(一)简单版RNN实现文本情感分析(Pytorch)
在本系列教程中,我们将使用PyTorch和TorchText构建一个机器学习模型来检测情感(即检测句子是积极的还是消极的)。这将使用电影评论上的IMDb数据集完成。
在第一篇笔记中,我们将从非常简单的概念开始理解,而不是真正关心好的结果。接下来的笔记将建立在这些知识之上,我们会得到很好的结果。
文章目录
-
- 引言
- 数据预处理
- 搭建模型
- 训练模型
- 完整代码
- 后续行动
引言
我们将使用循环神经网络(RNN),因为它们通常用于分析序列。RNN接受单词序列, X = { x 1 , … , x T } X=\{x_1,…, x_T\} X={x1,…,xT},一次接收一个,并为每个单词生成一个隐藏状态 h h h。我们通过输入当前单词 x t x_t xt和前一个单词的隐藏状态 h t − 1 h_{t-1} ht−1来循环使用RNN,以产生下一个隐藏状态 h t h_t ht。
![]()
一旦我们有了最终的隐藏状态 h T h_T hT,(从输入序列的最后一个单词, x T x_T xT),我们通过一个线性层 f f f(也称为全连接层)输入它,以接收我们预测的情绪 y ^ = f ( h T ) \hat{y} = f(h_T) y^=f(hT)。
下面是一个例子,RNN模型的预测为零,表示负面情绪。RNN用橙色表示,线性层用银色表示。注意,我们对每个单词都使用相同的RNN,也就是说,它有相同的参数。初始隐藏状态 h 0 h_0 h0是一个初始化为所有零的张量。

注意:图中省略了一些层和步骤,但这些将在后面解释。
数据预处理
TorchText的一个主要概念是 Field(字段)。这些定义了应该如何处理数据。在我们的情感分类任务中,数据由原始的评论字符串和情感状态组成,即“pos”或“neg”。
Field的参数指定如何处理数据。
我们用TEXT field(字段)来定义评论数据应该如何处理,用LABEL field(字段)来处理情绪状态。
我们的TEXT 字段有tokenize='spacy’作为参数。这定义了“tokenization”(将字符串拆分为离散的“tokens(标记)”的行为)应该使用spaCy标记器来完成。
LABEL由LabelField定义,这是Field类的一个特殊子集,专门用于处理标签。稍后我们将解释dtype参数。
想了解更多关于Fields的信息,请点击这里。
为了重现性,我们也设置了随机种子。
import torch
from torchtext import data
SEED = 1234
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
TEXT = data.Field(tokenize = 'spacy', tokenizer_language='en_core_web_sm')
LABEL = data.LabelField(dtype = torch.float)
TorchText的另一个方便的特性是它支持用于自然语言处理(NLP)的公共数据集。
下面的代码自动下载IMDb数据集,并将其分割成规范的train/test作为torchtext.datasets对象。它使用我们前面定义的Fields(字段)来处理数据。IMDb数据集由5万篇电影评论组成,每篇都被标记为正面或负面的评论。
from torchtext import datasets
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
我们可以通过检查它们的长度来查看每个分割中有多少个示例。
print(f'Number of training examples: {len(train_data)}')
print(f'Number of testing examples: {len(test_data)}')
Number of training examples: 25000
Number of testing examples: 25000
我们还可以看一个例子。
print(vars(train_data.examples[0]))
{‘text’: [‘elvira’, ‘mistress’, ‘of’, ‘the’, ‘dark’, ‘is’, ‘one’, ‘of’, ‘my’, ‘fav’, ‘movies’, ‘,’, ‘it’, ‘has’, ‘every’, ‘thing’, ‘you’, ‘would’, ‘want’, ‘in’, ‘a’, ‘film’, ‘,’, ‘like’, ‘great’, ‘one’, ‘liners’, ‘,’, ‘sexy’, ‘star’, ‘and’, ‘a’, ‘Outrageous’, ‘story’, ‘!’, ‘if’, ‘you’, ‘have’, ‘not’, ‘seen’, ‘it’, ‘,’, ‘you’, ‘are’, ‘missing’, ‘out’, ‘on’, ‘one’, ‘of’, ‘the’, ‘greatest’, ‘films’, ‘made’, ‘.’, ‘i’, ‘ca’, “n’t”, ‘wait’, ‘till’, ‘her’, ‘new’, ‘movie’, ‘comes’, ‘out’, ‘!’], ‘label’: ‘pos’}
IMDb数据集只有train/test分割,所以我们需要创建一个validation set验证集。我们可以使用.split()方法来完成这个操作。
默认情况下,分割比是70/30,但是通过传递一个split_ratio参数,我们可以改变分割的比率,例如,split_ratio为0.8意味着80%的示例组成了训练集,20%组成了验证集。
我们还将随机种子传递给random_state参数,以确保每次得到相同的训练/验证分割。
import random
train_data, valid_data = train_data.split(random_state = random.seed(SEED))
同样,我们将查看每个拆分中有多少个示例。
print(f'Number of training examples: {len(train_data)}')
print(f'Number of validation examples: {len(valid_data)}')
print(f'Number of testing examples: {len(test_data)}')
Number of training examples: 17500
Number of validation examples: 7500
Number of testing examples: 25000
接下来,我们要建立一个词汇表。这是一个有效的查找表,数据集中的每个唯一的单词都有一个对应的索引(一个整数)。
我们这样做是因为我们的机器学习模型不能在字符串上运行,只能在数字上运行。每个索引用于为每个单词构造一个one-hot向量。one-hot vector是指除了一个元素为1外所有元素都为0的向量,向量的维数是词汇表中唯一单词的总数,通常用 V V V表示。
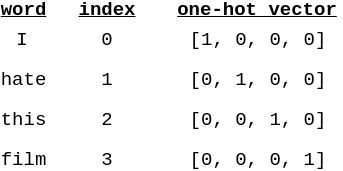
在我们的训练集中唯一单词的数量超过10万个,这意味着我们的一个one-hot向量将有超过10万个维度!这将使训练变慢,并且可能不适合你的GPU(如果你使用GPU的话)。
有两种方法可以有效地减少我们的词汇量,我们要么只取最常见的单词,要么忽略出现次数少于 m m m的单词。我们选择前者,只保留前25000个单词。
我们该如何处理那些在例子中出现但被我们从词汇表中删除的单词呢?我们用一个特殊的unknown或《unk》标记替换它们。例如,如果这句话是“This film is great and I love it”,但是词汇表中没有“love”这个词,它就会变成“This film is great and I 《unk》 it”。
下面构建词汇表,只保留最常见的max_size标记。
MAX_VOCAB_SIZE = 25_000
TEXT.build_vocab(train_data, max_size = MAX_VOCAB_SIZE)
LABEL.build_vocab(train_data)
为什么我们只在训练集上建立词汇表?在测试任何机器学习系统时,你都不希望以任何方式查看测试集。我们不包括验证集,因为我们希望它尽可能反映测试集。
print(f"Unique tokens in TEXT vocabulary: {len(TEXT.vocab)}")
print(f"Unique tokens in LABEL vocabulary: {len(LABEL.vocab)}")
Unique tokens in TEXT vocabulary: 25002
Unique tokens in LABEL vocabulary: 2
为什么词汇量是25002而不是25000?其中一个额外标记是《unk》标记,另一个是《pad》标记。
当我们将句子输入我们的模型时,我们一次输入一批句子,即一次输入多个句子,并且批处理中的所有句子都需要相同的大小。因此,为了确保批中的每个句子都是相同的大小,任何短于批中的最长句子的句子都会被填充。

我们还可以查看词汇表中最常见的单词及其频率。
print(TEXT.vocab.freqs.most_common(20))
[(‘the’, 202789), (’,’, 192769), (’.’, 165632), (‘and’, 109469), (‘a’, 109242), (‘of’, 100791), (‘to’, 93641), (‘is’, 76253), (‘in’, 61374), (‘I’, 54030), (‘it’, 53487), (‘that’, 49111), (’"’, 44657), ("‘s", 43331), (‘this’, 42385), (’-’, 36979), (’/> 我们还可以使用stoi (string to int)或itos (int to string)方法直接查看词汇表。 [’《unk》’, ‘《pad》’, ‘the’, ‘,’, ‘.’, ‘and’, ‘a’, ‘of’, ‘to’, ‘is’] 我们也可以检查标签,确保0代表消极1代表积极。 defaultdict( 准备数据的最后一步是创建迭代器。我们在训练/评估循环中遍历这些变量,并且它们在每次迭代时返回一批示例(索引并转换为张量)。 我们将使用BucketIterator,这是一种特殊类型的迭代器,它将返回一批示例,其中每个示例的长度都相似,从而最大限度地减少每个示例的填充量。 我们还希望将迭代器返回的张量放在GPU上(如果你正在使用的话)。PyTorch使用torch.device来处理,然后将这个device传递给迭代器。 下一个阶段是建立我们最终要训练和评估的模型。 在PyTorch中创建模型时,有少量的样板代码,请注意我们的RNN类是nn.Module的子类和super的使用。 在__init__中定义模块的层。我们的三层是嵌入层,RNN和线性层。所有层的参数都初始化为随机值,除它们被非显式指定。 嵌入层用来将我们稀疏的一个one-hot向量(稀疏是因为大部分元素都是0)转换成一个密集的嵌入向量(密集是因为维度要小得多,所有元素都是实数)。这个嵌入层只是一个完全连接的层。除了降低RNN输入的维数外,还有一种理论认为,在这个密集的向量空间中,对评论情绪有相似影响的单词被紧密映射在一起。有关词嵌入的更多信息,请参阅这里。 RNN层是我们的RNN接受我们的稠密向量和前面的隐藏状态 h t − 1 h_{t-1} ht−1,并使用它来计算下一个隐藏状态 h t h_t ht。 当我们将示例输入到模型中时,将调用forward方法。 每批文本都是一个大小为[sentence length,batch size]的张量。这是一批句子,每个句子都将每个单词转换成一个one-hot向量。 您可能会注意到,由于one-hot向量,这个张量应该有另一个维度,然而PyTorch很方便地将一个one-hot向量存储为其索引值,即表示一个句子的张量只是该句子中每个标记的索引的张量。将tokens列表转换为索引列表的行为通常称为数字化。 然后,输入批处理(input batch)通过嵌入层得到嵌入值,从而为我们的句子提供密集的向量表示。embedded是一个大小为[sentence length,batch size,hidden dim]的张量。 embedded然后馈送到RNN。在一些框架中,必须将初始隐藏状态 h 0 h_0 h0输入RNN,但是在PyTorch中,如果没有将初始隐藏状态作为参数传递,则默认为初始是一个全为0的张量。 RNN返回2个张量,输出(output)的大小为[sentence length,batch size,hidden dim]和隐藏(hidden)的大小为[1,batch size,hidden dim]。输出(output)是每个时间步骤的隐藏状态的连接,而隐藏(hidden)只是最终的隐藏状态。我们使用assert语句验证这一点。请注意“squeeze”方法,它用于删除尺寸为1的维度。 最后,我们通过线性层fc输入最后一个隐藏状态,hidden,来产生一个预测。 现在,我们创建RNN类的一个实例。 输入维数是one-hot向量的维数,等于词汇量大小。 嵌入维数是密集词向量的大小。这通常是50-250个维度,但取决于词汇量的大小。 隐藏维度是隐藏状态的大小。这通常是100-500个维度,但也取决于词汇量大小、密集向量的大小和任务的复杂性等因素。 输出维数通常是类的个数,然而在只有两个类的情况下,输出值在0到1之间,因此可以是一维的,即单个标量实数。 让我们创建一个函数来告诉我们模型中有多少可训练的参数,这样我们就可以比较不同模型中参数的数量。 The model has 2,592,105 trainable parameters 现在我们将设置训练,然后训练模型。 首先,我们将创建一个优化器。这是我们用来更新模型参数的算法。在这里,我们将使用随机梯度下降(SGD)。第一个参数是参数将被优化器更新,第二个参数是学习率,即当我们进行参数更新时,我们将改变参数多少。 接下来,我们将定义损失函数。在PyTorch中,这通常被称为criterion。 这里的损失函数是带对数的二进制交叉熵(binary cross entropy with logits)。 我们的模型目前输出一个未绑定的实数。因为我们的标签要么是0要么是1,所以我们希望将预测限制为在0到1之间的数字。我们用sigmoid或logit函数来完成这个任务。 然后我们利用这个有界标量来用二进制交叉熵计算损失。 BCEWithLogitsLoss criterion 实现了sigmoid和二进制交叉熵步骤。 使用.to,我们可以把模型和criterion 放在GPU上(如果我们有GPU的话)。 我们的criterion 函数计算损失,然而我们必须写我们的函数来计算精度。 这个函数首先通过一个sigmoid层提供预测,将0到1之间的值压缩,然后将它们四舍五入到最接近的整数。这将使任何大于0.5到1的值四舍五入(正面情绪),其余的值四舍五入为0(负面情绪)。 然后我们计算有多少四舍五入的预测等于实际标签,并在批中求平均值。 train函数遍历所有示例,一次一个批处理。 使用model.train()将模型置于“训练模式”,开启dropout和batch normalization。尽管我们没有在这个模型中使用它们,但最好还是包含它们。 对于每一批,我们首先消除梯度。模型中的每个参数都有一个grad属性,它存储由criterion计算出的梯度。PyTorch不会自动删除(或“置零”)上次计算的梯度,因此它们必须手动置零。 然后我们馈入这批句子,batch.text,一批一批地放入模型中。注意,您不需要执行model.forward(batch.text),只需调用模型即可工作。由于预测的初始尺寸为[batch size, 1],因此需要压缩,并且我们需要删除尺寸为1的维度,因为PyTorch期望我们的criterion 函数的预测输入的尺寸为[batch size]。 损失和准确率的计算使用我们的预测值和标签值,batch.labels,使损失在批中的所有样本上取平均值。 我们使用loss.backward()计算每个参数的梯度,然后使用optimizer.step()使用梯度和优化器算法更新参数。 损失和准确率在epoch中累积,.item()方法用于从只包含单个值的张量中提取标量。 最后,我们返回经过每个epoch的损失和准确率。迭代器的长度是迭代器中的批数。 你可能还记得在初始化标签字段时,我们设置了dtype=torch.float。这是因为TorchText默认将张量设置为长张量( LongTensors),但是我们的criterion要求两个输入都是浮点数(FloatTensors)。我们设置dtype为torch.float。另一种方法是在train函数内部进行转换,通过传递batch.label.float()而不是batch.label给criterion。 evaluate函数与train类似,有一些修改,因为您不希望在评估时更新参数。 model.eval()将模型置于“评估模式”,这关闭了dropout 和batch normalization。同样,我们不会在这个模型中使用它们,但是最好包含它们。 在with no_grad()块内的PyTorch操作上不计算梯度。这将导致使用更少的内存并加快计算速度。 函数的其余部分与train相同,只是删除了optimizer.zero_grad()、loss.backward()和optimizer.step(),因为在求值时不更新模型的参数。 我们还将创建一个函数来告诉我们一轮epoch的模型训练需要多长时间。 然后我们通过多个epoch循环训练模型,一个epoch完整的通过所有的在训练和验证集上例子。 在每个epoch,如果验证损失是我们迄今为止看到的最好的,我们将保存模型的参数,然后在训练结束后,我们将在测试集上使用该模型。 你可能已经注意到损失并没有真正减少,而且准确性很差。这是因为模型的几个问题,我们将在下一篇笔记中改进。 最后,我们真正关心的度量是测试的损失和准确性,我们将从我们得到的最好的验证损失的参数模型中得到。 在下一篇笔记中,我们将做的改进是: 这将使我们达到84%的准确度。print(TEXT.vocab.itos[:10])
print(LABEL.vocab.stoi)
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
搭建模型
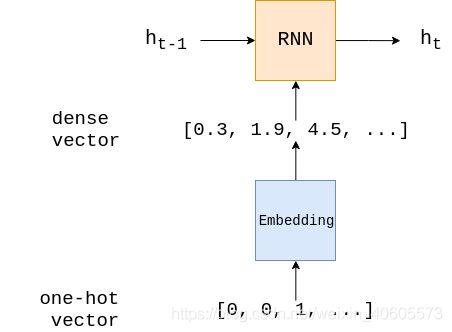
最后,线性层获取最终的隐藏状态,并通过一个全连接层 f ( h T ) f(h_T) f(hT)将其传递给它,并将其转换为正确的输出维度。import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim):
super(RNN, self).__init__()
self.embedding = nn.Embedding(input_dim, embedding_dim)
self.rnn = nn.RNN(embedding_dim, hidden_dim)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, text):
# text = [sent_len, batch_size]
embedded = self.embedding(text)
# embedded = [sent_len, batch_size, embedding_dim]
output, hidden = self.rnn(embedded)
# output = [sent_len, batch_size, hid_dim]
# hidden = [1, batch_size, hid_dim]
assert torch.equal(output[-1, :, :], hidden.squeeze(0))
return self.fc(hidden.squeeze(0))
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 1
model = RNN(INPUT_DIM, EMBEDDING_DIM, HIDDEN_DIM, OUTPUT_DIM)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
训练模型
import torch.optim as optim
optimizer = optim.SGD(model.parameters(), lr=1e-3)
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
def binary_accuracy(preds, y):
"""
Returns accuracy per batch, i.e. if you get 8/10 right, this returns 0.8, NOT 8
"""
#round predictions to the closest integer
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float() #convert into float for division
acc = correct.sum() / len(correct)
return acc
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
import time
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut1-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')
Epoch: 01 | Epoch Time: 0m 25s
Train Loss: 0.694 | Train Acc: 50.28%
Val. Loss: 0.698 | Val. Acc: 49.74%
Epoch: 02 | Epoch Time: 0m 25s
Train Loss: 0.693 | Train Acc: 49.94%
Val. Loss: 0.698 | Val. Acc: 50.01%
Epoch: 03 | Epoch Time: 0m 25s
Train Loss: 0.693 | Train Acc: 49.94%
Val. Loss: 0.698 | Val. Acc: 50.20%
Epoch: 04 | Epoch Time: 0m 25s
Train Loss: 0.693 | Train Acc: 49.77%
Val. Loss: 0.698 | Val. Acc: 49.69%
Epoch: 05 | Epoch Time: 0m 23s
Train Loss: 0.693 | Train Acc: 50.07%
Val. Loss: 0.698 | Val. Acc: 50.54%
model.load_state_dict(torch.load('tut1-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
Test Loss: 0.712 | Test Acc: 45.90%
完整代码
import torch
from torchtext import data
SEED = 1234
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
TEXT = data.Field(tokenize = 'spacy', tokenizer_language='en_core_web_sm')
LABEL = data.LabelField(dtype = torch.float)
from torchtext import datasets
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
print(f'Number of training examples: {len(train_data)}')
print(f'Number of testing examples: {len(test_data)}')
print(vars(train_data.examples[0]))
import random
train_data, valid_data = train_data.split(random_state = random.seed(SEED))
print(f'Number of training examples: {len(train_data)}')
print(f'Number of validation examples: {len(valid_data)}')
print(f'Number of testing examples: {len(test_data)}')
MAX_VOCAB_SIZE = 25_000
TEXT.build_vocab(train_data, max_size = MAX_VOCAB_SIZE)
LABEL.build_vocab(train_data)
print(f"Unique tokens in TEXT vocabulary: {len(TEXT.vocab)}")
print(f"Unique tokens in LABEL vocabulary: {len(LABEL.vocab)}")
print(TEXT.vocab.freqs.most_common(20))
print(TEXT.vocab.itos[:10])
print(LABEL.vocab.stoi)
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device
)
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim):
super(RNN, self).__init__()
self.embedding = nn.Embedding(input_dim, embedding_dim)
self.rnn = nn.RNN(embedding_dim, hidden_dim)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, text):
# text = [sent_len, batch_size]
embedded = self.embedding(text)
# embedded = [sent_len, batch_size, embedding_dim]
output, hidden = self.rnn(embedded)
# output = [sent_len, batch_size, hid_dim]
# hidden = [1, batch_size, hid_dim]
assert torch.equal(output[-1, :, :], hidden.squeeze(0))
return self.fc(hidden.squeeze(0))
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 1
model = RNN(INPUT_DIM, EMBEDDING_DIM, HIDDEN_DIM, OUTPUT_DIM)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
import torch.optim as optim
optimizer = optim.SGD(model.parameters(), lr=1e-3)
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
def binary_accuracy(preds, y):
# round predictions to the closest integer
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float() # convert into float for division
acc = correct.sum() / len(correct)
return acc
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
import time
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut1-model.pt')
print(f'Epoch: {epoch + 1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc * 100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc * 100:.2f}%')
model.load_state_dict(torch.load('tut1-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
后续行动