人工智能 | ShowMeAI资讯日报 #2022.06.02

ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
1.工具&框架

工具:Public APIs - 免费开放 API 大列表
tags: [免费 API,天气,书籍,博客]
GitHub:http://github.com/markodenic/public-apis

工具:GitNoter - 本地部署的开源版web版Markdown笔记应用
tags:[markdown,开源]
GitHub:http://github.com/git-noter/gitnoter
工具:audio-preview - VS Code的wav音频文件预览与播放扩展
tags:[音频,wav,预览,播放]
GitHub:http://github.com/sukumo28/vscode-audio-preview
工具库:LBF - 多智能体强化学习环境
tags:[强化学习,多智能体,模拟环境]
GitHub:http://github.com/semitable/lb-foraging
框架:LightAutoML - 快速可定制的自动机器学校模型创建(AutoML)框架
tags:[automl,自动化机器学习,轻量]
GitHub:http://github.com/sb-ai-lab/LightAutoML

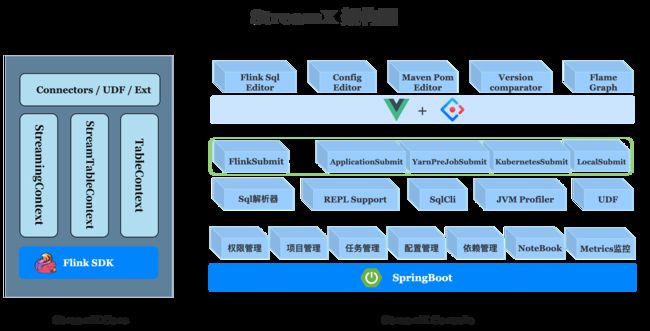
工具平台:StreamX - Flink/Spark 极速开发框架,一站式流数据处理平台
tags:[Flink,Spark,流式数据,流数据处理,StreamX]
提供开箱即用的流式大数据开发体验,可在平台上统一管理配置、开发、测试、部署、监控、运维的整个过程。
GitHub:https://github.com/streamxhub/streamx
2.项目&代码

项目:基于T5的文本检索系统
tags:[文本检索,T5,JAX,Text-to-Text,Transformer]
'T5X Retrieval - a JAX implementation of T5 (Text-to-Text Transfer Transformer) optimized for retrieval applications’ by Google Research
GitHub:http://github.com/google-research/t5x_retrieval
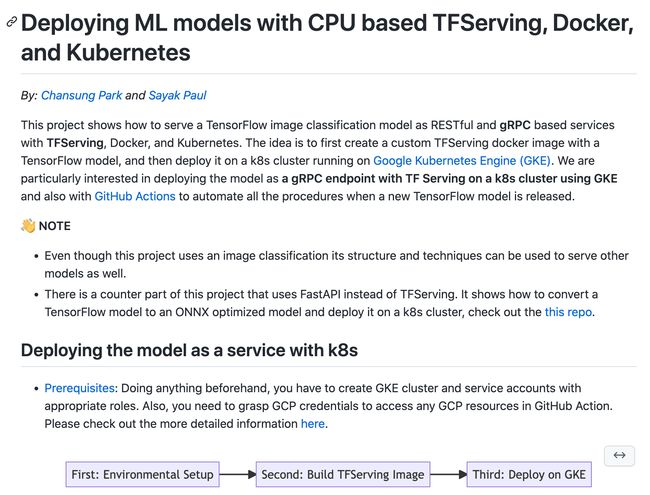
应用:基于TFServing,Docker与Kubernetes的CPU机器学习模型部署
tags:[模型,部署,服务,TFServing,Docker,Kubernetes]
GitHub:http://github.com/deep-diver/ml-deployment-k8s-tfserving
项目:基于文本生成视频
tags:[视频生成,文本视频生成]
CogVideo,由清华大学数据挖掘研究小组开源的基于文本生成视频的开源项目,项目 Repo 中附有论文。
GitHub:https://github.com/THUDM/CogVideo
系统:大 AI 模型推理系统
tags:[大模型,推理,加速]
Energon-AI:大模型推理系统,仅需对现有项目进行极少量修改,即可完成自定义大模型的推理部署,获得并行扩展的超线性加速。
项目以 “高性能、高可用、可伸缩” 为理念,深入单实例多设备推理场景,在性能和易用性上兼具优势。
GitHub:http://github.com/hpcaitech/ColossalAI
3.博文&分享

博文:耗散度与优化算法分析
《Dissipativity and Algorithm Analysis》by Laurent Lessard
Link:https://laurentlessard.com/dissipativity-and-algorithm-analysis/
博文:多项式与最优化关系(第5部分)
《On the Link Between Optimization and Polynomials, Part 5 - Cyclical Step-sizes》by Baptiste Goujaud and Fabian Pedregosa
Link:https://fa.bianp.net/blog/2022/cyclical/
博文:深度学习应用与实战书籍推荐
The best books about applied deep learning
Link:https://shepherd.com/best-books/applied-deep-learning
4.数据&资源

数据&模型:中文语音数据+中文语音预训练模型
tags:[语音,中文,speech,数据]
中文语音预训练模型,用 WenetSpeech train_l 集的 1 万小时中文数据作为无监督预训练数据
Link:https://github.com/TencentGameMate/chinese_speech_pretrain


资源列表:低延迟开发相关资源大列表
tags:[低延迟,开发,资源]
GitHub:http://github.com/penberg/awesome-low-latency
资源:Python网络爬虫开放知识库
tags:[爬虫,知识库]
‘Web scraping with Python open knowledge - Repository of open knowledge about web scraping in Python’ by Re Analytics - DataBoutique.com
GitHub:http://github.com/reanalytics-databoutique/webscraping-open-project
5.研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的6月论文合辑。
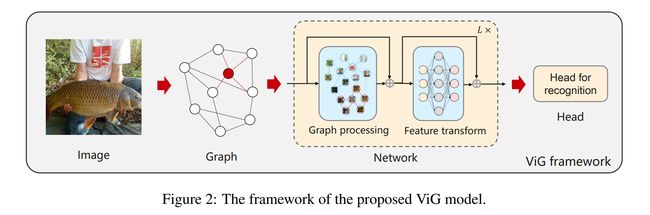
论文:Vision GNN: An Image is Worth Graph of Nodes
论文标题:Vision GNN: An Image is Worth Graph of Nodes
论文时间:1 Jun 2022
所属领域:Computer Vision/计算机视觉
对应任务:Object Detection,物体检测,目标检测
论文地址:https://arxiv.org/abs/2206.00272
代码实现:https://github.com/huawei-noah/CV-backbones
论文作者:Kai Han, Yunhe Wang, Jianyuan Guo, Yehui Tang, Enhua Wu
论文简介:In this paper, we propose to represent the image as a graph structure and introduce a new Vision GNN (ViG) architecture to extract graph-level feature for visual tasks./在本文中,我们提出将图像表示为图形结构,并引入一种新的视觉GNN(ViG)体系结构来提取视觉任务的图形级特征。
论文摘要:Network architecture plays a key role in the deep learning-based computer vision system. The widely-used convolutional neural network and transformer treat the image as a grid or sequence structure, which is not flexible to capture irregular and complex objects. In this paper, we propose to represent the image as a graph structure and introduce a new Vision GNN (ViG) architecture to extract graph-level feature for visual tasks. We first split the image to a number of patches which are viewed as nodes, and construct a graph by connecting the nearest neighbors. Based on the graph representation of images, we build our ViG model to transform and exchange information among all the nodes. ViG consists of two basic modules: Grapher module with graph convolution for aggregating and updating graph information, and FFN module with two linear layers for node feature transformation. Both isotropic and pyramid architectures of ViG are built with different model sizes. Extensive experiments on image recognition and object detection tasks demonstrate the superiority of our ViG architecture. We hope this pioneering study of GNN on general visual tasks will provide useful inspiration and experience for future research. The PyTroch code will be available at https://github.com/huawei-noah/CV-Backbones and the MindSpore code will be avaiable at https://gitee.com/mindspore/models.
网络架构在基于深度学习的计算机视觉系统中起着关键作用。广泛使用的卷积神经网络和transformer将图像视为网格或序列结构,对于捕捉不规则和复杂的物体来说不灵活。在本文中,我们建议将图像表示为图形结构,并引入新的 Vision GNN (ViG) 架构来提取视觉任务的图形级特征。我们首先将图像分割成许多块,这些块被视为节点,并通过连接最近的邻居来构造一个图。基于图像的图表示,我们构建了我们的 ViG 模型来在所有节点之间转换和交换信息。 ViG 由两个基本模块组成:具有图卷积的 Grapher 模块,用于聚合和更新图信息,以及具有两个线性层的 FFN 模块,用于节点特征变换。 ViG 的各向同性和金字塔结构都是用不同的模型大小构建的。图像识别和目标检测任务的大量实验证明了我们的 ViG 架构的优越性。我们希望 GNN 在一般视觉任务上的这项开创性研究能为未来的研究提供有益的启发和经验。
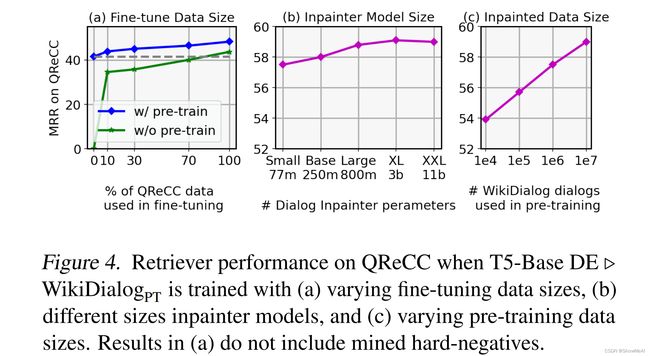
论文:Dialog Inpainting: Turning Documents into Dialogs
论文标题:Dialog Inpainting: Turning Documents into Dialogs
论文时间:18 May 2022
所属领域:Natural Language Processing/自然语言处理
对应任务:Conversational Question Answering,Question Answering,会话问答,问答
论文地址:https://arxiv.org/abs/2205.09073
代码实现:https://github.com/google-research/dialog-inpainting
论文作者:Zhuyun Dai, Arun Tejasvi Chaganty, Vincent Zhao, Aida Amini, Qazi Mamunur Rashid, Mike Green, Kelvin Guu
论文简介:Our approach takes the text of any document and transforms it into a two-person dialog between the writer and an imagined reader: we treat sentences from the article as utterances spoken by the writer, and then use a dialog inpainter to predict what the imagined reader asked or said in between each of the writer’s utterances./我们的方法将任何文档的文本转换为作者和想象读者之间的两人对话:我们将文章中的句子视为作者所说的话,然后使用对话修复者预测想象读者在每个作者的话语之间所问或所说的话。
论文摘要:Many important questions (e.g. “How to eat healthier?”) require conversation to establish context and explore in depth. However, conversational question answering (ConvQA) systems have long been stymied by scarce training data that is expensive to collect. To address this problem, we propose a new technique for synthetically generating diverse and high-quality dialog data: dialog inpainting. Our approach takes the text of any document and transforms it into a two-person dialog between the writer and an imagined reader: we treat sentences from the article as utterances spoken by the writer, and then use a dialog inpainter to predict what the imagined reader asked or said in between each of the writer’s utterances. By applying this approach to passages from Wikipedia and the web, we produce WikiDialog and WebDialog, two datasets totalling 19 million diverse information-seeking dialogs – 1,000x larger than the largest existing ConvQA dataset. Furthermore, human raters judge the answer adequacy and conversationality of WikiDialog to be as good or better than existing manually-collected datasets. Using our inpainted data to pre-train ConvQA retrieval systems, we significantly advance state-of-the-art across three benchmarks (QReCC, OR-QuAC, TREC CAsT) yielding up to 40% relative gains on standard evaluation metrics.
许多重要问题(例如,“如何吃得更健康?”)需要对话来建立背景并深入探讨。然而,会话式问答(ConvQA)系统长期以来一直受到缺乏培训数据的困扰,而这些数据的收集成本很高。为了解决这个问题,我们提出了一种综合生成各种高质量对话数据的新技术:对话修复。我们的方法将任何文档的文本转换为作者和想象读者之间的两人对话:我们将文章中的句子视为作者所说的话,然后使用对话修复者预测想象读者在每个作者的话语之间所问或所说的话。通过将这种方法应用于Wikipedia和web中的段落,我们生成了WikiDialog和WebDialog,这两个数据集共有1900万个不同的信息搜索对话框,比现有最大的ConvQA数据集大1000倍。此外,人工评分员判断WikiDialog的答案充分性和对话性与现有手动收集的数据集一样好或更好。使用我们修复的数据对ConvQA检索系统进行预培训,我们在三个基准(QReCC或QuAC、TREC CAsT)上显著提升了最新水平,在标准评估指标上获得了高达40%的相对收益。

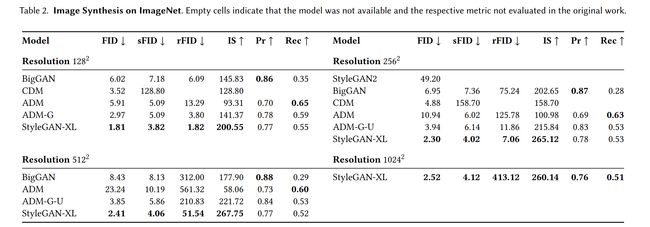
论文:StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
论文标题:StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
论文时间:1 Feb 2022
所属领域:计算机视觉
对应任务:Image Generation/图像生成
论文地址:https://arxiv.org/abs/2202.00273
代码实现:https://github.com/autonomousvision/stylegan_xl
论文作者:Axel Sauer, Katja Schwarz, Andreas Geiger
论文简介:StyleGAN in particular sets new standards for generative modeling regarding image quality and controllability./StyleGAN 尤其为关于图像质量和可控性的生成建模设定了新标准。
论文摘要:Computer graphics has experienced a recent surge of data-centric approaches for photorealistic and controllable content creation. StyleGAN in particular sets new standards for generative modeling regarding image quality and controllability. However, StyleGAN’s performance severely degrades on large unstructured datasets such as ImageNet. StyleGAN was designed for controllability; hence, prior works suspect its restrictive design to be unsuitable for diverse datasets. In contrast, we find the main limiting factor to be the current training strategy. Following the recently introduced Projected GAN paradigm, we leverage powerful neural network priors and a progressive growing strategy to successfully train the latest StyleGAN3 generator on ImageNet. Our final model, StyleGAN-XL, sets a new state-of-the-art on large-scale image synthesis and is the first to generate images at a resolution of 10242 at such a dataset scale. We demonstrate that this model can invert and edit images beyond the narrow domain of portraits or specific object classes.
最近,计算机图形学经历了以数据为中心的照片级逼真和可控内容创建方法的激增。 StyleGAN 尤其为关于图像质量和可控性的生成建模设定了新标准。然而,StyleGAN 的性能在 ImageNet 等大型非结构化数据集上严重下降。 StyleGAN 专为可控性而设计;因此,先前的工作怀疑其限制性设计不适合不同的数据集。相比之下,我们发现主要的限制因素是当前的训练策略。遵循最近引入的 Projected GAN 范例,我们利用强大的神经网络先验和渐进式增长策略在 ImageNet 上成功训练最新的 StyleGAN3 生成器。我们的最终模型 StyleGAN-XL 在大规模图像合成方面树立了新的最先进技术,并且是第一个在这样的数据集规模上生成分辨率为 10242 的图像的模型。我们证明该模型可以在肖像或特定对象类的狭窄领域之外反转和编辑图像。

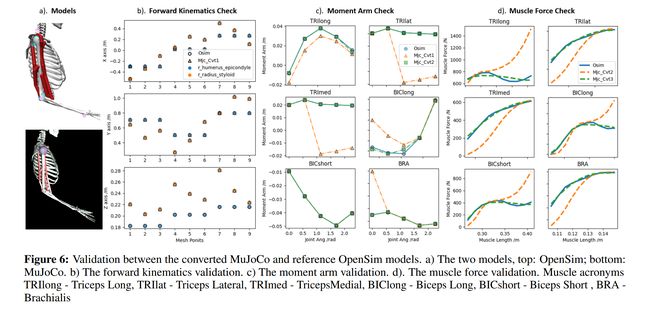
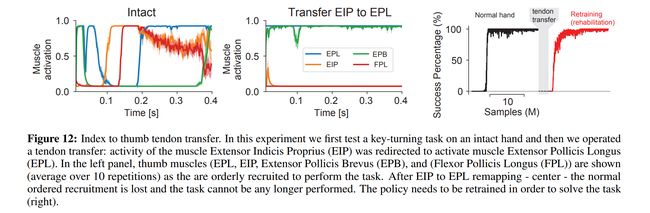
论文:MyoSuite - A contact-rich simulation suite for musculoskeletal motor control
论文标题:MyoSuite – A contact-rich simulation suite for musculoskeletal motor control
论文时间:26 May 2022
所属领域:Playing Games/游戏
对应任务:Continuous Control,连续控制
论文地址:https://arxiv.org/abs/2205.13600
代码实现:https://github.com/facebookresearch/myosuite
论文作者:Vittorio Caggiano, Huawei Wang, Guillaume Durandau, Massimo Sartori, Vikash Kumar
论文简介:Current frameworks for musculoskeletal control do not support physiological sophistication of the musculoskeletal systems along with physical world interaction capabilities./当前的肌肉骨骼控制框架不支持肌肉骨骼系统的生理复杂性以及物理世界的交互能力。
论文摘要:Embodied agents in continuous control domains have had limited exposure to tasks allowing to explore musculoskeletal properties that enable agile and nimble behaviors in biological beings. The sophistication behind neuro-musculoskeletal control can pose new challenges for the motor learning community. At the same time, agents solving complex neural control problems allow impact in fields such as neuro-rehabilitation, as well as collaborative-robotics. Human biomechanics underlies complex multi-joint-multi-actuator musculoskeletal systems. The sensory-motor system relies on a range of sensory-contact rich and proprioceptive inputs that define and condition muscle actuation required to exhibit intelligent behaviors in the physical world. Current frameworks for musculoskeletal control do not support physiological sophistication of the musculoskeletal systems along with physical world interaction capabilities. In addition, they are neither embedded in complex and skillful motor tasks nor are computationally effective and scalable to study large-scale learning paradigms. Here, we present MyoSuite – a suite of physiologically accurate biomechanical models of elbow, wrist, and hand, with physical contact capabilities, which allow learning of complex and skillful contact-rich real-world tasks. We provide diverse motor-control challenges: from simple postural control to skilled hand-object interactions such as turning a key, twirling a pen, rotating two balls in one hand, etc. By supporting physiological alterations in musculoskeletal geometry (tendon transfer), assistive devices (exoskeleton assistance), and muscle contraction dynamics (muscle fatigue, sarcopenia), we present real-life tasks with temporal changes, thereby exposing realistic non-stationary conditions in our tasks which most continuous control benchmarks lack.
连续控制域中的具体化代理对任务的接触有限,因此可以探索肌肉骨骼特性,从而在生物中实现敏捷和灵活的行为。神经肌肉骨骼控制背后的复杂性可能给运动学习社区带来新的挑战。同时,解决复杂神经控制问题的代理可以在神经康复以及协作机器人等领域产生影响。人体生物力学是复杂的多关节多执行器肌肉骨骼系统的基础。感觉运动系统依赖于一系列丰富的感觉接触和本体感觉输入,这些输入定义和调节了在物理世界中展示智能行为所需的肌肉驱动。目前的肌肉骨骼控制框架不支持肌肉骨骼系统的生理复杂性以及物理世界交互能力。此外,它们既不嵌入复杂和熟练的运动任务中,也不具有计算效率和可扩展性,无法研究大规模学习范式。在这里,我们展示了MyoSuite——一套肘部、腕部和手部的生理学精确生物力学模型,具有物理接触能力,允许学习复杂和熟练的接触丰富的现实世界任务。我们通过支持肌肉骨骼几何结构(肌腱转移)、辅助装置(外骨骼辅助)和肌肉收缩动力学(肌肉疲劳、肌肉减少症)的生理改变,提供各种运动控制挑战:从简单的姿势控制到熟练的手-物交互,如转动钥匙、旋转钢笔、单手旋转两个球等,我们呈现具有时间变化的真实任务,从而在任务中暴露出大多数连续控制基准所缺乏的现实非平稳条件。
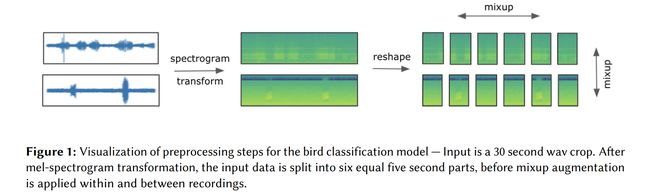
论文:Recognizing bird species in diverse soundscapes under weak supervision
论文标题:Recognizing bird species in diverse soundscapes under weak supervision
论文时间:16 Jul 2021
所属领域:nan
对应任务:Robust classification
论文地址:https://arxiv.org/abs/2107.07728
代码实现:https://github.com/ChristofHenkel/kaggle-birdclef2021-2nd-place
论文作者:Christof Henkel, Pascal Pfeiffer, Philipp Singer
论文简介:We present a robust classification approach for avian vocalization in complex and diverse soundscapes, achieving second place in the BirdCLEF2021 challenge./我们提出了一种针对复杂多样声景中鸟类发声的稳健分类方法,在BirdCLEF2021挑战赛中获得第二名。
论文摘要:We present a robust classification approach for avian vocalization in complex and diverse soundscapes, achieving second place in the BirdCLEF2021 challenge. We illustrate how to make full use of pre-trained convolutional neural networks, by using an efficient modeling and training routine supplemented by novel augmentation methods. Thereby, we improve the generalization of weakly labeled crowd-sourced data to productive data collected by autonomous recording units. As such, we illustrate how to progress towards an accurate automated assessment of avian population which would enable global biodiversity monitoring at scale, impossible by manual annotation.
我们提出了一种针对复杂多样声景中鸟类发声的稳健分类方法,在BirdCLEF2021挑战赛中获得第二名。我们说明了如何充分利用预训练的卷积神经网络,通过使用有效的建模和训练例程,并辅以新的增强方法。因此,我们改进了将弱标记的众包数据泛化为由自主记录单元收集的生产数据。因此,我们说明了如何实现鸟类种群的准确自动评估,从而实现大规模的全球生物多样性监测,而这个任务无法通过手动注释完成。


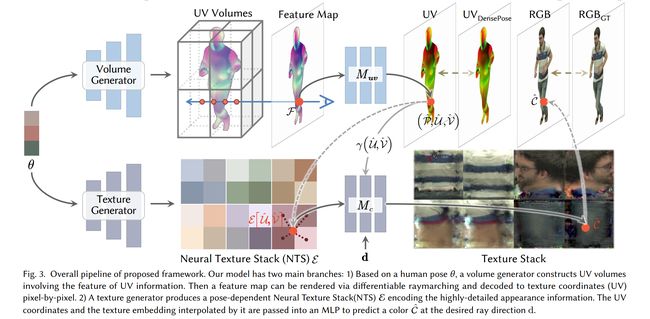
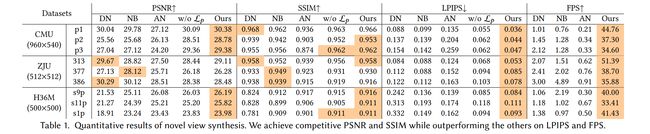
论文:UV Volumes for Real-time Rendering of Editable Free-view Human Performance
论文标题:UV Volumes for Real-time Rendering of Editable Free-view Human Performance
论文时间:27 Mar 2022
所属领域:计算机视觉
论文地址:https://arxiv.org/abs/2203.14402
代码实现:https://github.com/fanegg/UV-Volumes
论文作者:Yue Chen, Xuan Wang, Xingyu Chen, Qi Zhang, Xiaoyu Li, Yu Guo, Jue Wang, Fei Wang
论文简介:Neural volume rendering enables photo-realistic renderings of a human performer in free-view, a critical task in immersive VR/AR applications./神经体绘制能够在自由视图中对人类表演者进行逼真的渲染,这是沉浸式 VR/AR 应用程序中的一项关键任务。
论文摘要:Neural volume rendering enables photo-realistic renderings of a human performer in free-view, a critical task in immersive VR/AR applications. But the practice is severely limited by high computational costs in the rendering process. To solve this problem, we propose the UV Volumes, a new approach that can render an editable free-view video of a human performer in realtime. It separates the high-frequency (i.e., non-smooth) human appearance from the 3D volume, and encodes them into 2D neural texture stacks (NTS). The smooth UV volumes allow much smaller and shallower neural networks to obtain densities and texture coordinates in 3D while capturing detailed appearance in 2D NTS. For editability, the mapping between the parameterized human model and the smooth texture coordinates allows us a better generalization on novel poses and shapes. Furthermore, the use of NTS enables interesting applications, e.g., retexturing. Extensive experiments on CMU Panoptic, ZJU Mocap, and H36M datasets show that our model can render 960 * 540 images in 30FPS on average with comparable photo-realism to state-of-the-art methods. The project and supplementary materials are available at https://fanegg.github.io/UV-Volumes .
神经体绘制能够在自由视图中对人类表演者进行逼真的渲染,这是沉浸式 VR/AR 应用程序中的一项关键任务。但是这种做法受到渲染过程中高计算成本的严重限制。为了解决这个问题,我们提出了 UV Volumes,这是一种可以实时渲染人类表演者的可编辑自由视图视频的新方法。它将高频(即非平滑)人类外观与 3D 体积分离,并将它们编码为 2D 神经纹理堆栈(NTS)。平滑的 UV 体积允许更小和更浅的神经网络在 3D 中获取密度和纹理坐标,同时在 2D NTS 中捕获详细外观。对于可编辑性,参数化人体模型和平滑纹理坐标之间的映射使我们能够更好地概括新颖的姿势和形状。此外,使用 NTS 可以实现有趣的应用,例如重新纹理化。在 CMU Panoptic、ZJU Mocap 和 H36M 数据集上进行的大量实验表明,我们的模型可以平均以 30FPS 的速度渲染 960 * 540 图像,其照片真实感与最先进的方法相当。
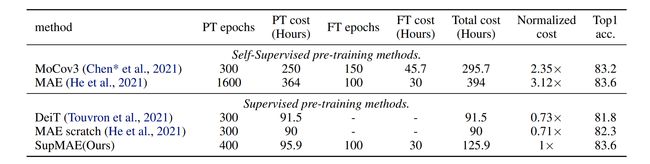
论文:SupMAE: Supervised Masked Autoencoders Are Efficient Vision Learners
论文标题:SupMAE: Supervised Masked Autoencoders Are Efficient Vision Learners
论文时间:28 May 2022
所属领域:计算机视觉
论文地址:https://arxiv.org/abs/2205.14540
代码实现:https://github.com/cmu-enyac/supmae
论文作者:Feng Liang, Yangguang Li, Diana Marculescu
论文简介:Self-supervised Masked Autoencoders (MAE) are emerging as a new pre-training paradigm in computer vision./自监督掩码自动编码器(MAE)是计算机视觉中一种新兴的预训练模式。
论文摘要:Self-supervised Masked Autoencoders (MAE) are emerging as a new pre-training paradigm in computer vision. MAE learns semantics implicitly via reconstructing local patches, requiring thousands of pre-training epochs to achieve favorable performance. This paper incorporates explicit supervision, i.e., golden labels, into the MAE framework. The proposed Supervised MAE (SupMAE) only exploits a visible subset of image patches for classification, unlike the standard supervised pre-training where all image patches are used. SupMAE is efficient and can achieve comparable performance with MAE using only 30% compute when evaluated on ImageNet with the ViT-B/16 model. Detailed ablation studies are conducted to verify the proposed components.
自监督掩码自编码器 (MAE) 正在成为计算机视觉中一种新的预训练范式。 MAE 通过重建局部补丁来隐式学习语义,需要数千个预训练 epoch 才能获得良好的性能。本文将显式监督,即黄金标签,纳入 MAE 框架。所提出的监督 MAE (SupMAE) 仅利用图像块的可见子集进行分类,这与使用所有图像块的标准监督预训练不同。 SupMAE 是高效的,并且在使用 ViT-B/16 模型在 ImageNet 上进行评估时,仅使用 30% 的计算就可以实现与 MAE 相当的性能。进行详细的消融研究以验证建议的组件。

论文:SymForce: Symbolic Computation and Code Generation for Robotics
论文标题:SymForce: Symbolic Computation and Code Generation for Robotics
论文时间:17 Apr 2022
所属领域:Computer Code
对应任务:Code Generation,Motion Planning,代码生成,运动规划
论文地址:https://arxiv.org/abs/2204.07889
代码实现:https://github.com/symforce-org/symforce
论文作者:Hayk Martiros, Aaron Miller, Nathan Bucki, Bradley Solliday, Ryan Kennedy, Jack Zhu, Tung Dang, Dominic Pattison, Harrison Zheng, Teo Tomic, Peter Henry, Gareth Cross, Josiah VanderMey, Alvin Sun, Samuel Wang, Kristen Holtz
论文简介:We present SymForce, a library for fast symbolic computation, code generation, and nonlinear optimization for robotics applications like computer vision, motion planning, and controls./我们介绍了 SymForce,这是一个用于快速符号计算、代码生成和非线性优化的库,适用于计算机视觉、运动规划和控制等机器人应用程序。
论文摘要:We present SymForce, a library for fast symbolic computation, code generation, and nonlinear optimization for robotics applications like computer vision, motion planning, and controls. SymForce combines the development speed and flexibility of symbolic math with the performance of autogenerated, highly optimized code in C++ or any target runtime language. SymForce provides geometry and camera types, Lie group operations, and branchless singularity handling for creating and analyzing complex symbolic expressions in Python, built on top of SymPy. Generated functions can be integrated as factors into our tangent-space nonlinear optimizer, which is highly optimized for real-time production use. We introduce novel methods to automatically compute tangent-space Jacobians, eliminating the need for bug-prone handwritten derivatives. This workflow enables faster runtime code, faster development time, and fewer lines of handwritten code versus the state-of-the-art. Our experiments demonstrate that our approach can yield order of magnitude speedups on computational tasks core to robotics. Code is available at https://github.com/symforce-org/symforce .
我们介绍了 SymForce,这是一个用于快速符号计算、代码生成和非线性优化的库,适用于计算机视觉、运动规划和控制等机器人应用程序。 SymForce 将符号数学的开发速度和灵活性与 C++ 或任何目标运行时语言中自动生成、高度优化的代码的性能相结合。 SymForce 提供几何和相机类型、李群操作和无分支奇点处理,用于在 Python 中创建和分析复杂的符号表达式,建立在 SymPy 之上。生成的函数可以作为因子集成到我们的切线空间非线性优化器中,该优化器针对实时生产使用进行了高度优化。我们引入了自动计算切线空间雅可比矩阵的新方法,消除了对容易出错的手写导数的需求。与最先进的技术相比,此工作流程可实现更快的运行时代码、更快的开发时间和更少的手写代码行。我们的实验表明,我们的方法可以在机器人核心的计算任务上产生数量级的加速。

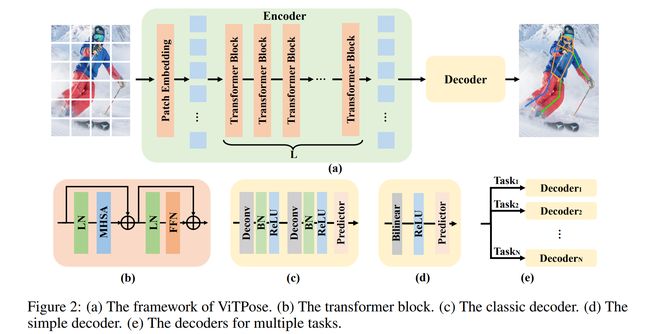
论文:ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
论文标题:ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
论文时间:26 Apr 2022
所属领域:Computer Vision/计算机视觉
对应任务:Keypoint Detection,Pose Estimation,关键点检测,姿态估计
论文地址:https://arxiv.org/abs/2204.12484
代码实现:https://github.com/vitae-transformer/vitpose
论文作者:Yufei Xu, Jing Zhang, Qiming Zhang, DaCheng Tao
论文简介:In this paper, we show the surprisingly good capabilities of plain vision transformers for pose estimation from various aspects, namely simplicity in model structure, scalability in model size, flexibility in training paradigm, and transferability of knowledge between models, through a simple baseline model called ViTPose./在本文中,我们通过一个简单的方法,从模型结构的简单性、模型大小的可扩展性、训练范式的灵活性以及模型之间知识的可转移性等各个方面展示了普通视觉变换器在姿态估计方面的惊人能力,称为 ViTPose 的基线模型。
论文摘要:Although no specific domain knowledge is considered in the design, plain vision transformers have shown excellent performance in visual recognition tasks. However, little effort has been made to reveal the potential of such simple structures for pose estimation tasks. In this paper, we show the surprisingly good capabilities of plain vision transformers for pose estimation from various aspects, namely simplicity in model structure, scalability in model size, flexibility in training paradigm, and transferability of knowledge between models, through a simple baseline model called ViTPose. Specifically, ViTPose employs plain and non-hierarchical vision transformers as backbones to extract features for a given person instance and a lightweight decoder for pose estimation. It can be scaled up from 100M to 1B parameters by taking the advantages of the scalable model capacity and high parallelism of transformers, setting a new Pareto front between throughput and performance. Besides, ViTPose is very flexible regarding the attention type, input resolution, pre-training and finetuning strategy, as well as dealing with multiple pose tasks. We also empirically demonstrate that the knowledge of large ViTPose models can be easily transferred to small ones via a simple knowledge token. Experimental results show that our basic ViTPose model outperforms representative methods on the challenging MS COCO Keypoint Detection benchmark, while the largest model sets a new state-of-the-art. The code and models are available at https://github.com/ViTAE-Transformer/ViTPose .
尽管在设计中没有考虑特定的领域知识,但普通vision transformers在视觉识别任务中表现出了出色的性能。然而,很少有人努力揭示这种简单结构在姿势估计任务中的潜力。在本文中,我们通过一个简单的基线模型(称为ViTPose。具体来说,ViTPose 使用普通和非分层vision transformers作为骨干来提取给定人物实例的特征,并使用轻量级解码器进行姿势估计。利用 Transformer 的可扩展模型容量和高并行性的优势,它可以从 100M 扩展到 1B 参数,在吞吐量和性能之间设置了新的 Pareto 前沿。此外,ViTPose 在注意力类型、输入分辨率、预训练和微调策略以及处理多个姿势任务方面非常灵活。我们还凭经验证明,大型 ViTPose 模型的知识可以通过简单的知识令牌轻松转移到小型模型。实验结果表明,我们的基础版 ViTPose 模型在具有挑战性的 MS COCO 关键点检测基准上优于过往一些代表性的典型方法,而大模型版本设定了新的技术前沿。
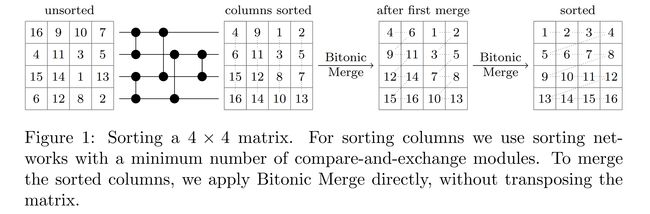
论文:Vectorized and performance-portable Quicksort
论文标题:Vectorized and performance-portable Quicksort
论文时间:12 May 2022
所属领域:nan
对应任务:nan
论文地址:https://arxiv.org/abs/2205.05982
代码实现:https://github.com/google/highway
论文作者:Mark Blacher, Joachim Giesen, Peter Sanders, Jan Wassenberg
论文简介:Recent works showed that implementations of Quicksort using vector CPU instructions can outperform the non-vectorized algorithms in widespread use./最近的工作表明,使用向量 CPU 指令实现快速排序可以胜过广泛使用的非向量化算法。
论文摘要:Recent works showed that implementations of Quicksort using vector CPU instructions can outperform the non-vectorized algorithms in widespread use. However, these implementations are typically single-threaded, implemented for a particular instruction set, and restricted to a small set of key types. We lift these three restrictions: our proposed ‘vqsort’ algorithm integrates into the state-of-the-art parallel sorter ‘ips4o’, with a geometric mean speedup of 1.59. The same implementation works on seven instruction sets (including SVE and RISC-V V) across four platforms. It also supports floating-point and 16-128 bit integer keys. To the best of our knowledge, this is the fastest sort for non-tuple keys on CPUs, up to 20 times as fast as the sorting algorithms implemented in standard libraries. This paper focuses on the practical engineering aspects enabling the speed and portability, which we have not yet seen demonstrated for a Quicksort implementation. Furthermore, we introduce compact and transpose-free sorting networks for in-register sorting of small arrays, and a vector-friendly pivot sampling strategy that is robust against adversarial input.
最近的工作表明,使用向量 CPU 指令实现快速排序可以胜过广泛使用的非向量化算法。但是,这些实现通常是单线程的,针对特定指令集实现,并且仅限于一小组密钥类型。我们解除了这三个限制:我们提出的“vqsort”算法集成到最先进的并行排序器“ips4o”中,几何平均加速为 1.59。相同的实现适用于四个平台的七个指令集(包括 SVE 和 RISC-V V)。它还支持浮点和 16-128 位整数键。据我们所知,这是 CPU 上非元组键的最快排序,比标准库中实现的排序算法快 20 倍。本文侧重于实现速度和可移植性的实际工程方面,我们尚未看到 Quicksort 实现对此进行了演示。此外,我们引入了紧凑且无转置的排序网络,用于小数组的寄存器内排序,以及一种对对抗性输入具有鲁棒性的向量友好型枢轴采样策略。

我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击这里回复关键字 日报 免费获取AI电子月刊与资料包。

- 作者:韩信子@ShowMeAI
- 历史文章列表
- 专题合辑&电子月刊
- 声明:版权所有,转载请联系平台与作者并注明出处
- 欢迎回复,拜托点赞,留言推荐中有价值的文章、工具或建议,我们都会尽快回复哒~