python自动化办公 处理表格文件更新邮件内容并自动发邮件
上次写的合并文件的代码还没捂热乎,就被道高一丈的工作变换了需要,完全、再也用不到了。于是乎,我又作死般写了另一些用来优化现有的工作,嗯希望这次存活得久一些吧。
日常有个发日报的工作,每天从库里或者平台上导出5个excel文件,将其中两个合并为不同sheet的一个文件,另外3个来自于数据库,一个需要vba代码分sheet(没用python),一个需要排下序(也没用),还有一个不需要处理,但是邮件内容中会用到它的数据。
最终实现的效果:
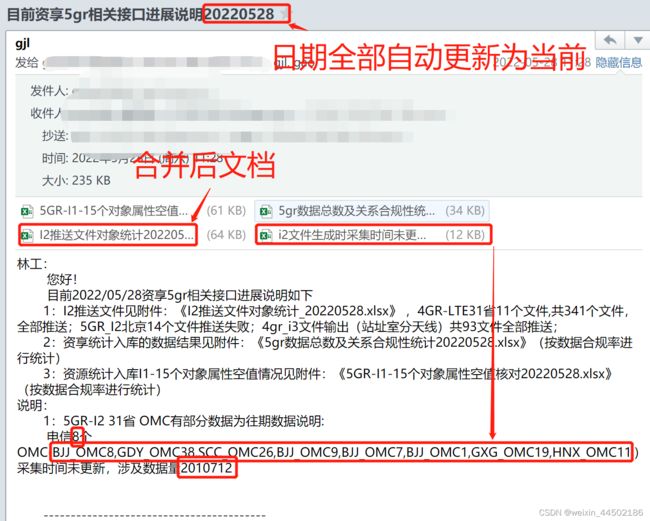
一、先来文档的处理
import smtplib
from email.header import Header
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
import openpyxl as op
import time
import os
def file_operation():
#合并数据,将第二个表数据加入到第一个
#读表,别问我为什么是C盘,我就一个盘
workbook01 = op.load_workbook(filename='C:。\\api订阅统计报表.xlsx')
workbook02 = op.load_workbook(filename='C:。\\api订阅统计报表明细.xlsx')
#读取第二个表的第一个sheet,好吧它就一个sheet
sheet_move = workbook02['文件生成统计报表']
#在第一个表中加一个sheet
workbook01_sheet2=workbook01.create_sheet(title='报表明细',index=1)
#创建空列表(临时列表),准备写入第二个表读到的数据
content_move = []
#获取第二个表的最大行数和列数
lenrow = sheet_move.max_row
lencol = sheet_move.max_column
#len = sheet_move.nrows()#这个不知道为啥不能用
#写入第二个表到临时列表
for row1 in sheet_move.iter_rows(min_row=1,max_row=lenrow,min_col=1,max_col=lencol):
list1 = []
#将每一单元格的值结果写入list1中,一个循环写一行,写第二行之前将list1清空
for cell1 in row1:
#print(cell1.value)
list1.append(cell1.value)
content_move.append(list1)
#将临时列表的数据写到第一个表的第二个sheet
for row2 in content_move:
workbook01_sheet2.append(row2)
#保存文件,并且重命名为当前日期的文件,时间的模块
workbook01.save(filename='C:\\Users\\gjl\\Downloads\\新建文件夹\\I2推送文件对象统计%s.xlsx'%(time.strftime('%Y%m%d', time.localtime(time.time()))))
#读取i2文件生成采集时间未更新文件,要返回三个值在正文里显示
workbook11 = op.load_workbook(filename='C:\\Users\\gjl\\Downloads\\新建文件夹\\i2文件生成时采集时间未更新%s.xlsx'%(time.strftime('%Y%m%d', time.localtime(time.time()))))
#workbook11.security.lockStructure = False#这里是一开始报错,以为文件是受保护所以打不开,结果发现是工作表名字写错了,没错就是下面这个sheet全写成了小写
sheet11 = workbook11['Sheet1']
list_omc = []
#这次每次只处理单列数据,所以不需要最大列
max_omc_row = sheet11.max_row
for row2 in sheet11.iter_rows(min_row=2,max_row=max_omc_row,min_col=3,max_col=3):
for cell2 in row2:
list_omc.append(cell2.value)
#将几个枚举值去重写入新的列表
list_omc_new = list(set(list_omc))
print(list_omc_new)
#枚举值个数
num_omc = len(list_omc_new)
print(num_omc)
num_sum = 0
#求和数量列并得出总数
for row22 in sheet11.iter_rows(min_row=2,max_row=max_omc_row,min_col=5,max_col=5):
for cell22 in row22:
num_sum += int(cell22.value)
print(num_sum)
return (num_omc,list_omc_new,num_sum)
二、邮件内容处理
def email_content(to_addr,to_send,mail_from):
#定义邮件对象
msg_root = MIMEMultipart('related')# 采用related定义内嵌资源的邮件体,还有啥其他类型吗,大佬的代码里也没写
#邮件主题
subject = '目前资享5gr相关接口进展说明%s'%(time.strftime('%Y%m%d', time.localtime(time.time())))
msg_root['subject'] = Header(subject, 'utf-8')#设置主题格式
msg_root['From'] = mail_from
#这块为啥是这样其实咱也不会,是不是该去看看源码...可是那种天书真的要让我看吗......
#to_addr是收件邮箱,to_send是抄送人
msg_root['to'] = to_addr
msg_root['Cc'] = to_send
text_sentence = '''林工:
您好!
目前%s资享5gr相关接口进展说明如下
1:I2推送文件见附件:《I2推送文件对象统计_%s.xlsx》 ,4GR-LTE31省11个文件,共341个文件,全部推送;5GR_I2北京14个文件推送失败;4gr_i3文件输出(站址室分天线)共93文件全部推送;
2:资享统计入库的数据结果见附件:《5gr数据总数及关系合规性统计%s.xlsx》(按数据合规率进行统计)
3:资源统计入库I1-15个对象属性空值情况见附件:《5GR-I1-15个对象属性空值核对%s.xlsx》(按数据合规率进行统计)
说明:
1:5GR-I2 31省 OMC有部分数据为往期数据说明:
电信%s个OMC(%s)采集时间未更新,涉及数据量%s
-----------------------------------------
这里原来是邮件签名
'''%((time.strftime('%Y/%m/%d', time.localtime(time.time()))),
time.strftime('%Y%m%d', time.localtime(time.time())),
time.strftime('%Y%m%d', time.localtime(time.time())),
time.strftime('%Y%m%d', time.localtime(time.time())),
result[0],txt_omc,result[2]
)
text_sub = MIMEText(text_sentence, 'plain', 'utf-8')
msg_root.attach(text_sub)
#改变当前目录为取附件的文件夹
os.chdir('C:。。\\新建文件夹')
#饶了我吧,只知道这里能把邮件附件加上,根本不知道为啥能加上,暴露了代码是抄来的...
dir = os.getcwd()#获取操作目录
for fn in os.listdir(dir):
print(fn)
xlsx_file = open(fn,'rb').read()
xlsx_file = MIMEText(xlsx_file, 'base64', 'utf-8')
xlsx_file["Content-Type"] = 'application/octet-stream'
xlsx_file.add_header('Content-Disposition', 'attachment', filename=fn)
msg_root.attach(xlsx_file)
return msg_root
三、发送邮件
def email_send(msg_root,mail_from):
#邮箱服务器地址和端口,登录邮箱后在设置里应该就能看到
try:
sftp_obj =smtplib.SMTP_SSL('smtp.qiye.163.com', 465)
#我一定是个憨憨,只传了邮箱名为入参,没传密码
sftp_obj.login(mail_from,'邮箱密码')
#收件邮箱和抽送邮箱都以逗号分隔
sftp_obj.sendmail(mail_from,to_addr.split(',') + to_send.split(','),msg_root.as_string())
#退出服务
sftp_obj.quit()
print('sendemail successful!')
except Exception as e:
print('sendemail failed next is the reason')
print(e)
四、函数调用
if __name__ == '__main__':
result = file_operation()
print(result)
#获取到模板数据,列表第二个是另一个带有枚举值的列表,要将其改为只有枚举值和逗号的文本,先设个空文本
txt_omc = ''
#最后一个枚举值后的逗号不能要,通过if去掉
for i in result[1]:
print(i)
if i == result[1][-1]:
txt_omc += str(i)
else:
txt_omc+=str(i)+','
mail_from = '发件邮箱'
# 可以是一个列表,支持多个邮件地址同时发送,测试改成自己的邮箱地址
#不知道为啥,只要名字是汉字,就会出现英文名和汉字名挨在一起,邮件名和邮件名挨在一起,最后我粗暴的解决办法是全改为英文名
to_addr = 'hie<收件人邮箱>,王二<收件人邮箱>'
to_send = 'wao<抄送人邮箱>,wocao<抄送人邮箱>'
msg_root = email_content(to_addr,to_send,mail_from)
email_send(msg_root,mail_from)
五、没什么用的总结感悟
1、可做的优化:
(1)表的复制合并好像有xlrd库可以用,但是试了总报错,或许可以再试试,或许就不用读全表的内容了?
(2)另外两个表或许也可以自动处理一下,或许以后就只用运行一次代码,嗖地就发完了,但是涉及vba代码的运行,难道要把vba改为python的程序,啊~头秃…
(3)还有那个带汉语名字的邮箱排列的问题。
2、收获?
(1)能节省二十分钟左右工作时间吧,也避免部分日期或数值忘记更新。
(2)总算会写函数啦!
ps:程序是陆续写成,参考了很多的文章,但是忘了记下来,所以,只能是感谢各位无名大佬吧!