人工智能 | ShowMeAI资讯日报 #2022.06.10

ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
1.工具&框架

工具库:tsai - 基于Pytorch & fastai的深度学习时序处理库
tags: [深度学习,时间序列,pytorch,fastai]
‘tsai - Time series Timeseries Deep Learning Machine Learning Pytorch fastai | State-of-the-art Deep Learning library for Time Series and Sequences in Pytorch / fastai’ by timeseriesAI
GitHub: https://github.com/timeseriesAI/tsai

工具库:FlagAI - 快速、易于使用和可扩展的大模型工具包,目标是支持在多模态的各种下游任务上训练、微调和部署大规模模型
tags: [大模型,微调,部署,下游任务]
‘FlagAI - FlagAI (Fast LArge-scale General AI models) is a fast, easy-to-use and extensible toolkit for large-scale models.’ by BAAI-Open
GitHub: https://github.com/BAAI-Open/FlagAI

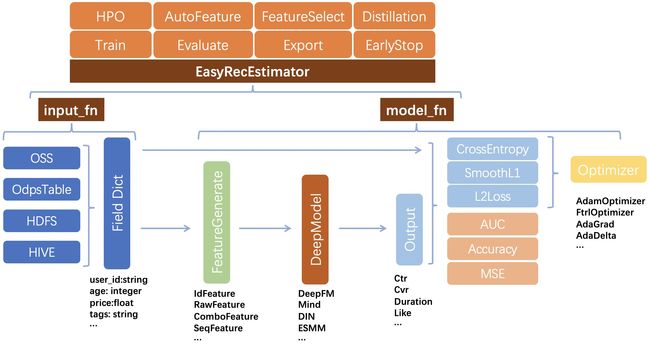
工具库:EasyRec - 深度学习推荐算法框架,支持大规模训练、评估、导出和部署
tags: [推荐系统,智能推荐,召回,排序,多目标优化]
EasyRec是阿里巴巴开源的针对推荐任务的工具库,实现了推荐过程中的一些先进的深度学习模型:召回(匹配)、排序(评分)和多任务学习。它通过简单的配置和超参数调整(HPO)提高了生成高性能模型的效率。实现了以下算法:
- 召回:DSSM / MIND / DropoutNet / CoMetricLearningI2I
- 排序:W&D / DeepFM / MultiTower / DCN / DIN / BST
- 多目标优化:MMoE / ESMM / DBMTL / PLE
GitHub: https://github.com/AlibabaPAI/EasyRec
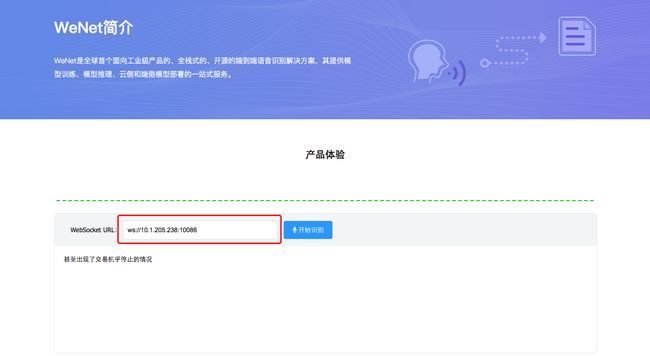
工具库:WeNet - 面向工业落地应用的语音识别工具包,提供了从语音识别模型的训练到部署的一条龙服务
tags: [深度学习,语音识别,训练,部署]
WeNet 是一款面向工业落地应用的语音识别工具包,提供了从语音识别模型的训练到部署的一条龙服务,其主要特点如下:
- 使用 conformer 网络结构和 CTC/attention loss 联合优化方法,统一的流式/非流式语音识别方案,具有业界一流的识别效果。
- 提供云上和端上直接部署的方案,最小化模型训练和产品落地之间的工程工作。
- 框架简洁,模型训练部分完全基于 pytorch 生态,不依赖于 kaldi 等复杂的工具。
- 详细的注释和文档,非常适合用于学习端到端语音识别的基础知识和实现细节。
- 支持时间戳,对齐,端点检测,语言模型等相关功能。
‘WeNet - Production First and Production Ready End-to-End Speech Recognition Toolkit’ by WeNet Open Source Community
GitHub: https://github.com/wenet-e2e/wenet
对应论文:《WeNet: Production First and Production Ready End-to-End Speech Recognition Toolkit》
工具库:AutoTrader - 旨在帮助开发、优化和部署自动交易系统的Python平台
tags: [自动交易,量化]
‘AutoTrader - A Python-based development platform for automated trading systems - from backtesting to optimisation to livetrading.’ by Kieran Mackle
GitHub: https://github.com/kieran-mackle/AutoTrader

工具库:Wrangl - NLP 和机器学习的并行数据预处理
tags: [数据预处理,并行计算]
‘Wrangl - Parallel data preprocessing for NLP and ML.’ by Victor Zhong
GitHub: https://github.com/vzhong/wrangl

2.项目&代码

项目:ONNX-HybridNets-Multitask-Road-Detection 多目标混合网络道路检测(分割)
tags: [ONNX,目标检测,道路分割,车道线检测,自动驾驶]
Python scripts for performing road segmentation and car detection using the HybridNets multitask model in ONNX.’ by Ibai Gorordo
GitHub: https://github.com/ibaiGorordo/ONNX-HybridNets-Multitask-Road-Detection

3.博文&分享

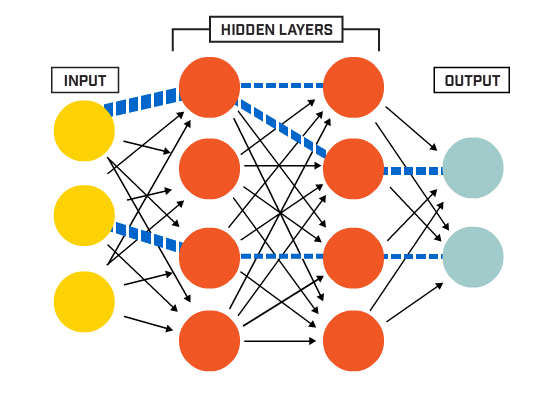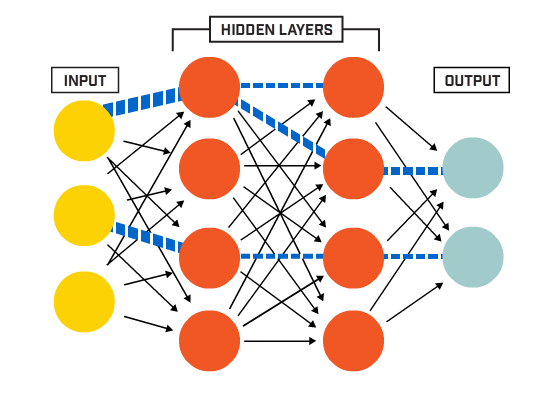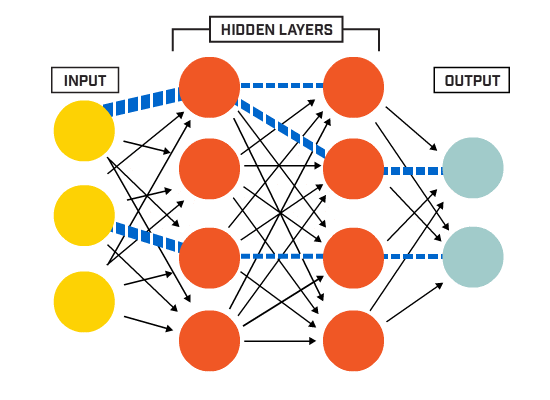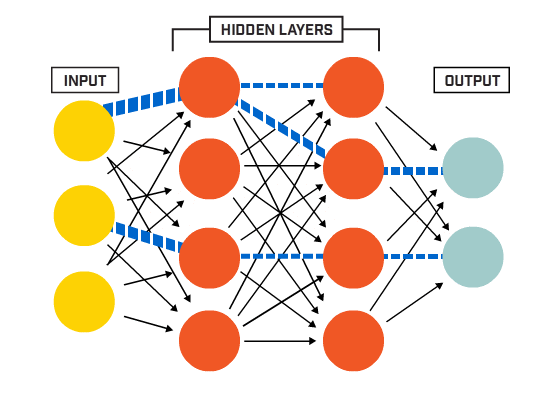
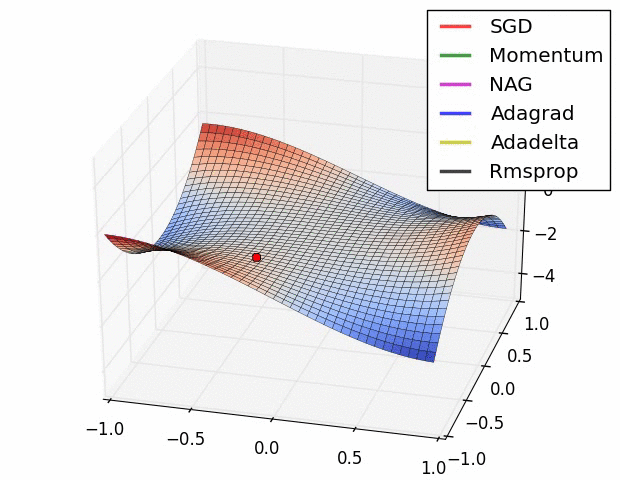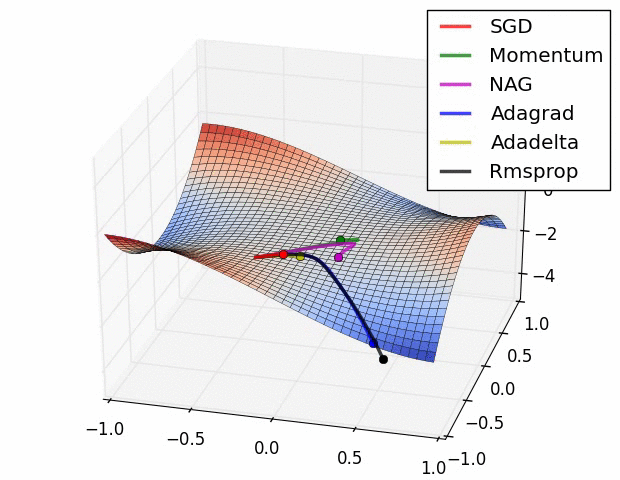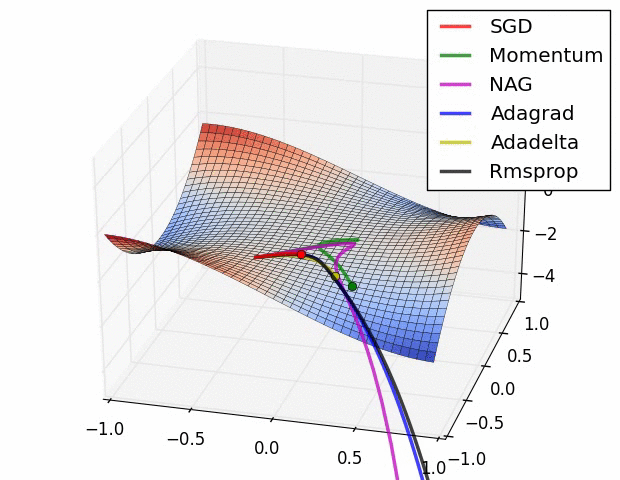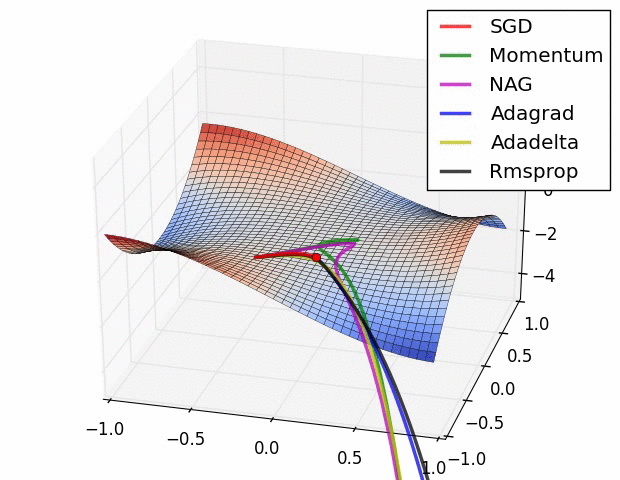
笔记:Andrew NG深度学习专项课程手写笔记
tags: [深度学习,吴恩达,笔记]
‘Andrew NG Notes Collection - This is Andrew NG Coursera Handwritten Notes.’ by Ashish Patel
GitHub: https://github.com/ashishpatel26/Andrew-NG-Notes


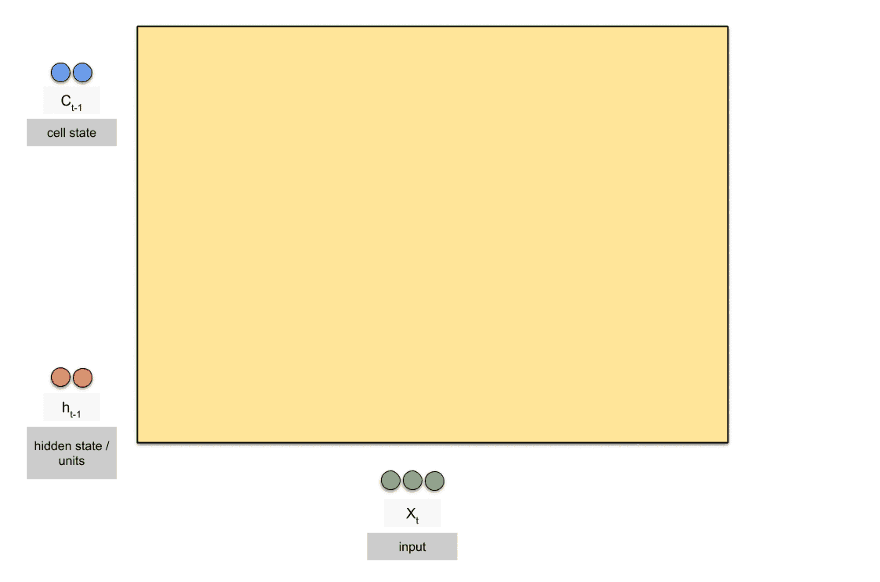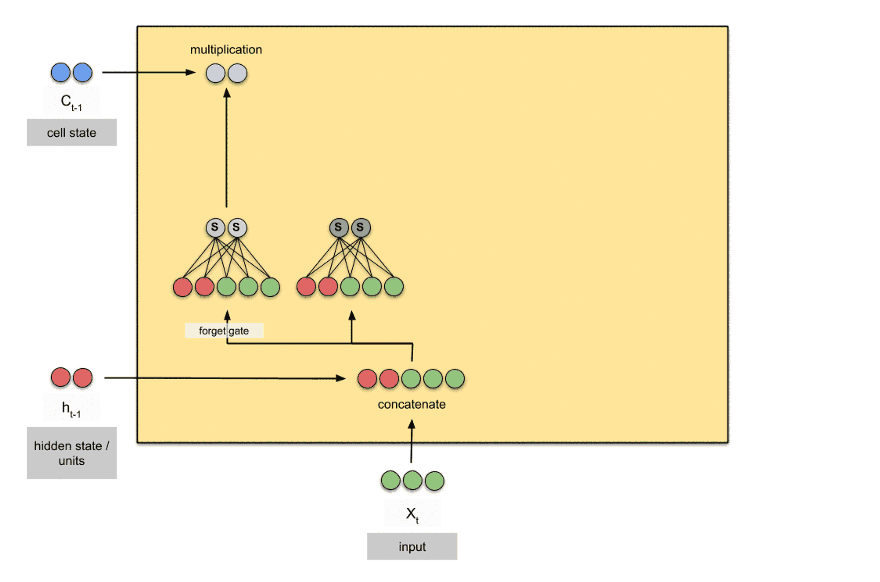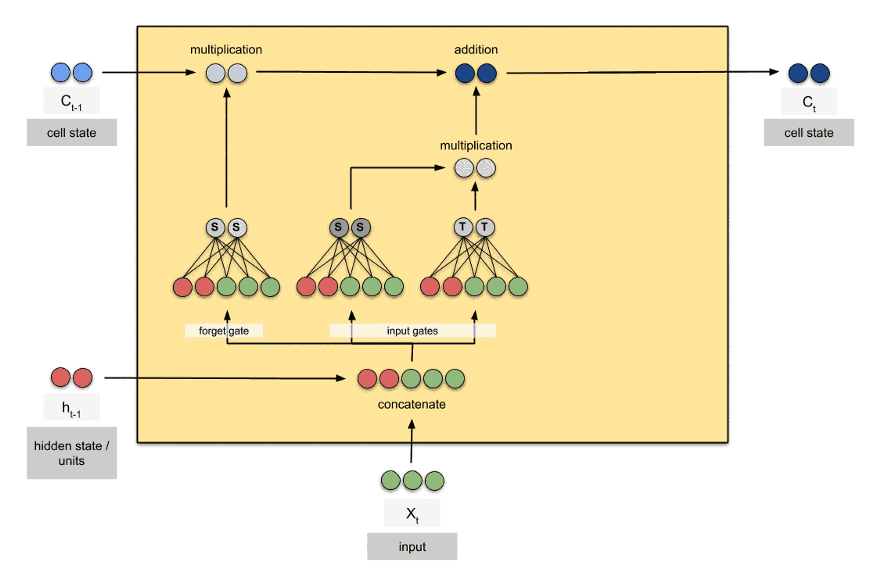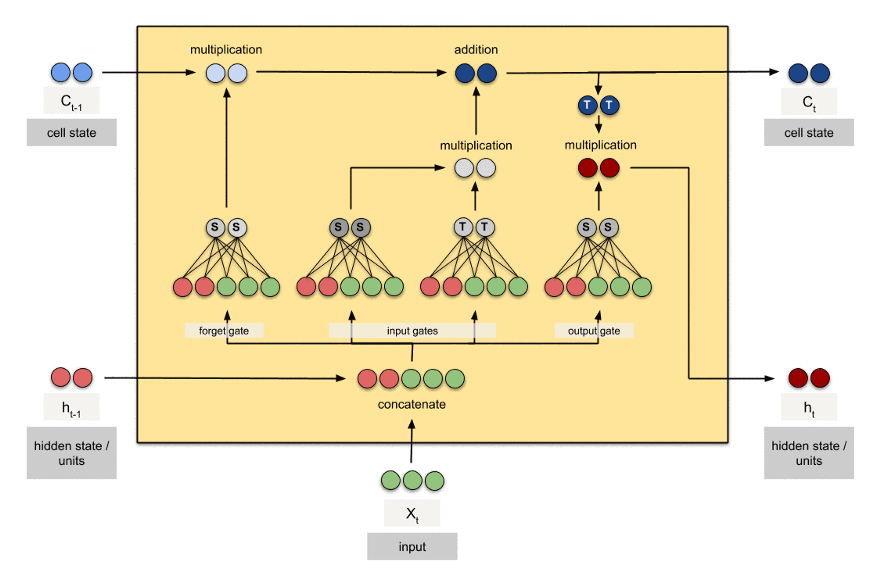
4.数据&资源

资源列表:主动学习相关资源大列表
tags: [主动学习,资源大全]
‘Awesome Active Learning - Hope you can find everything you need about active learning in this repository.’ by SupeRuier
GitHub: https://github.com/SupeRuier/awesome-active-learning

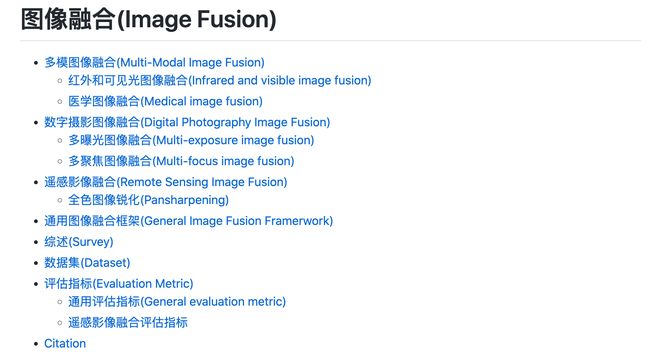
资源列表:图像融合(Image Fusion)相关工作/资源整理
tags: [图像融合,资源大全]
‘Deep Learning-based Image Fusion: A Survey’ by Linfeng Tang
GitHub: https://github.com/Linfeng-Tang/Image-Fusion
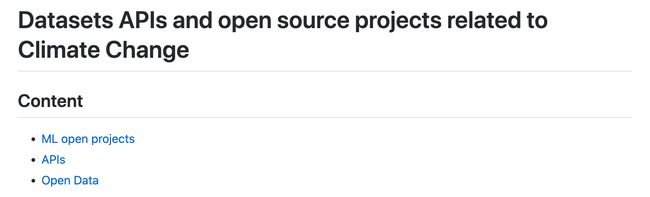
资源列表:与气候变化相关的数据集 API 和开源项目列表
tags: [气候变化,数据,资源大全]
‘Datasets APIs and open source projects related to Climate Change - A curated list of APIs, open data and ML/AI projects on climate change’ by Kasia
GitHub: https://github.com/KKulma/climate-change-data
资源列表:Awesome-Point-Cloud-Scene-Flow - 点云场景流相关论文列表
tags: [点云,资源大全
‘Awesome-Point-Cloud-Scene-Flow - A list of point cloud scene flow papers, codes and datasets.’ by Jiadai Sun
GitHub: https://github.com/MaxChanger/awesome-point-cloud-scene-flow
资源:健康学习到150岁 - 人体系统调优不完全指南
tags: [健康,程序员健康,资源]
GitHub: https://github.com/zijie0/HumanSystemOptimization

5.研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的6月论文合辑。
论文:Bongard-HOI: Benchmarking Few-Shot Visual Reasoning for Human-Object Interactions
论文标题:Bongard-HOI: Benchmarking Few-Shot Visual Reasoning for Human-Object Interactions
论文时间:27 May 2022
所属领域:计算机视觉
对应任务:Few-Shot Image Classification,Few-Shot Learning,Human-Object Interaction Detection,Representation Learning,Visual Reasoning,Few-Shot 图像分类,Few-Shot 学习,人物交互检测,表示学习,视觉推理
论文地址:https://arxiv.org/abs/2205.13803
代码实现:https://github.com/nvlabs/bongard-hoi
论文作者:Huaizu Jiang, Xiaojian Ma, Weili Nie, Zhiding Yu, Yuke Zhu, Anima Anandkumar
论文简介:A significant gap remains between today’s visual pattern recognition models and human-level visual cognition especially when it comes to few-shot learning and compositional reasoning of novel concepts. / 当今的视觉模式识别模型和人类水平的视觉认知之间仍然存在很大差距,尤其是在涉及新概念的小样本学习和组合推理时。
论文摘要:A significant gap remains between today’s visual pattern recognition models and human-level visual cognition especially when it comes to few-shot learning and compositional reasoning of novel concepts. We introduce Bongard-HOI, a new visual reasoning benchmark that focuses on compositional learning of human-object interactions (HOIs) from natural images. It is inspired by two desirable characteristics from the classical Bongard problems (BPs): 1) few-shot concept learning, and 2) context-dependent reasoning. We carefully curate the few-shot instances with hard negatives, where positive and negative images only disagree on action labels, making mere recognition of object categories insufficient to complete our benchmarks. We also design multiple test sets to systematically study the generalization of visual learning models, where we vary the overlap of the HOI concepts between the training and test sets of few-shot instances, from partial to no overlaps. Bongard-HOI presents a substantial challenge to today’s visual recognition models. The state-of-the-art HOI detection model achieves only 62% accuracy on few-shot binary prediction while even amateur human testers on MTurk have 91% accuracy. With the Bongard-HOI benchmark, we hope to further advance research efforts in visual reasoning, especially in holistic perception-reasoning systems and better representation learning.
当今的视觉模式识别模型与人类水平的视觉认知之间仍然存在显着差距,尤其是在涉及新概念的小样本学习和组合推理时。我们推出了 Bongard-HOI,这是一种新的视觉推理基准,专注于从自然图像中进行人与对象交互 (HOI) 的组合学习。它受到经典 Bongard 问题 (BP) 的两个特征的启发:1) 小样本概念学习,以及 2) 上下文相关推理。我们仔细策划了带有hard负例样本的少数实例,其中正样本和负样本图像仅在动作标签上存在分歧,使得仅仅识别对象类别不足以完成我们的基准测试。我们还设计了多个测试集来系统地研究视觉学习模型的泛化,其中我们改变了训练集和测试集之间的 HOI 概念的重叠,从部分重叠到没有重叠。 Bongard-HOI 对当今的视觉识别模型提出了重大挑战。最先进的 HOI 检测模型在小样本二元预测上仅达到 62% 的准确度,而即使是 MTurk 上的业余人类测试人员也有 91% 的准确度。通过 Bongard-HOI 基准,我们希望进一步推进视觉推理的研究工作,特别是在整体感知推理系统和更好的表示学习方面。
论文:Masked Autoencoders Are Scalable Vision Learners
论文标题:Masked Autoencoders Are Scalable Vision Learners
论文时间:11 Nov 2021
所属领域:计算机视觉
对应任务:Domain Generalization,Image Classification,Object Detection,Self-Supervised Image Classification,Self-Supervised Learning,Semantic Segmentation,领域泛化,图像分类,目标检测,自监督图像分类,自监督学习,语义分割
论文地址:https://arxiv.org/abs/2111.06377
代码实现:https://github.com/facebookresearch/mae , https://github.com/pengzhiliang/MAE-pytorch , https://github.com/keras-team/keras-io/blob/master/examples/vision/masked_image_modeling.py , https://github.com/BR-IDL/PaddleViT , https://github.com/alibaba/EasyCV
论文作者:Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick
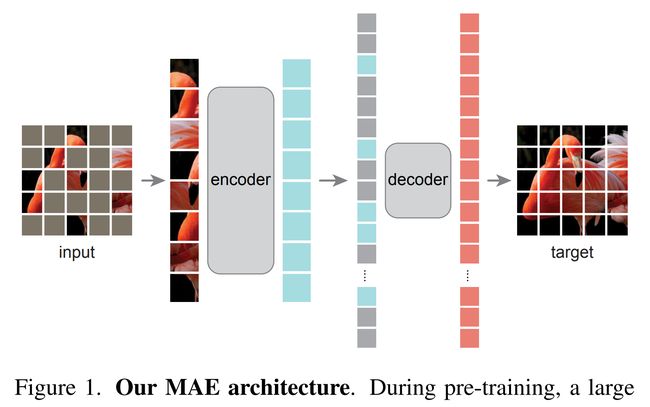
论文简介:Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. / 我们的 MAE 方法很简单:我们屏蔽输入图像的随机补丁并重建丢失的像素。
论文摘要:This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs enables us to train large models efficiently and effectively: we accelerate training (by 3x or more) and improve accuracy. Our scalable approach allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream tasks outperforms supervised pre-training and shows promising scaling behavior.
本文表明,掩蔽自编码器 (MAE) 是用于计算机视觉的可扩展自监督学习器。我们的 MAE 方法很简单:我们屏蔽输入图像的随机区域并重建丢失的像素。它基于两个核心设计。首先,我们开发了一个非对称的编码器-解码器架构,其中一个编码器只对可见的区域子集(没有掩码令牌)进行操作,以及一个轻量级解码器,它从潜在表示和掩码令牌重建原始图像。其次,我们发现屏蔽输入图像的高比例,例如 75%,会产生一个重要且有意义的自监督任务。结合这两种设计使我们能够高效地训练大型模型:我们加速训练(3 倍或更多)并提高准确性。我们的可扩展方法允许学习泛化良好的大容量模型:例如,在仅使用 ImageNet-1K 数据的方法中,vanilla ViT-Huge 模型实现了最佳精度 (87.8%)。下游任务中的迁移性能优于有监督的预训练,并显示出有希望的扩展行为。
论文:BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
论文标题:BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
论文时间:31 Mar 2022
所属领域:Computer Vision / 计算机视觉
对应任务:3D Object Detection,Autonomous Driving,3D物体检测,自动驾驶
论文地址:https://arxiv.org/abs/2203.17270
代码实现:https://github.com/zhiqi-li/BEVFormer
论文作者:Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, Jifeng Dai
论文简介:In a nutshell, BEVFormer exploits both spatial and temporal information by interacting with spatial and temporal space through predefined grid-shaped BEV queries. / 简而言之,BEVFormer 通过预定义的网格形 BEV 查询与空间和时间空间交互,利用空间和时间信息。
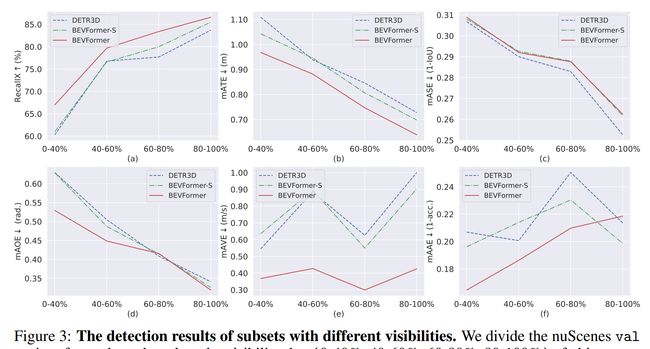
论文摘要:3D visual perception tasks, including 3D detection and map segmentation based on multi-camera images, are essential for autonomous driving systems. In this work, we present a new framework termed BEVFormer, which learns unified BEV representations with spatiotemporal transformers to support multiple autonomous driving perception tasks. In a nutshell, BEVFormer exploits both spatial and temporal information by interacting with spatial and temporal space through predefined grid-shaped BEV queries. To aggregate spatial information, we design a spatial cross-attention that each BEV query extracts the spatial features from the regions of interest across camera views. For temporal information, we propose a temporal self-attention to recurrently fuse the history BEV information. Our approach achieves the new state-of-the-art 56.9% in terms of NDS metric on the nuScenes test set, which is 9.0 points higher than previous best arts and on par with the performance of LiDAR-based baselines. We further show that BEVFormer remarkably improves the accuracy of velocity estimation and recall of objects under low visibility conditions. The code will be released at https://github.com/zhiqi-li/BEVFormer
3D 视觉感知任务,包括基于多摄像头图像的 3D 检测和地图分割,对于自动驾驶系统至关重要。在这项工作中,我们提出了一个名为 BEVFormer 的新框架,它使用时空变换器学习统一的 BEV 表示,以支持多个自动驾驶感知任务。简而言之,BEVFormer 通过预定义的网格形 BEV 查询与空间和时间空间交互,利用空间和时间信息。为了聚合空间信息,我们设计了一个空间交叉注意,每个 BEV 查询从相机视图的感兴趣区域中提取空间特征。对于时间信息,我们提出了一种时间自注意力来反复融合历史 BEV 信息。我们的方法在 nuScenes 测试集的 NDS 指标方面实现了新的最先进的 56.9%,比以前的最佳方法高 9.0 分,与基于 LiDAR 的基线的性能相当。我们进一步表明,BEVFormer 在低能见度条件下显着提高了速度估计和对象召回的准确性。代码将发布在 https://github.com/zhiqi-li/BEVFormer



论文:Understanding The Robustness in Vision Transformers
论文标题:Understanding The Robustness in Vision Transformers
论文时间:26 Apr 2022
所属领域:计算机视觉
对应任务:Domain Generalization,Image Classification,Object Detection,Semantic Segmentation,领域泛化,图像分类,目标检测,语义分割
论文地址:https://arxiv.org/abs/2204.12451
代码实现:https://github.com/nvlabs/fan
论文作者:Daquan Zhou, Zhiding Yu, Enze Xie, Chaowei Xiao, Anima Anandkumar, Jiashi Feng, Jose M. Alvarez
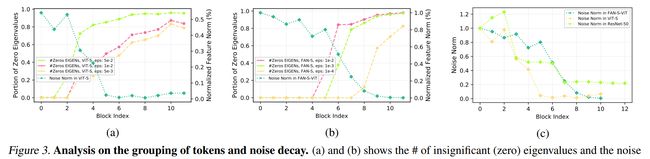
论文简介:Our study is motivated by the intriguing properties of the emerging visual grouping in Vision Transformers, which indicates that self-attention may promote robustness through improved mid-level representations. / 我们的研究受到视觉变形金刚中新兴视觉分组的有趣特性的推动,这表明自我注意可以通过改进的中级表示来提高鲁棒性。
论文摘要:Recent studies show that Vision Transformers(ViTs) exhibit strong robustness against various corruptions. Although this property is partly attributed to the self-attention mechanism, there is still a lack of systematic understanding. In this paper, we examine the role of self-attention in learning robust representations. Our study is motivated by the intriguing properties of the emerging visual grouping in Vision Transformers, which indicates that self-attention may promote robustness through improved mid-level representations. We further propose a family of fully attentional networks (FANs) that strengthen this capability by incorporating an attentional channel processing design. We validate the design comprehensively on various hierarchical backbones. Our model achieves a state of-the-art 87.1% accuracy and 35.8% mCE on ImageNet-1k and ImageNet-C with 76.8M parameters. We also demonstrate state-of-the-art accuracy and robustness in two downstream tasks: semantic segmentation and object detection. Code will be available at https://github.com/NVlabs/FAN
最近的研究表明,Vision Transformers (ViTs) 对各种损坏表现出很强的鲁棒性。尽管该属性部分归因于自注意力机制,但仍然缺乏系统的理解。在本文中,我们研究了自注意力在学习鲁棒表示中的作用。我们的研究受到视觉Transformer中新兴视觉分组的有趣特性的推动,这表明自我注意可以通过改进的中级表示来提高鲁棒性。我们进一步提出了一系列全注意力网络(FAN),通过结合注意力通道处理设计来增强这种能力。我们在各种分层主干上全面验证了设计。我们的模型在具有 76.8M 参数的 ImageNet-1k 和 ImageNet-C 上实现了最先进的 87.1% 准确率和 35.8% mCE。我们还在两个下游任务中展示了最先进的准确性和鲁棒性:语义分割和对象检测。代码将在 https://github.com/NVlabs/FAN 上提供

论文:Remember Intentions: Retrospective-Memory-based Trajectory Prediction
论文标题:Remember Intentions: Retrospective-Memory-based Trajectory Prediction
论文时间:22 Mar 2022
所属领域:Time Series / 时间序列
对应任务:Trajectory Prediction,轨迹预测
论文地址:https://arxiv.org/abs/2203.11474
代码实现:https://github.com/mediabrain-sjtu/memonet
论文作者:Chenxin Xu, Weibo Mao, Wenjun Zhang, Siheng Chen
论文简介:However, in this way, the model parameters come from all seen instances, which means a huge amount of irrelevant seen instances might also involve in predicting the current situation, disturbing the performance. / 然而,通过这种方式,模型参数来自所有可见实例,这意味着大量不相关的可见实例也可能涉及预测当前情况,干扰性能。
论文摘要:To realize trajectory prediction, most previous methods adopt the parameter-based approach, which encodes all the seen past-future instance pairs into model parameters. However, in this way, the model parameters come from all seen instances, which means a huge amount of irrelevant seen instances might also involve in predicting the current situation, disturbing the performance. To provide a more explicit link between the current situation and the seen instances, we imitate the mechanism of retrospective memory in neuropsychology and propose MemoNet, an instance-based approach that predicts the movement intentions of agents by looking for similar scenarios in the training data. In MemoNet, we design a pair of memory banks to explicitly store representative instances in the training set, acting as prefrontal cortex in the neural system, and a trainable memory addresser to adaptively search a current situation with similar instances in the memory bank, acting like basal ganglia. During prediction, MemoNet recalls previous memory by using the memory addresser to index related instances in the memory bank. We further propose a two-step trajectory prediction system, where the first step is to leverage MemoNet to predict the destination and the second step is to fulfill the whole trajectory according to the predicted destinations. Experiments show that the proposed MemoNet improves the FDE by 20.3%/10.2%/28.3% from the previous best method on SDD/ETH-UCY/NBA datasets. Experiments also show that our MemoNet has the ability to trace back to specific instances during prediction, promoting more interpretability.
为了实现轨迹预测,以前的大多数方法都采用基于参数的方法,将所有看到的过去-未来实例对编码为模型参数。但是,通过这种方式,模型参数来自所有可见实例,这意味着大量不相关的可见实例也可能涉及预测当前情况,从而干扰性能。为了在当前情况和所见实例之间提供更明确的联系,我们模仿神经心理学中的回顾性记忆机制并提出了 MemoNet,这是一种基于实例的方法,通过在训练数据中寻找类似的场景来预测代理的运动意图。在 MemoNet 中,我们设计了一对记忆库来明确存储训练集中的代表性实例,充当神经系统中的前额叶皮层,以及一个可训练的记忆寻址器,以自适应地搜索记忆库中具有相似实例的当前情况,就像基底节。在预测过程中,MemoNet 通过使用内存寻址器对内存库中的相关实例进行索引来调用先前的内存。我们进一步提出了一个两步轨迹预测系统,第一步是利用 MemoNet 预测目的地,第二步是根据预测的目的地完成整个轨迹。实验表明,所提出的 MemoNet 在 SDD/ETH-UCY/NBA 数据集上比之前的最佳方法提高了 20.3%/10.2%/28.3% 的 FDE。实验还表明,我们的 MemoNet 能够在预测期间追溯特定实例,从而提高可解释性。



论文:StyleGAN-Human: A Data-Centric Odyssey of Human Generation
论文标题:StyleGAN-Human: A Data-Centric Odyssey of Human Generation
论文时间:25 Apr 2022
所属领域:计算机视觉
对应任务:Image Generation,图像生成
论文地址:https://arxiv.org/abs/2204.11823
代码实现:https://github.com/stylegan-human/stylegan-human
论文作者:Jianglin Fu, Shikai Li, Yuming Jiang, Kwan-Yee Lin, Chen Qian, Chen Change Loy, Wayne Wu, Ziwei Liu
论文简介:In addition, a model zoo and human editing applications are demonstrated to facilitate future research in the community. / 此外,还给出了一个模型仓库和人工编辑应用程序,以促进社区未来的研究。
论文摘要:Unconditional human image generation is an important task in vision and graphics, which enables various applications in the creative industry. Existing studies in this field mainly focus on “network engineering” such as designing new components and objective functions. This work takes a data-centric perspective and investigates multiple critical aspects in “data engineering”, which we believe would complement the current practice. To facilitate a comprehensive study, we collect and annotate a large-scale human image dataset with over 230K samples capturing diverse poses and textures. Equipped with this large dataset, we rigorously investigate three essential factors in data engineering for StyleGAN-based human generation, namely data size, data distribution, and data alignment. Extensive experiments reveal several valuable observations w.r.t. these aspects: 1) Large-scale data, more than 40K images, are needed to train a high-fidelity unconditional human generation model with vanilla StyleGAN. 2) A balanced training set helps improve the generation quality with rare face poses compared to the long-tailed counterpart, whereas simply balancing the clothing texture distribution does not effectively bring an improvement. 3) Human GAN models with body centers for alignment outperform models trained using face centers or pelvis points as alignment anchors. In addition, a model zoo and human editing applications are demonstrated to facilitate future research in the community.
无条件约束的人物图像生成是视觉和图形学中的一项重要任务,它使创意产业的各种应用成为可能。该领域的现有研究主要集中在“网络(结构)工程”,例如设计新的组件和目标函数。这项工作以数据为中心,研究了“数据工程”中的多个关键方面,我们认为这将补充当前的实践。为了促进全面研究,我们收集并注释了一个包含超过 23 万个样本的大规模人体图像数据集,这些样本捕获了不同的姿势和纹理。借助这个大型数据集,我们严格研究了基于 StyleGAN 的人类生成数据工程中的三个基本因素,即数据大小、数据分布和数据对齐。广泛的实验揭示了几个有价值的观察结果。这些方面: 1)需要大规模数据,超过 40K 图像,以使用 vanilla StyleGAN 训练高保真无条件人类生成模型。 2)与长尾对应物相比,平衡的训练集有助于提高稀有面部姿势的生成质量,而简单地平衡服装纹理分布并不能有效地带来改进。 3) 具有用于对齐的身体中心的人类 GAN 模型优于使用面部中心或骨盆点作为对齐锚点训练的模型。此外,还给出了一个模型仓库和人工编辑应用程序,以促进社区未来的研究。
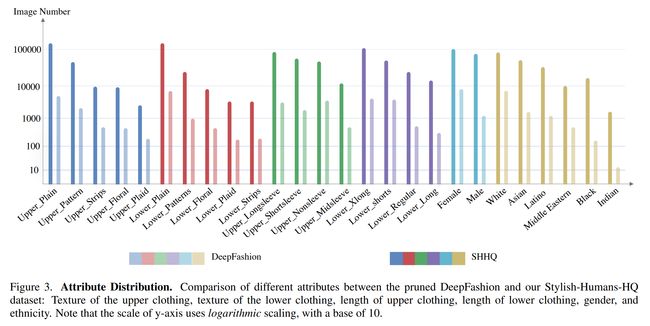
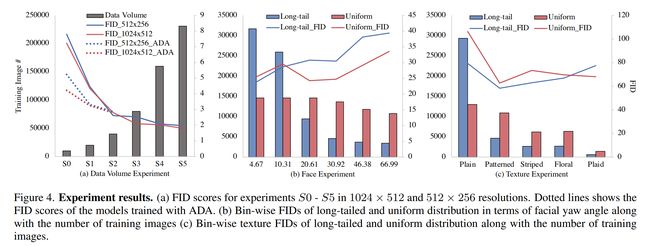
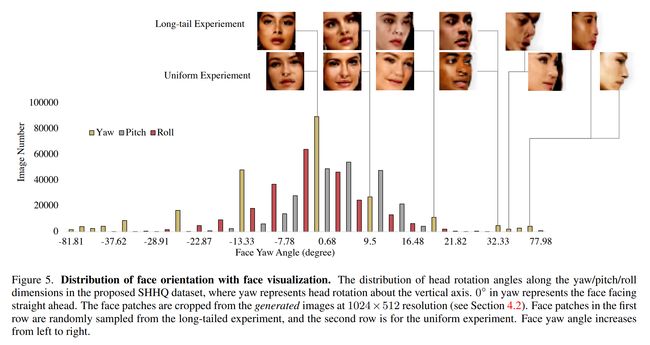

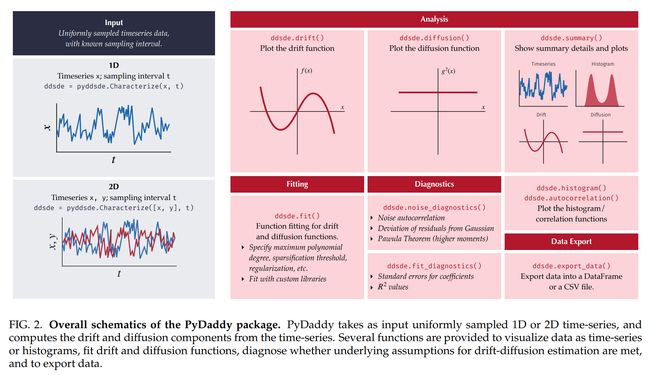
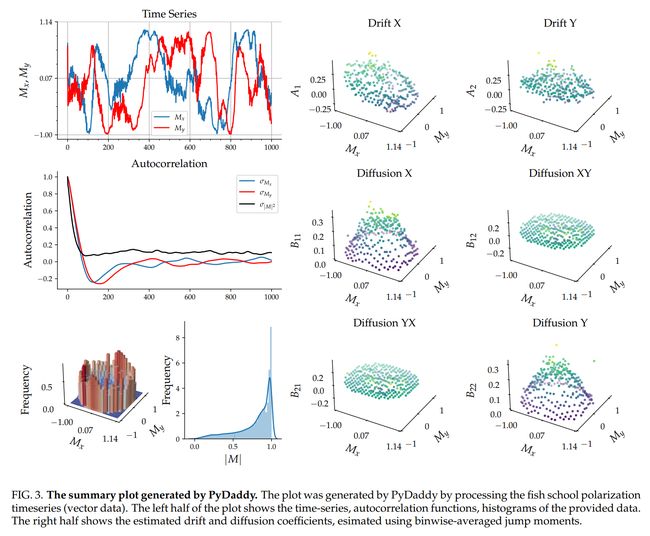
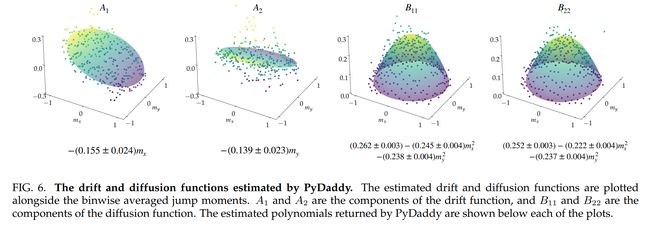
论文:PyDaddy: A Python package for discovering stochastic dynamical equations from timeseries data
论文标题:PyDaddy: A Python package for discovering stochastic dynamical equations from timeseries data
论文时间:5 May 2022
所属领域:Time Series / 时间序列
对应任务:Time Series,时间序列
论文地址:https://arxiv.org/abs/2205.02645
代码实现:https://github.com/tee-lab/pydaddy
论文作者:Arshed Nabeel, Ashwin Karichannavar, Shuaib Palathingal, Jitesh Jhawar, Danny Raj M, Vishwesha Guttal
论文简介:Here, we present PyDaddy (PYthon library for DAta Driven DYnamics), a toolbox to construct and analyze interpretable SDE models based on time-series data. / 在这里,我们介绍了 PyDaddy(用于数据驱动的时序 Python 库),这是一个基于时间序列数据构建和分析可解释 SDE 模型的工具箱。
论文摘要:Most real-world ecological dynamics, ranging from ecosystem dynamics to collective animal movement, are inherently stochastic in nature. Stochastic differential equations (SDEs) are a popular modelling framework to model dynamics with intrinsic randomness. Here, we focus on the inverse question: If one has empirically measured time-series data from some system of interest, is it possible to discover the SDE model that best describes the data. Here, we present PyDaddy (PYthon library for DAta Driven DYnamics), a toolbox to construct and analyze interpretable SDE models based on time-series data. We combine traditional approaches for data-driven SDE reconstruction with an equation learning approach, to derive symbolic equations governing the stochastic dynamics. The toolkit is presented as an open-source Python library, and consists of tools to construct and analyze SDEs. Functionality is included for visual examination of the stochastic structure of the data, guided extraction of the functional form of the SDE, and diagnosis and debugging of the underlying assumptions and the extracted model. Using simulated time-series datasets, exhibiting a wide range of dynamics, we show that PyDaddy is able to correctly identify underlying SDE models. We demonstrate the applicability of the toolkit to real-world data using a previously published movement data of a fish school. Starting from the time-series of the observed polarization of the school, pyDaddy readily discovers the SDE model governing the dynamics of group polarization. The model recovered by PyDaddy is consistent with the previous study. In summary, stochastic and noise-induced effects are central to the dynamics of many biological systems. In this context, we present an easy-to-use package to reconstruct SDEs from timeseries data.
大多数现实世界的生态动力学,从生态系统动力学到集体动物运动,本质上都是随机的。随机微分方程 (SDE) 是一种流行的建模框架,用于对具有内在随机性的动力学进行建模。在这里,我们专注于逆向问题:如果从某个感兴趣的系统中根据经验测量时间序列数据,是否有可能发现最能描述数据的 SDE 模型。在这里,我们介绍了 PyDaddy(用于数据驱动的 PYthon 库),这是一个基于时间序列数据构建和分析可解释 SDE 模型的工具箱。我们将数据驱动的 SDE 重建的传统方法与方程学习方法相结合,以推导控制随机动力学的符号方程。该工具包以开源 Python 库的形式呈现,包含构建和分析 SDE 的工具。功能包括可视化检查数据的随机结构、引导提取 SDE 的功能形式,以及诊断和调试基础假设和提取的模型。使用模拟的时间序列数据集,展示广泛的动态,我们证明 PyDaddy 能够正确识别底层 SDE 模型。我们使用先前发布的鱼群运动数据证明了该工具包对现实世界数据的适用性。从观察到的群极化的时间序列开始,pyDaddy 很容易发现控制群体极化动力学的 SDE 模型。 PyDaddy 恢复的模型与之前的研究一致。总之,随机和噪声诱导效应是许多生物系统动力学的核心。在这种情况下,我们提出了一个易于使用的包来从时间序列数据中重建 SDE。
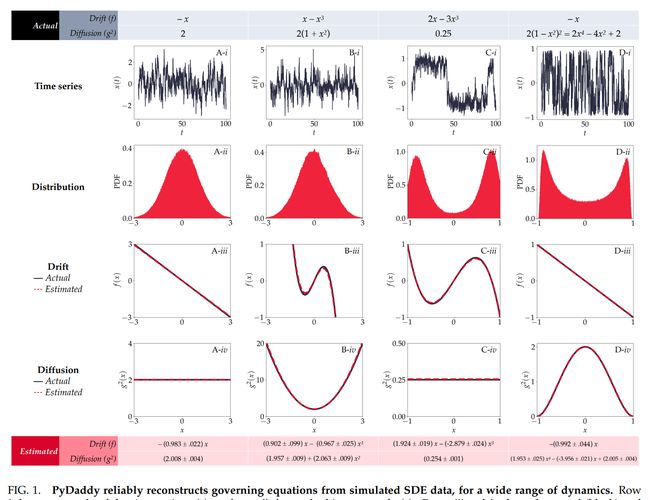
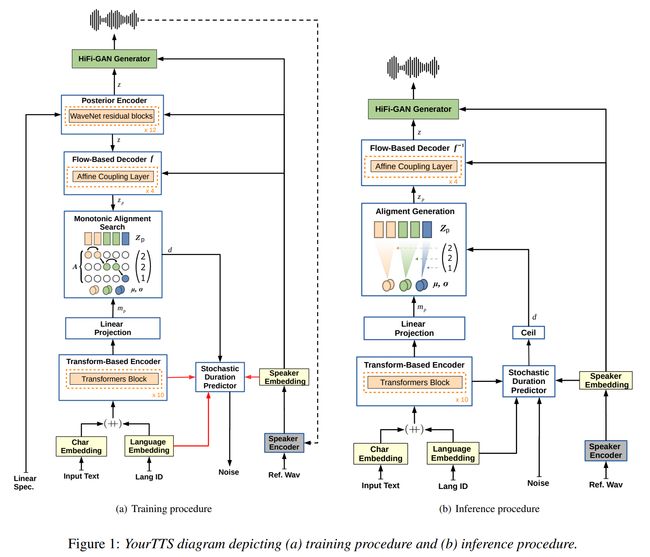
论文:YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
论文标题:YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
论文时间:4 Dec 2021
所属领域:Speech / 语音
对应任务:Speech Synthesis,Text-To-Speech Synthesis,Voice Conversion,Zero-Shot Learning,Zero-Shot Multi-Speaker TTS,语音合成,文本到语音合成,语音转换,零样本学习,零样本多说话者语音文本转换
论文地址:https://arxiv.org/abs/2112.02418
代码实现:https://github.com/coqui-ai/TTS , https://github.com/edresson/yourtts
论文作者:Edresson Casanova, Julian Weber, Christopher Shulby, Arnaldo Candido Junior, Eren Gölge, Moacir Antonelli Ponti
论文简介:YourTTS brings the power of a multilingual approach to the task of zero-shot multi-speaker TTS. / YourTTS 将多语言方法的能力带到了零样本多说话者 TTS 的任务中。
论文摘要:YourTTS brings the power of a multilingual approach to the task of zero-shot multi-speaker TTS. Our method builds upon the VITS model and adds several novel modifications for zero-shot multi-speaker and multilingual training. We achieved state-of-the-art (SOTA) results in zero-shot multi-speaker TTS and results comparable to SOTA in zero-shot voice conversion on the VCTK dataset. Additionally, our approach achieves promising results in a target language with a single-speaker dataset, opening possibilities for zero-shot multi-speaker TTS and zero-shot voice conversion systems in low-resource languages. Finally, it is possible to fine-tune the YourTTS model with less than 1 minute of speech and achieve state-of-the-art results in voice similarity and with reasonable quality. This is important to allow synthesis for speakers with a very different voice or recording characteristics from those seen during training.
YourTTS 将多语言方法的能力带到了零样本多说话者 TTS 的任务中。我们的方法建立在 VITS 模型的基础上,并为零样本多说话者和多语言训练添加了一些新颖的修改。我们在 VCTK 数据集上的零样本多说话者 TTS 中取得了最先进的 (SOTA) 结果,并在零样本语音转换中取得了与 SOTA 相当的结果。此外,我们的方法在具有单说话人数据集的目标语言中取得了可喜的结果,为低资源语言中的零样本多说话者 TTS 和零样本语音转换系统开辟了可能性。最后,可以用不到 1 分钟的语音微调 YourTTS 模型,并在语音相似度和质量合理的情况下达到最先进的结果。这对于允许合成具有与训练期间看到的声音或录音特征非常不同的扬声器的扬声器非常重要。
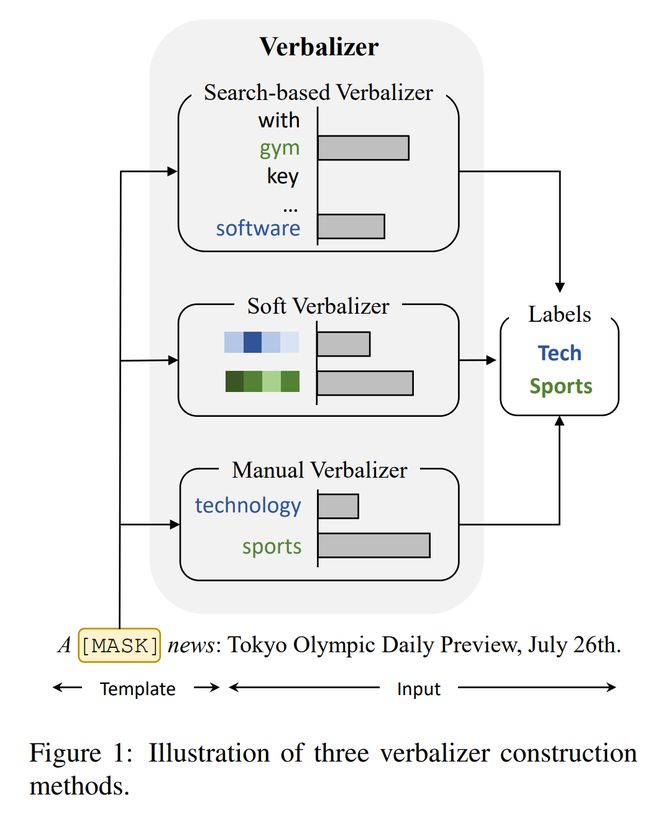
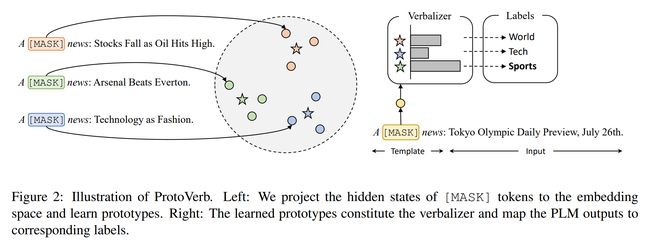
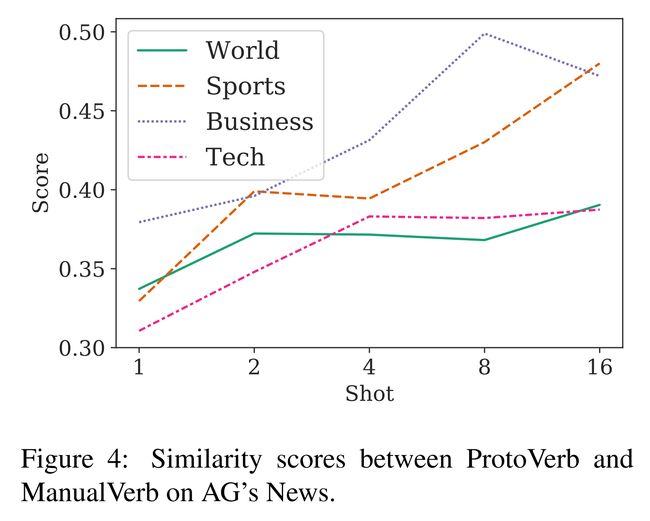
论文:Prototypical Verbalizer for Prompt-based Few-shot Tuning
论文标题:Prototypical Verbalizer for Prompt-based Few-shot Tuning
论文时间:ACL 2022
所属领域:Computer Vision / 计算机视觉
对应任务:Contrastive Learning,Entity Typing,Few-Shot Learning,Topic Classification,对比学习,实体分类,小样本学习,主题分类
论文地址:https://arxiv.org/abs/2203.09770
代码实现:https://github.com/thunlp/OpenPrompt
论文作者:Ganqu Cui, Shengding Hu, Ning Ding, Longtao Huang, Zhiyuan Liu
论文简介:However, manual verbalizers heavily depend on domain-specific prior knowledge and human efforts, while finding appropriate label words automatically still remains challenging. In this work, we propose the prototypical verbalizer (ProtoVerb) which is built directly from training data. / 然而,手动语言器在很大程度上依赖于特定领域的先验知识和人工努力,而自动找到合适的标签词仍然具有挑战性。在这项工作中,我们提出了直接从训练数据构建的原型语言器(ProtoVerb)。
论文摘要:Prompt-based tuning for pre-trained language models (PLMs) has shown its effectiveness in few-shot learning. Typically, prompt-based tuning wraps the input text into a cloze question. To make predictions, the model maps the output words to labels via a verbalizer, which is either manually designed or automatically built. However, manual verbalizers heavily depend on domain-specific prior knowledge and human efforts, while finding appropriate label words automatically still remains challenging.In this work, we propose the prototypical verbalizer (ProtoVerb) which is built directly from training data. Specifically, ProtoVerb learns prototype vectors as verbalizers by contrastive learning. In this way, the prototypes summarize training instances and are able to enclose rich class-level semantics. We conduct experiments on both topic classification and entity typing tasks, and the results demonstrate that ProtoVerb significantly outperforms current automatic verbalizers, especially when training data is extremely scarce. More surprisingly, ProtoVerb consistently boosts prompt-based tuning even on untuned PLMs, indicating an elegant non-tuning way to utilize PLMs. Our codes are avaliable at https://github.com/thunlp/OpenPrompt
基于提示的预训练语言模型 (PLM) 调优已显示出其在少样本学习中的有效性。通常,基于提示的调整将输入文本包装成一个完形填空问题。为了进行预测,该模型通过手动设计或自动构建的语言器将输出词映射到标签。然而,手动语言器在很大程度上依赖于特定领域的先验知识和人工努力,而自动找到合适的标签词仍然具有挑战性。在这项工作中,我们提出了直接从训练数据构建的原型语言器 (ProtoVerb)。具体来说,ProtoVerb 通过对比学习将原型向量作为语言器来学习。通过这种方式,原型总结了训练实例并能够包含丰富的类级语义。我们对主题分类和实体类型任务进行了实验,结果表明 ProtoVerb 明显优于当前的自动语言器,尤其是在训练数据极其稀缺的情况下。更令人惊讶的是,即使在未调整的 PLM 上,ProtoVerb 也始终如一地提升基于提示的调整,这表明了一种利用 PLM 的优雅的非调整方式。我们的代码可在 https://github.com/thunlp/OpenPrompt 获得。


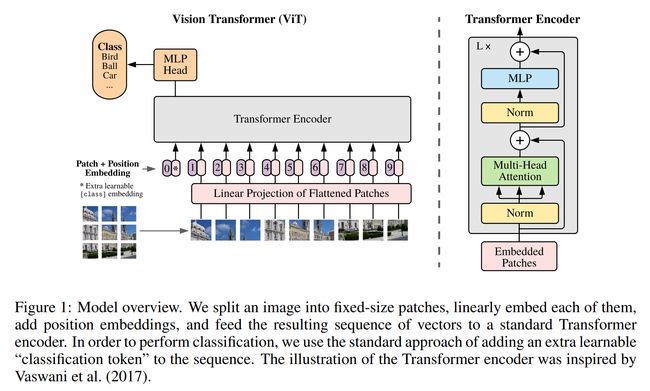
论文:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
论文标题:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
论文时间:ICLR 2021
所属领域:Computer Vision / 计算机视觉
对应任务:Document Image Classification,Fine-Grained Image Classification,Image Classification,文档图像分类,细粒度图像分类,图像分类
论文地址:https://arxiv.org/abs/2010.11929
代码实现:https://github.com/google-research/vision_transformer , https://github.com/tensorflow/models/tree/master/official/projects/vit , https://github.com/huggingface/transformers , https://github.com/rwightman/pytorch-image-models , https://github.com/pytorch/vision
论文作者:Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
论文简介:While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. / 虽然 Transformer 架构已成为自然语言处理任务的事实标准,但其在计算机视觉中的应用仍然有限。
论文摘要:While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
虽然 Transformer 架构已成为自然语言处理任务的事实标准,但其在计算机视觉中的应用仍然有限。在视觉上,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。我们表明,这种对 CNN 的依赖是不必要的,直接应用于图像块序列的纯transformer可以在图像分类任务上表现得非常好。当对大量数据进行预训练并转移到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB 等)时,与前沿CNN方法相比,Vision Transformer (ViT) 获得了出色的结果,同时需要更少的计算资源来训练。


我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。

- 作者:韩信子@ShowMeAI
- 历史文章列表
- 专题合辑&电子月刊
- 声明:版权所有,转载请联系平台与作者并注明出处
- 欢迎回复,拜托点赞,留言推荐中有价值的文章、工具或建议,我们都会尽快回复哒~