最具体的K-均值聚类算法及实现!小白也能懂!
k-均值聚类算法
- 一.聚类分析概述
-
- 1.簇的定义
- 2.常用的聚类算法
- 二.K-均值聚类算法
-
- 1.k-均值算法的python实现
-
- 1.1 导入数据集
- 1.2 构建距离计算函数
- 1.3 编写自动生成rand质心的函数
- 1.4 K-means聚类函数的实现
一.聚类分析概述
聚类分析是无监督类机器学习算法中常用的一类,其目的是将数据划分成有意义或有用的组(也被称为簇)。组
内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。组内的相似性 (同质性)越 大,组间差别越大,聚类就越好。
1.簇的定义
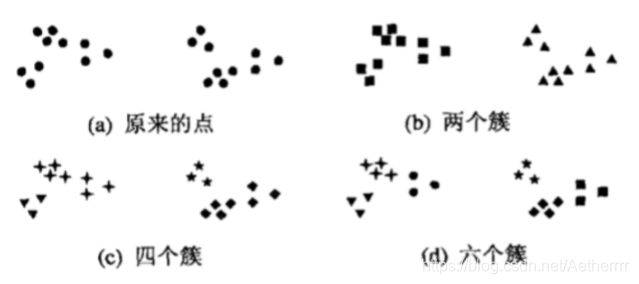
簇就是分类结果中的类,其没有确切的定义,也没有客观的标准,我们可以利用这个我网上找来的图来理解一下什么是簇:
该图中显示了20个点的三种不同的分法,不同的类别用不同的形状表示,图a表示还未分类的原始图。b,c,d三图分别表示分为两部分,四部分,六部分的不同分法。其中我们将簇分为两类可能是最普遍的表示方法,但是分为四个簇仔细一想好像并不是不无道理,而六个簇的分类中,将两个较大的簇均分为三个小簇可能是人视觉系统造成的假象。这也进一步说明了簇的定义其实是不准确的,而我们如何在问题中更好的定义簇,这依赖于该数据的特性和期望的结果。
2.常用的聚类算法
常用的聚类算法有以下三种:
•K-means聚类:也称为K均值聚类,它试图发现k(用户指定个数)个不同的簇 ,并且每个簇的中心采用簇中所含 值的均值计算而成。
•层次聚类:层次聚类(hierarchical clustering)试图在不同层次对数据集进行划分,从而形成树形的聚类结构。
•DBSCAN:这是一种基于密度的聚类算法,簇的个数由算法自动地确定。低密度区域中的点被视为噪声而忽略, 因此DBSCAN不产生完全聚类。
(挖个坑,后续的总结中也会总结这几个算法)
二.K-均值聚类算法
简要的概述k-均值算法:我们通过给定的数据集,将其分为K个簇,簇的个数K是用户给定的。给一个簇通过其质心(centroid)来描述。
大概的流程:1.随机选取K个质心(大数据数学基础老师曾讲过这个更高级的算法中会有更具体的初始化质心,现在还并未了解到),k为用户所指定。
2.将数据中每一个点和这K个质心算距离,并将其归为最近的质心点,归为同一个质心点的数据点为一个簇
3.根据归属的k个类的数据点,计算该簇的平均值作为新的质心点,并反复2,3操作直至簇不再发生变化或质心不再发生变化为止。
1.k-均值算法的python实现
伪代码:
创建k个点作为初始质心(通常是随机选择)
当任意一个点的簇分配结果发生改变时:
对数据集中的每个点:
对每个质心:
计算质心与数据点之间的距离
将数据点分配到据其近的簇
对每个簇,计算簇中所有点的均值并将均值作为新的质心
直到簇不再发生变化或者达到大迭代次数
对于距离的计算,我们使用最简单的欧氏距离。
1.1 导入数据集
在这里我使用的是之前老师给的鸢尾花数据集(常用的那种,然后把第一行标签删掉,蒟蒻不会处理第一行标签)
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
iris = pd.read_csv('iris.csv', header=None)
(简单的读入)
1.2 构建距离计算函数
我们需要定义一个两个长度相同的数组,基于此我们来实现欧氏距离的计算函数,而不是直接应用计算距离计算结果,只比距离远近的情况下,我们可以免去开平方运算以减少运算量,加快运算速度。
这里要注意量纲(单位)的统一!因为这里用的是鸢尾花数据集,所以不需要考虑量纲问题。
def dist(arrA , arrB):
x = arrA - arrB
dist = np.sum(np.power(x,2),axis=1)
return dist
1.3 编写自动生成rand质心的函数
选取data中所有行,第n-1列中的最小值和最大值(n-1列为其中一个特征值数据),利用np.random.uniform函数生成随机质心,三个参数分别为(随机数下界,随机数上界,(k*n-1)的矩阵)
def randCent(D , k):
n = D.shape[1]
D_min = D.iloc[ : , :n-1].min()
D_max = D.iloc[ : , :n-1].max()
centers = np.random.uniform(D_min , D_max , (k,n-1))
return centers
1.4 K-means聚类函数的实现
因为在k-means实现的时候我们需要不断地迭代质心,因此我们需要两个可以迭代的容器来完成这个目标:
第一个容器是用来存放质心的,用list来存放,因为,list不仅是可迭代对象,同时list内不同元素索引位置也可用于标记和区分各质心,即各簇的编号;命名为center
第二个容器是三列,第一列存放与最近质心点的距离,第二列存放本次迭代的类别,第三列存放上次迭代的类别。(通过比较第二列和第三列来选择是否终止迭代) 命名为res_mid,之后与元数据合并为resultlist
其中 dist代表返回的欧氏距离值
def Kmeans(D , k):
m,n = D.shape
center = randCent(D , 3)
res_mid = np.zeros((m,3))
res_mid[: , 0] = np.inf
res_mid[: , 1:3] = -1
resultlist = pd.concat([D , pd.DataFrame(res_mid)] , axis = 1 , ignore_index = True)
changed = True
while changed:
changed = False
for i in range(m):
dist1 = dist(D.iloc[i,:n - 1].values, center)
resultlist.iloc[i, n] = dist1.min()
resultlist.iloc[i, n+1] = np.where(dist1 == dist1.min())[0]
changed = not (resultlist.iloc[:, n+1] == resultlist.iloc[ : , n +2]).all()
if changed:
cent_df = resultlist.groupby(n+1).mean()
center = cent_df.iloc[: , :n-1].values
resultlist.iloc[: , n+2] = resultlist.iloc[: , n+1]
return center , resultlist
有以下几点需要特别注意:
1.设置统一的操作对象resultlist
为了调用和使用的方便,此处将res_mid容易转换为了DataFrame并与输入DataFrame合并,组成的 对象可作为后续调用的统一对象,该对象内即保存了原始数据,也保存了迭代运算的中间结果,包括数据所 属簇标记和数据质心距离等,该对象同时也作为终函数的返回结果;
2. 判断质心发生是否发生改变条件
注意,在K-Means中判断质心是否发生改变,即判断是否继续进行下一步迭代的依据并不是某点距离新的质 心距离变短,而是某点新的距离向量(到各质心的距离)中短的分量位置是否发生变化,即质心变化后某 点是否应归属另外的簇。在质心变化导致各点所属簇发生变化的过程中,点到质心的距离不一定会变短,即 判断条件不能用下述语句表示
if not (resultlist.iloc[:, -1] == resultlist.iloc[:, -2]).all()
3.合并DataFrame后索引值为n的列
这里有个小技巧,能够帮助迅速定位DataFrame合并后列的索引,即两个DF合并后后者的第一列在合并后的 DF索引值为n,第二列索引值为n+1
4.质心和类别一一对应
即在后生成的结果中,center的行标即为resultlist中各点所属类别