今天我们发布了 .NET 7 预览版 5。.NET 7 的这个预览版包括对通用数学的改进,方便了 API 作者,使其更轻松,一个新的 ML.NET 文本分类 API,增加了最先进的深度学习技术 ,对于自然语言处理,对源代码生成器的各种改进以及用于 RegexGenerator 的新 Roslyn 分析器和修复器,以及在 CodeGen、可观察性、JSON 序列化/反序列化和使用流方面的多项性能改进。
您可以下载适用于 Windows、macOS 和 Linux 的 .NET 7 Preview 5。
.NET 7 预览版 5 已通过 Visual Studio 17.3 预览版 2 进行测试。如果您想将 .NET 7 与 Visual Studio 系列产品一起使用,我们建议您使用预览频道版本。如果您使用的是 macOS,我们建议使用最新的 Visual Studio 2022 for Mac 预览版。现在,让我们了解此版本中的一些最新更新。
可观察性
可观察性的目标是帮助您更好地了解应用程序在规模和技术复杂性增加时的状态。
▌公开高效的 ActivityEvent 和 ActivityLink 标记枚举器方法
公开的方法可用于在性能关键场景中枚举 Tag 对象,而无需任何额外的分配和快速的项目访问。
var tags = new List>()
{
new KeyValuePair("tag1", "value1"),
new KeyValuePair("tag2", "value2"),
};
ActivityLink link = new ActivityLink(default, new ActivityTagsCollection(tags));
foreach (ref readonly KeyValuePair tag in link.EnumerateTagObjects())
{
// Consume the link tags without any extra allocations or value copying.
}
ActivityEvent e = new ActivityEvent("SomeEvent", tags: new ActivityTagsCollection(tags));
foreach (ref readonly KeyValuePair tag in e.EnumerateTagObjects())
{
// Consume the event's tags without any extra allocations or value copying.
} 可观察性:
https://devblogs.microsoft.com/dotnet/opentelemetry-net-reaches-v1-0/?ocid=AID3042760System.Text.Json多态性
#63747
System.Text.Json 现在支持使用属性注释对多态类型层次结构进行序列化和反序列化:
[JsonDerivedType(typeof(Derived))]
public class Base
{
public int X { get; set; }
}
public class Derived : Base
{
public int Y { get; set; }
}此配置为 Base 启用多态序列化,特别是在运行时类型为 Derived 时:
Base value = new Derived();
JsonSerializer.Serialize请注意,这不会启用多态反序列化,因为有效负载将作为 Base 往返:
Base value = JsonSerializer.Deserialize▌使用类型鉴别器
要启用多态反序列化,用户需要为派生类指定类型鉴别器:
[JsonDerivedType(typeof(Base), typeDiscriminator: "base")]
[JsonDerivedType(typeof(Derived), typeDiscriminator: "derived")]
public class Base
{
public int X { get; set; }
}
public class Derived : Base
{
public int Y { get; set; }
}现在将发出 JSON 以及类型鉴别器元数据:
Base value = new Derived();
JsonSerializer.Serialize可用于多态反序列化值:
Base value = JsonSerializer.Deserialize类型鉴别器标识符也可以是整数,因此以下形式是有效的:
[JsonDerivedType(typeof(Derived1), 0)]
[JsonDerivedType(typeof(Derived2), 1)]
[JsonDerivedType(typeof(Derived3), 2)]
public class Base { }
JsonSerializer.Serialize▌Utf8JsonReader.CopyString
#54410
直到今天,Utf8JsonReader.GetString() 一直是用户使用解码后的 JSON 字符串的唯一方式。这将始终分配一个新字符串,这可能不适合某些性能敏感的应用程序。新包含的 CopyString 方法允许将未转义的 UTF-8 或 UTF-16 字符串复制到用户拥有的缓冲区:
int valueLength = reader.HasReadOnlySequence ? checked((int)ValueSequence.Length) : ValueSpan.Length;
char[] buffer = ArrayPool.Shared.Rent(valueLength);
int charsRead = reader.CopyString(buffer);
ReadOnlySpan source = buffer.Slice(0, charsRead);
ParseUnescapedString(source); // handle the unescaped JSON string
ArrayPool.Shared.Return(buffer); 或者如果处理 UTF-8 更可取:
ReadOnlySpan source = stackalloc byte[0];
if (!reader.HasReadOnlySequence && !reader.ValueIsEscaped)
{
source = reader.ValueSpan; // No need to copy to an intermediate buffer if value is span without escape sequences
}
else
{
int valueLength = reader.HasReadOnlySequence ? checked((int)ValueSequence.Length) : ValueSpan.Length;
Span buffer = valueLength <= 256 ? stackalloc byte[256] : new byte[valueLength];
int bytesRead = reader.CopyString(buffer);
source = buffer.Slice(0, bytesRead);
}
ParseUnescapedBytes(source); ▌源生成改进
添加了对 IAsyncEnumerable
例如:
[JsonSerializable(typeof(typeof(MyPoco))]
public class MyContext : JsonSerializerContext {}
public class MyPoco
{
// Use of IAsyncEnumerable that previously resulted
// in JsonSerializer.Serialize() throwing NotSupportedException
public IAsyncEnumerable Data { get; set; }
}
// It now works and no longer throws NotSupportedException
JsonSerializer.Serialize(new MyPoco { Data = ... }, MyContext.MyPoco); System.IO.Stream 、 ReadExactly 和 ReadAtLeast
使用 Stream.Read() 时最常见的错误之一是 Read() 返回的数据可能比 Stream 中可用的数据少,而数据也比传入的缓冲区少。即使对于意识到这一点的程序员来说, 每次他们想从 Stream 中读取时都编写相同的循环很烦人。
为了解决这种情况,我们在 System.IO.Stream 基类中添加了新方法:
namespace System.IO;
public partial class Stream
{
public void ReadExactly(Span buffer);
public void ReadExactly(byte[] buffer, int offset, int count);
public ValueTask ReadExactlyAsync(Memory buffer, CancellationToken cancellationToken = default);
public ValueTask ReadExactlyAsync(byte[] buffer, int offset, int count, CancellationToken cancellationToken = default);
public int ReadAtLeast(Span buffer, int minimumBytes, bool throwOnEndOfStream = true);
public ValueTask ReadAtLeastAsync(Memory buffer, int minimumBytes, bool throwOnEndOfStream = true, CancellationToken cancellationToken = default);
} 新的 ReadExactly 方法保证准确读取请求的字节数。如果流在读取请求的字节之前结束,则抛出 EndOfStreamException。
using FileStream f = File.Open("readme.md");
byte[] buffer = new byte[100];
f.ReadExactly(buffer); // guaranteed to read 100 bytes from the file新的 ReadAtLeast 方法将至少读取请求的字节数。如果有更多数据可用,它可以读取更多数据,直到缓冲区的大小。如果流在读取请求的字节之前结束,则会引发 EndOfStreamException(在高级情况下,当您想要 ReadAtLest 的好处但您还想自己处理流结束场景时,您可以选择不引发异常)。
using FileStream f = File.Open("readme.md");
byte[] buffer = new byte[100];
int bytesRead = f.ReadAtLeast(buffer, 10);
// 10 <= bytesRead <= 100RegexGenerator 的新 Roslyn 分析器和修复器
在 .NET 7 中的正则表达式改进中,Stephen Toub 描述了新的 RegexGenerator 源生成器,它允许您在编译时静态生成正则表达式,从而获得更好的性能。要利用这一点,首先您必须在代码中找到可以使用它的位置,然后对每个代码进行更改。这听起来像是 Roslyn 分析器和修复器的完美工作,所以我们在 Preview 5 中添加了一个。
▌分析仪
新的分析器包含在 .NET 7 中,将搜索可以转换为使用 RegexGenerator 源生成器的 Regex 用途。分析器将检测 Regex 构造函数的使用,以及满足以下条件的 Regex 静态方法的使用:
提供的参数在编译时具有已知值。源代码生成器的输出取决于这些值,因此必须在编译时知道它们。
它们是面向 .NET 7 的应用程序的一部分。新的分析器包含在 .NET 7 目标包中,只有面向 .NET 7 的应用程序才有资格使用此分析器。
LangVersion(了解更多)高于 10。目前正则表达式源生成器需要将 LangVersion 设置为预览。
下面是 Visual Studio 中正在运行的新分析器:
▌代码修复器
代码修复程序也包含在 .NET 7 中,它做了两件事。首先,它建议使用 RegexGenerator 源生成器方法,并为您提供覆盖默认名称的选项。然后它用对新方法的调用替换原始代码。
以下是 Visual Studio 中正在运行的新代码修复程序: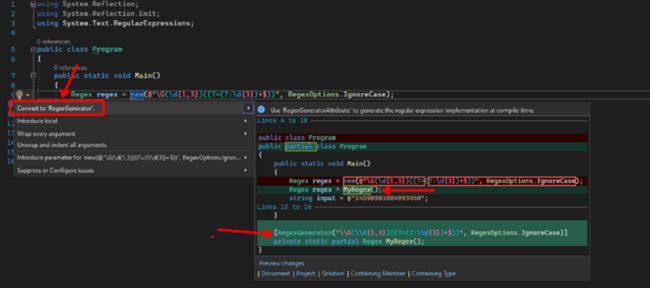
通用数学
在 .NET 6 中,我们预览了一个名为 Generic Math 的功能,它允许 .NET 开发人员在通用代码中利用静态 API,包括运算符。此功能将直接使可以简化代码库的 API 作者受益。其他开发人员将间接受益,因为他们使用的 API 将开始支持更多类型,而不需要每个数字类型都获得显式支持。
在 .NET 7 中,我们对实现进行了改进并响应了社区的反馈。有关更改和可用 API 的更多信息,请参阅我们的通用数学特定公告。
System.Reflection 调用成员时的性能改进
#67917
当对同一个成员进行多次调用时,使用反射来调用成员(无论是方法、构造函数还是属性 gettersetter)的开销已大大减少。典型增益快 3-4 倍。
使用 BenchmarkDotNet 包:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Reflection;
namespace ReflectionBenchmarks
{
internal class Program
{
static void Main(string[] args)
{
BenchmarkRunner.Run();
}
}
public class InvokeTest
{
private MethodInfo? _method;
private object[] _args = new object[1] { 42 };
[GlobalSetup]
public void Setup()
{
_method = typeof(InvokeTest).GetMethod(nameof(InvokeMe), BindingFlags.Public | BindingFlags.Static)!;
}
[Benchmark]
// *** This went from ~116ns to ~39ns or 3x (66%) faster.***
public void InvokeSimpleMethod() => _method!.Invoke(obj: null, new object[] { 42 });
[Benchmark]
// *** This went from ~106ns to ~26ns or 4x (75%) faster. ***
public void InvokeSimpleMethodWithCachedArgs() => _method!.Invoke(obj: null, _args);
public static int InvokeMe(int i) => i;
}
} ML.NET 文本分类 API
文本分类是将标签或类别应用于文本的过程。
常见用例包括:
- 将电子邮件分类为垃圾邮件或非垃圾邮件
- 从客户评论中分析情绪是积极的还是消极的
- 应用标签来支持工单
文本分类是分类的一个子集,因此今天您可以使用 ML.NET 中现有的分类算法来解决文本分类问题。然而,这些算法并没有解决文本分类以及现代深度学习技术的常见挑战。
我们很高兴推出 ML.NET 文本分类 API,该 API 使您可以更轻松地训练自定义文本分类模型,并将用于自然语言处理的最新最先进的深度学习技术引入 ML.NET。
有关更多详细信息,请参阅我们的 ML.NET 特定公告。
代码生成
非常感谢社区贡献者。
@singleaccretion 在预览版 5 期间做出了 23 项 PR 贡献,其中亮点是:
改进冗余分支优化以处理更多副作用 #68447
PUTARG_STK/x86: 标记 push [mem] 候选 reg 可选 #68641
在 LCL_FLD 上复制传播 #68592
@Sandreenko 完成允许 StoreLclVar src 成为 IND/FLD #59315。@hez2010 修复了 #68475 中的 CircleInConvex 测试。
来自@anthonycanino、@aromaa 和@ta264 的更多贡献包含在后面的部分中。
▌Arm64
#68363 合并“msub”(将两个寄存器值相乘,从第三个寄存器值中减去乘积)和“madd”(将两个寄存器值相乘,添加第三个寄存器值)逻辑。
Arm64:让 CpBlkUnroll 和 InitBlkUnroll 使用 SIMD 寄存器来初始化复制小于 128 字节的内存块(请参阅性能改进细节)。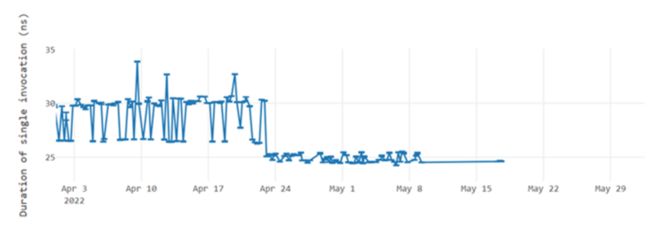
▌循环优化
#67930 处理循环克隆的更多场景现在支持以 > 1 的增量向后或向前的循环(请参阅性能改进详细信息)。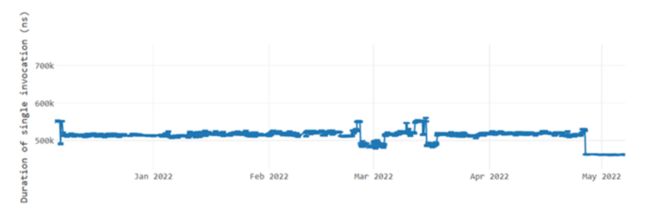
#68588 提升“this”对象的空值检查将空值检查移动到循环外的对象上(请参阅性能改进细节)。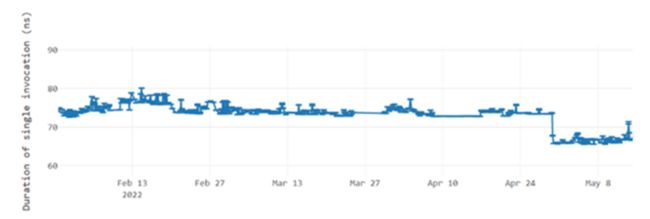
x86/x64 优化
- #67182 在 x64 上将 shlx、sarx、shrx 优化为 x64 上的 mov+shl、sar 或 shr 到 shlx、sarx 或 shrx。
- #68091为 x64 启用了 UMOD 优化。
- @anthonycanino 在 #68677中添加了 X86Serialize 硬件内在。
- @aromaa 在 #66965中将 bswap+mov 优化为movbe。
- @ta264 修复了 #68046 中 clr.alljits 子集的linux-x86 编译。
一般优化
现代化 JIT
随着社区增加了对 JIT 代码库的贡献,重组和现代化我们的代码库以使我们的贡献者能够轻松地增加和快速开发代码变得非常重要。
在 Preview 5 中,我们在内部做了大量工作,清理了 JIT 的中间表示,并消除了过去设计决策带来的限制。在许多情况下,这项工作导致 JIT 本身的内存使用更少和吞吐量更高,而在其他情况下,它导致了更好的代码质量。以下是一些亮点:
- 删除 CLS_VAR #68524
- 删除 GT_ARGPLACE #68140
- 删除 GT_PUTARG_TYPE #68748
以上允许我们在使用 byte/sbyte/short/ushort 类型的参数内联函数时消除 JIT 内联中的旧限制,从而提高代码质量(允许内联替换小参数 #69068)
需要改进的一个领域是更好地理解涉及读取和写入结构和结构字段的不安全代码。@SingleAccretion 通过将 JIT 的内部模型转换为更通用的“物理”模型,在这一领域做出了巨大的改变。这为 JIT 使用 struct reinterpretation 等功能更好地推理不安全代码铺平了道路:
还进行了其他小的清理以简化 JIT IR:
启用库修剪
正如我们之前所描述的,修剪让 SDK 从您的自包含应用程序中删除未使用的代码,以使它们更小。但是,修剪警告可能表明应用程序与修剪不兼容。为了使应用程序兼容,它们的所有引用也必须兼容。
为此,我们需要库也采用修剪。在预览版 5 中,我们努力使用 Roslyn 分析器更轻松地查找和修复库中的修剪警告。要查看库的修剪警告,请将
面向 .NET 7
要面向 .NET 7,您需要在项目文件中使用 .NET 7 Target Framework Moniker (TFM)。例如:
net7.0 全套 .NET 7 TFM,包括特定于操作的 TFM。
- net7.0
- net7.0-安卓
- net7.0-ios
- net7.0-maccatalyst
- net7.0-macos
- net7.0-tvos
- net7.0-windows
我们希望从 .NET 6 升级到 .NET 7 应该很简单。请报告您在使用 .NET 7 测试现有应用程序的过程中发现的任何重大更改。
支持
.NET 7 是一个短期支持 (STS) 版本,这意味着它将在发布之日起 18 个月内获得免费支持和补丁。需要注意的是,所有版本的质量都是相同的。唯一的区别是支撑的长度。有关 .NET 支持政策的更多信息,请参阅 .NET 和 .NET Core 官方支持政策。
我们最近将“Current当前”名称更改为“短期支持 (STS)”。我们正在推出这一变化。
重大变化
您可以通过阅读 .NET 7 中的重大更改文档找到最新的 .NET 7 重大更改列表。它按区域和版本列出了重大更改,并附有详细说明的链接。
要查看提出了哪些重大更改但仍在审核中,请关注 Proposed .NET Breaking Changes GitHub 问题。
路线图
.NET 版本包括产品、库、运行时和工具,代表了 Microsoft 内外多个团队之间的协作。您可以通过阅读产品路线图了解有关这些领域的更多信息:
我们感谢您对 .NET 的所有支持和贡献。请尝试 .NET 7 Preview 5 并告诉我们您的想法!

长按识别二维码
关注微软中国MSDN