李宏毅老师2022机器学习课程笔记 03 自注意力机制(Self-Attention)
03 自注意力机制(Self-Attention)
更加复杂形式的输入
向量序列形式的输入
在实际应用中,数据可能会有各种各样的形式,为了将数据作为输入提供给模型训练,可以考虑将其表示为向量序列的形式。
比如,在文字处理的场景中,可以将单词表示为向量,将句子看作单词的序列。
比如,在语音处理的场景中,可以将一个window大小(比如25ms)的一小段语音表示为一个向量,将完整的语音看作是小段语音的序列。(特别说明的是,根据经验每一小段语音之间是有重叠的,即窗口每次移动的时候,移动的大小是可以小于窗口大小的,这一点和文字处理有所不同,不是直接一个单词一个单词的移动彼此之间无重叠。)
比如,在处理分子结构(图,graph)的场景中,可以将一个原子看作是一个向量,将分子看作原子的组合。
当然将这些数据表示为向量有各种各样的方法,比如在文字处理中可以用one-hot编码、Word Embedding方法等。当然由于本文的重点在于自注意力机制,故不详细介绍将各类数据表示为向量的方法。
向量序列的各种输出
| 输入类型 | 输出类型 | 应用场景举例 |
|---|---|---|
| 向量序列 | 与输入向量个数相同的标签 | 词性标记、graph中的每个节点特性的预测(比如人际网中的某一个用户可能买产品还是不买) |
| 向量序列 | 一个标签 | 文本情感分析、语音识别speaker |
| 向量序列 | 不确定长度的标签 | 文本翻译 |
本文重点介绍上表中的第一种类型,即输出标签个数与输入向量个数相同的类型。
Self-Attention介绍
Self-Attention的设计动机
如前面所说,输入可能是一个向量的序列,并且序列的长度是不确定的。比如,当输入是一个句子的时候,可以把句子看作是一个单词的序列,那么句子包含的单词个数是不确定的。
那么这种情况下,如果将整个序列作为一个整体,普通的模型是无法进行处理的;如果将序列中的每个向量单独交给模型处理,那么无法利用向量之间的关联性。(比如在词性标注任务中,同一个单词可能会被标注为不同的词性,但这是要结合上下文决定的,而不仅仅是单词本身。)
简言之,Self-Attention的设计动机就是处理形式为可变长度向量序列输入,且这些向量之间会有一定的关联。
Self-Attention的整体结构

将向量输入到Self-Attention,输出是同等数量的向量,且每一个输出的向量都考虑到了输入序列中所有向量的信息。然后再用全连接网络对每一个向量分别处理。上述过程可以叠加进行多次,全连接网络的处理结果可以作为一个新的输入序列继续输入下一个Self-Attention中。
Self-Attention的具体设计
Self-Attention的具体设计主要包括两个部分,计算输入向量之间的相关性和根据相关性提取相关性高的信息。细节将在后文展开。
Self-Attention的输入输出
如上图所示,由于Self-Attention层可以被叠加使用,因此Self-Attention层的输入可以是输入的数据,也可以前一个隐藏层的输出向量。
Self-Attention的每一个输出都考虑了输入序列中所有的向量。
计算输入向量之间的相关性
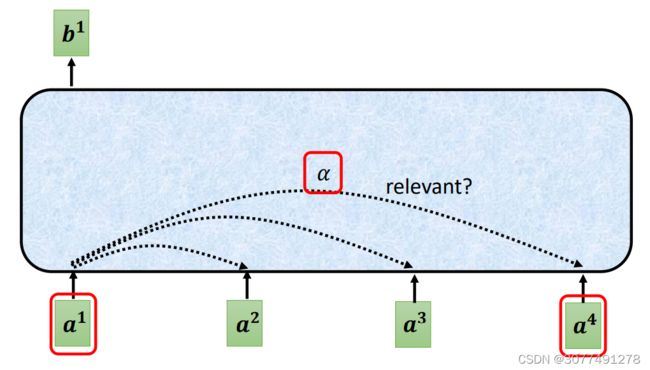
如上图所示,Self-Attention的输出都考虑了输入序列中所有的向量的方式是计算输入向量两两之间的相关性。
一个常用的计算相关性的方法是将输入的两个向量分别乘上一个不同的矩阵,然后将结果进行点乘的运算,得到注意力得分 α \alpha α。
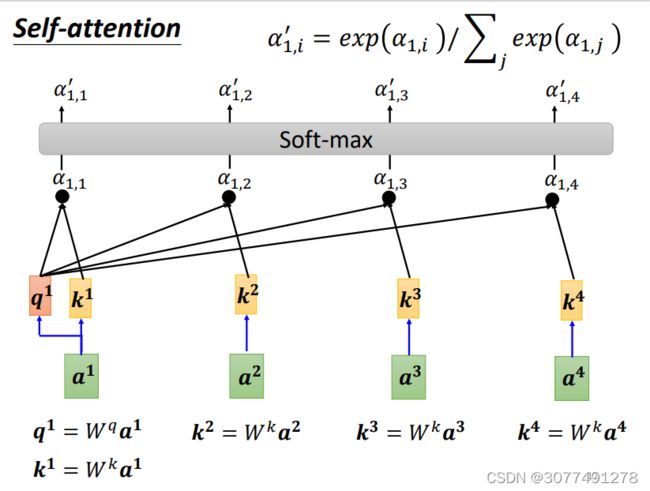
如上图所示,先对第一个向量 a 1 a^1 a1计算和序列中所有向量的注意力得分(包括和他自己)。然后对所有输入的向量进行类似的操作计算自己和序列中所有向量的注意力得分。最后使用一个softmax函数,得到最终的注意力得分。(softmax不是必须的,也可以用ReLU等代替)
提取相关性高的信息
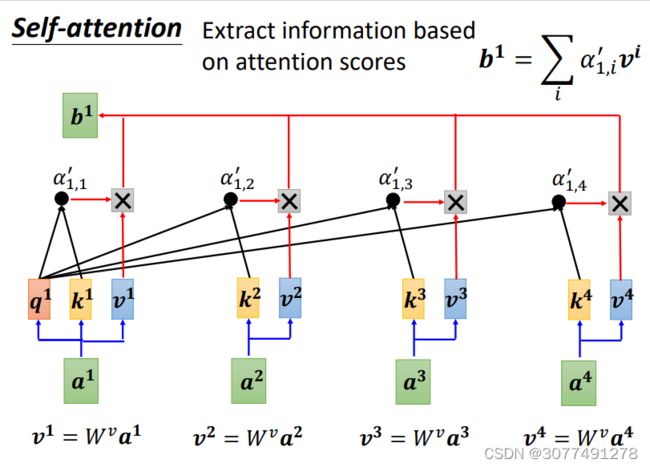
将每个向量与 W v W^v Wv相乘得到向量 v i v^i vi,再将每个向量 v i v^i vi乘上对应的注意力得分。显然,最终的向量 b i b^i bi会与注意力得分比较高的向量更相似。
得到的向量 b i b^i bi的序列即为Self-Attention层的输出。
Self-Attention结构的矩阵形式
Self-Attention结构的矩阵形式与前文介绍的Self-Attention结构是完全一致的,只不过为了形式上的简洁,将其用线性代数中的矩阵形式进行表示。

如上图所示, I I I表示由输入向量组成的矩阵,各个输入向量构成了 I I I的列向量。
将输入向量分别与矩阵 W q W^q Wq、 W k 、 W^k、 Wk、 W w W^w Ww相乘,得到 Q Q Q、 K K K、 W W W。
将 K T K^T KT与 Q Q Q相乘,并输入一个softmax函数,得到注意力得分矩阵 A ′ A^{'} A′。
再将 V V V与 A ′ A^{'} A′相乘得到输出 O O O。
需要说明的是,在这个模型中,机器需要学习的未知参数就是图中红色标明的矩阵 W q W^q Wq、 W k 、 W^k、 Wk、 W w W^w Ww。
Self-attention的进阶版——多头自注意机制(Multi-head Self-attention)
Multi-head Self-Attention的整体结构

如上图所示,Multi-head Self-attention与普通的Self-attention的区别在于Multi-head Self-attention会在 q q q的基础上继续生成多个不同的 q i q^i qi( k k k、 v v v也是类似)。
Multi-head Self-attention的设计动机
Self-attention的目的是要找相关的 q q q和 k k k,但是相关性的定义可能有很多种,所以可考虑设计多个 q q q,不同的 q q q用于寻找不同的相关性。
Multi-head Self-attention的细节说明
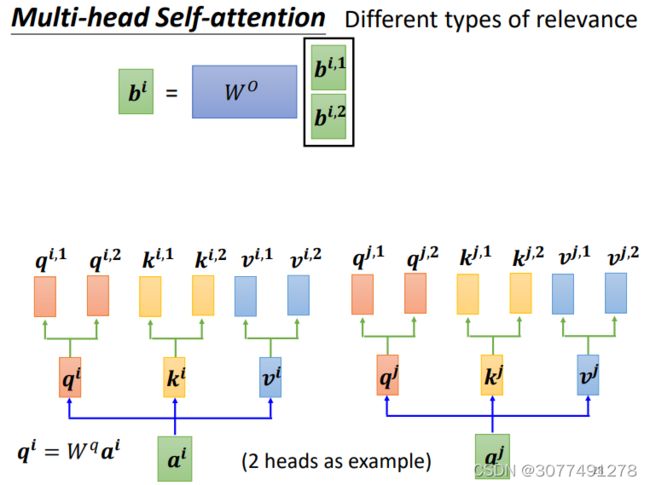
Multi-head Self-attention与普通的Self-attention的区别在于Multi-head Self-attention的每一个向量会在生成向量 q q q的基础上,再乘上若干个矩阵生成多个不同的 q i , j q^{i,j} qi,j,上图所示的情况是2个不同的 q q q,也即两头的情况。
与之相应的,向量 k k k和 v v v也会生成多个。
然后对每一个“头”上的向量进行与普通Self-attention相同的操作,得到每一“头”的输出 b i , j b^{i,j} bi,j。然后可以将 b i , j b^{i,j} bi,j拼接起来,再乘上一个矩阵得到最终的Self-Attention层的输出。
加入位置信息的编码
在前面所讲的Self-attention层中,Self-attention是无法利用输入的位置信息的。因为他的计算结果取决于输入的向量相似性,所以向量在序列中的位置如果发送改变,也并不影响其结果,也就是说Self-attention并没有用到输入序列的位置信息。
而位置信息在很多时候是比较重要的,比如在词性标记的场景中,动词就不容易出现在一个句子序列的开头。应该考虑在输入中加入位置信息的编码。
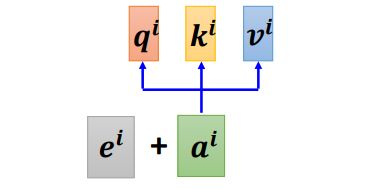
如上图所示,给输出加上位置信息 e i e^i ei。
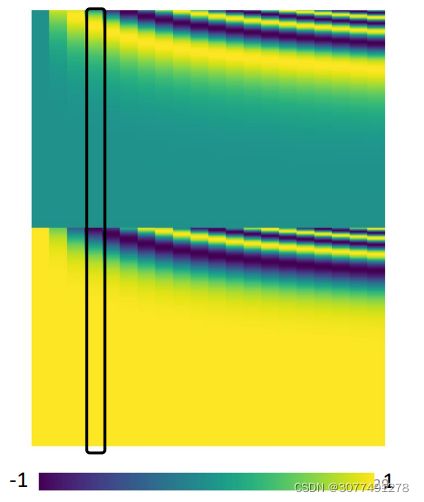
上图中的每一列都代表了一个的位置信息,每一个位置都对应一个专属的位置信息 e i e^i ei,这样Self-Attention层在进行处理时就能知道输入的位置信息。
位置信息可以人为设定也可以根据特定的规则产生,对位置信息进行编码仍然是一个尚待研究的问题。
Self-Attention的应用
文本处理
比如在文字处理的场景中,可以将单词表示为向量,将句子看作单词的序列,用Self-Attention对单词进行词性标记。
语音处理
比如在简化版的语音辨识的场景中,以将一小段音频表示为向量,将整段音频看作是小段音频的序列,用Self-Attention对小段音频的phonetic进行标记。
需要注意的是,由于音频的序列会非常长,为了降低运算复杂度,同时考虑到某一小段音频仅与其前后一部分存在关联。并不需要将整段音频对应的向量序列都输入到Self-Attention中,仅将小段音频附近的向量序列输入Self-Attention中即可。
图片处理
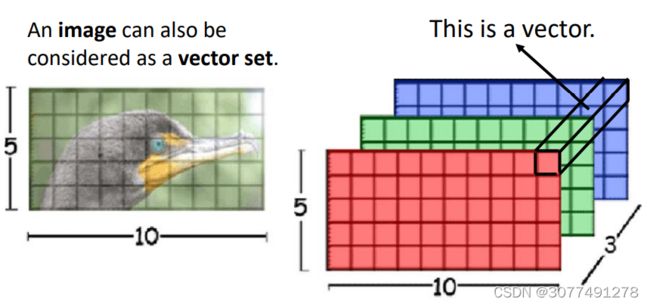
将图片的每个像素看作是一个三维的向量,图片也可以看作是向量的集合。
对图(graph)的处理
图中的每个节点也可以看做是一个向量,graph也可以看作是向量的集合。
需要注意的是,可以利用图中节点本身的相连信息(边)考虑向量之间的相关性,比如没有边相连的节点可以认位这两个节点没有关联性,直接将其相关性设置为0。
将Self-Attention的思想用于graph时,就是一种GNN的类型。
Self-Attention和CNN(卷积神经网络)的比较
CNN是简化版的Self-Attention,Self-Attention是复杂版的CNN。
因为在CNN中,仅仅只考虑感受野中的信息,而在Self-Attention中,考虑的是整张图片的信息。换言之,Self-Attention中的感受野是机器自己学习的,CNN的感受野是人为设定的。
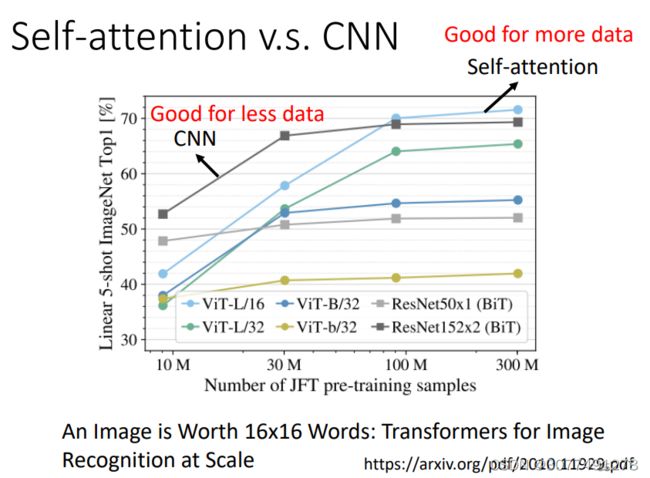
如上图所示,数据量小时,CNN效果比较好,数据量大时Self-Attention效果比较好。
因为模型的参数越多,那么模型的弹性越大、能力更强,但是在数据量比较少时容易过拟合。而如果模型参数较小,则模型不容易过拟合,但是无法从更多的数据量中学习到有用的信息。所以,在数据量比较少的时候,用参数少的模型好,在数据量比较大的时候,用参数多的模型好。
Self-Attention和CNN(循环神经网络)的比较
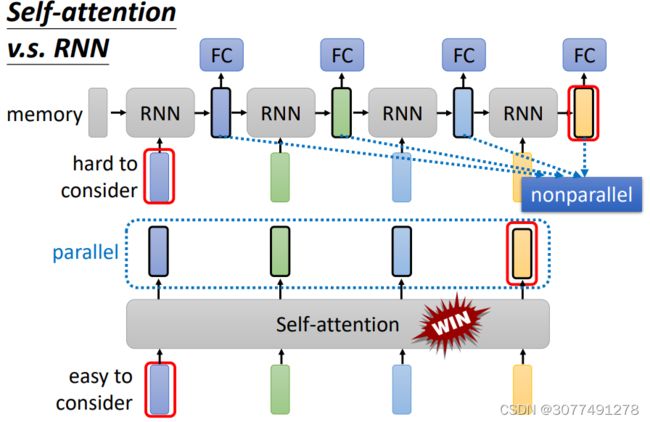
RNN的结构如上图所示,RNN模型中,会把上一个隐含层的输出和当前的向量一起输入到当前RNN中。
并且可以使用双向的RNN,RNN的输出也是一个向量的序列,且每个输出向量考虑到了序列中的所有信息。
但是与Self-Attention相比,RNN主要有两个缺点,一是两边的向量在运算过程中对后续向量的影响可能会逐渐变小,二是输出向量无法并行计算产生。
所以Self-Attention基本上取代了RNN。