Python 在问答频道中刷题积累到的小技巧(六)

1. 统计字串里的字母个数:四种方法
string = "Hann Yang's id: boysoft2002"
print( sum(map(lambda x:x.isalpha(),string)) )
print( len([*filter(lambda x:x.isalpha(),string)]) )
print( sum(['a'<=s.lower()<='z' for s in string]) )
import re
print( len(re.findall(r'[a-z]', string, re.IGNORECASE)) )2. 一行代码求水仙花数
[*filter(lambda x:x==sum(map(lambda n:int(n)**3,str(x))),range(100,1000))]增强型水仙花:一个整数各位数字的该整数位数次方之和等于这个整数本身。如:
1634 == 1^4 + 6^4 + 3^4 + 4^4
92727 == 9^5 + 2^5 + 7^5 + 2^5+7^5
548834 == 5^6 + 4^6 + 8^6+ 8^6+ 3^6 + 4^6
求3~7位水仙花数,用了81秒:
[*filter(lambda x:x==sum(map(lambda n:int(n)**len(str(x)),str(x))),range(100,10_000_000))]
# [153, 370, 371, 407, 1634, 8208, 9474, 54748, 92727, 93084, 548834, 1741725, 4210818, 9800817, 9926315]不要尝试计算7位以上的,太耗时了。我花了近15分钟得到3个8位水仙花数:
>>> t=time.time();[*filter(lambda x:x==sum(map(lambda n:int(n)**len(str(x)),str(x))),range(10_000_000,100_000_000))];print(time.time()-t)
[24678050, 24678051, 88593477]
858.79821443557743. 字典的快捷生成、键值互换、合并:
>>> dict.fromkeys('abcd',0) # 只能设置一个默认值
{'a': 0, 'b': 0, 'c': 0, 'd': 0}
>>> d = {}
>>> d.update(zip('abcd',range(4)))
>>> d
{'a': 0, 'b': 1, 'c': 2, 'd': 3}
>>> d = dict(enumerate('abcd'))
>>> d
{0: 'a', 1: 'b', 2: 'c', 3: 'd'}
>>> dict(zip(d.values(), d.keys()))
{'a': 0, 'b': 1, 'c': 2, 'd': 3}
>>> dict([v,k] for k,v in d.items())
{'a': 0, 'b': 1, 'c': 2, 'd': 3}
>>> d1 = dict(zip(d.values(), d.keys()))
>>>
>>> d = dict(enumerate('cdef'))
>>> d2 = dict(zip(d.values(), d.keys()))
>>> d2
{'c': 0, 'd': 1, 'e': 2, 'f': 3}
>>>
>>> {**d1, **d2}
{'a': 0, 'b': 1, 'c': 0, 'd': 1, 'e': 2, 'f': 3}
>>> {**d2, **d1}
{'c': 2, 'd': 3, 'e': 2, 'f': 3, 'a': 0, 'b': 1}
# 合并时以前面的字典为准,后者也有的键会被覆盖,没有的追加进来4. 字典的非覆盖合并: 键重复的值相加或者以元组、集合存放
dicta = {"a":3,"b":20,"c":2,"e":"E","f":"hello"}
dictb = {"b":3,"c":4,"d":13,"f":"world","G":"gg"}
dct1 = dicta.copy()
for k,v in dictb.items():
dct1[k] = dct1.get(k,0 if isinstance(v,int) else '')+v
dct2 = dicta.copy()
for k,v in dictb.items():
dct2[k] = (dct2[k],v) if dct2.get(k) else v
dct3 = {k:{v} for k,v in dicta.items()}
for k,v in dictb.items():
dct3[k] = set(dct3.get(k))|{v} if dct3.get(k) else {v} # 并集运算|
print(dicta, dictb, sep='\n')
print(dct1, dct2, dct3, sep='\n')
'''
{'a': 3, 'b': 20, 'c': 2, 'e': 'E', 'f': 'hello'}
{'b': 3, 'c': 4, 'd': 13, 'f': 'world', 'G': 'gg'}
{'a': 3, 'b': 23, 'c': 6, 'e': 'E', 'f': 'helloworld', 'd': 13, 'G': 'gg'}
{'a': 3, 'b': (20, 3), 'c': (2, 4), 'e': 'E', 'f': ('hello', 'world'), 'd': 13, 'G': 'gg'}
{'a': {3}, 'b': {3, 20}, 'c': {2, 4}, 'e': {'E'}, 'f': {'world', 'hello'}, 'd': {13}, 'G': {'gg'}}
'''5. 三边能否构成三角形的判断:
# 传统判断: if a+b>c and b+c>a and c+a>b:
a,b,c = map(eval,input().split())
p = (a+b+c)/2
if p > max([a,b,c]):
s = (p*(p-a)*(p-b)*(p-c))**0.5
print('{:.2f}'.format(s))
else:
print('不能构成三角形')
#或者写成:
p = a,b,c = [*map(eval,input().split())]
if sum(p) > 2*max(p):
p = sum(p)/2
s = (p*(p-a)*(p-b)*(p-c))**0.5
print('%.2f' % s)
else:
print('不能构成三角形')6. Zen of Python的单词中,词频排名前6的画出统计图
import matplotlib.pyplot as plt
from this import s,d
import re
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
dat = ''
for t in s: dat += d.get(t,t)
dat = re.sub(r'[,|.|!|*|\-|\n]',' ',dat) #替换掉所有标点,缩略语算一个词it's、aren't...
lst = [word.lower() for word in dat.split()]
dct = {word:lst.count(word) for word in lst}
dct = sorted(dct.items(), key=lambda x:-x[1])
X,Y = [k[0] for k in dct[:6]],[v[1] for v in dct[:6]]
plt.figure('词频统计',figsize=(12,5))
plt.subplot(1,3,1) #子图的行列及序号,排两行两列则(2,2,1)
plt.title("折线图")
plt.ylim(0,12)
plt.plot(X, Y, marker='o', color="red", label="图例一")
plt.legend()
plt.subplot(1,3,2)
plt.title("柱状图")
plt.ylim(0,12)
plt.bar(X, Y, label="图例二")
plt.legend()
plt.subplot(1,3,3)
plt.title("饼图")
exp = [0.3] + [0.2]*5 #离圆心位置
plt.xlim(-4,4)
plt.ylim(-4,8)
plt.pie(Y, radius=3, labels=X, explode=exp,startangle=120, autopct="%3.1f%%", shadow=True, counterclock=True, frame=True)
plt.legend(loc="upper right") #图例位置右上
plt.show()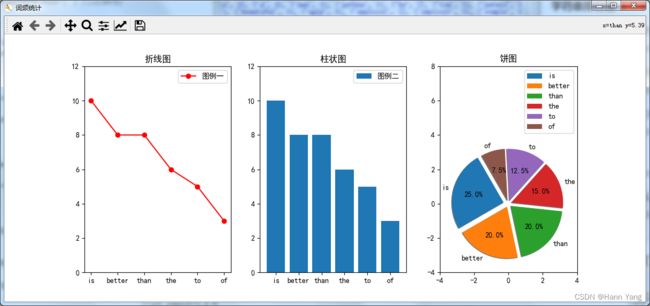
【附录】
matplotlib.pyplot.pie 参数表
| 参数 | 解释 |
|---|---|
| x | 楔形尺寸 |
| explode | 类似数组,默认值: 无,如果不是无,则是一个len(x)数组,用于指定偏移每个楔块的半径 |
| labels | 标签列表:默认值:无,为每个楔块提供标签的一系列字符串 |
| colors | 颜色,默认值:无,饼图循环使用的一系列颜色,如果没有,将使用当前活动周期中的颜色 |
| autopct | 默认值:无,如果不是无,则是一个字符串或函数,用于用数字值标记楔块.标签将放在楔子内,如果是格式字符串,则标签为fmt%pct,如果是函数,则调用 |
| pctdistance | 默认值为0.6,每个饼图切片的中心与生成的文本开头之间的比率 |
| shadow | 默认值为:False,楔块的阴影 |
| labeldistance | 默认值1.1,绘制饼图标签径向距离,如果设置为’无’,则不会绘制标签,会存储标签以供在图列()中使用 |
| startangle | 饼图角度起始角度 |
| radius | 默认值1,饼图的半径,数值越大,饼图越大 |
| counterclock | 设置饼图的方向,默认值为True,表示逆时针方向,False,为顺时针 |
| wedgeprops | 默认值:无,传递给楔形对象的参数,设置楔形的属性 |
| textprops | 设置文本对象的字典参数 |
| center | 浮点类型的列表,可选参数,图标中心位置 |
| frame | 是否选择轴框架,默认值为False,如果是True,则绘制带有表的轴框架 |
| rotatelabels | 默认值为False,布尔类型,如果为True,则将每个标签旋转到相应切片的角度 |
| narmalize | 布尔类型,默认值为True,如果为True,则始终通过规范化x来制作完整的饼图,使总和(x)=1。如果sum(x)<=1,False将生成部分饼图,并为sum(x)>1引发ValueError。 |
| data | 可选参数,如果给定,一下参数接受字符串s,该字符串被解释为数据[s] |
【相关阅读】
Python 在问答频道中刷题积累到的小技巧(一)
https://hannyang.blog.csdn.net/article/details/124935045
Python 在问答频道中刷题积累到的小技巧(二)
https://hannyang.blog.csdn.net/article/details/125026881
Python 在问答频道中刷题积累到的小技巧(三)
https://hannyang.blog.csdn.net/article/details/125058178
Python 在问答频道中刷题积累到的小技巧(四)
https://hannyang.blog.csdn.net/article/details/125211774
Python 在问答频道中刷题积累到的小技巧(五)
https://hannyang.blog.csdn.net/article/details/125270812