原文由williamfzc发表于TesterHome社区,点击[原文链接]直达原帖与作者在线交流。
项目地址:https://github.com/williamfzc...
官方文档:https://williamfzc.github.io/...
使用指引:https://github.com/williamfzc...
前言
之前我陆陆续续分享了一些图像识别在测试领域内的应用实践,功能测试与性能测试都有涉及。前段时间写了 让所有人都能用图像识别做 UI 自动化 与 基于图像识别的 UI 自动化解决方案 之后 ,随着他逐渐稳定下来,在功能测试的这一块的个人目标终于基本算是完成了。
在性能测试方向,近期也有不少同学一直很关注这项技术在性能测试上的应用。这是之前陆陆续续做的两个版本:
尽管后来的版本已经基本可用(后来随着迭代,效率变得太低了,又变得不太可用了),但总感觉,这不是一个最理想的版本。
经过这段时间,我终于做好了一个更加符合我预期的方案: stagesep-x。
为什么又开新坑
与之前的版本相比,它原理完全不同,使用场景也不完全一致。所以我选择另外开一个项目而不是继续迭代。
stagesepx 能做什么
在软件工程领域,视频是一种较为通用的UI(现象)描述方法。它能够记录下用户到底做了哪些操作,以及界面发生了什么事情。例如,下面的例子描述了从桌面打开chrome进入amazon主页的过程:
stagesepx能够自动侦测并提取视频中的稳定或不稳定的阶段(例子中,stagesepx认为视频中包含三个稳定的阶段,分别是点击前、点击时与页面加载完成后):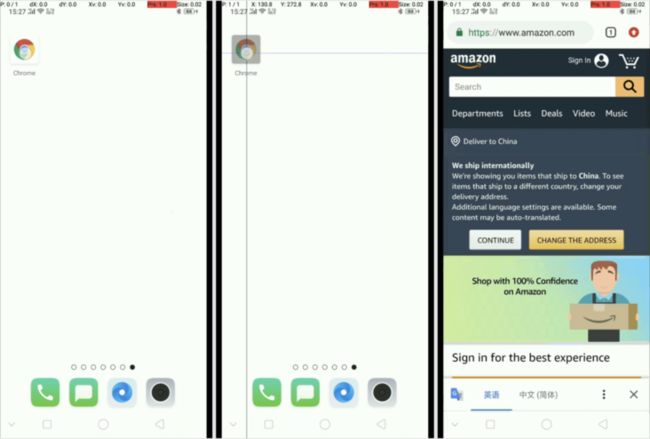
然后,自动得到每个阶段对应的时间区间:
例如,从图中可以看出:
- 视频开始直到 0.76s 时维持在阶段0
- 在 0.76s 时从阶段0切换到阶段1
- 在 0.92s 时从阶段1切换到阶段0,随后进入变化状态(当stagesepx无法将帧分为某特定类别、或帧不在待分析范围内时,会被标记为 -1,一般会在页面发生变化的过程中出现)
- 在 1.16s 时到达阶段2
- ...
以此类推,我们能够对视频的每个阶段进行非常细致的评估。通过观察视频也可以发现,识别效果与实际完全一致。
在运行过程中,stagesepx强大的快照功能能够让你很轻松地知道每个阶段到底发生了什么: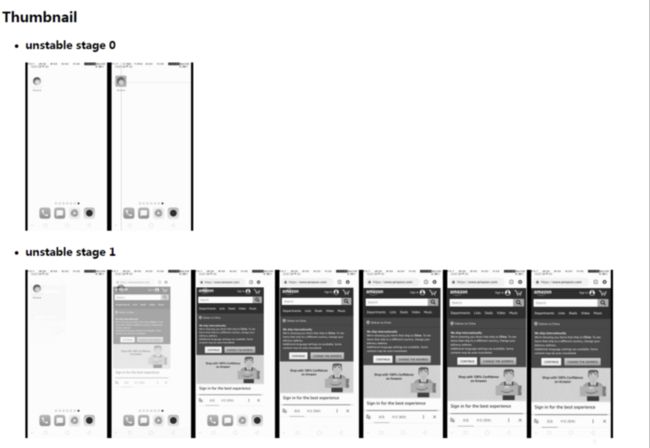
而所有的一切只需要一个视频,无需前置模板、无需提前学习。
应用举例
所有stagesepx需要的只是一个视频,而且它本质上只跟视频有关联,并没有任何特定的使用场景!所以,你可以尽情发挥你的想象力,用它帮助你实现更多的功能。
APP
- 前面提到的应用启动速度计算
- 那么同理,页面切换速度等方面都可以应用
- 除了性能,你可以使用切割器对视频切割后,用诸如findit等图像识别方案对功能性进行校验
- 除了应用,游戏这种无法用传统测试方法的场景更是它的主场
- ...
除了APP?
- 除了移动端,当然PC、网页也可以同理计算出结果
- 甚至任何视频?

Do whatever you want:)
使用
安装
Python >= 3.6
pip install stagesepx 例子
还想要更多功能?
当然,stagesepx不仅如此。但在开始下面的阅读之前,你需要了解 切割器(cutter)与 分类器(classifier)。stagesepx主要由这两个概念组成。
切割器
顾名思义,切割器的功能是将一个视频按照一定的规律切割成多个部分。他负责视频阶段划分与采样,作为数据采集者为其他工具(例如AI模型)提供自动化的数据支持。它应该提供友好的接口或其他形式为外部(包括分类器)提供支持。例如,pick_and_save方法完全是为了能够使数据直接被 keras 利用而设计的。
切割器的定位是预处理,降低其他模块的运作成本及重复度。得到稳定区间之后,我们可以知道视频中有几个稳定阶段、提取稳定阶段对应的帧等等。在此基础上,你可以很轻松地对阶段进行图片采样(例子中为每个阶段采集3张图片,一共有3个稳定阶段,分别名为0、1、2)后保存起来,以备他用(例如AI训练、功能检测等等):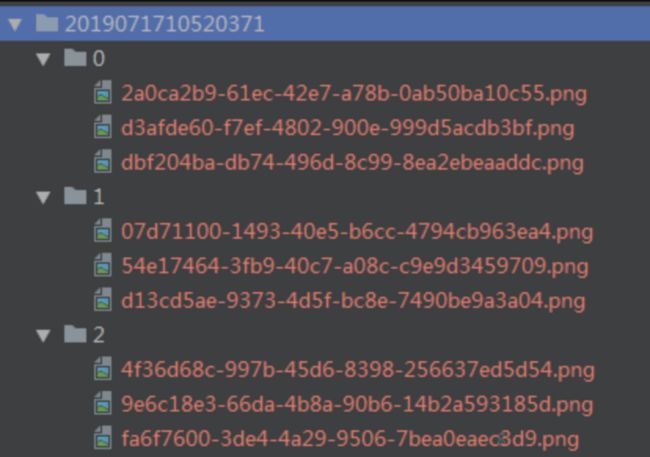
分类器
针对上面的例子,分类器应运而生。它主要是加载(在AI分类器上可能是学习)一些分类好的图片,并据此对帧(图片)进行分类。
例如,当加载上述例子中稳定阶段对应的帧后,分类器即可将视频进行帧级别的分类,得到每个阶段的准确耗时。
分类器的定位是对视频进行帧级别、高准确度的图片分类,并能够利用采样结果。它应该有不同的存在形态(例如机器学习模型)、以达到不同的分类效果。例如,你可以在前几次视频中用采样得到的数据训练你的AI模型,当它收敛之后在你未来的分析中你就可以直接利用训练好的模型进行分类,而不需要前置的采样过程了。stagesep2本质上是一个分类器。
不同形态的分类器
stagesepx提供了两种不同类型的分类器,用于处理切割后的结果:
- 传统的 SSIM 分类器无需训练且较为轻量化,多用于阶段较少、较为简单的视频;
- SVM + HoG分类器在阶段复杂的视频上表现较好,你可以用不同的视频对它进行训练逐步提高它的识别效果,使其足够被用于生产环境;
目前基于CNN的分类器已经初步完成,在稳定后会加入 :)但目前来看,前两个分类器在较短视频上的应用已经足够了(可能需要调优,但原理上是够用的)。
事实上,stagesepx在设计上更加鼓励开发者根据自己的实际需要设计并使用自己的分类器,以达到最好的效果。
丰富的图表
想得到耗时?stagesepx已经帮你计算好了:
快照功能能够让你很直观地知道每个阶段的情况:
...
优异的性能表现
在效率方面,吸取了 stagesep2 的教训(他真的很慢,而这一点让他很难被用于生产环境),在项目规划期我们就将性能的优先级提高。对于该视频而言,可以从日志中看到,它的耗时在惊人的300毫秒左右(windows7 i7-6700 3.4GHz 16G):
2019-07-17 10:52:03.429 | INFO | stagesepx.cutter:cut:200 - start cutting: test.mp4
...
2019-07-17 10:52:03.792 | INFO | stagesepx.cutter:cut:203 - cut finished: test.mp4除了常规的基于图像本身的优化手段,stagesepx主要利用采样机制进行性能优化,它指把时间域或空间域的连续量转化成离散量的过程。由于分类器的精确度要求较高,该机制更多被用于切割器部分,用于加速切割过程。它在计算量方面优化幅度是非常可观的,以5帧的步长为例,它相比优化前节省了80%的计算量。
当然,采样相比连续计算会存在一定的误差,如果你的视频变化较为激烈或者你希望有较高的准确度,你也可以关闭采样功能。
更强的稳定性
stagesep2存在的另一个问题是,对视频本身的要求较高,抗干扰能力不强。这主要是它本身使用的模块(template matching、OCR等)导致的,旋转、分辨率、光照都会对识别效果造成影响;由于它强依赖预先准备好的模板图片,如果模板图片的录制环境与视频有所差异,很容易导致误判的发生。
而SSIM本身的抗干扰能力相对较强。如果使用默认的SSIM分类器,所有的数据(训练集与测试集)都来源于同一个视频,保证了环境的一致性,规避了不同环境(例如旋转、光照、分辨率等)带来的影响,大幅度降低了误判的发生。
Bug Report
可想而知的,要考虑到所有的场景是非常困难的,在项目前期很难做到。
有什么建议或者遇到问题可以通过issue反馈给我 :)
项目地址
https://github.com/williamfzc...
原文由williamfzc发表于TesterHome社区,点击[原文链接]直达原帖与作者在线交流。

今日份的知识已摄入!想要学习更多干货知识、结识质量行业大牛和业界精英?
第十届中国互联网测试开发大会·深圳,了解下 >>