人工智能 | ShowMeAI资讯日报 #2022.06.08

ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
1.工具&框架

工具库:distributed-faiss - 分布式faiss索引构建库
tags:[faiss,近邻检索,分布式]
‘distributed-faiss - A library for building and serving multi-node distributed faiss indices.’ by Meta Research
GitHub:http://github.com/facebookresearch/distributed-faiss
工具库:Pytorch-Energizer - Pytorch主动学习库
tags:[主动学习,pytorch]
‘Pytorch-Energizer - An active learning library for Pytorch based on Pytorch-Lightning.’ by Pietro Lesci
GitHub:http://github.com/pietrolesci/pytorch-energizer

工具库:solo-learn - Pytorch Lightning 无监督视觉表示学习自监督方法库
tags:[无监督学习,计算机视觉,视觉表示,pytorch]
‘solo-learn - solo-learn: a library of self-supervised methods for visual representation learning powered by Pytorch Lightning’ by Samuel Lavoie
GitHub:http://github.com/lavoiems/simplicial-embeddings

工具库:imodels - 可解释机器学习包,用于简洁、透明和准确的预测建模
tags:[可解释模型,机器学习]
‘Interpretable machine learning models (imodels) - Interpretable ML package for concise, transparent, and accurate predictive modeling (sklearn-compatible).’ by Chandan Singh
GitHub:http://github.com/csinva/imodels

工具库:Quokka - 快速数据处理引擎
'Quokka - a fast data processing engine whose core consists of ~1000 lines of Python code’ by Ziheng Wang
GitHub:http://github.com/marsupialtail/quokka


工具:ShowWhy - 指导用户用观察数据回答因果问题的交互式应用
tags:[因果推断,应用]
'ShowWhy - an interactive application that guides users through the process of answering a causal question using observational data’ by Microsoft
GitHub:http://github.com/microsoft/showwhy
工具:Image-Processing-Node-Editor - 基于节点编辑器的图像/视频处理应用
‘Image-Processing-Node-Editor - An application that performs image processing with the node editor’ by KazuhitoTakahashi
GitHub:http://github.com/Kazuhito00/Image-Processing-Node-Editor
2.项目&代码

项目代码:基于文本的图像生成
tags:[图像生成,基于文本的图像生成]
GitHub:https://github.com/energy-based-model/Compositional-Visual-Generation-with-Composable-Diffusion-Models-PyTorch
项目运行地址:https://colab.research.google.com/github/energy-based-model/Compositional-Visual-Generation-with-Composable-Diffusion-Models-PyTorch/blob/main/notebooks/compose_glide.ipynb

3.博文&分享

教程:(ICASSP 2022 Tutorial Slides)神经文本语音合成
tags:[语音合成,基于文本的语音合成]
‘Neural Text to Speech Synthesis’ by tts-tutorial
GitHub:http://github.com/tts-tutorial/icassp2022


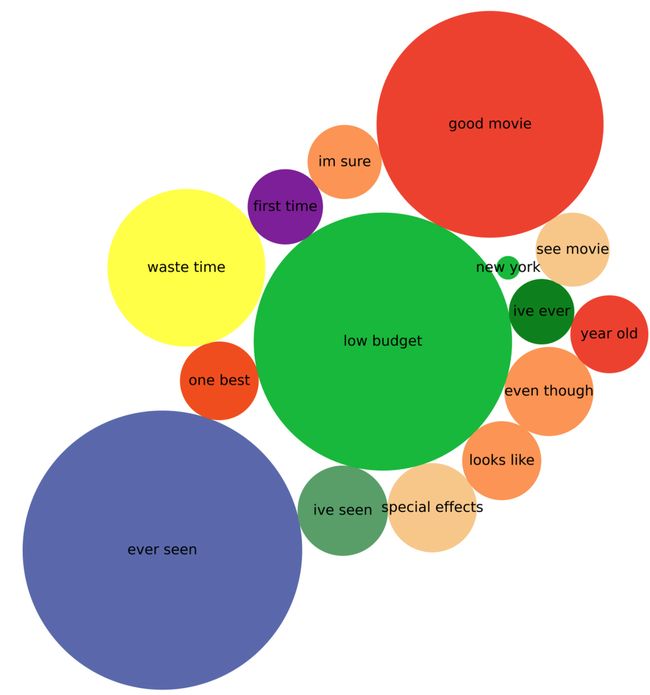
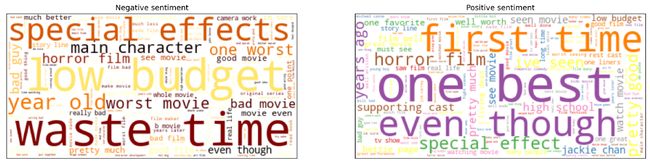
博文:文本数据分析高级可视化
tags:[数据可视化,可视化,文本分析]
《Advanced Visualisations for Text Data Analysis》by Petr Korab
Link:http://towardsdatascience.com/advanced-visualisations-for-text-data-analysis-fc8add8796e2
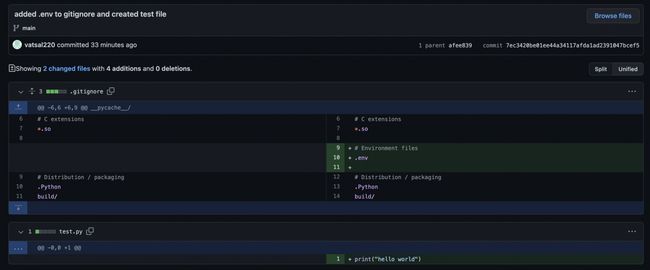
博文:给数据科学家的GitHub综合指南
tags:[GitHub指南,数据科学]
《Comprehensive Guide to GitHub for Data Scientists》by Vasal
Link:http://towardsdatascience.com/comprehensive-guide-to-github-for-data-scientist-d3f71bd320da


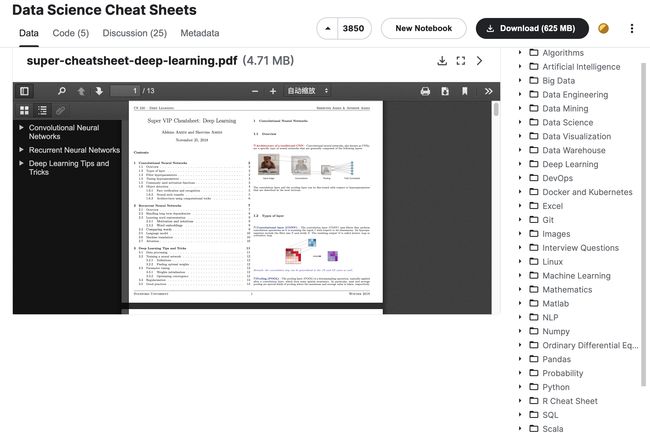
4.数据&资源

资源列表:数据科学速查集锦
tags:[数据科学,速查表,Cheatsheet]
《Data Science Cheat Sheets | Kaggle》
Link:https://www.kaggle.com/datasets/timoboz/data-science-cheat-sheets
资源列表:免费自学数学路线图与资源
tags:[数学,学习路径,资源大全]
‘Path to a free self-taught education in Mathematics!’ by Open Source Society University
GitHub:http://github.com/ossu/math

资源列表:图像质量相关文献列表
tags:[图像质量,质量评估,资源大全]
‘Image-Quality-Related-Papers - A list of image quality related papers published in top conferences and journals’ by Wei Zhou
GitHub:http://github.com/weizhou-geek/Recent-Image-Quality-Related-Papers

5.研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的6月论文合辑。
论文:Compressible-composable NeRF via Rank-residual Decomposition
论文标题:Compressible-composable NeRF via Rank-residual Decomposition
论文时间:30 May 2022
所属领域:计算机视觉
论文地址:https://arxiv.org/abs/2205.14870
代码实现:https://github.com/ashawkey/ccnerf
论文作者:Jiaxiang Tang, Xiaokang Chen, Jingbo Wang, Gang Zeng
论文简介:To circumvent the hurdle, in this paper, we present an explicit neural field representation that enables efficient and convenient manipulation of models. / 为了规避这个障碍,在本文中,我们提出了一种显式的神经场表示,可以有效和方便地操作模型
论文摘要:Neural Radiance Field (NeRF) has emerged as a compelling method to represent 3D objects and scenes for photo-realistic rendering. However, its implicit representation causes difficulty in manipulating the models like the explicit mesh representation. Several recent advances in NeRF manipulation are usually restricted by a shared renderer network, or suffer from large model size. To circumvent the hurdle, in this paper, we present an explicit neural field representation that enables efficient and convenient manipulation of models. To achieve this goal, we learn a hybrid tensor rank decomposition of the scene without neural networks. Motivated by the low-rank approximation property of the SVD algorithm, we propose a rank-residual learning strategy to encourage the preservation of primary information in lower ranks. The model size can then be dynamically adjusted by rank truncation to control the levels of detail, achieving near-optimal compression without extra optimization. Furthermore, different models can be arbitrarily transformed and composed into one scene by concatenating along the rank dimension. The growth of storage cost can also be mitigated by compressing the unimportant objects in the composed scene. We demonstrate that our method is able to achieve comparable rendering quality to state-of-the-art methods, while enabling extra capability of compression and composition. Code will be made available at \url{https://github.com/ashawkey/CCNeRF }.
神经辐射场 (NeRF) 已成为一种令人信服的方法来表示 3D 对象和场景以进行逼真的渲染。然而,它的隐式表示导致难以像显式网格表示那样操作模型。 NeRF 操作的一些最新进展通常受到共享渲染器网络的限制,或者受到大型模型的影响。为了规避这个障碍,在本文中,我们提出了一种显式的神经场表示,可以有效和方便地操作模型。为了实现这一目标,我们在没有神经网络的情况下学习了场景的混合张量秩分解。受 SVD 算法的低秩逼近特性的启发,我们提出了一种秩残差学习策略,以鼓励在较低秩中保存主要信息。然后可以通过等级截断来动态调整模型大小以控制细节级别,从而在不进行额外优化的情况下实现近乎最佳的压缩。此外,不同的模型可以通过沿着等级维度连接任意变换和组合成一个场景。存储成本的增长也可以通过压缩合成场景中不重要的对象来缓解。我们证明我们的方法能够实现与最先进的方法相当的渲染质量,同时实现额外的压缩和合成能力。代码可以在https://github.com/ashawkey/CCNeRF 上获得。
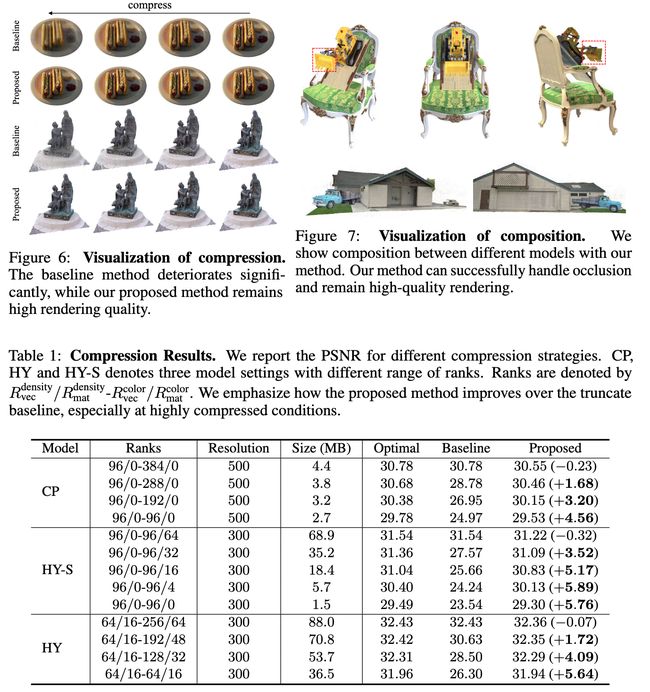
论文:A ConvNet for the 2020s
论文标题:A ConvNet for the 2020s
论文时间:10 Jan 2022
所属领域:计算机视觉
对应任务:Domain Generalization,Image Classification,Object Detection,Semantic Segmentation ,域泛化,图像分类,目标检测,语义分割
论文地址:https://arxiv.org/abs/2201.03545
代码实现:https://github.com/facebookresearch/ConvNeXt ,https://github.com/rwightman/pytorch-image-models , https://github.com/pytorch/vision ,https://github.com/open-mmlab/mmclassification,https://github.com/BR-IDL/PaddleViT/tree/develop/image_classification/ConvNeXt
论文作者:Zhuang Liu, Hanzi Mao, Chao-yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie
论文简介:The “Roaring 20s” of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. / 视觉识别的“鼎盛20年代 ”始于 Vision Transformers (ViTs) 的引入,它迅速取代了 ConvNets,成为最先进的图像分类模型。
论文摘要:The “Roaring 20s” of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers (e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually “modernize” a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
视觉识别的“鼎盛20 年代”始于 Vision Transformers (ViTs) 的引入,它迅速取代了 ConvNets,成为最先进的图像分类模型。另一方面,普通的 ViT 在应用于目标检测和语义分割等一般计算机视觉任务时面临困难。正是分层 Transformers(例如,Swin Transformers)重新引入了几个 ConvNet 先验,使 Transformers 作为通用视觉骨干网络实际上可行,并在各种视觉任务上表现出卓越的性能。然而,这种混合方法的有效性在很大程度上仍归功于 Transformer 的内在优势,而不是卷积固有的归纳偏差。在这项工作中,我们重新检查了设计空间并测试了纯 ConvNet 所能达到的极限。我们逐渐将标准 ResNet “现代化”为视觉 Transformer 的设计,并在此过程中发现了导致性能差异的几个关键组件。这一探索的结果是一系列纯 ConvNet 模型,称为 ConvNeXt。 ConvNeXts 完全由标准 ConvNet 模块构建,在准确性和可扩展性方面与 Transformer 竞争,实现 87.8% ImageNet top-1 准确率,在 COCO 检测和 ADE20K 分割方面优于 Swin Transformers,同时保持标准 ConvNet 的简单性和效率。
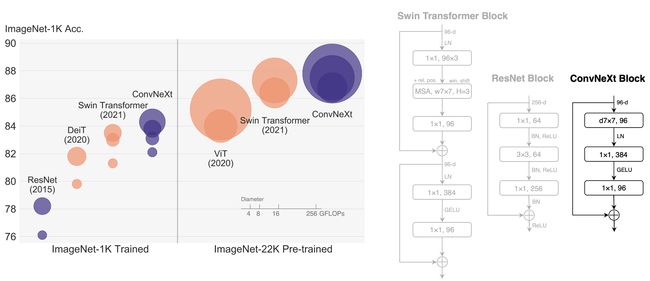
论文:FENeRF: Face Editing in Neural Radiance Fields
论文标题:FENeRF: Face Editing in Neural Radiance Fields
论文时间:30 Nov 2021
所属领域:计算机视觉
对应任务:Image Generation ,图像生成
论文地址:https://arxiv.org/abs/2111.15490
代码实现:https://github.com/MrTornado24/FENeRF
论文作者:Jingxiang Sun, Xuan Wang, Yong Zhang, Xiaoyu Li, Qi Zhang, Yebin Liu, Jue Wang
论文简介:2D GANs can generate high fidelity portraits but with low view consistency. / 2D GAN 可以生成高保真人像,但视图一致性低。
论文摘要:Previous portrait image generation methods roughly fall into two categories: 2D GANs and 3D-aware GANs. 2D GANs can generate high fidelity portraits but with low view consistency. 3D-aware GAN methods can maintain view consistency but their generated images are not locally editable. To overcome these limitations, we propose FENeRF, a 3D-aware generator that can produce view-consistent and locally-editable portrait images. Our method uses two decoupled latent codes to generate corresponding facial semantics and texture in a spatial aligned 3D volume with shared geometry. Benefiting from such underlying 3D representation, FENeRF can jointly render the boundary-aligned image and semantic mask and use the semantic mask to edit the 3D volume via GAN inversion. We further show such 3D representation can be learned from widely available monocular image and semantic mask pairs. Moreover, we reveal that joint learning semantics and texture helps to generate finer geometry. Our experiments demonstrate that FENeRF outperforms state-of-the-art methods in various face editing tasks.
以前的肖像图像生成方法大致分为两类:2D GANs 和 3D-aware GANs。 2D GAN 可以生成高保真人像,但视图一致性低;3D 感知 GAN 方法可以保持视图一致性,但它们生成的图像不能在本地编辑。为了克服这些限制,我们提出了 FENeRF,这是一个 3D 感知生成器,可以生成视图一致和本地可编辑的肖像图像。我们的方法使用两个解耦的潜在代码在具有共享几何的空间对齐 3D 体积中生成相应的面部语义和纹理。受益于这种底层的 3D 表示,FENeRF 可以联合渲染边界对齐的图像和语义掩码,并使用语义掩码通过 GAN 反转来编辑 3D 体积。我们进一步表明,可以从广泛可用的单目图像和语义掩码对中学习这种 3D 表示。此外,我们揭示了联合学习语义和纹理有助于生成更精细的几何图形。我们的实验表明,FENeRF 在各种面部编辑任务中优于最先进的方法。
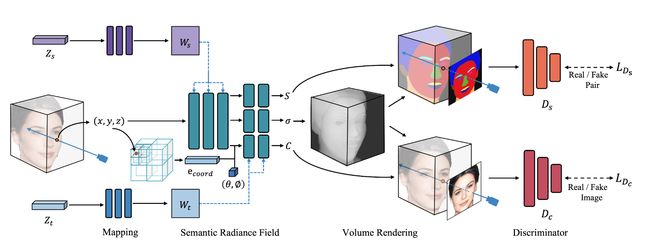
论文:CogView: Mastering Text-to-Image Generation via Transformers
论文标题:CogView: Mastering Text-to-Image Generation via Transformers
论文时间:NeurIPS 2021
所属领域:自然语言处理,计算机视觉
对应任务:Image Generation,Super-Resolution,Text to image generation,Text-to-Image Generation,Zero-Shot Text-to-Image Generation ,图像生成,超分辨率,文本到图像生成,零样本文本到图像生成
论文地址:https://arxiv.org/abs/2105.13290
代码实现:https://github.com/THUDM/CogView , https://github.com/JunnYu/x-transformers-paddle
论文作者:Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, Jie Tang
论文简介:Text-to-Image generation in the general domain has long been an open problem, which requires both a powerful generative model and cross-modal understanding. / 通用领域的文本到图像生成长期以来一直是一个开放的问题,它需要强大的生成模型和跨模态理解。
论文摘要:Text-to-Image generation in the general domain has long been an open problem, which requires both a powerful generative model and cross-modal understanding. We propose CogView, a 4-billion-parameter Transformer with VQ-VAE tokenizer to advance this problem. We also demonstrate the finetuning strategies for various downstream tasks, e.g. style learning, super-resolution, text-image ranking and fashion design, and methods to stabilize pretraining, e.g. eliminating NaN losses. CogView achieves the state-of-the-art FID on the blurred MS COCO dataset, outperforming previous GAN-based models and a recent similar work DALL-E.
通用领域的文本到图像生成长期以来一直是一个开放的问题,它需要强大的生成模型和跨模态理解。我们提出了 CogView,一个带有 VQ-VAE 标记器的 40 亿参数的 Transformer 来解决这个问题。我们还展示了各种下游任务的微调策略,例如风格学习、超分辨率、文本图像排名和时尚设计,以及稳定预训练的方法,例如消除 NaN 损失。 CogView 在模糊的 MS COCO 数据集上实现了目前最好的 FID效果,优于以前基于 GAN 的模型和最近的类似工作 DALL-E。


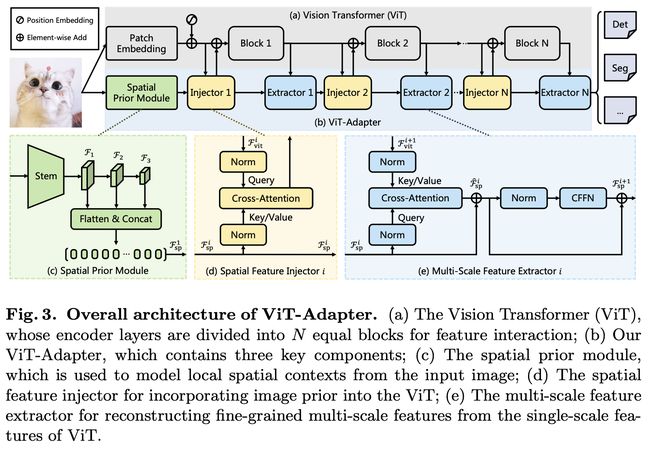
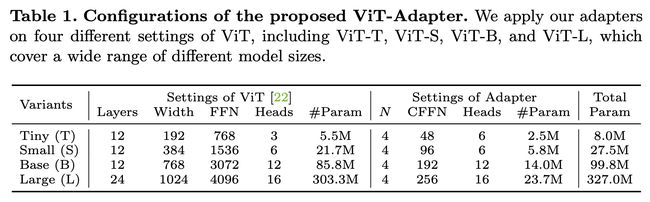
论文:Vision Transformer Adapter for Dense Predictions
论文标题:Vision Transformer Adapter for Dense Predictions
论文时间:17 May 2022
所属领域:Computer Vision / 计算机视觉
对应任务:Instance Segmentation,Object Detection,Semantic Segmentation ,实例分割,目标检测,语义分割
论文地址:https://arxiv.org/abs/2205.08534
代码实现:https://github.com/czczup/vit-adapter
论文作者:Zhe Chen, Yuchen Duan, Wenhai Wang, Junjun He, Tong Lu, Jifeng Dai, Yu Qiao
论文简介:When fine-tuning on downstream tasks, a modality-specific adapter is used to introduce the data and tasks’ prior information into the model, making it suitable for these tasks. / 在对下游任务进行微调时,使用特定于模态的适配器将数据和任务的先验信息引入模型,使其适用于这些任务。
论文摘要:This work investigates a simple yet powerful adapter for Vision Transformer (ViT). Unlike recent visual transformers that introduce vision-specific inductive biases into their architectures, ViT achieves inferior performance on dense prediction tasks due to lacking prior information of images. To solve this issue, we propose a Vision Transformer Adapter (ViT-Adapter), which can remedy the defects of ViT and achieve comparable performance to vision-specific models by introducing inductive biases via an additional architecture. Specifically, the backbone in our framework is a vanilla transformer that can be pre-trained with multi-modal data. When fine-tuning on downstream tasks, a modality-specific adapter is used to introduce the data and tasks’ prior information into the model, making it suitable for these tasks. We verify the effectiveness of our ViT-Adapter on multiple downstream tasks, including object detection, instance segmentation, and semantic segmentation. Notably, when using HTC++, our ViT-Adapter-L yields 60.1 box AP and 52.1 mask AP on COCO test-dev, surpassing Swin-L by 1.4 box AP and 1.0 mask AP. For semantic segmentation, our ViT-Adapter-L establishes a new state-of-the-art of 60.5 mIoU on ADE20K val, 0.6 points higher than SwinV2-G. We hope that the proposed ViT-Adapter could serve as an alternative for vision-specific transformers and facilitate future research. The code and models will be released at https://github.com/czczup/ViT-Adapter
这项工作研究了一个简单而强大的 Vision Transformer (ViT) 适配器。与最近将视觉特定的归纳偏差引入其架构的视觉转换器不同,ViT 由于缺乏图像的先验信息,在密集预测任务上的性能较差。为了解决这个问题,我们提出了一种视觉转换器适配器(ViT-Adapter),它可以通过额外的架构引入归纳偏差来弥补 ViT 的缺陷并实现与视觉特定模型相当的性能。具体来说,我们框架中的主干是一个普通的Transformer,可以使用多模态数据进行预训练。在对下游任务进行微调时,使用特定于模态的适配器将数据和任务的先验信息引入模型,使其适用于这些任务。我们验证了 ViT-Adapter 在多个下游任务上的有效性,包括对象检测、实例分割和语义分割。值得注意的是,当使用 HTC++ 时,我们的 ViT-Adapter-L 在 COCO test-dev 上产生 60.1 box AP 和 52.1 mask AP,超过 Swin-L 1.4 box AP 和 1.0 mask AP。对于语义分割,我们的 ViT-Adapter-L 在 ADE20K val 上建立了新的 60.5 mIoU,比 SwinV2-G 高 0.6 个点。我们希望所提出的 ViT-Adapter 可以作为视觉特定Transformer的替代品,并促进未来的研究。代码和模型可以在 https://github.com/czczup/ViT-Adapter 获取
论文:Palette: Image-to-Image Diffusion Models
论文标题:Palette: Image-to-Image Diffusion Models
论文时间:10 Nov 2021
所属领域:Computer Vision / 计算机视觉
对应任务:Colorization,Denoising,Image-to-Image Translation,JPEG Decompression,Perceptual Distance,Translation,Uncropping ,着色,上色,去噪,图像到图像转换,JPEG解压缩,感知距离,平移,去裁剪
论文地址:https://arxiv.org/abs/2111.05826
代码实现:https://github.com/LouisRouss/Diffusion-Based-Model-for-Colorization , https://github.com/Janspiry/Palette-Image-to-Image-Diffusion-Models
论文作者:Chitwan Saharia, William Chan, Huiwen Chang, Chris A. Lee, Jonathan Ho, Tim Salimans, David J. Fleet, Mohammad Norouzi
论文简介:We expect this standardized evaluation protocol to play a role in advancing image-to-image translation research. / 我们希望这种标准化的评估协议能够在推进图像到图像的翻译研究中发挥作用。
论文摘要:This paper develops a unified framework for image-to-image translation based on conditional diffusion models and evaluates this framework on four challenging image-to-image translation tasks, namely colorization, inpainting, uncropping, and JPEG restoration. Our simple implementation of image-to-image diffusion models outperforms strong GAN and regression baselines on all tasks, without task-specific hyper-parameter tuning, architecture customization, or any auxiliary loss or sophisticated new techniques needed. We uncover the impact of an L2 vs. L1 loss in the denoising diffusion objective on sample diversity, and demonstrate the importance of self-attention in the neural architecture through empirical studies. Importantly, we advocate a unified evaluation protocol based on ImageNet, with human evaluation and sample quality scores (FID, Inception Score, Classification Accuracy of a pre-trained ResNet-50, and Perceptual Distance against original images). We expect this standardized evaluation protocol to play a role in advancing image-to-image translation research. Finally, we show that a generalist, multi-task diffusion model performs as well or better than task-specific specialist counterparts. Check out https://diffusion-palette.github.io for an overview of the results.
本文基于条件扩散模型开发了一个统一的图像到图像转换框架,并在四个具有挑战性的图像到图像转换任务上评估了该框架,即着色、修复、取消裁剪和 JPEG 恢复。我们简单实现的图像到图像扩散模型在所有任务上都优于强大的 GAN 和回归基线,无需特定任务的超参数调整、架构定制或任何辅助损失或所需的复杂新技术。我们揭示了去噪扩散目标中 L2 与 L1 损失对样本多样性的影响,并通过实证研究证明了自注意力在神经结构中的重要性。重要的是,我们提倡基于 ImageNet 的统一评估协议,具有人工评估和样本质量分数(FID、初始分数、预训练 ResNet-50 的分类准确度以及与原始图像的感知距离)。我们希望这种标准化的评估协议能够在推进图像到图像的翻译研究中发挥作用。最后,我们展示了通才、多任务扩散模型的性能与特定任务的专家模型一样好或更好。查看 https://diffusion-palette.github.io 了解论文结果概述。
论文:Real-time Multi-Adaptive-Resolution-Surfel 6D LiDAR Odometry using Continuous-time Trajectory Optimization
论文标题:Real-time Multi-Adaptive-Resolution-Surfel 6D LiDAR Odometry using Continuous-time Trajectory Optimization
论文时间:5 May 2021
所属领域:Computer Vision / 计算机视觉
对应任务:Simultaneous Localization and Mapping ,同时定位和映射
论文地址:https://arxiv.org/abs/2105.02010
代码实现:https://github.com/ais-bonn/lidar_mars_registration
论文作者:Jan Quenzel, Sven Behnke
论文简介:Simultaneous Localization and Mapping (SLAM) is an essential capability for autonomous robots, but due to high data rates of 3D LiDARs real-time SLAM is challenging. / 同步定位和映射 (SLAM) 是自主机器人的基本能力,但由于 3D LiDAR 的高数据速率,实时 SLAM 具有挑战性。
论文摘要:Simultaneous Localization and Mapping (SLAM) is an essential capability for autonomous robots, but due to high data rates of 3D LiDARs real-time SLAM is challenging. We propose a real-time method for 6D LiDAR odometry. Our approach combines a continuous-time B-Spline trajectory representation with a Gaussian Mixture Model (GMM) formulation to jointly align local multi-resolution surfel maps. Sparse voxel grids and permutohedral lattices ensure fast access to map surfels, and an adaptive resolution selection scheme effectively speeds up registration. A thorough experimental evaluation shows the performance of our approach on multiple datasets and during real-robot experiments.
同步定位和映射 (SLAM) 是自主机器人的基本能力,但由于 3D LiDAR 的高数据速率,实时 SLAM 具有挑战性。我们提出了一种用于 6D LiDAR 里程计的实时方法。我们的方法将连续时间 B 样条轨迹表示与高斯混合模型 (GMM) 公式相结合,以联合对齐局部多分辨率面元图。稀疏体素网格和 permutohedral 晶格确保快速访问地图面元,自适应分辨率选择方案有效地加快了配准。并通过充分的实验评估了我们的方法在多个数据集和真实机器人实验中的性能。

论文:Architecture-Agnostic Masked Image Modeling – From ViT back to CNN
论文标题:Architecture-Agnostic Masked Image Modeling – From ViT back to CNN
论文时间:27 May 2022
所属领域:计算机视觉
对应任务:图像识别,目标检测,语义分割
论文地址:https://arxiv.org/abs/2205.13943
代码实现:https://github.com/Westlake-AI/openmixup
论文作者:Siyuan Li, Di wu, Fang Wu, Zelin Zang, Kai Wang, Lei Shang, Baigui Sun, Hao Li, Stan. Z. Li
论文简介:We observe that MIM essentially teaches the model to learn better middle-level interactions among patches and extract more generalized features. / 我们观察到 MIM 本质上是在教模型学习更好的补丁之间的中级交互并提取更通用的特征。
论文摘要:Masked image modeling (MIM), an emerging self-supervised pre-training method, has shown impressive success across numerous downstream vision tasks with Vision transformers (ViT). Its underlying idea is simple: a portion of the input image is randomly masked out and then reconstructed via the pre-text task. However, why MIM works well is not well explained, and previous studies insist that MIM primarily works for the Transformer family but is incompatible with CNNs. In this paper, we first study interactions among patches to understand what knowledge is learned and how it is acquired via the MIM task. We observe that MIM essentially teaches the model to learn better middle-level interactions among patches and extract more generalized features. Based on this fact, we propose an Architecture-Agnostic Masked Image Modeling framework (A2MIM), which is compatible with not only Transformers but also CNNs in a unified way. Extensive experiments on popular benchmarks show that our A2MIM learns better representations and endows the backbone model with the stronger capability to transfer to various downstream tasks for both Transformers and CNNs.
掩码(遮蔽)图像建模 (MIM) 是一种新兴的自我监督预训练方法,使用视觉transformer (ViT) 在众多下游视觉任务中取得了令人瞩目的成功。它的基本思想很简单:输入图像的一部分被随机遮蔽,然后通过前置任务重建。然而,为什么 MIM 运作良好并没有得到很好的解释,之前的研究坚持认为 MIM 主要适用于 Transformer 系列,但与 CNN 不兼容。在本文中,我们首先研究补丁之间的交互,以了解学习了哪些知识以及如何通过 MIM 任务获取知识。我们观察到 MIM 本质上是在教模型学习更好的补丁之间的中级交互并提取更通用的特征。基于这一事实,我们提出了一种与架构无关的遮蔽图像建模框架 (A2MIM),它不仅兼容 Transformer,还以统一的方式兼容 CNN。对流行基准的广泛实验表明,我们的 A2MIM 学习了更好的表示,并赋予主干模型更强的能力来转移到 Transformer 和 CNN 的各种下游任务。


论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
论文标题:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
论文时间:NeurIPS 2020
所属领域:Natural Language Processing / 自然语言处理
对应任务:Fact Verification,Question Answering,Text Generation ,事实验证,问答,文本生成
论文地址:https://arxiv.org/abs/2005.11401
代码实现:https://github.com/huggingface/transformers , https://github.com/deepset-ai/haystack
论文作者:Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela
论文简介:Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks. / 大型预训练语言模型已被证明可以在其参数中存储事实知识,并在对下游 NLP 任务进行微调时获得最先进的结果。
论文摘要:Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely manipulate knowledge is still limited, and hence on knowledge-intensive tasks, their performance lags behind task-specific architectures. Additionally, providing provenance for their decisions and updating their world knowledge remain open research problems. Pre-trained models with a differentiable access mechanism to explicit non-parametric memory can overcome this issue, but have so far been only investigated for extractive downstream tasks. We explore a general-purpose fine-tuning recipe for retrieval-augmented generation (RAG) – models which combine pre-trained parametric and non-parametric memory for language generation. We introduce RAG models where the parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. We compare two RAG formulations, one which conditions on the same retrieved passages across the whole generated sequence, the other can use different passages per token. We fine-tune and evaluate our models on a wide range of knowledge-intensive NLP tasks and set the state-of-the-art on three open domain QA tasks, outperforming parametric seq2seq models and task-specific retrieve-and-extract architectures. For language generation tasks, we find that RAG models generate more specific, diverse and factual language than a state-of-the-art parametric-only seq2seq baseline.
大型预训练语言模型已被证明可以在其参数中存储事实知识,并在对下游 NLP 任务进行微调时获得最先进的结果。然而,它们访问和精确操作知识的能力仍然有限,因此在知识密集型任务上,它们的性能落后于特定任务结构的架构。此外,为他们的决定提供出处和更新他们的世界知识仍然是开放的研究问题。具有显式非参数内存的可微分访问机制的预训练模型可以克服这个问题,但迄今为止仅针对抽取式下游任务进行了研究。我们探索了一种用于检索增强生成 (RAG) 的通用微调方法——将预训练的参数和非参数记忆结合起来用于语言生成的模型。我们介绍了 RAG 模型,其中参数记忆是预训练的 seq2seq 模型,非参数记忆是维基百科的密集向量索引,可通过预训练的神经检索器访问。我们比较了两种 RAG 公式,一种以整个生成序列中相同的检索段落为条件,另一种可以对每个标记使用不同的段落。我们在广泛的知识密集型 NLP 任务上微调和评估我们的模型,并在三个开放域 QA 任务上设置最先进的模型,优于参数 seq2seq 模型和特定任务的检索和提取架构。对于语言生成任务,我们发现 RAG 模型生成的语言比最先进的仅参数 seq2seq 基线更具体、多样和真实。
论文:OPT: Open Pre-trained Transformer Language Models
论文标题:OPT: Open Pre-trained Transformer Language Models
论文时间:2 May 2022
所属领域:Natural Language Processing / 自然语言处理
对应任务:Hate Speech Detection,Language Modelling,Stereotypical Bias Analysis ,仇恨言论检测,语言建模,刻板偏见分析
论文地址:https://arxiv.org/abs/2205.01068
代码实现:https://github.com/facebookresearch/metaseq
论文作者:Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, Luke Zettlemoyer
论文简介:Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. / 大型语言模型通常经过数十万个计算日的训练,在零样本和少样本学习方面表现出非凡的能力。
论文摘要:Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.
大型语言模型通常经过数十万个计算日的训练,在零样本和少样本学习方面表现出非凡的能力。考虑到它们的计算成本,如果没有大量资金,这些模型很难复制。对于通过 API 可用的少数几个,无法访问完整的模型权重,这使得它们难以研究。我们展示了开放式预训练Transformer (OPT),这是一套仅解码器的预训练Transformer,参数范围从 125M 到 175B,我们的目标是与感兴趣的研究人员充分和负责任地共享。我们表明 OPT-175B 与 GPT-3 相当,而开发所需的碳足迹仅为 1/7。我们还将发布日志,详细说明我们面临的基础设施挑战,以及用于试验所有已发布模型的代码。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。

- 作者:韩信子@ShowMeAI
- 历史文章列表
- 专题合辑&电子月刊
- 声明:版权所有,转载请联系平台与作者并注明出处
- 欢迎回复,拜托点赞,留言推荐中有价值的文章、工具或建议,我们都会尽快回复哒~