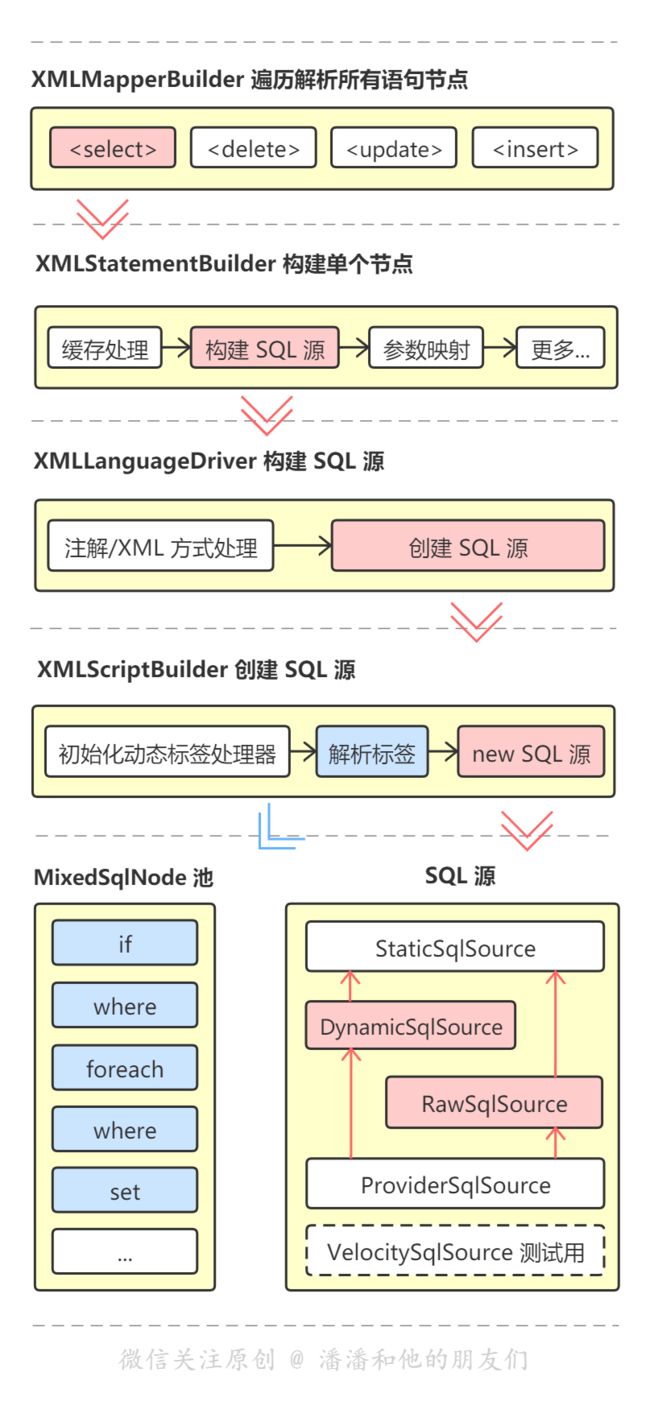
通过以上的程序初始构建阶段,我们可以发现,最终语言驱动通过调用 XMLScriptBuilder 对象来创建 SQL 源。
// XML 语言驱动
public class XMLLanguageDriver implements LanguageDriver {
// 通过调用 XMLScriptBuilder 对象来创建 SQL 源
@Override
public SqlSource createSqlSource() {
// 实例
XMLScriptBuilder builder = new XMLScriptBuilder();
// 解析
return builder.parseScriptNode();
}
}
而在前面我们就已经介绍, XMLScriptBuilder 实例初始构造时,会初始构建所有动态标签处理器:
// XML脚本标签构建器
public class XMLScriptBuilder{
// 标签节点处理器池
private final Map<String, NodeHandler> nodeHandlerMap = new HashMap<>();
// 构造器
public XMLScriptBuilder() {
initNodeHandlerMap();
//... 其它初始化不赘述也不重要
}
// 动态标签处理器
private void initNodeHandlerMap() {
nodeHandlerMap.put("trim", new TrimHandler());
nodeHandlerMap.put("where", new WhereHandler());
nodeHandlerMap.put("set", new SetHandler());
nodeHandlerMap.put("foreach", new ForEachHandler());
nodeHandlerMap.put("if", new IfHandler());
nodeHandlerMap.put("choose", new ChooseHandler());
nodeHandlerMap.put("when", new IfHandler());
nodeHandlerMap.put("otherwise", new OtherwiseHandler());
nodeHandlerMap.put("bind", new BindHandler());
}
}
继 XMLScriptBuilder 初始化流程之后,解析创建 SQL 源流程再分为两步:
1、解析动态标签,通过判断每一块动态标签的类型,使用对应的标签处理器进行解析属性和语句处理,并最终放置到混合 SQL 节点池中(MixedSqlNode),以供程序运行时构建 BoundSql 时使用。
2、new SQL 源,根据 SQL 是否有动态标签或通配符占位符来确认产生对象的静态或动态 SQL 源。
public SqlSource parseScriptNode() {
// 1、解析动态标签 ,并放到混合SQL节点池中
MixedSqlNode rootSqlNode = parseDynamicTags(context);
// 2、根据语句类型,new 出来最终的 SQL 源
SqlSource sqlSource;
if (isDynamic) {
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}
原来解析动态标签的工作交给了 parseDynamicTags() 方法,并且每一个语句对象的动态 SQL 标签最终都会被放到一个混合 SQL 节点池中。
// 混合 SQL 节点池
public class MixedSqlNode implements SqlNode {
// 所有动态 SQL 标签:IF、WHERE、SET 等
private final List<SqlNode> contents;
}
我们先看一下 SqlNode 接口的实现类,基本涵盖了我们所有动态 SQL 标签处理器所需要使用到的节点实例。而其中混合 SQL 节点 MixedSqlNode 作用仅是为了方便获取每一个语句的所有动态标签节点,于是应势而生。
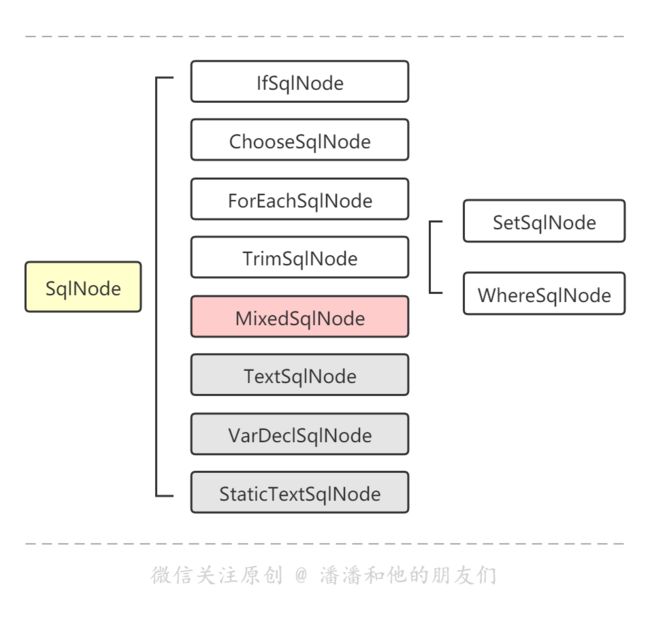
知道动态 SQL 标签节点处理器及以上的节点实现类之后,其实就能很容易理解,到达程序运行时,执行器会调用 SQL 源来协助构建 BoundSql 对象,而 SQL 源的核心工作,就是根据每一小段标签类型,匹配到对应的节点实现类以解析拼接每一小段 SQL 语句。
程序运行时,动态 SQL 源获取 BoundSql 对象 :
// 动态 SQL 源
public class DynamicSqlSource implements SqlSource {
// 这里的 rootSqlNode 属性就是 MixedSqlNode
private final SqlNode rootSqlNode;
@Override
public BoundSql getBoundSql(Object parameterObject) {
// 动态SQL核心解析流程
rootSqlNode.apply(...);
return boundSql;
}
}
很明显,通过调用 MixedSqlNode 的 apply () 方法,循环遍历每一个具体的标签节点。
public class MixedSqlNode implements SqlNode {
// 所有动态 SQL 标签:IF、WHERE、SET 等
private final List<SqlNode> contents;
@Override
public boolean apply(...) {
// 循环遍历,把每一个节点的解析分派到具体的节点实现之上
// 例如 节点的解析交给 IfSqlNode
// 例如 纯文本节点的解析交给 StaticTextSqlNode
contents.forEach(node -> node.apply(...));
return true;
}
}
我们选择一两个标签节点的解析过程进行说明,其它标签节点实现类的处理也基本雷同。首先我们看一下 IF 标签节点的处理:
// IF 标签节点
public class IfSqlNode implements SqlNode {
private final ExpressionEvaluator evaluator;
// 实现逻辑
@Override
public boolean apply(DynamicContext context) {
// evaluator 是一个基于 OGNL 语法的解析校验类
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}
}
IF 标签节点的解析过程非常简单,通过解析校验类 ExpressionEvaluator 来对 IF 标签的 test 属性内的表达式进行解析校验,满足则拼接,不满足则跳过。我们再看看 Trim 标签的节点解析过程,set 标签与 where 标签的底层处理都基于此:
public class TrimSqlNode implements SqlNode {
// 核心处理方法
public void applyAll() {
// 前缀智能补充与去除
applyPrefix(..);
// 前缀智能补充与去除
applySuffix(..);
}
}
再来看一个纯文本标签节点实现类的解析处理流程:
// 纯文本标签节点实现类
public class StaticTextSqlNode implements SqlNode {
private final String text;
public StaticTextSqlNode(String text) {
this.text = text;
}
// 节点处理,仅仅就是纯粹的语句拼接
@Override
public boolean apply(DynamicContext context) {
context.appendSql(text);
return true;
}
}
到这里,动态 SQL 的底层解析过程我们基本讲解完,冗长了些,但流程上大致算完整,有遗漏的,我们回头再补充。

总结
不知不觉中,我又是这么巨篇幅的讲解剖析,确实不太适合碎片化时间阅读,不过话说回来,毕竟此文属于 Mybatis 全解系列,作为学研者还是建议深谙其中,对往后众多框架技术的学习必有帮助。本文中我们很多动态 SQL 的介绍基本都使用 XML 配置方式,当然注解方式配置动态 SQL 也是支持的,动态 SQL 的语法书写同 XML 方式,但是需要在字符串前后添加 script 标签申明该语句为动态 SQL ,例如:
public class UserDao {
/**
* 更新用户
*/
@Select(
""
)
void updateUser( User user);
}
此种动态 SQL 写法可读性较差,并且维护起来也挺硌手,所以我个人是青睐 xml 方式配置语句,一直追求解耦,大道也至简。当然,也有很多团队和项目都在使用注解方式开发,这些没有绝对,还是得结合自己的实际项目情况与团队等去做取舍。
本篇完,本系列下一篇我们讲《 Mybatis系列全解(九):Mybatis的复杂映射 》。

文章持续更新,微信搜索「潘潘和他的朋友们」第一时间阅读,随时有惊喜。本文会在 GitHub https://github.com/JavaWorld 收录,关于热腾腾的技术、框架、面经、解决方案、摸鱼技巧、教程、视频、漫画等等等等,我们都会以最美的姿势第一时间送达,欢迎 Star ~ 我们未来 不止文章!想进读者群的朋友欢迎撩我个人号:panshenlian,备注「加群」我们群里畅聊, BIU ~
