微服务设计:去中心化的技术治理与数据管理
现如今我们进入了一个软件业快速变化的年代。一方面,互联网带动着越来越多的传统行业向着互联网转型,使得传统行业的从业者也必须得适应高并发、高吞吐量的应用场景,并且需要不断调整技术架构来应对越来越大的业务量。另一方面,随着业务的不断拓展,服务人群的不断扩大,软件系统也变得越来越复杂。也就是说,虽然互联网行业必须要应对高并发,但业务毕竟还不是太复杂。但传统行业向互联网转型,不仅要面对高并发,还要面对越来越复杂的业务。在这样的状况下,大家突然发现,微服务架构成为了互联网转型的利器,它恰恰能够帮助我们很好地适应互联网的特点,解决高并发、高可用的诸多难题。那么,微服务长什么样儿呢?
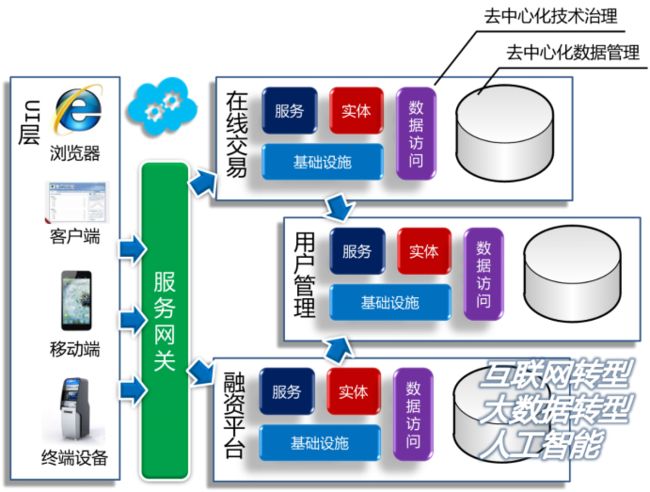
去中心化技术治理与去中心化数据管理
如图,当用户以不同的渠道接入到系统中以后,通过服务网关就会调用到后面的微服务。每个微服务都是一个独立的软件项目,麻雀虽小五脏俱全,即每个微服务都有各自的基础设施、服务、实体、数据访问层与数据库。这时就有了2个重要的概念:去中心化的技术治理与去中心化的数据管理。
去中心化的技术治理
每个微服务都是一个独立的软件项目,都有各自的基础设施与技术架构,因此它们可以设计得各不一样。这样的设计使得每个团队都可以根据各自业务的不同,选用不同的技术架构,甚至不同的编程语言。譬如,有的团队过去使用的.Net,现在希望转型为Java,那么不需要将过去的代码按Java重新实现,而是将它们各自做成不同的微服务,新业务用Java,老业务用.Net,通过微服务就可以将它们集成在一起,系统改造成本将大幅度降低。
再譬如,现在需要采用一些新技术来应对未来的新业务。过去“单体应用”的时代,升级新技术意味着所有的功能都必须升级,采用新技术的成本很高,使得团队不敢轻易尝试新技术,从而在市场中处于劣势。现在有了微服务,可以将原有的业务放到微服务中,保持技术不变。然后,构建新的微服务,采用新的技术,实现新的业务。这样,新技术应用于新业务,老业务不变,技术升级的成本更低,就使得我们可以经常性地采用新技术,从而在市场中获得技术竞争的优势。
也就是说,微服务架构可以为日后快速的技术变革创造条件。当今,技术变革越来越快,但要在老项目中进行技术架构调整,对每个团队来说都是一种挑战。为什么呢?因为在传统的单体应用中,一旦技术架构调整,所有的功能都要调整,其成本就会非常高昂。但是,原有的功能运行得好好的,我们为什么要调整它呢?新的技术我们是希望应用在新功能、新业务上。因此,采用了微服务架构,老功能运行在老的技术架构上,而新功能放在新的微服务中,采用新的技术架构。这样,我们采用新技术的成本就会更低,就可以更加频繁的采用新技术,从而在市场中获得技术竞争的优势。

架构团队实践去中心化技术治理
然而,架构师应当掌握一个度,即去中心化的技术治理并不意味着系统中的每个微服务都可以采用完全不同的技术架构,那样会使得运维人员在日后必须掌握更多的技术架构,才能运维整个系统,从而增大了日后运维的成本。
变与不变,架构师必须把握好这个“度”。因此,如图,在项目初期,为了降低系统的运维成本,架构团队设计了架构A,并且微服务A、B、C三个团队都是基于架构A进行设计开发。日后,随着技术与市场的更迭,当设计微服务X和Z时,架构A已经不能满足它们的需求了,因此架构团队根据新需求设计了架构B。这时,微服务X和Z可以基于架构B进行设计,那么微服务A、B、C需要升级吗?微服务C因为业务的增长,架构A已经不能满足它的需要了。这时,我们只需要将微服务C升级到架构B。然而,微服务A与B在原有的业务上运行得好好的,就不用升级到架构B,继续在架构A上运行,技术升级的成本将变得可控。
去中心化的数据管理
每个微服务除了有自己的基础设施,通过数据库拆分,还可以有自己的数据库。这样,每个微服务都有自己的数据库,那么这些数据库采用的数据架构必须一样吗?当然可以不一样。这样,每个微服务可以根据数据量的大小,以及用户访问数据的特点,采用不同的数据库。这对于即将到来的大数据转型,显得尤为重要。
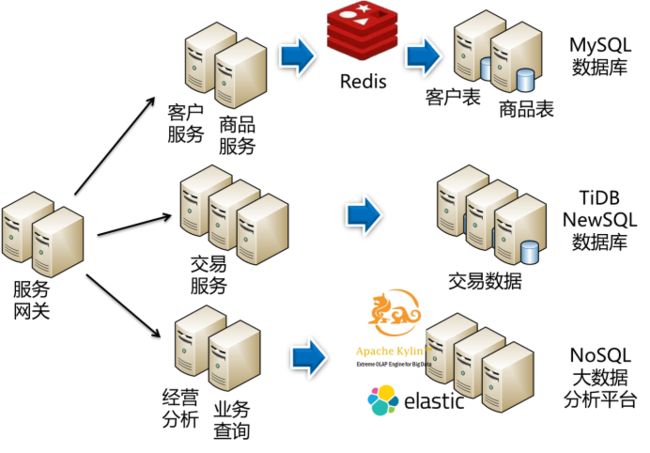
去中心化数据管理
如图,通过微服务的拆分,客户微服务与商品微服务,其各自对应的客户表与商品表,它们的共同特点都是数据量小且需要反复读取。因此,可以采用一个小型的MySQL数据库进行数据存储,并且在前面架设一个Redis缓存,提高查询效率。这样的设计就可以很好应对这类微服务的需求。
但对于交易微服务,以及它对应的交易数据,其特点则是高并发与大数据量写入。因此,只有一个数据库节点是肯定支撑不住它的数据需求。选用分布式的NewSQL数据库(如TiDB),既可以通过分布式存储,将数据均匀存储在多个物理节点上,分散用户压力,又可以利用NewSQL数据库保障数据的一致性,就可以满足这类微服务的数据需求。
而经营分析与业务查询,这类微服务是对海量数据的数据分析与秒级查询。这时它们要面对的是数十亿甚至上百亿的历史数据。对于它们,首先通过读写分离,将数据从生产库抽取到由NoSQL数据库或大数据平台组成的查询库中。
在面对海量数据的秒级查询时,最大的障碍是join操作,它将极大影响查询效率。因此,在从生产库导入NoSQL数据库前,先进行join操作,将关联以后的数据导入NoSQL数据库的一个表中,形成大宽表,然后建立分布式索引(如ElasticSearch),就能实现海量数据的秒级查询。
对于“经营分析”这一类的统计分析需要,需要在动辄数年的数据中进行大范围的扫描,进行汇总、求和等操作。这时通过大数据平台提前进行汇总分析,形成数据仓库,然后通过Cube进行OLAP建模(如Kylin),就能很好地应付这一类的数据需求。
因此,采用微服务的去中心化数据治理,可以有效地帮助开发团队,在大数据转型的大背景下,有更加灵活的方案,选用更加合适的数据架构,去应对未来高并发、大数据的应用场景。
干货最后,推荐一下玄姐和范钢老师联合撰写的《架构真意:企业级应用架构设计方法论与实践》一书,本书是玄姐的“百万架构师修炼”训练营配套书籍,是一套操作性极强的架构设计方法论,希望能够帮助更多读者成为顶级架构师。更多关于微服务的设计实践,尽在这本书中。
书中包含:
落地、实践,为架构师提供切实可行、操作性强的架构设计方法;
难题、方案,为架构师解决项目实践中的设计难题提供思路与方案;
前瞻、全局,为架构师展现未来技术发展趋势。
